
ANDES: Agent Native Data Evolving Synthesis Tool for Autonomous Instruction Alignment
Source: arXiv:2606.01279 · Published 2026-05-31 · By Zhengyang Zhao, Shengjie Ye, Lu Ma, Hao Liang, Hengyi Feng, Wentao Zhang
TL;DR
This paper addresses the challenge of autonomous post-training alignment of large language models (LLMs) by tackling the critical bottleneck of high-quality data acquisition. Current autonomous agents tasked with transforming base LLMs into aligned assistants struggle due to limitations in their ability to search, filter, and balance diverse datasets from noisy web sources. Prior synthetic data pipelines are often static, non-interactive, and unable to adapt dynamically to ongoing training needs. To overcome these limitations, the authors propose Andes, an Agent Native Data Evolving Synthesis framework that treats data generation as a plug-and-play agent skill enabling closed-loop interactive data synthesis. Andes uses a self-evolving hierarchical World Tree routing mechanism combined with diagnostic synthesis reports that allow trainer agents— even relatively weak ones—to steer data generation toward aligned, diverse, and capability-targeted training samples in an iterative manner. Through extensive evaluation on PostTrainBench and additional benchmarks, Andes significantly boosts autonomous post-training performance to state-of-the-art levels under compute constraints and base model limitations. It improves not only raw accuracy but also cross-task generalization and data diversity, surpassing strong baselines and prior agent-driven post-training pipelines.
Key findings
- Andes improves GLM-4.7 agent average autonomous post-training accuracy on PostTrainBench from 7.48% (baseline) to 33.39%, a +25.86% absolute gain.
- Outperforms strongest existing agent method Opus-4.7 (xHigh) by 4.83% average accuracy (33.39% vs 28.56%).
- Directed routing in World Tree shifts data synthesis focus towards target-aligned topics, increasing fusion-track data ratio up to ~60% over time (Fig 3a).
- Node evolution continually expands topical subtrees, rising cumulative new themes/scenarios to preserve training diversity even as sampling concentrates (Fig 3c).
- Removing report-driven interaction drops performance from 30.39% to 26.80%, showing iterative feedback loop improves data quality and diversity.
- Integration of Andes tool beats just a custom trainer scaffold which alone boosts average from 7.11% to 21.56%, confirming Andes drives a second wave of gains (Fig 5).
- Performance gains consistent across different base models including Qwen3-1.7B, Qwen3-4B, SmolLM3-3B, and Gemma-3-4B.
- Andes achieves +48% absolute improvement on BFCL and +49% on GSM8K benchmark versus base zero-shot models.
Threat model
The adversary is the inherent difficulty of autonomously curating high-quality, diverse training data from noisy open web sources under limited agent capabilities. The post-training agent cannot perfectly parse, filter, or balance raw web datasets; Andes assumes no malicious adversarial manipulation but addresses cascading failures caused by data quality degradation and distribution mismatch that impair model alignment.
Methodology — deep read
Threat Model & Assumptions: The threat model focuses on the autonomous post-training phase where a trainer agent—potentially foundationally weak—must autonomously generate high-quality training data aligned with downstream evaluation benchmarks. The adversary is implicitly the noisy, unstructured web from which typical agents attempt to curate training data, where challenges include noise, imbalance, and diversity collapse. The approach assumes no direct adversarial manipulation but addresses intrinsic data quality and distribution issues limiting autonomous training performance.
Data: Training data is synthesized by Andes itself through multi-round interactions. The core data structure is the 'World Tree', a hierarchical topic-theme-scenario taxonomy starting with approximately 72 topics, 394 themes, and 1,182 scenarios at initialization. Each round produces batches of question-answer (QA) pairs configured per targeted capability dimension (tasks are decomposed into macro capability domains). Data quality is dynamically measured via diagnostic reports assessing logical diversity, effort score, and topical alignment. Benchmarked on PostTrainBench plus 5 additional unseen benchmarks covering math, coding, medical dialogue, scientific QA, and creative writing.
Architecture / Algorithm: Andes is implemented as a plug-and-play agent skill comprising four stages: (1) Target-driven agent request decomposes the benchmark objectives into capability domains, encoding task descriptions (τ), sample budgets (N), and format protocols (φ). (2) Self-evolving Dynamic World Tree Routing samples topics weighted by alignment scores, then picks associated themes and scenarios for two generation tracks: fusion (strong alignment) or generic (weak). Sampling weights (w_t) are updated iteratively based on sample suitability scores from a Router LLM. Node evolution expands topic subtrees dynamically to prevent diversity collapse.
(3) Two-stage data synthesis: Stage 1 generates raw QA pairs via sequential LLM calls conditioned on routing configuration r_i; fusion track samples receive stronger constraints aligned to τ, while generic track samples focus on broad context. Stage 2 refines QA pairs via a Refiner LLM which critiques each sample and produces an effort score; heavily defective samples are filtered out. Refined samples are also checked batch-wise for logical collapse to suppress repetitive reasoning templates.
(4) Outputs and feedback: The agent receives the refined dataset and a structured synthesis report summarizing topic distributions, logical diversity, and acceptance ratios. This drives the next round’s input configuration (τ_{j+1}, N_{j+1}, φ_{j+1}) via a closed feedback loop to improve alignment and data diversity.
Training Regime: Experiments run in a sandbox environment on a single GPU with a 10-hour wall-clock constraint per training session. Multiple base models tested, including GLM-4.7 and Qwen variants. Batch sizes and sample budgets vary per capability dimension configured by the trainer agent. The trainer agent uses a custom CLI scaffold to orchestrate calls to Andes and downstream training.
Evaluation Protocol: Primary evaluation is on PostTrainBench, measuring relative performance improvements on seven benchmarks spanning math (GSM8K, AIME), coding (HumanEval), tool use (BFCL), scientific QA (GPQA-Main), medical dialogue (HealthBench), and open-ended writing (ArenaHard). Metrics are task-specific accuracies or benchmarks’ official metrics. Baselines include base zero-shot models, standard agents with conventional data acquisition pipelines, and agents equipped with the custom scaffold but without Andes. Ablations isolate the effect of Andes components such as report-driven interaction. Visualizations and analyses (Fig 3,5) elucidate routing dynamics and node evolution.
Reproducibility: The codebase is publicly released at https://github.com/zzy1127/ANDES. Benchmarks used are public or standard (PostTrainBench, GSM8K, HumanEval, etc.). Full training configurations and scaffold details are documented in the appendix. Exact frozen model weights for Andes components are not explicitly stated but likely reproducible.
Example end-to-end: The trainer agent decomposes a benchmark (e.g., GSM8K) into math reasoning capability, initiates Andes call with task description τ and sample budget N. Andes samples topics from World Tree, routes scenarios based on alignment, and generates initial QA pairs. The Refiner critiques them, filters defective pairs, and produces a synthesis report highlighting logical repetition and diversity. The trainer reads the report, adjusts τ and N accordingly, and calls Andes again to steer the data generation towards under-covered scenario themes, iterating multiple rounds. The final accumulated data is used to fine-tune the base LLM, resulting in a +51.61% absolute improvement in GSM8K accuracy vs zero-shot.
Technical innovations
- Reconceptualizing data synthesis for autonomous agent post-training as a plug-and-play agent skill with a standardized interactive interface.
- Introducing a self-evolving hierarchical World Tree routing mechanism that dynamically weights, routes, and expands scenario nodes to maintain target alignment and diversity.
- A two-stage data synthesis pipeline combining scenario-conditioned constrained QA generation and an LLM-based refinement and logical diversity assessment layer.
- A closed feedback loop wherein diagnostic synthesis reports actively guide the trainer agent’s iterative adjustments to task descriptions and sample budgets, enhancing data quality over multiple rounds.
Datasets
- PostTrainBench — multiple benchmarks, standard public benchmark for autonomous post-training evaluation
- GSM8K — math word problem dataset, ~8.5k samples
- HumanEval — code generation benchmark, publicly available
- AIME 2025, ArenaHardWriting, BFCL, GPQA-Main, HealthBench — varied task domains, publicly referenced benchmarks
Baselines vs proposed
- GLM-4.7 (OpenCode CLI baseline): average accuracy = 7.48% vs Andes-equipped GLM-4.7: 33.39%
- Opus-4.7 (xHigh): 28.56% average accuracy vs Andes: 33.39% (+4.83% absolute)
- GLM-4.7 (Scaffold-only): 21.56% vs Andes (full system): 33.39% (+11.83%)
- Andes without interaction mechanism: 26.80% vs full Andes with interaction: 30.39%
- Base Models zero-shot average: 7.53% vs Andes on GLM-4.7: 33.39% (post-training improvement)
- Significant benchmark-specific gains: BFCL boosted +48.21% (12.81%→56.14%), GSM8K +51.61% (20.43%→72.04%)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.01279.
Fig 1: Andes achieves SOTA performance on PostTrainBench. Compared to the bare execution

Fig 2: Overview of Andes. Guided by the Andes skill, a trainer agent decomposes downstream

Fig 3 (page 4).

Fig 4 (page 4).
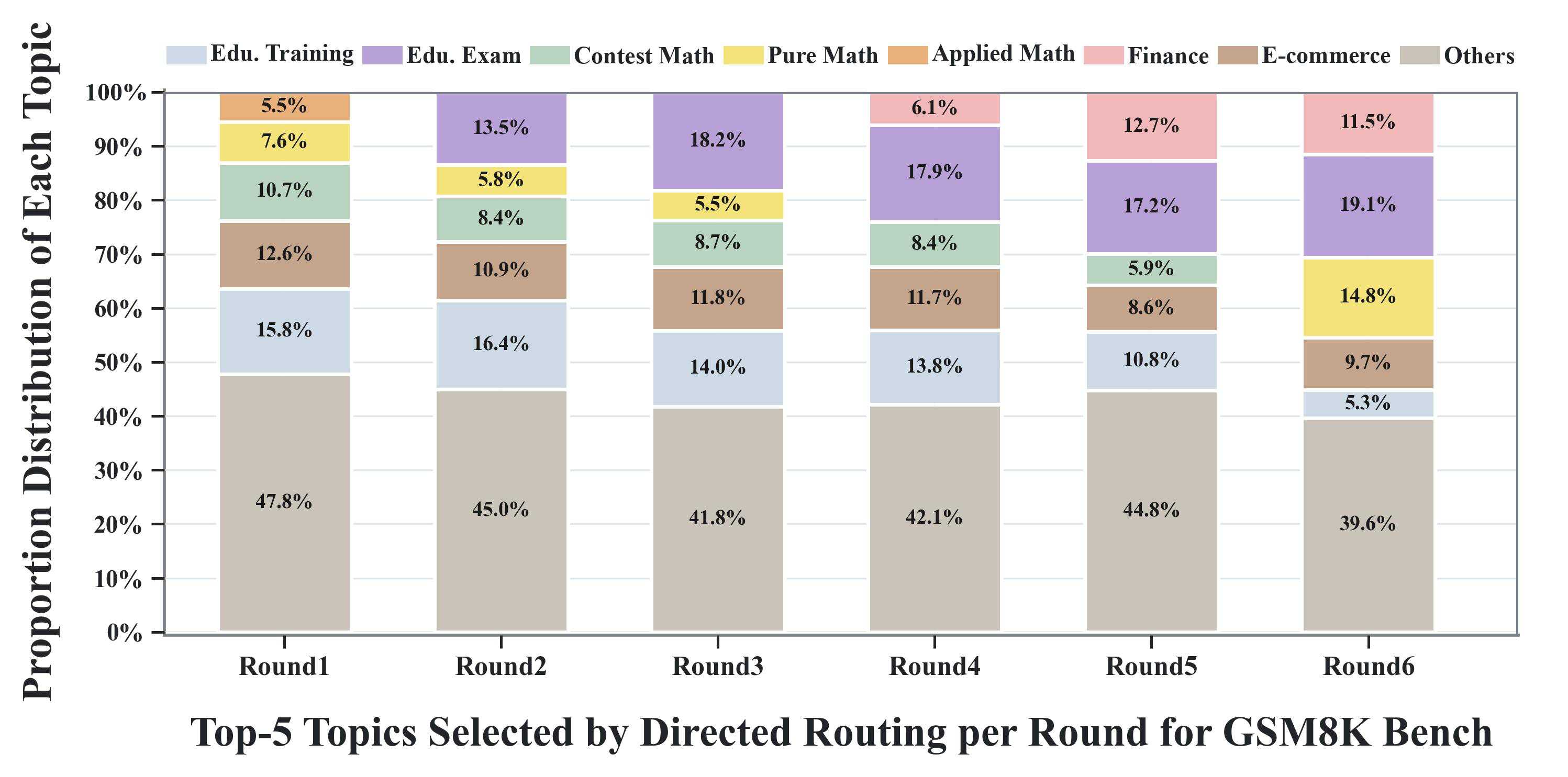
Fig 3: Visualization of Andes routing and node evolution mechanism. (a) The increasing
Fig 4: Experimental results across
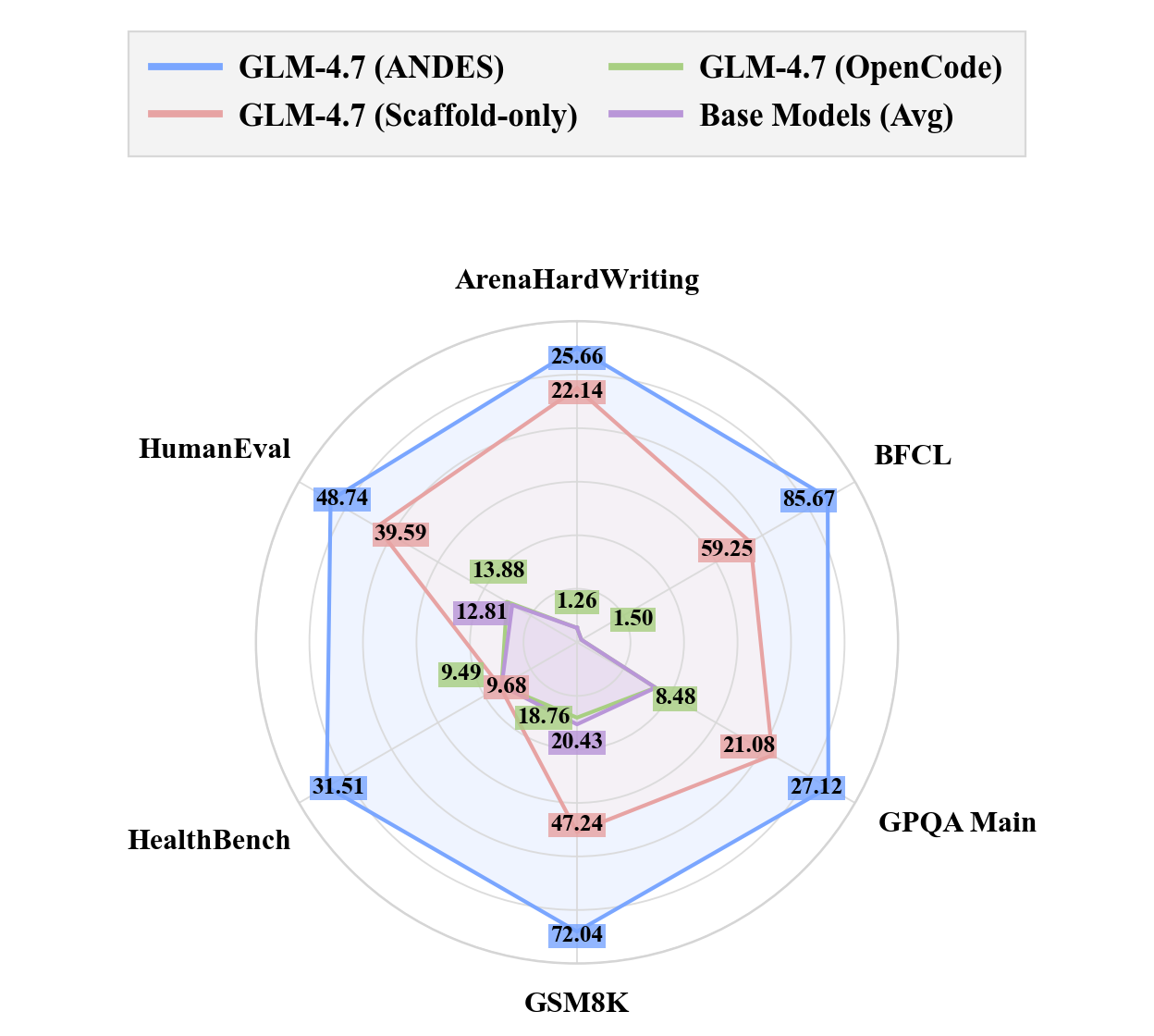
Fig 5: Decoupled performance on
Fig 6: Visualization of the knowledge coverage of the Andes world tree.
Limitations
- Experiments focus on autonomous post-training for instruction alignment but omit adversarial robustness or direct bot/attack simulation evaluations.
- World Tree initial taxonomy and node evolution depend on LLM generation quality; unseen tasks outside taxonomy coverage may reduce effectiveness.
- Report-driven feedback relies on heuristic effort scores and logical diversity metrics which may not perfectly measure sample training value.
- Computational cost and training time still constrained to a single GPU and 10-hour limit; scaling to larger models or corpora is not extensively explored.
- Strong dependence on downstream benchmark decomposition into capability dimensions, which requires manual or heuristic intervention.
- No explicit ablation for sensitivity to hyperparameters governing node evolution thresholds (ρ) or weighting factors (γ+, γ−).
Open questions / follow-ons
- How well does Andes generalize to post-training for newer, larger LLMs with fundamentally different architectures or capabilities?
- Can the World Tree taxonomy and routing mechanisms be adapted or learned dynamically for completely novel task domains?
- What are the limits of the iterative closed-loop feedback in scenarios with severely sparse or contradictory training signals?
- How does Andes integrate with reinforcement learning-based post-training alignment or human-in-the-loop supervision?
Why it matters for bot defense
For bot-defense engineers and CAPTCHA practitioners exploring autonomous model alignment and defense agents, Andes demonstrates a novel paradigm for systematically synthesizing high-quality, diverse training data in a closed feedback loop. Its approach to dynamically routing generation tasks through hierarchical knowledge structures while maintaining data diversity is potentially applicable to generating challenge-response pairs or adaptive testing scenarios in CAPTCHA systems. The diagnostic report-driven interaction could inspire techniques for online adaptation of challenge difficulty or diversity based on attacker behavior feedback. Meanwhile, the modular plug-and-play skill abstraction lowers agent capability requirements, which might enable more lightweight on-device CAPTCHAs that evolve reactively under adversarial attempts. Although the paper focuses on post-training of LLMs, the core innovations in dynamic data synthesis and iterative steering bear direct conceptual relevance to evolving CAPTCHA challenges that remain robust against automated attacks.
Cite
@article{arxiv2606_01279,
title={ ANDES: Agent Native Data Evolving Synthesis Tool for Autonomous Instruction Alignment },
author={ Zhengyang Zhao and Shengjie Ye and Lu Ma and Hao Liang and Hengyi Feng and Wentao Zhang },
journal={arXiv preprint arXiv:2606.01279},
year={ 2026 },
url={https://arxiv.org/abs/2606.01279}
}