
Med-HEAL: Analyzing and Mitigating Hallucinations in Medical LLMs with Hallucination-Aware In-Context Learning
Source: arXiv:2606.01301 · Published 2026-05-31 · By Yiming Liao, Zeno Franco, Jose Eduardo Lizarraga Mazaba, Keke Chen
TL;DR
Med-HEAL addresses the critical problem of hallucinations in medical large language models (LLMs) that analyze electronic health records (EHRs) for clinical question answering. Unlike prior benchmarks that rely on synthetic data or isolated factual recall, Med-HEAL builds on the clinically realistic EHRNoteQA dataset from MIMIC-IV discharge summaries to collect naturally occurring hallucinations generated by BioMistral-7B. These hallucinations are labeled through a dual-judge pipeline combining GPT-4o as an LLM assessor with human auditing by medical students, capturing detailed error types. The authors then propose an inference-time mitigation framework based on a self-critique pipeline that lets a model detect and correct its own reasoning errors, supported by retrieval-augmented in-context learning (RA-ICL) of contrastive hallucinated and corrected examples. Experiments across five open-source medical LLMs (BioMistral-7B, Llama-3.1, DeepSeek, Qwen2.5, Qwen3) demonstrate that the self-critique approach improves accuracy significantly for three models without model fine-tuning. The work offers a reusable hallucination dataset grounded in real clinical scenarios and a practical prompting framework for hallucination mitigation in EHR-based QA, advancing safer medical AI deployment.
Key findings
- BioMistral-7B zero-shot accuracy on EHRNoteQA is 63.8% with 36.2% hallucinations among 962 open-ended questions.
- Hallucination types: 98.0% factual errors, 82.2% incomplete reasoning, and 5.2% fabricated sources (non-synthetic, realistic failures).
- GPT-4o as LLM judge achieves 94.0% agreement with human-validated gold standard (100 samples), outperforming individual medical student reviewers (80-89%).
- Accuracy decreases from 74.1% with 1 discharge note to 38.9% with 3 notes, showing difficulty synthesizing complex records.
- Self-critique plus retrieval-augmented in-context learning improves accuracy: e.g., DeepSeek from 76.9% to 85.9% (+9%, p<0.001), Llama3 92.1% to 94.1% (+2.0%, p=0.024), Qwen2.5 91.6% to 92.8% (+1.2%, p=0.02).
- BioMistral-7B baseline is 48.1%, improves only +2.3% (p=0.11) due to limited context window and fine-tuning artifacts preventing effective self-critique.
- Retrieval-augmented ICL alone (positive or negative example retrieval) and chain-of-thought prompting had little or inconsistent improvement.
- Self-critique pipeline rejects revised responses if deemed worse, ensuring no degradation from attempted corrections.
Threat model
The work considers an implicit threat model of medical LLMs hallucinating false or fabricated clinical information in electronic health record question answering; adversaries are not explicit actors but hallucinations represent inadvertent model failures that could cause clinical harm if undetected. Models cannot be retrained or fine-tuned at inference time, and mitigation must occur without external adversarial input or corruption.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly detailed but the focus is on hallucinations present in real, complex clinical EHR question answering by LLMs operating in a clinical decision support setting. The models have no parameter retraining during mitigation; adversaries do not manipulate inputs or outputs actively.
Data: The study uses EHRNoteQA, derived from 962 MIMIC-IV discharge summaries coupled with clinician-verified open-ended clinical questions and ground truth answers, covering diverse medical diagnosis, treatments, labs, timelines, etc. BioMistral-7B zero-shot answers to these questions produce hallucinated outputs. A subset (100 samples) is human-audited by medical students; the full set is labeled via a dual evaluation using GPT-4o plus humans for calibration. The final Med-HEAL dataset contains tuples of (Discharge Note, Question, Model Answer, Ground Truth Answer, Binary hallucination label, Error type annotation).
Architecture/Algorithm: The Med-HEAL mitigation uses a hallucination-aware in-context learning pipeline consisting of: (a) Zero-shot answer generation by test model; (b) Self-critique: same model reviews its own answer along with context and question to identify reasoning errors; (c) Retrieval of the most semantically similar hallucination example (with error diagnosis and corrected answer) from Med-HEAL dataset using GTR-T5-base embeddings for discharge summary similarity; (d) Regeneration of answer conditioned on error diagnosis and retrieved example; (e) Self-verdict: model judges whether regenerated answer is better; outputs improved answer only if it passes.
No parameter updates or fine-tuning were performed during mitigation, only prompt engineering with retrieval-augmented in-context learning (RA-ICL) and model self-critique.
Training Regime: No new weights training for mitigation; base models are either fine-tuned versions or open-source LLMs serving inference. Experiments use 5-fold cross-validation splitting on EHRNoteQA. Inference at temp=0.1, max tokens=8,096 on a RTX 4090 GPU. Seeds and hyperparameters for inference are unspecified but consistent.
Evaluation Protocol: Accuracy measured by GPT-4o judge binary correctness against clinician data. Human reviews used for calibration and validation. Comparison of zero-shot baseline vs multiple prompting/ICL methods including positive retrieval, negative retrieval, contrastive retrieval, chain-of-thought (evidence-first and conclusion-first), and their proposed self-critique + RA-ICL method. Statistical significance tested using McNemar’s exact test over 962 questions in 5-fold CV.
Reproducibility: Code and Med-HEAL dataset publicly released on GitHub. Evaluations use OpenAI GPT-4o API and local model inference through vLLM. Limited number of human audits (100 samples) due to complexity. Med-HEAL dataset comes primarily from BioMistral hallucinations; scope for augmenting with more models in future.
Concrete end-to-end example: BioMistral generates an incorrect answer with fabricated fracture cause and surgery. GPT-4o labels this hallucination and categorizes error types. During mitigation, the same or a different LLM critiques the answer, retrieves a similar hallucination+correction example from Med-HEAL via GTR-T5 semantic similarity on discharge summaries, then regenerates and self-verdicts an improved answer conditionally.
This multi-step prompting pipeline enables error detection and guided revision without retraining for safer clinical QA.
Technical innovations
- Dual-judge hallucination labeling pipeline combining GPT-4o as automated LLM judge with human medical student audits to generate clinically validated hallucination dataset.
- Inference-time self-critique prompting pipeline where models identify and correct their own hallucinated reasoning errors without parameter updates.
- Retrieval-augmented in-context learning (RA-ICL) using semantically similar hallucination error examples paired with corrections as contrastive prompts.
- Self-verdict mechanism for models to accept regenerated answers only if they improve correctness over zero-shot outputs.
Datasets
- EHRNoteQA — 962 clinical questions from MIMIC-IV discharge summaries — public via referenced benchmark
- Med-HEAL hallucination dataset — 348 hallucinated responses with multi-label error annotations from BioMistral-7B on EHRNoteQA — released at github.com/yimingliao-blad/med-heal.git
Baselines vs proposed
- BioMistral-7B zero-shot: 48.1% accuracy vs Med-HEAL self-critique: 50.4% (+2.3%, p=0.11)
- DeepSeek-R1-8B zero-shot: 76.9% accuracy vs Med-HEAL self-critique: 85.9% (+9.0%, p<0.001)
- Llama-3.1-8B zero-shot: 92.1% accuracy vs Med-HEAL self-critique: 94.1% (+2.0%, p=0.024)
- Qwen2.5-7B zero-shot: 91.6% accuracy vs Med-HEAL self-critique: 92.8% (+1.2%, p=0.02)
- Qwen3-8B zero-shot: 96.3% accuracy vs Med-HEAL self-critique: 98.0% (+1.7%, p=0.07)
- Retrieval-augmented ICL (positive, negative, contrastive) and Chain-of-Thought prompting provided limited or inconsistent improvements compared to zero-shot baselines.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.01301.
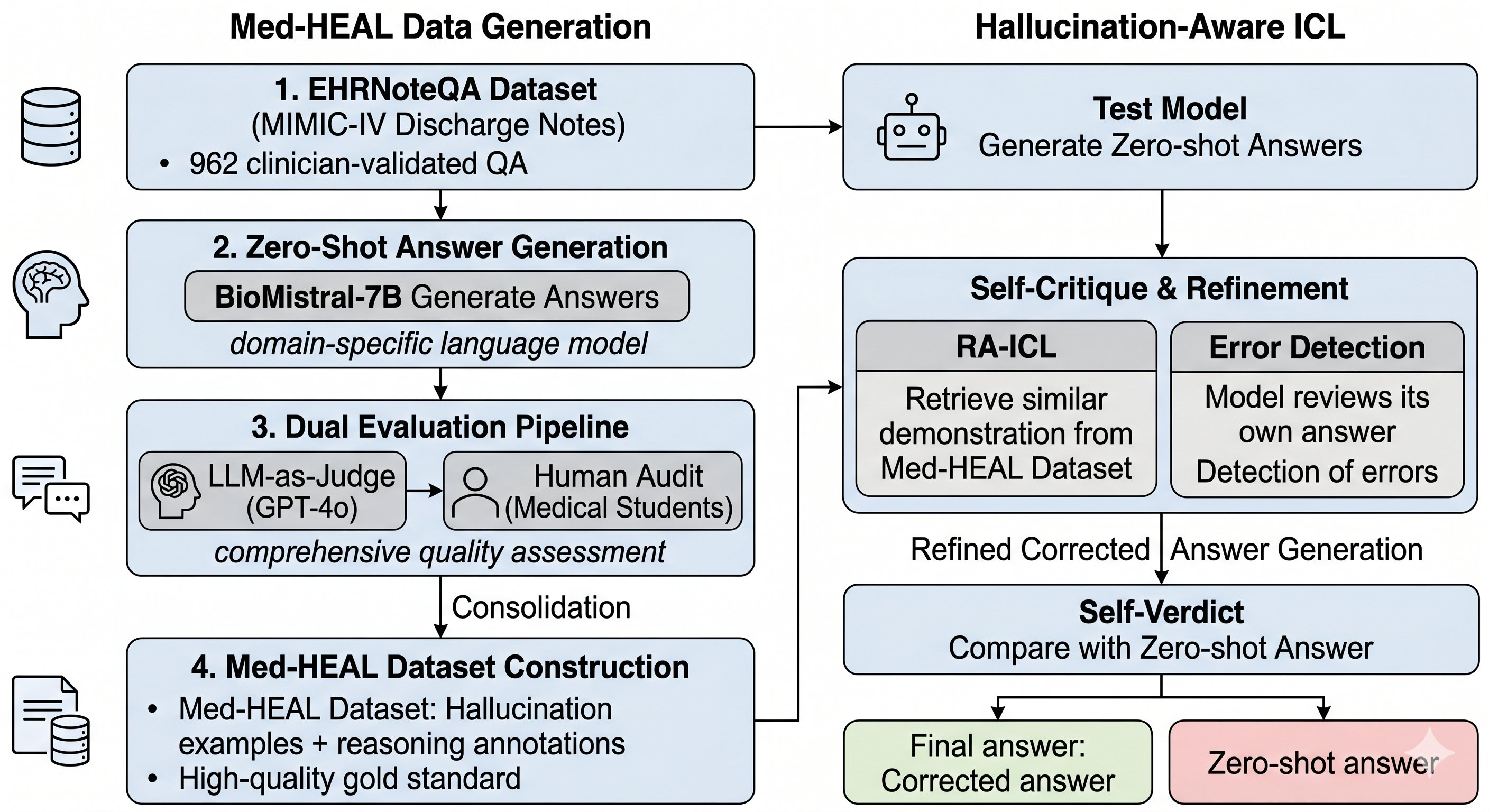
Fig 1: Overall Pipeline of Med-HEAL. Phase 1 (Left): LLM-generated labels are audited against human ground truth provided
Limitations
- Med-HEAL dataset created primarily from hallucinations of a single source model (BioMistral-7B), which may limit diversity of hallucination patterns captured.
- Human auditing limited to 100 samples due to resource constraints, potentially limiting accuracy and coverage of label calibration.
- Self-critique pipeline depends on model ability to reflect on errors; less capable or heavily fine-tuned models like BioMistral struggle to effectively perform self-critique.
- Evaluation uses GPT-4o automated judge with human calibration but potential biases or errors remain in automated clinical correctness assessments.
- Current experiments focus only on EHRNoteQA discharge summary data; generalization to other medical text types or modalities remains untested.
- No adversarial or distributional shift testing to evaluate robustness of hallucination mitigation strategies.
Open questions / follow-ons
- How well does the self-critique hallucination mitigation generalize to other medical LLM architectures and broader clinical datasets beyond EHRNoteQA?
- Can incorporating hallucination data from multiple diverse source models improve mitigation robustness and coverage?
- What is the impact of adversarially crafted inputs or distribution shifts on the efficacy of Med-HEAL’s hallucination detection and correction pipeline?
- Could integration of external knowledge bases or verified clinical ontologies further reduce hallucination rates when combined with self-critique?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, Med-HEAL’s approach demonstrates an effective methodology to identify and mitigate hallucinated outputs in complex NLP systems without model retraining. The dual-judge labeling combining an LLM assessor and human audits exemplifies scalable but clinically robust error annotation, which could inspire similar high-fidelity adversarial bot detection evaluations. The inference-time self-critique and retrieval-augmented in-context learning (RA-ICL) pipeline shows how prompt engineering and external knowledge retrieval can materially reduce logical errors under complex reasoning constraints, a principle transferable to bot response validation or challenge generation frameworks requiring nuanced reasoning. Additionally, the work highlights the limits of naive retrieval methods and chain-of-thought prompting for complex error correction, reinforcing the need for task-specific error reflection mechanisms. While focusing on medical LLMs, these techniques inform general strategies for enhancing trustworthiness and safety of language models deployed in security-sensitive and high-stakes interactive settings.
Cite
@article{arxiv2606_01301,
title={ Med-HEAL: Analyzing and Mitigating Hallucinations in Medical LLMs with Hallucination-Aware In-Context Learning },
author={ Yiming Liao and Zeno Franco and Jose Eduardo Lizarraga Mazaba and Keke Chen },
journal={arXiv preprint arXiv:2606.01301},
year={ 2026 },
url={https://arxiv.org/abs/2606.01301}
}