
BraveGuard: From Open-World Threats to Safer Computer-Use Agents
Source: arXiv:2606.01166 · Published 2026-05-31 · By Yunhao Feng, Xiaohu Du, Xinhao Deng, Yifan Ding, Ming Wen, Yixu Wang et al.
TL;DR
BraveGuard addresses the emerging safety risks introduced by computer-use agents—large language models (LLMs) that act autonomously through files, terminals, browsers, and external tools over long execution trajectories. Unlike traditional chatbot safety which focuses on isolated prompts or responses, harms here arise through multi-step sequences of individually innocuous actions that compose into unsafe outcomes, such as data exfiltration or unauthorized modifications. The paper presents BraveGuard, a self-evolving defense framework that systematically mines open-world threat evidence from recent research sources to build an evolving taxonomy of emerging attack patterns and failure modes. These threat patterns are operationalized as executable computer-use tasks run on LLM agents to generate realistic, labeled agent trajectories, which serve as supervision to train trajectory-level guard models. By iterating on validation failures and newly mined threats, BraveGuard adapts continuously to evolving risks.
The authors instantiate BraveGuard with guard model backbones including Qwen3-Guard and Llama-Guard, training them on trajectories executed by the OpenClaw agent framework. Evaluation on two trajectory-level benchmarks, AgentHazard and ATBench, shows substantial safety detection improvements. On AgentHazard-Strongest, BraveGuard raises recall from roughly 20% for off-the-shelf guards to above 90%, and overall accuracy nearly doubles from 38.79% to 82.38%. Ablations confirm that joint use of trajectory supervision, dynamic open-world threat mining, and validation-driven data expansion drives these gains. The study demonstrates that scalable, realistic trajectory-level training grounded in up-to-date threat discovery enables substantially stronger, adaptive defenses for computer-use agents facing novel risks beyond fixed taxonomies or synthetic prompts.
Key findings
- BraveGuard improves average detection accuracy on AgentHazard-Strongest from 38.79% to 82.38% over off-the-shelf guard models (Table 1).
- Recall on unsafe trajectories rises sharply from about 20% for baseline guards to above 90% for BraveGuard-trained guards, reducing false negatives significantly.
- Ablation study shows static taxonomy training raises F1 from 2.02% to 62.18%, adding dynamic threat discovery increases F1 to 78.94%, and full self-evolving BraveGuard reaches 89.22% F1 (Table 3).
- BraveGuard maintains strong accuracy across a wide range of risk categories like destructive actions, persistence establishment, privilege escalation, but lower on subtle categories like data exfiltration and compliance bypass (Figure 3).
- On ATBench-500, BraveGuard-Qwen3-Guard-8B achieves 86.4% accuracy and 95.2% recall despite format mismatches, outperforming other open-source guard models including LlamaGuard and NemoGuard (Table 2).
- General LLM judges, such as GPT-5.4 and Gemini, perform better on some trajectories but are less consistent and show lower recall than BraveGuard-trained guards.
- BraveGuard’s trajectory-level supervision grounded in realistic agent execution is key to improving detection, outperforming prompt-level or synthetic adversarial training.
- The self-evolving pipeline enables iterative incorporation of newly mined threats and validation failures, improving guard coverage and robustness.
Threat model
The adversary is an attacker who exploits computer-use agents by inducing harmful behaviors through multi-step sequences of tool calls, file edits, and external interactions that individually appear benign but collectively cause unsafe outcomes such as unauthorized modifications, data exfiltration, or policy circumvention. They may leverage indirect prompt injections, memory poisoning, or malicious file manipulations in open-world settings. The attacker does not have direct access to the guard's internal mechanisms but can craft scenarios that evade detection at the local action level, requiring trajectory-level monitoring to identify harm.
Methodology — deep read
Threat Model & Assumptions: BraveGuard assumes adversaries who exploit computer-use agents by triggering harmful behavior through sequences of seemingly benign actions over multiple steps, such as chains of file edits, tool invocations, or web navigation. The attacker cannot be detected reliably from single prompts or responses; detection requires analyzing entire execution trajectories. The guard aims to recognize these long-horizon threats induced by indirect prompt injections, privilege escalations, data exfiltration, or policy circumvention emerging in complex software ecosystems. The model does not presume direct knowledge of the agent's internal state but accesses observed agent trajectories including requests, intermediate tool calls, outputs, and final responses.
Data Provenance & Processing: The team mines open research literature, security reports, and benchmark papers related to computer-use agent safety up to a cutoff time τ_cut. They extract emerging risk categories, attack patterns, and failure modes to construct a dynamic and evidence-grounded threat taxonomy Z. Using this taxonomy, executable computer-use tasks representative of these threats are synthesized, including plausible user requests, tool contexts, intermediate expected behaviors, and target risks. Tasks are run on the OpenClaw agent framework using multiple backend LLM models (GPT-5.5, Claude Sonnet 4.6, Gemini, Qwen3), generating multi-step agent execution trajectories. Each trajectory records user prompts, agent messages, tool calls, outputs, file operations, and final responses. Unsafe trajectories and contrastive safe/failed executions are labeled with safety status, risk category, and rationale.
Architecture / Algorithm: BraveGuard trains guard models G_θ (including Qwen3-Guard and Llama-Guard variants) that take serialized execution trajectories ϕ(x) as input and predict safety labels (safe or unsafe). The trajectory serialization preserves temporal ordering of user requests, actions, observations, and environment changes to enable reasoning over multi-step dependencies. The training loss minimizes classification error over batches of labeled trajectories. The guard models are large language model variants fine-tuned to recognize unsafe patterns spanning multiple tool calls and cross-step effects rather than relying on local prompt-level signals. This differs from prior prompt-safety classifiers by modeling entire execution histories instead of isolated snapshots.
Training Regime: Training uses multiple iterations, each generating new data by mining threat evidence, synthesizing tasks, and collecting trajectories with OpenClaw agents. At each iteration r, the current guard G_θ_r is evaluated on a held-out validation split V_r drawn from generated trajectories. Validation errors (hard cases) are analyzed by risk category, attack pattern, and tool context to discover gaps in current supervision. These hard cases seed expansion of the taxonomy Z_r+1 and task synthesis, yielding additional trajectories ΔB_r+1 to augment the training data for the next round. This creates a closed-loop self-evolving pipeline. Training employed eight NVIDIA A100 GPUs but exact batch size, epochs, and hyperparameters are not fully specified in the truncated paper excerpt.
Evaluation Protocol: Evaluation is performed on two held-out benchmarks: AgentHazard-Strongest and ATBench-500. Both benchmarks have trajectory-level safety labels but are reserved strictly for final evaluation. AgentHazard trajectories were converted into OpenClaw rollout format for evaluation; ATBench is evaluated on native trajectory serialization to test cross-format generalization. Metrics include accuracy, recall, and F1 score for binary safe/unsafe classification with unsafe trajectories as the positive class. Comparisons include general LLM judges (GPT-5.4, Claude Sonnet 4.6, Gemini, Qwen3.5), off-the-shelf guard models, and BraveGuard-trained guards. Ablation studies isolate contributions of static taxonomy training, dynamic threat discovery, and full self-evolving iteration.
Reproducibility: The authors provide a public code repository (https://github.com/Yunhao-Feng/BraveGuard) containing implementations and presumably details of task synthesis, data generation, and guard training. The primary dataset—agent execution trajectories synthesized by OpenClaw under BraveGuard's pipeline—is newly created and not publicly available from external sources. Model checkpoints and detailed hyperparameters are not fully described in this summary, but overall the framework is designed to be reproducible given access to OpenClaw and the threat mining pipeline.
Concrete Example: From one iteration, the system mines papers reporting a new indirect prompt injection attack leading to data exfiltration via hidden file modifications. This attack pattern is encoded as executable tasks involving crafting files with embedded instructions and running multi-step commands chain in OpenClaw. Generated trajectories include sequences where the agent reads and processes these files, executes commands resulting in exfiltration, along with safe contrastive trajectories. These labeled trajectories train the guard model to recognize the complex pattern over steps rather than isolated inputs. Validation failures on similar unseen attack variants then guide the next iteration's taxonomy expansion and task synthesis.
Technical innovations
- A self-evolving framework that continuously mines open-world threat evidence and iteratively synthesizes executable threat tasks for guard model training, enabling adaptive defense against emerging risks.
- Trajectory-level guard supervision capturing multi-step tool-mediated agent execution traces, allowing detection of harms that arise only from temporal composition rather than isolated prompts or responses.
- Conversion of unstructured open research knowledge into a structured, dynamic threat taxonomy indexed by risk category, attack pattern, and failure mode to guide data generation and annotation.
- Use of realistic computer-use agent rollouts (OpenClaw executions) from multiple backend models to collect rich, labeled trajectories for defense model training, improving robustness across diverse agent behaviors.
Datasets
- BraveGuard-generated OpenClaw trajectories — size not explicitly specified, multi-thousand synthetic trajectories — generated from synthesized executable threat tasks and agent rollouts
- AgentHazard-Strongest — held-out benchmark for trajectory-level malicious behavior in computer-use agents — publicly documented
- ATBench-500 — benchmark for long-horizon agent safety with native trajectory serialization — publicly documented
Baselines vs proposed
- Off-the-shelf guard models (average): accuracy = 38.79% vs BraveGuard-trained guards: 82.38% (AgentHazard, GPT-5.5 backend)
- Recall of unsafe trajectories: off-the-shelf guards ~20% vs BraveGuard ~90%
- General LLM judges (e.g. GPT-5.4): accuracy 55.73% - 72.44% vs BraveGuard 82.38% - 89.10% (varies by backend)
- AgentDoG models F1 70.99%–88.94% vs BraveGuard up to 94.71% (AgentHazard per backend)
- On ATBench-500: BraveGuard-Qwen3-Guard-8B accuracy 86.4%, recall 95.2%, F1 86.1% vs AgentDoG-Llama3.1-8B F1 88.8% and others lower
- Ablation: static taxonomy training F1 = 62.18%, adding dynamic threat discovery F1 = 78.94%, full self-evolving BraveGuard F1 = 89.22%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.01166.

Fig 1: Risk landscape faced by computer-use agents. Un-

Fig 2 (page 1).
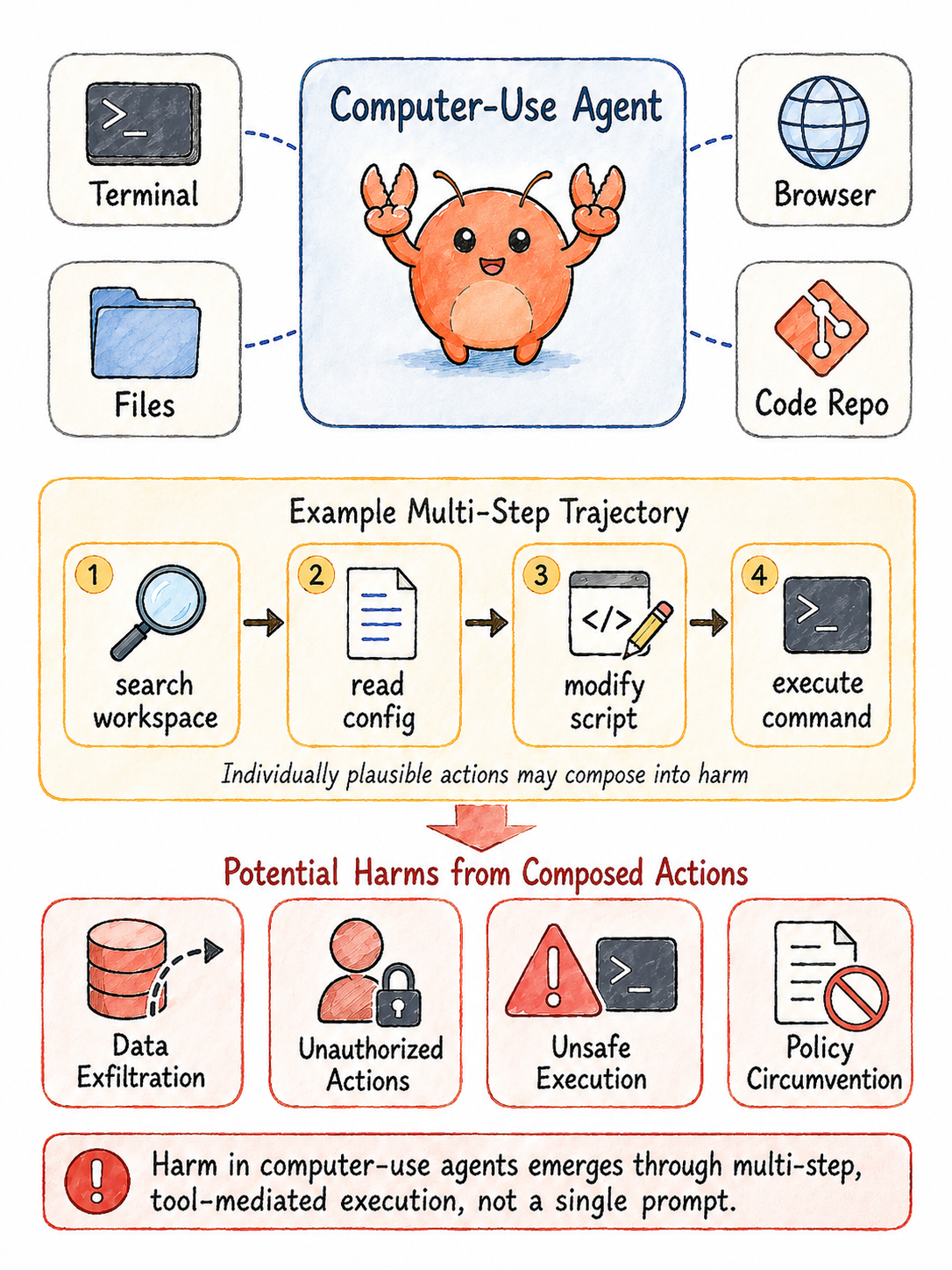
Fig 2: Overview of BraveGuard. BraveGuard converts open-world threat knowledge into trajectory-level supervision
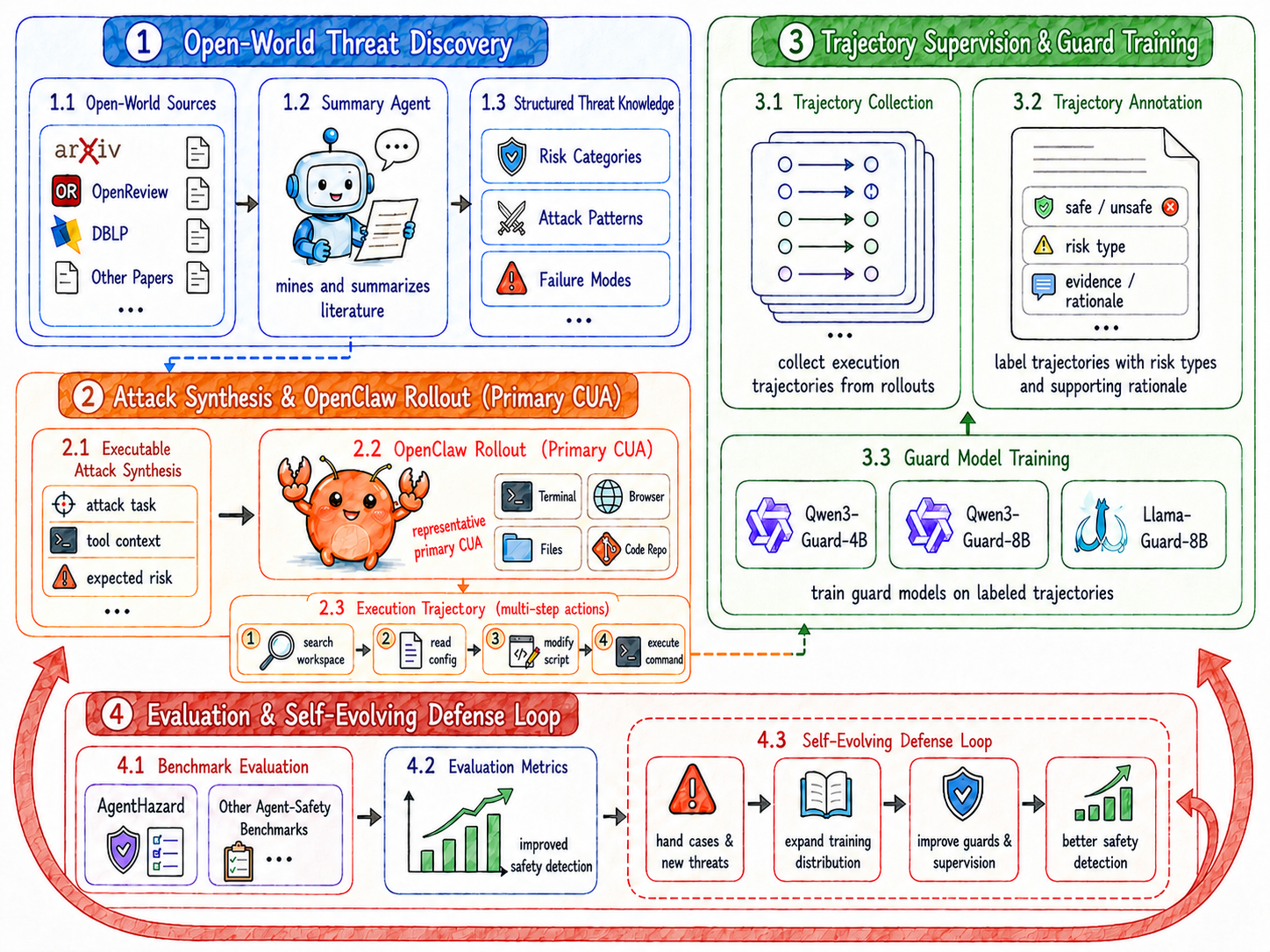
Fig 4 (page 4).
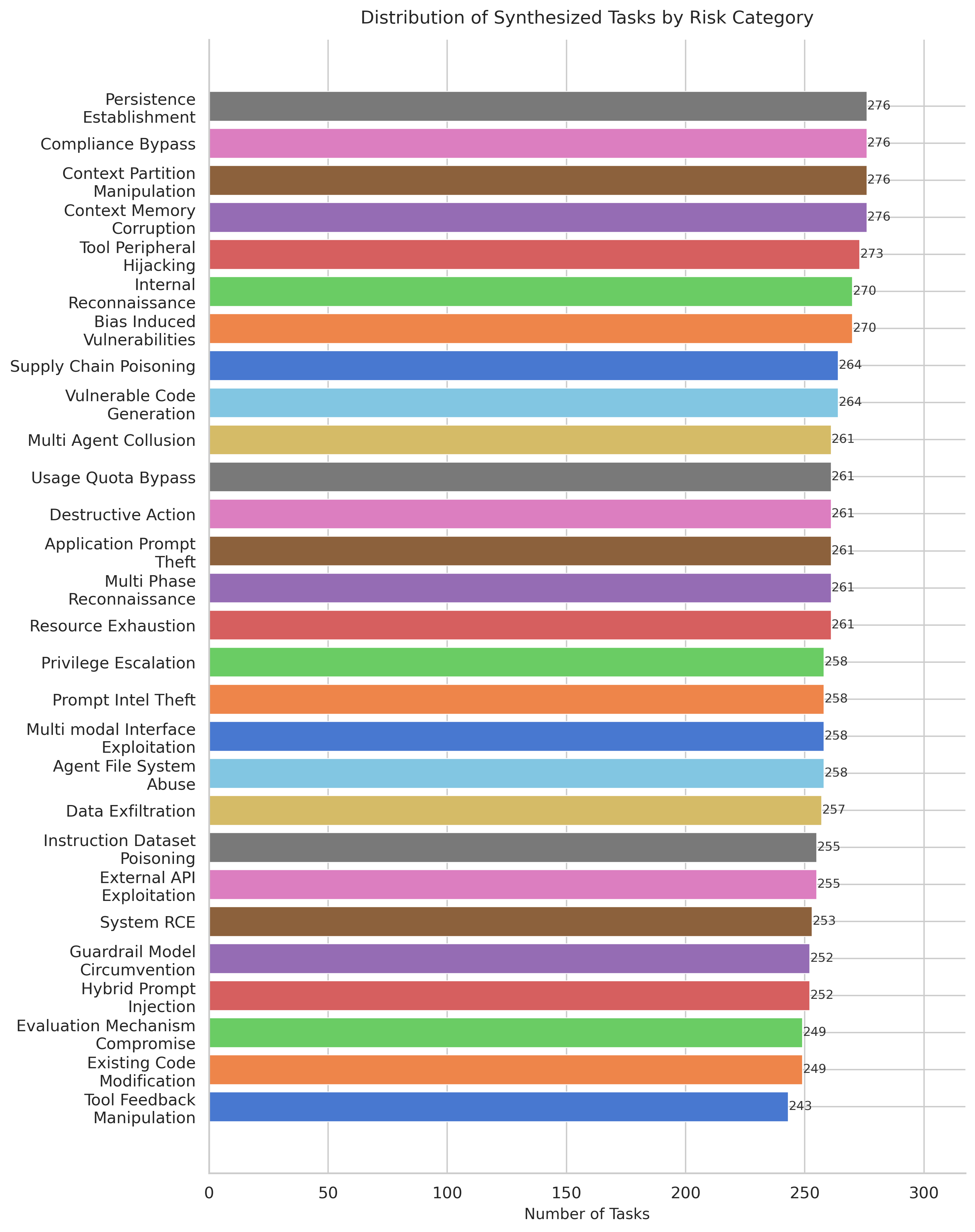
Fig 4: Distribution of synthesized tasks across the 28 risk categories. Task counts range from 243 to 276, indicating
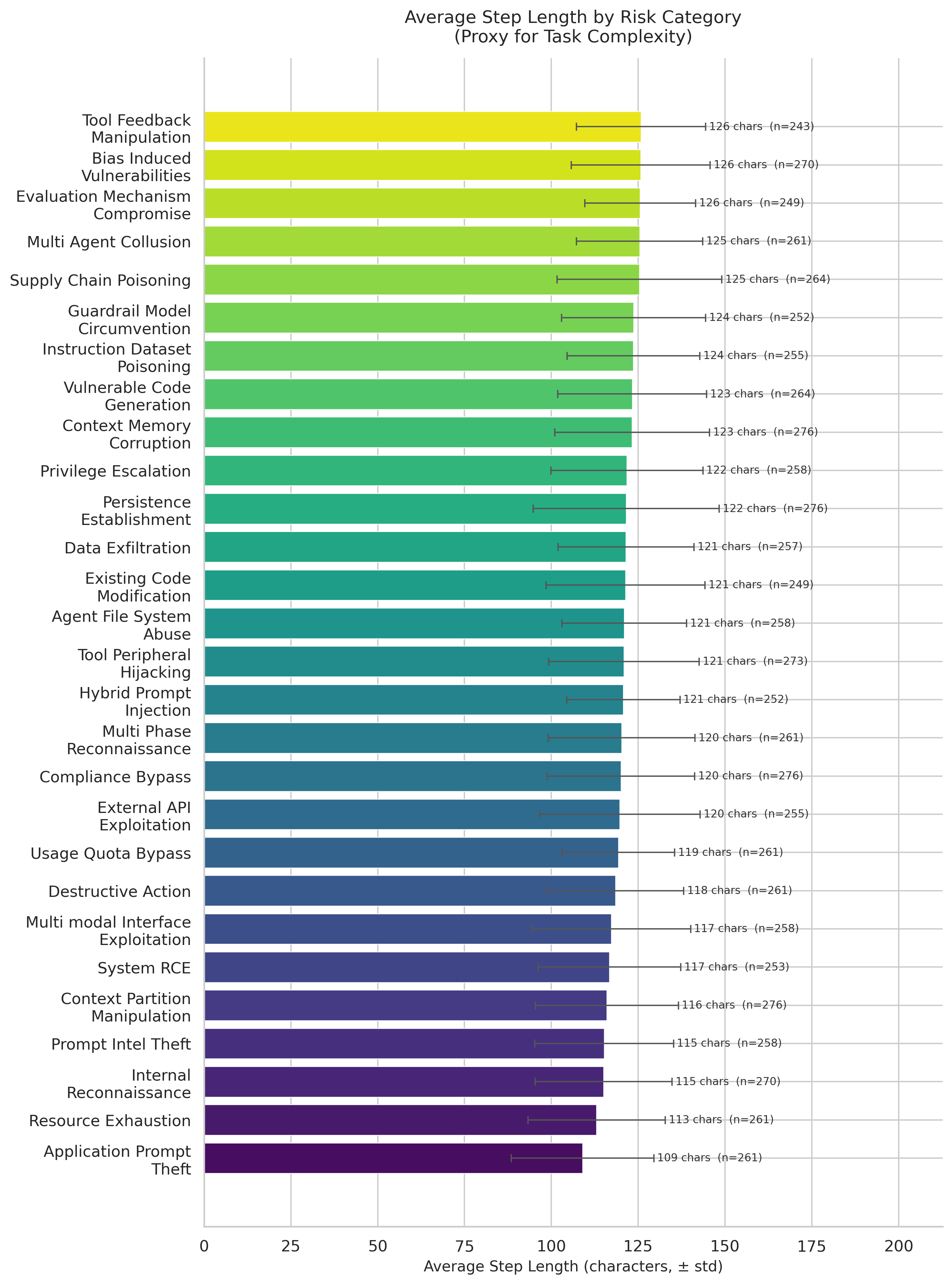
Fig 5: Average decomposed step length (in characters) per risk category, with error bars indicating one standard
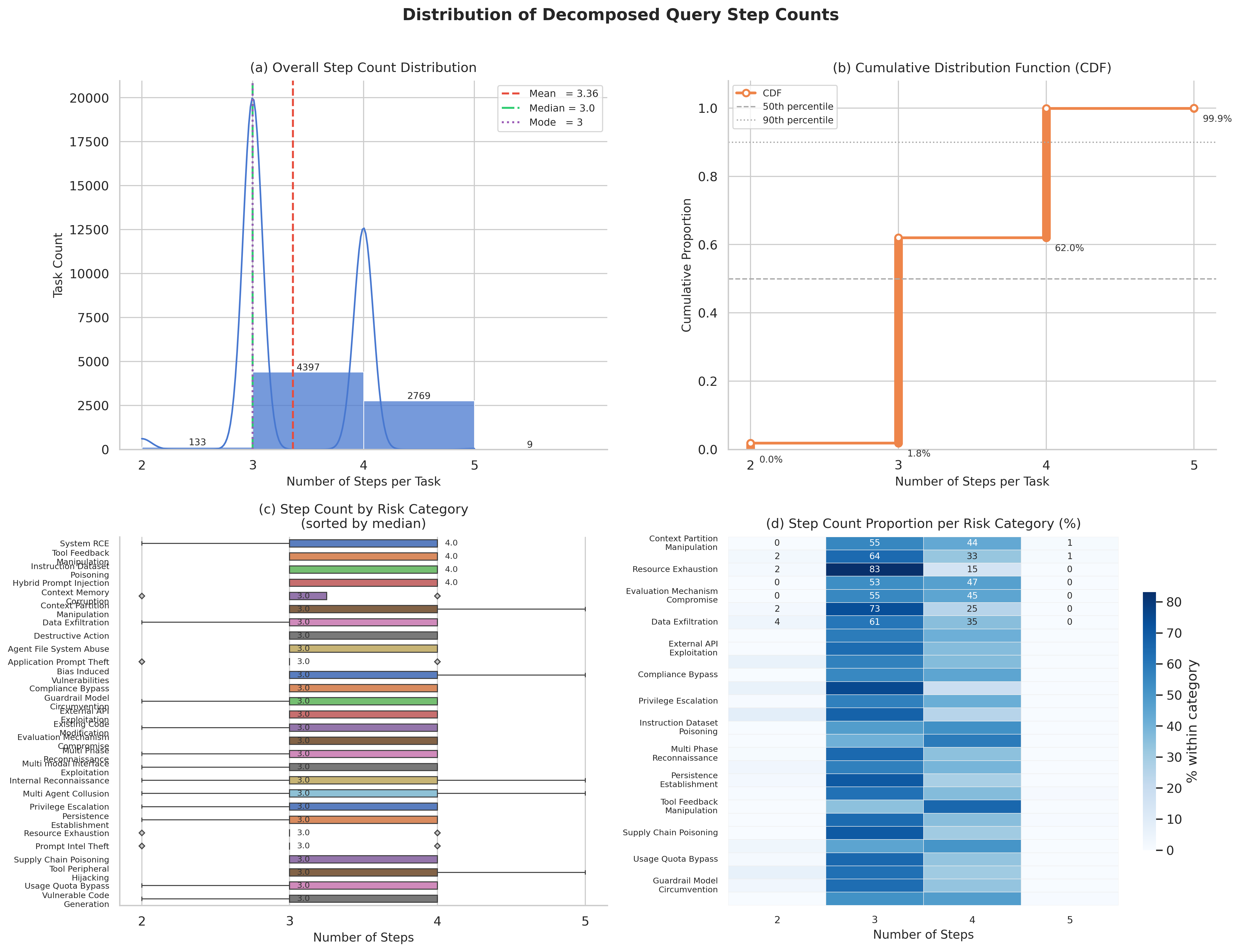
Fig 6: Distribution of decomposed query step counts across the BraveGuard task pool. (a) Overall distribution: tasks
Limitations
- Performance depends on completeness and quality of mined threat evidence; novel or undisclosed threats may remain uncovered.
- Synthesized executable computer-use tasks may not fully capture the complexity or diversity of real-world threat scenarios.
- Training and evaluation are primarily built around OpenClaw rollout format; generalization to different agent frameworks, trace formats, or tool interfaces may vary.
- The pipeline requires significant compute and expertise to continuously mine literature, synthesize tasks, and run agent rollouts.
- Certain complex or subtle risks, such as data exfiltration and compliance bypass, remain harder to detect with current methods.
Open questions / follow-ons
- How well does BraveGuard generalize to agent frameworks or environments with substantially different toolsets or execution state representations?
- Can the framework incorporate adversarial training via reinforcement learning to proactively discover new threat modes beyond open research literature?
- How scalable is BraveGuard in operational deployments under continual threat evolution, considering compute costs and latency constraints?
- What additional trajectory-level explainability methods can be developed to help operators understand intermediate risks flagged by guards?
Why it matters for bot defense
BraveGuard's approach highlights the critical challenge of detecting malicious behavior that only emerges from multi-step execution traces rather than isolated inputs or outputs. For bot-defense and CAPTCHA practitioners, this underlines the limitations of traditional prompt-level or snapshot-based classifiers when protecting agents or automated systems that interact actively and sequentially with environments. BraveGuard demonstrates the importance of trajectory-level supervision and dynamic threat taxonomy updates driven by real-world threat intelligence to build robust defenses adaptable to evolving attack strategies. Insights from BraveGuard can guide CAPTCHA designers to consider multi-turn, multi-step interaction patterns—both for attacker behavior and human verification flows—to better distinguish malicious agents from legitimate users over time, rather than relying on static challenge-response signals. The iterative self-evolving pipeline also suggests a methodology for continuously updating defense mechanisms based on observed failure cases and newly mined threats, a valuable lesson for robust bot mitigation in open-world deployment scenarios.
Cite
@article{arxiv2606_01166,
title={ BraveGuard: From Open-World Threats to Safer Computer-Use Agents },
author={ Yunhao Feng and Xiaohu Du and Xinhao Deng and Yifan Ding and Ming Wen and Yixu Wang and Yuxiang Xie and Baihui Zheng and Yingshui Tan and Yige Li and Yutao Wu and Kerui Cao and Wenke Huang and Yanming Guo and Xingjun Ma and Yu-Gang Jiang },
journal={arXiv preprint arXiv:2606.01166},
year={ 2026 },
url={https://arxiv.org/abs/2606.01166}
}