
HOLA: Holistic Multi-Modal Alignment for Open-Set 3D Recognition
Source: arXiv:2606.01334 · Published 2026-05-31 · By Koby Aharonov, Oren Shrout, Ayellet Tal
TL;DR
This paper tackles the challenge of open-set 3D recognition, where models must generalize to rare and unseen object categories in 3D point cloud data. Previous approaches align each 3D point cloud to a single 2D image or text caption using heavy Vision Transformers, which limits holistic understanding and hurts performance especially for long-tail categories. The authors propose a novel multi-modal alignment framework that jointly aligns each 3D point cloud with multiple images and multiple text descriptions to better capture the full 3D shape and semantics. A key technical contribution is a decoupled multi-positive contrastive loss that separates the multi-positive alignment from the negative-sample discrimination, preserving the hardness-aware property necessary to focus on challenging negatives. Additionally, they introduce a lightweight adapter for retrieved web captions to reduce domain gap with curated captions. They demonstrate state-of-the-art zero-shot open-vocabulary recognition on large long-tail benchmarks (e.g., Objaverse-LVIS), with significant accuracy gains and much fewer parameters and faster training than prior large ViT-based methods.
Key findings
- Decoupled multi-positive contrastive loss improves zero-shot Objaverse-LVIS top-1 accuracy by +2.0% over state-of-the-art large 2D ViT based models while using 72M params vs 1020M params.
- HOLA outperforms strongest lightweight baseline (TAMM-PointBERT 35M params) by 6.0% top-1 accuracy on Objaverse-LVIS with a comparable 32M parameter model.
- Using multiple positive views with standard multi-positive contrastive loss degrades performance due to spotlight crowding effect; the decoupled loss preserves hardness-aware gradients on negatives.
- Lightweight two-layer MLP text adapter applied only to noisy web captions reduces domain gap between in-domain annotations and web captions, improving zero-shot performance.
- HOLA models achieve substantially higher inference speed (e.g., 152-202 FPS) compared to 27-85 FPS of large ViT-based baselines, enabling faster deployment with strong accuracy.
- Multi-modal holistic alignment (3D point clouds with multiple image views and multiple text sources) yields more robust embeddings, especially benefiting rare and long-tail object categories.
- Zero-shot generalization gains also hold on real scanned data (ScanObjectNN) and standard benchmarks (ModelNet40), demonstrating transfer beyond training distributions.
Threat model
n/a — This paper is focused on developing training methods to improve open-set 3D recognition and multi-modal alignment, rather than addressing adversarial or malicious threat scenarios.
Methodology — deep read
Threat Model & Assumptions: The adversary is not explicitly considered, as this is a model and training methodology paper aimed at open-set generalization rather than adversarial robustness. The model assumes access to unlabeled or weakly-labeled 3D point cloud data with multi-view images and textual annotations, including noisy web captions.
Data: The authors train on multi-modal triplets consisting of one 3D point cloud, multiple rendered image views, and multiple textual descriptions (human annotations, model-generated captions, and retrieved web captions). Training data is drawn from datasets ShapeNetCore, 3D-FUTURE, ABO, and Objaverse, organized into three subsets: "ShapeNet" (52k triplets), "Ensembled no LVIS" (829k triplets), and "Ensembled" (875k triplets). Evaluation uses zero-shot classification on Objaverse-LVIS (long-tail, 46.8k shapes, 1156 categories), ScanObjectNN (real scanned objects, 15 categories), and ModelNet40 (40 categories). Text sources vary in fidelity and domain alignment.
Architecture/Algorithm: The model consists of three encoders – point cloud, image, and text encoders. The image and text encoders are frozen CLIP-style transformers pretrained on web-scale 2D corpora to provide large-scale vision-language knowledge. The 3D encoder is trainable and relatively lightweight, based on PointBERT or MinkowskiNet.
The key novel component is the decoupled multi-positive contrastive loss function: unlike standard multi-positive contrastive loss which jointly normalizes positives and negatives and suffers from "spotlight crowding," their loss decouples positive alignment and negative separation into separate additive terms. This preserves the hardness-aware focus on challenging negatives by making negatives compete only among themselves, while jointly attracting the anchor to all positives (multiple images and texts). They also introduce a hardness weighting for positive alignments, focusing more on harder positive anchors farther from their positives.
Additionally, a lightweight 2-layer MLP text adapter module is applied exclusively to retrieved web caption embeddings to reduce domain gap with in-domain labels. It uses residual connections and normalization and is trained end-to-end to align these noisier captions closer to rendered image embeddings.
Training Regime: Training uses batches with multiple multi-modal triplets, treating one modality at a time as anchor and the others as positives, with other batch samples as negatives. Temperature parameter tau is set (exact hyperparameters unspecified). Training is efficient due to lightweight 3D backbones and frozen large pre-trained 2D encoders. The model trains until convergence (not explicitly quantified), with standard optimizer and loss backpropagation.
Evaluation Protocol: Zero-shot 3D shape classification is evaluated by mapping test shapes to embeddings and matching against class text embeddings or image embeddings. Top-1, top-3, and top-5 accuracies are reported on multiple benchmarks. Cross-modal retrieval experiments further qualitatively validate embedding consistency. Multiple ablations examine loss variants, the effect of multiple positive views, adapter impact, and batch sizes.
Reproducibility: The paper states datasets are adopted from prior works, architectures like PointBERT are publicly available, and CLIP encoders are frozen pretrained models. Details on code release or exact seeds are not provided in the truncated text, so reproducibility may require implementation from main paper and supplements.
Example: Consider a single training triplet: a 3D point cloud of an object, multiple images from different viewpoints, and multiple text captions (human annotation, caption generated from images, retrieved web caption). The point cloud encoder generates a feature vector that is normalized. The multiple image and text encoders (frozen) produce normalized embeddings for each view or caption. During training, the decoupled multi-positive contrastive loss pulls the point cloud embedding to align closely with all its image and text positives while pushing away embeddings of other shapes in the batch (negatives) with competitive weighting. The lightweight text adapter modifies only the retrieved caption embeddings to better fit the shared space. Over many such triplets and batches, this encourages the 3D encoder to learn a holistic, multi-modal representation that generalizes to unseen categories and rare classes.
Technical innovations
- Decoupled multi-positive contrastive loss that separates multi-positive alignment from negative sample separation, preserving hardness-aware negative mining in multi-view multi-text settings.
- Hardness-aware weighting function for positive alignment terms to focus learning on harder positive anchors for stable convergence.
- Lightweight trainable MLP adapter module applied exclusively to noisy retrieved web caption embeddings to reduce domain gap with in-domain annotations.
- Holistic multi-modal alignment approach that jointly aligns 3D point clouds with multiple images and multiple text descriptions for improved open-set long-tail recognition.
Datasets
- ShapeNetCore — 52,470 triplets — publicly available CAD dataset
- 3D-FUTURE — size not explicitly stated — publicly available 3D dataset
- ABO — size not explicitly stated — publicly available 3D assets dataset
- Objaverse — 875,665 multi-modal triplets total, including Objaverse-LVIS subset
- Objaverse-LVIS — 46,832 shapes, 1156 categories — derived from LVIS annotated subset
- ScanObjectNN — real scanned objects, 15 categories — public benchmark
- ModelNet40 — 40 categories — public CAD dataset
Baselines vs proposed
- OpenShape-PointBERT (32.3M params): Objaverse-LVIS top-1 accuracy = 46.8% vs HOLA-PointBERT (72.1M params) = 50.7%
- TAMM-PointBERT (35.4M params): Objaverse-LVIS top-1 accuracy = 50.7% vs HOLA-PointBERT (32.3M params) = 50.3%
- VIT-LENS-G (2000M params): Objaverse-LVIS top-1 accuracy = 50.1% vs HOLA-PointBERT (32.3M params) = 50.3%
- UNI3D-G (1020M params): Objaverse-LVIS top-1 accuracy = 47.2% vs HOLA-PointBERT (72.1M params) = 50.7%
- MixCon3D-PointBERT (30.9M params): Objaverse-LVIS top-1 accuracy = 50.4% vs HOLA-PointBERT (32.3M params) = 50.3% (competitive performance with fewer FLOPs)
- HOLA achieves up to 202 FPS inference speed vs. baselines from 27 to 85 FPS on same benchmarks
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.01334.
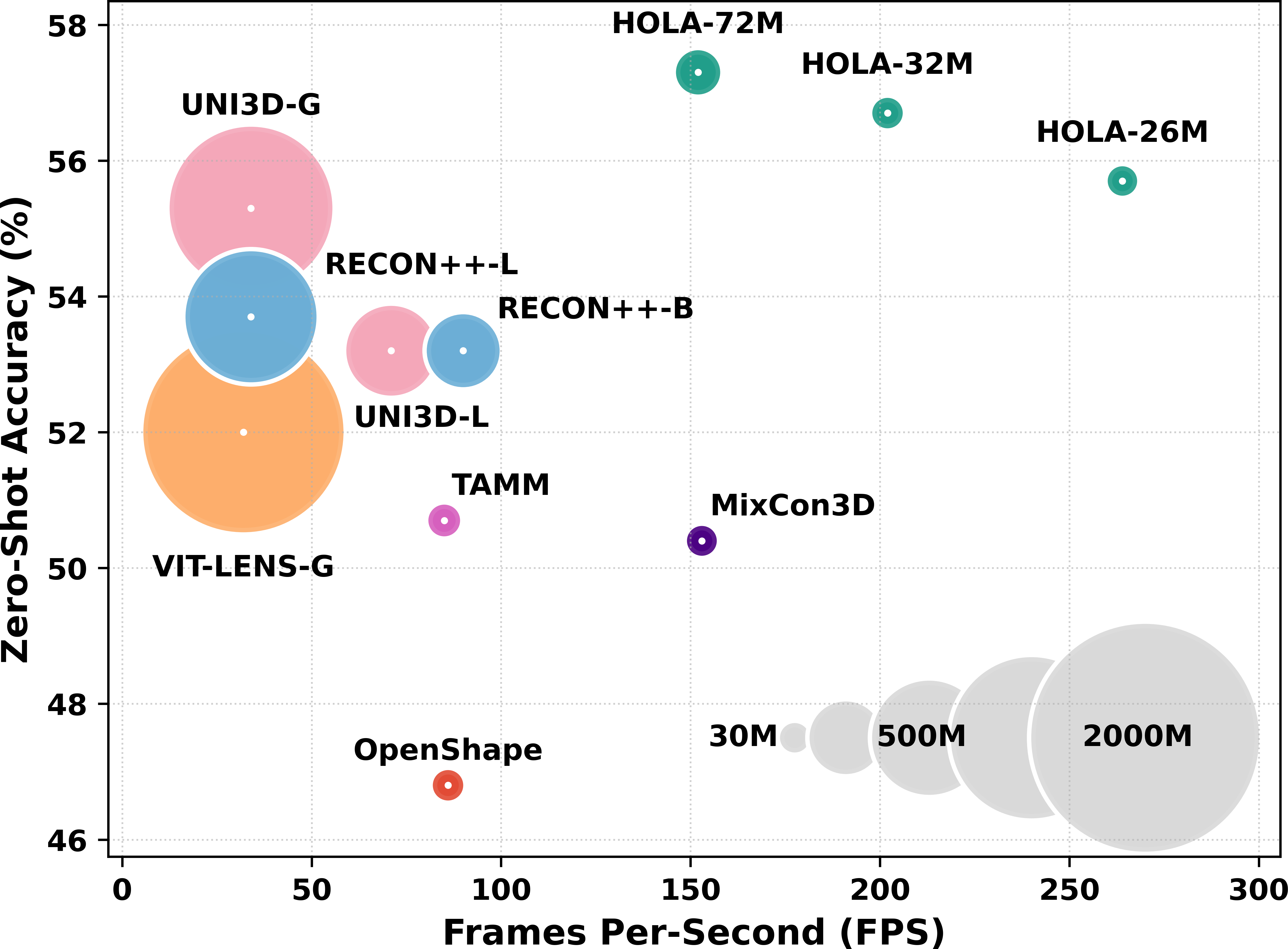
Fig 1: (a) The plot shows that our models (in teal) achieve higher accuracy (vertical axis) and

Fig 2: Input Triplets. Each training triplet consists of a point cloud, a set of rendered images,

Fig 3: It comprises three encoders, one for each modality. The image and text encoders are kept

Fig 4 (page 4).
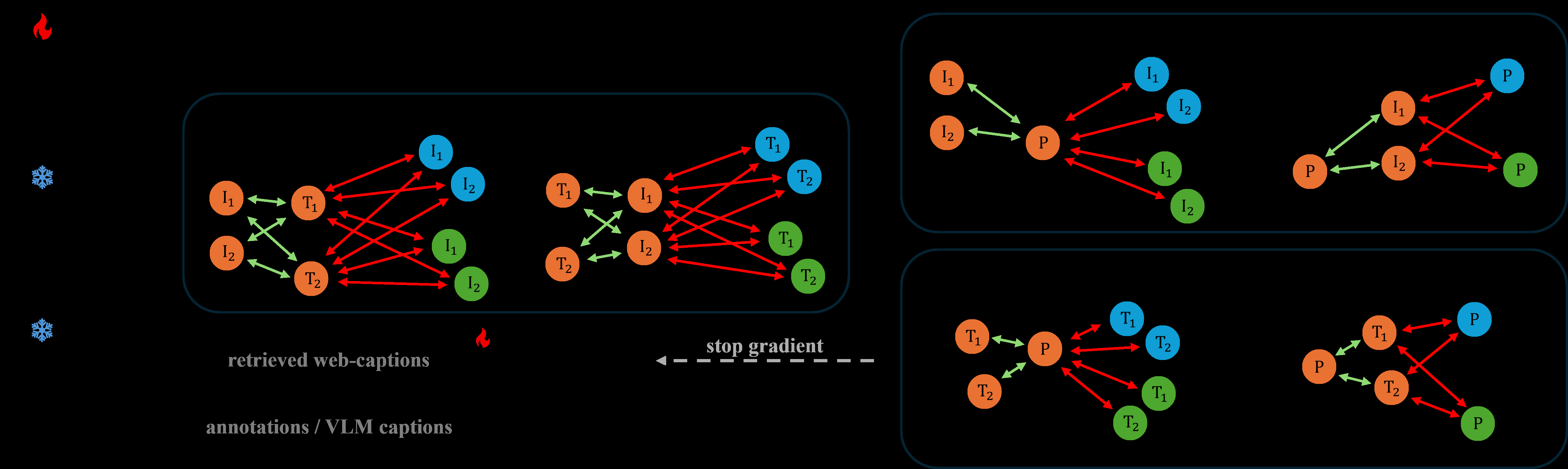
Fig 4: Effect of the “spotlight crowding” phenomenon. As views increase, the naive MP loss
Fig 6 (page 7).

Fig 5: Text-to-3D retrieval for common (head) categories. Each retrieved result is shown as a

Fig 6: Text-to-3D retrieval for rare (tail) categories. Each retrieved result is shown as a pair: an
Limitations
- The method relies on availability of multiple images and texts per 3D shape—datasets or domains lacking this modality richness may see degraded benefits.
- The domain gap reduction technique applies only to retrieved web captions and assumes access to such noisy but diverse data.
- While the loss decoupling addresses multiple positives, it is unclear if extremely large numbers of positives (e.g., hundreds) have been tested for scalability.
- Results focus on zero-shot and retrieval tasks; robustness against adversarial or out-of-distribution inputs is not evaluated.
- Training requires multi-modal paired data which may be costly to assemble at scale across diverse real-world domains.
- The lightweight 3D backbones used yield state-of-the-art results but performance on very large or high-resolution point clouds is not discussed.
Open questions / follow-ons
- How does the decoupled multi-positive contrastive loss scale to very large numbers of positive views or texts per instance?
- Can this holistic multi-modal alignment approach improve robustness to adversarial or corrupted sensor inputs in 3D recognition?
- What are the impacts of different backbone architectures or larger 3D encoders integrated with this loss function?
- Could unsupervised or self-supervised pretraining with the proposed loss further improve long-tail generalization?
Why it matters for bot defense
Bot-defense systems and CAPTCHA designs that rely on 3D object recognition or shape understanding could benefit from the proposed holistic multi-modal alignment to improve recognition accuracy on rare or unseen categories. The decoupled multi-positive contrastive loss provides a blueprint for integrating multiple complementary signals (e.g., different views or descriptions) while preserving focus on hard negative examples—an important property for robust discriminator training.
Furthermore, the lightweight text adapter concept may inspire improved handling of noisy text annotations in vision-language models used for understanding user inputs or challenges requiring semantic matching. The approach’s compact model size and high inference speed are advantageous for deployment in latency-sensitive bot-detection scenarios where computational resources are constrained. However, practical integration requires availability of multiple 2D views and textual descriptions aligned with 3D objects, which may limit applicability depending on available data modalities in the bot-defense pipeline.
Cite
@article{arxiv2606_01334,
title={ HOLA: Holistic Multi-Modal Alignment for Open-Set 3D Recognition },
author={ Koby Aharonov and Oren Shrout and Ayellet Tal },
journal={arXiv preprint arXiv:2606.01334},
year={ 2026 },
url={https://arxiv.org/abs/2606.01334}
}