
GitHub Copilot and Developer Productivity: An Observational Dose-Response Analysis
Source: arXiv:2606.00438 · Published 2026-05-30 · By Alex Heilman, Alex Kyllo, Emerson Murphy-Hill
TL;DR
This paper evaluates the productivity impact of GitHub Copilot (GHCP) on software engineers by analyzing 43 weeks of telemetry data from 16,223 Microsoft Cloud+AI engineers. The key challenge is separating GHCP's causal effect from confounding factors such as differences between engineers and variations in workload intensity across weeks. To address this, the authors use a within-engineer, week-level fixed-effects Poisson Pseudo-Maximum Likelihood (PPML) model controlling for measured development effort (active coding and browser time). This approach isolates an efficiency effect: how many more pull requests (PRs) an engineer completes at fixed effort given varying GHCP usage intensity. They find that in their highest GHCP usage weeks, engineers complete 40.5% more PRs compared to zero-usage weeks, with a monotonic dose-response exhibiting diminishing returns. Robustness tests rule out confounds such as generic AI engagement, team-level shocks, task reallocation, PR slicing, and shifts to easier tasks. Together these results provide strong observational evidence that GHCP improves developer productivity per coding hour.
Key findings
- Engineers complete 40.5% more pull requests in their highest GHCP usage weeks compared to zero-usage weeks, controlling for coding and browser time (Table 1).
- The dose-response gradient is monotonic with +21.0% (Low), +39.4% (Moderate), and +40.5% (High) GHCP usage terciles.
- Non-coding AI engagement (M365 Copilot in Word, Excel, etc.) shows no association with PR output, ruling out generic AI effect confounding (Section 4.1).
- Individual GHCP usage does not predict teammates’ PR counts beyond 1–2%, discounting team-level shock confounds (Section 4.2).
- Both PR authoring and code review counts rise with GHCP usage, contradicting a within-week task reallocation explanation (Section 4.3).
- Lagged and lead GHCP usage weeks show no positive association with PR output, supporting contemporaneous causality rather than persistent states (Section 4.4).
- Productivity gains concentrate in large PRs (7+ files) rather than small PRs, arguing against artificial task slicing (Section 4.5).
- Dose-response remains monotonic and even stronger for PRs excluding configuration/documentation-only types, negating easier task shift explanations (Section 4.6).
Threat model
The adversary is confounding variables that bias observational estimates of GHCP’s productivity impact. They include between-engineer differences in ability, team, or role, and within-engineer time-varying factors like busy weeks, motivation surges, or task mix shifts that simultaneously drive higher GHCP use and PR output. The analysis assumes, conditional on fixed effects and controlled effort, no such unobserved factors remain that jointly affect both usage intensity and productivity in the same week.
Methodology — deep read
Threat model and assumptions: The adversary is conceptualized as confounders that could bias observational productivity estimates of GHCP usage. These include between-engineer confounds (skill, team, task mix) and within-engineer, time-varying confounds (busy weeks with more work, motivation, task shifts). The key identifying assumption is that, conditional on engineer fixed effects, week fixed effects, coding time, and browser time (effort controls), GHCP usage intensity is independent of unobserved factors influencing PR output. This conditional independence assumption cannot be fully tested but is probed via robustness checks.
Data: The dataset comprises 16,223 individual contributor engineers at Microsoft in the Cloud+AI org, over 43 weeks (Feb–Dec 2025), yielding 413,732 engineer-weeks. Labels include weekly counts of pull requests created per engineer, aggregated GHCP usage telemetry (interaction depth: suggestions, prompts, accepts) per week, weekly active coding time and browser time from Microsoft internal telemetry. PRs are attributed by creation week and filtered to those completed within 28 days. Engineers with zero PRs or zero GHCP usage across the entire period are excluded to improve measurement validity.
Architecture/algorithm: The key model is a Poisson Pseudo-Maximum Likelihood (PPML) regression of PR counts on GHCP usage terciles (Low/Moderate/High vs Zero), controlling for coding time and browser time in levels (not logs) to avoid proportionality assumptions. Additionally, engineer fixed effects absorb time-invariant individual differences, and week fixed effects absorb calendar shocks. Standard errors are clustered at the manager level to account for shared team shocks. This approach estimates an efficiency effect interpreted as percentage change in PRs per unit of controlled development effort.
Training regime: Not applicable—this is an observational regression analysis. Model fitting uses the full panel dataset with fixed effects and robust clustering as described. The paper does not specify software/hardware details for computing.
Evaluation protocol: The main metric is percentage change in expected PR count from exponential coefficients of GHCP usage indicators. The model allows zero coding-time weeks to be naturally included. Seven falsification/robustness tests challenge alternative explanations by swapping treatment and/or outcome measures: using non-coding AI engagement as placebo treatment; using teammates' PRs as placebo outcome; testing reallocation between PR authoring and reviews; lag/lead GHCP usage; PR size and type decompositions; and alternative usage operationalizations (breadth vs depth). Results consistently show the GHCP productivity gradient to be significant and robust.
Reproducibility: The paper states use of internal Microsoft telemetry and data unavailable publicly. Code release is not mentioned. The inferred approach (PPML with fixed effects) is standard in econometrics. Exact replication would require internal data access.
Concrete example walkthrough: For a given engineer-week, the data records coding time (hours), browser time (hours), GHCP usage interactions (count). Weeks are bucketed into GHCP usage intensity terciles. The PPML model predicts the expected PR count, adjusting for engineer and week fixed effects. Comparing predictions for zero vs high GHCP usage at fixed coding and browser time yields the estimated +40.5% increase in PR completion attributed to GHCP efficiency. This comparison occurs within the same engineer over different weeks, isolating the tool's effect from individual ability differences.
Technical innovations
- Use of within-engineer, week-level fixed effects combined with Poisson Pseudo-Maximum Likelihood regression to isolate efficiency effects of GHCP from both time-invariant and time-varying confounders.
- Incorporation of coding time and browser time as level controls, rather than offsets, relaxing restrictive proportionality assumptions on effort-productivity relationship.
- Seven-part falsification battery employing placebo treatments and outcomes, outcome decompositions, and lead-lag tests to rigorously challenge alternative explanations.
- Monotonic dose-response modeling of GHCP interaction depth divided into terciles to reveal diminishing returns on productivity.
Datasets
- Microsoft Cloud+AI engineer telemetry: 16,223 engineers, 413,732 engineer-weeks — internal Microsoft telemetry
- Azure DevOps PR metadata subset with file counts and extensions — internal Microsoft data
Baselines vs proposed
- No GHCP usage (zero) baseline: reference group for PR count.
- Low GHCP usage: +21.0% PRs relative to zero usage weeks.
- Moderate GHCP usage: +39.4% PRs relative to zero usage weeks.
- High GHCP usage: +40.5% PRs relative to zero usage weeks.
- Non-coding M365 Copilot usage placebo treatment: ~0% change in PRs.
- Individual GHCP usage predicting teammates’ PRs: ~1-2% change.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2606.00438.
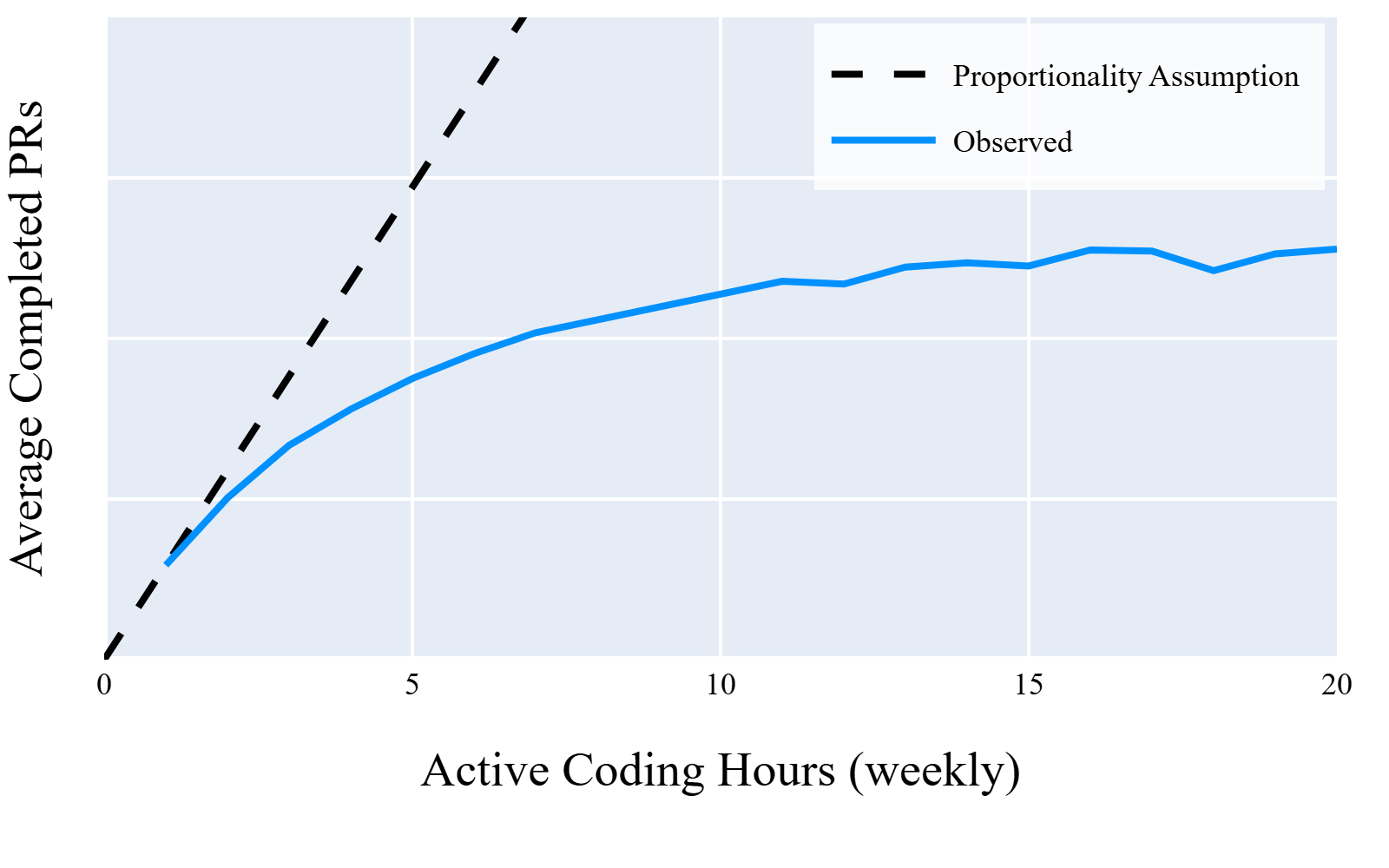
Fig 1: Average PRs vs. active coding hours, with propor-
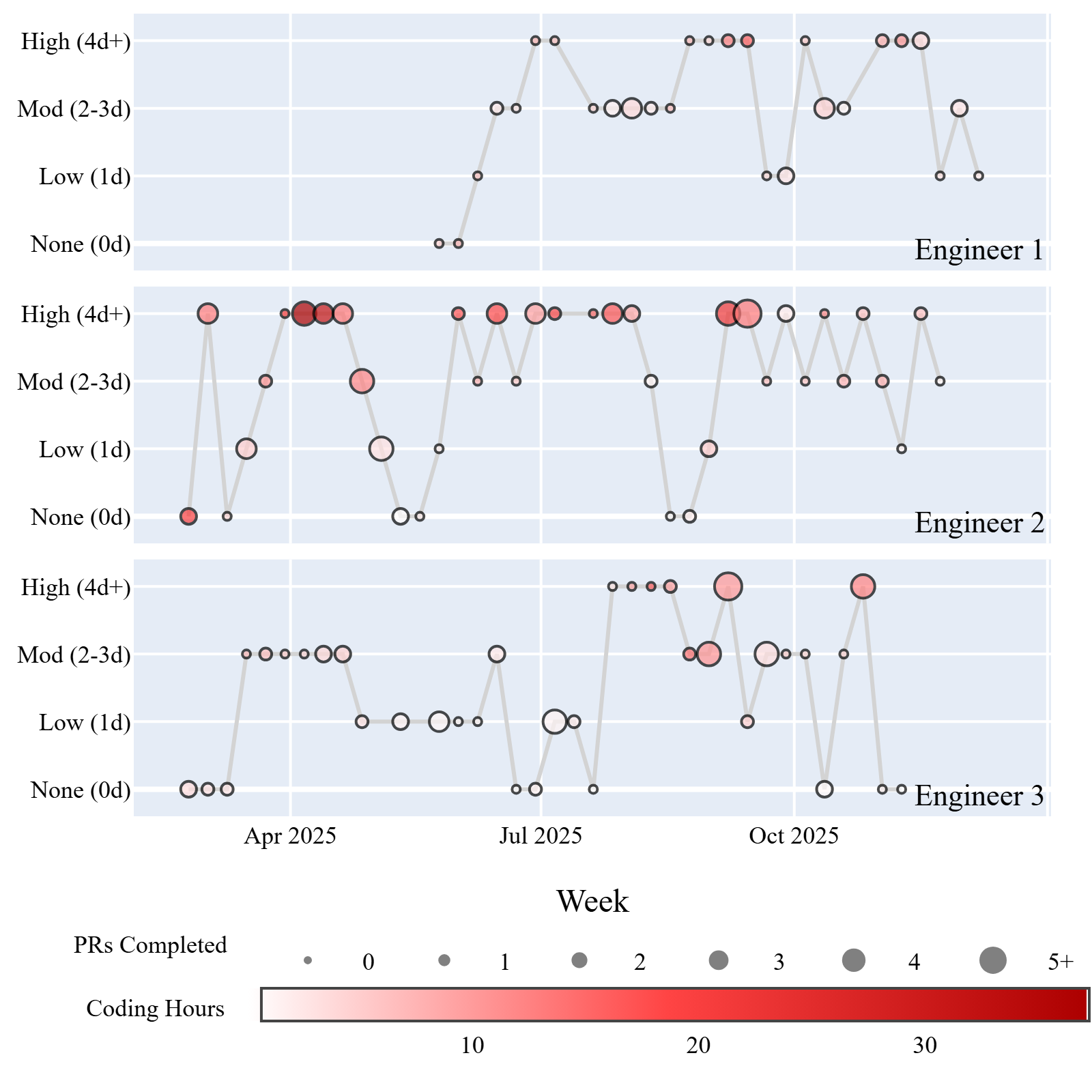
Fig 2: traces three randomly sampled engineers across all 43
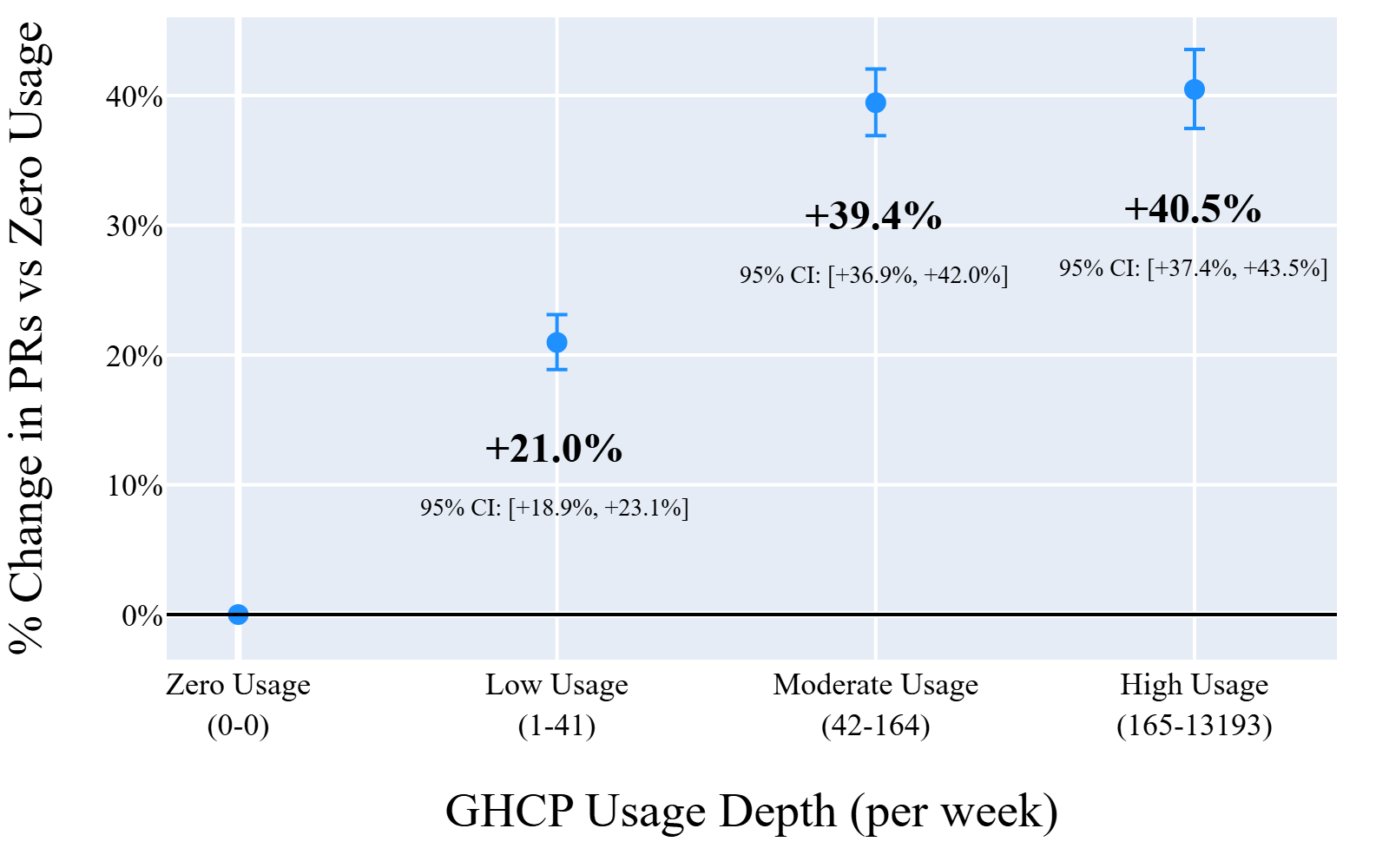
Fig 3: Usage depth dose-response.
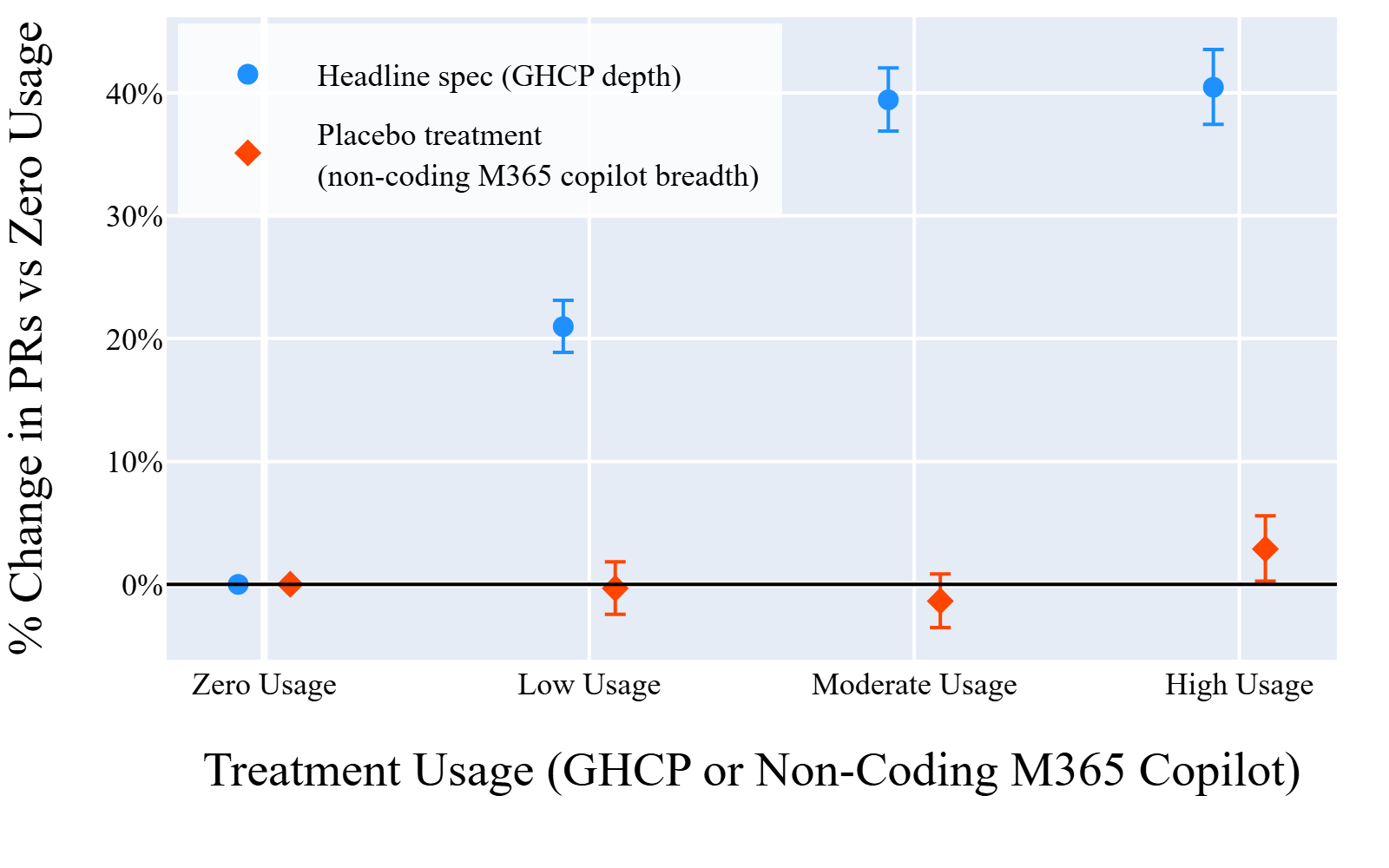
Fig 4: Placebo treatment: non-coding M365 Copilot
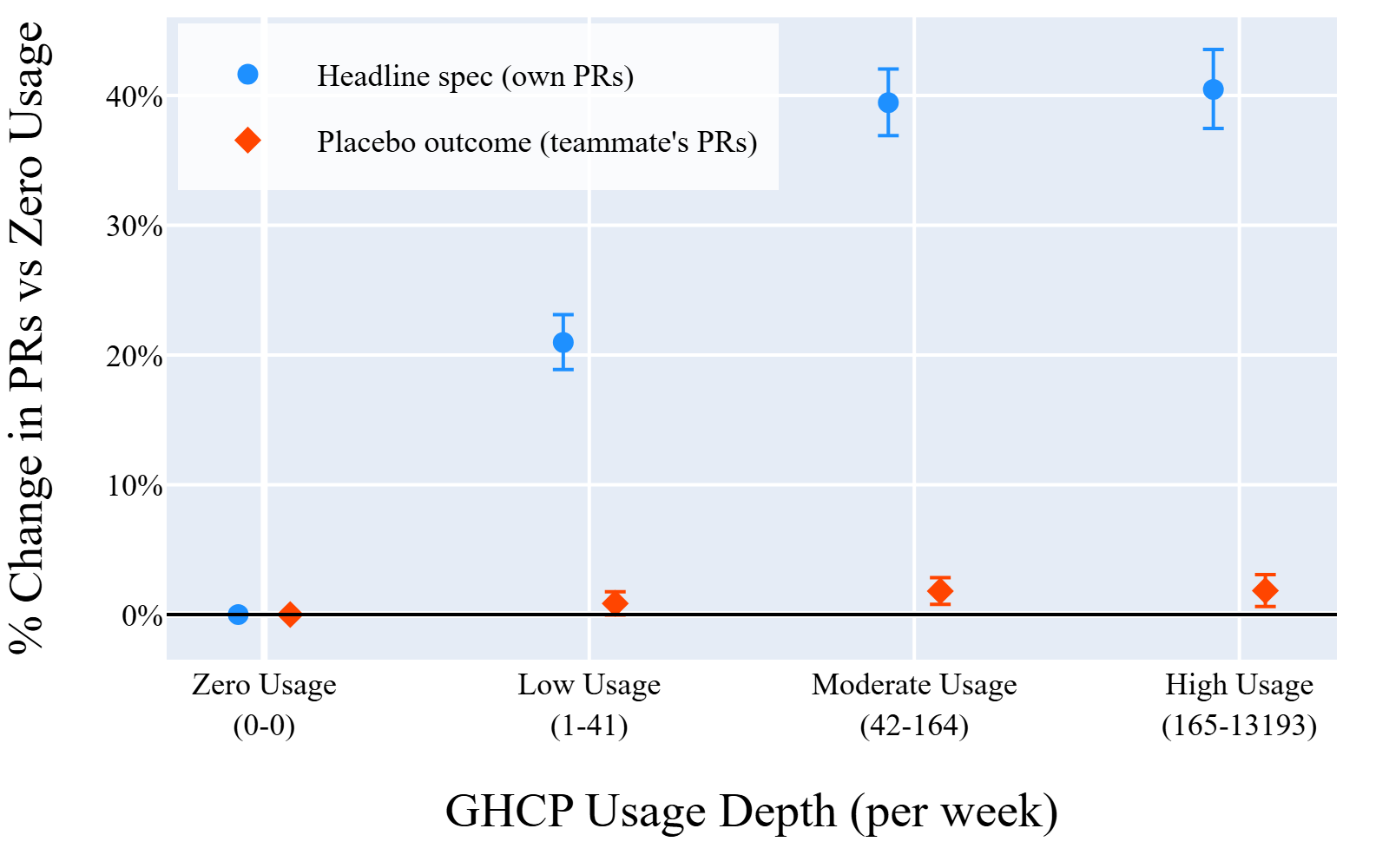
Fig 5: Placebo outcome: own PRs vs. teammates’ PRs by
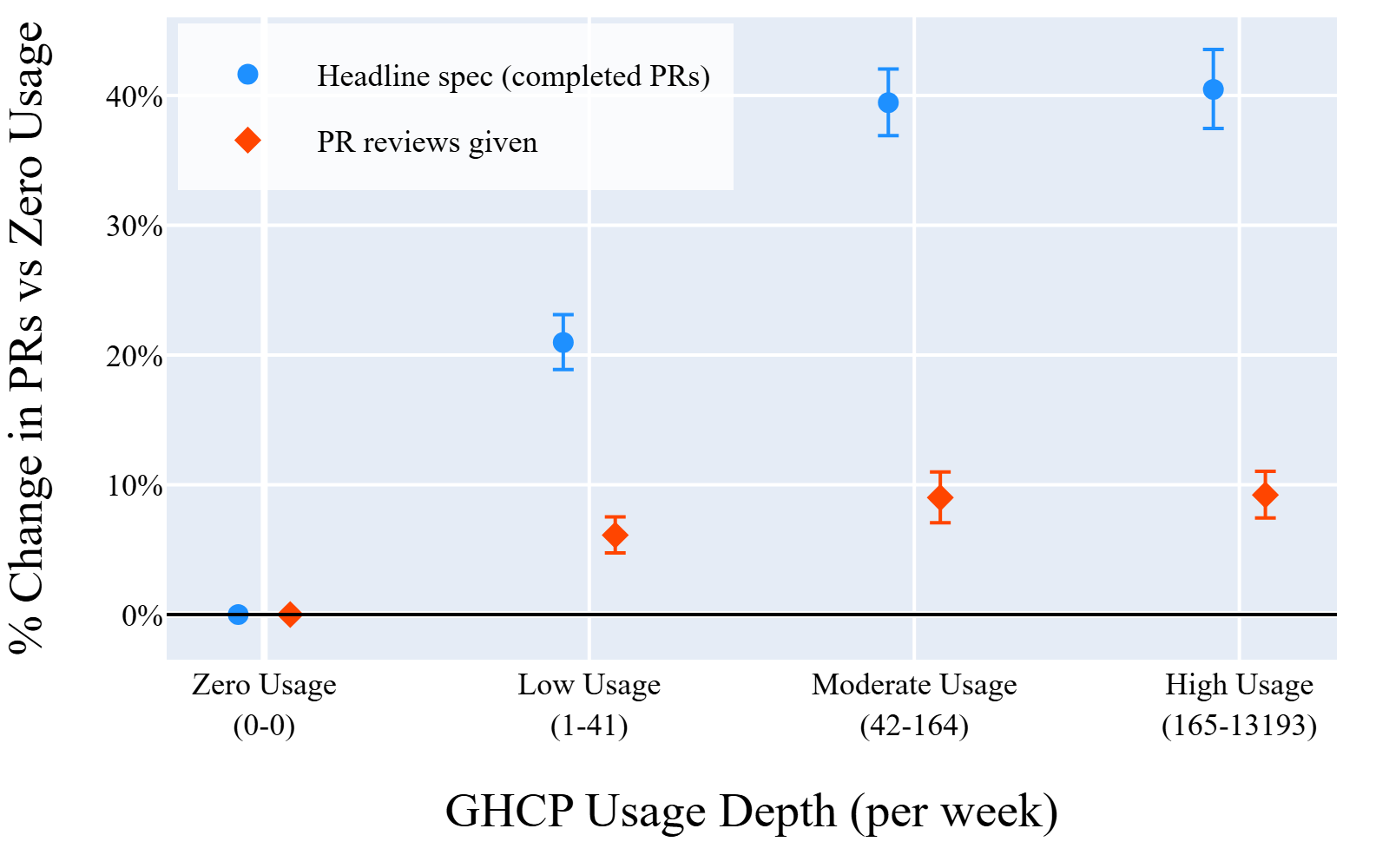
Fig 6: Task-mix test: GHCP gradient on PRs authored vs.
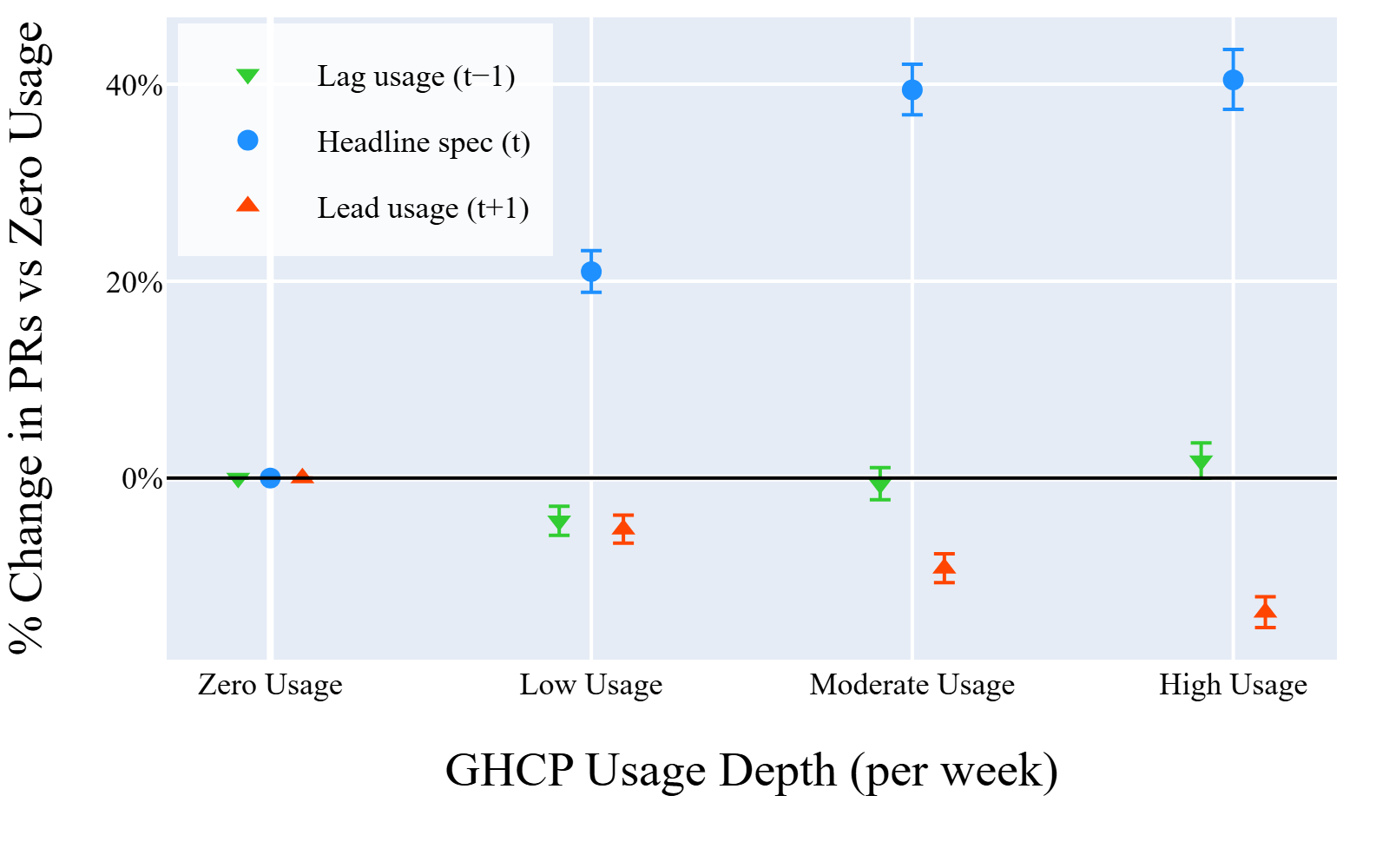
Fig 7: Timing tests: current (𝑡), lagged (𝑡−1), and leading
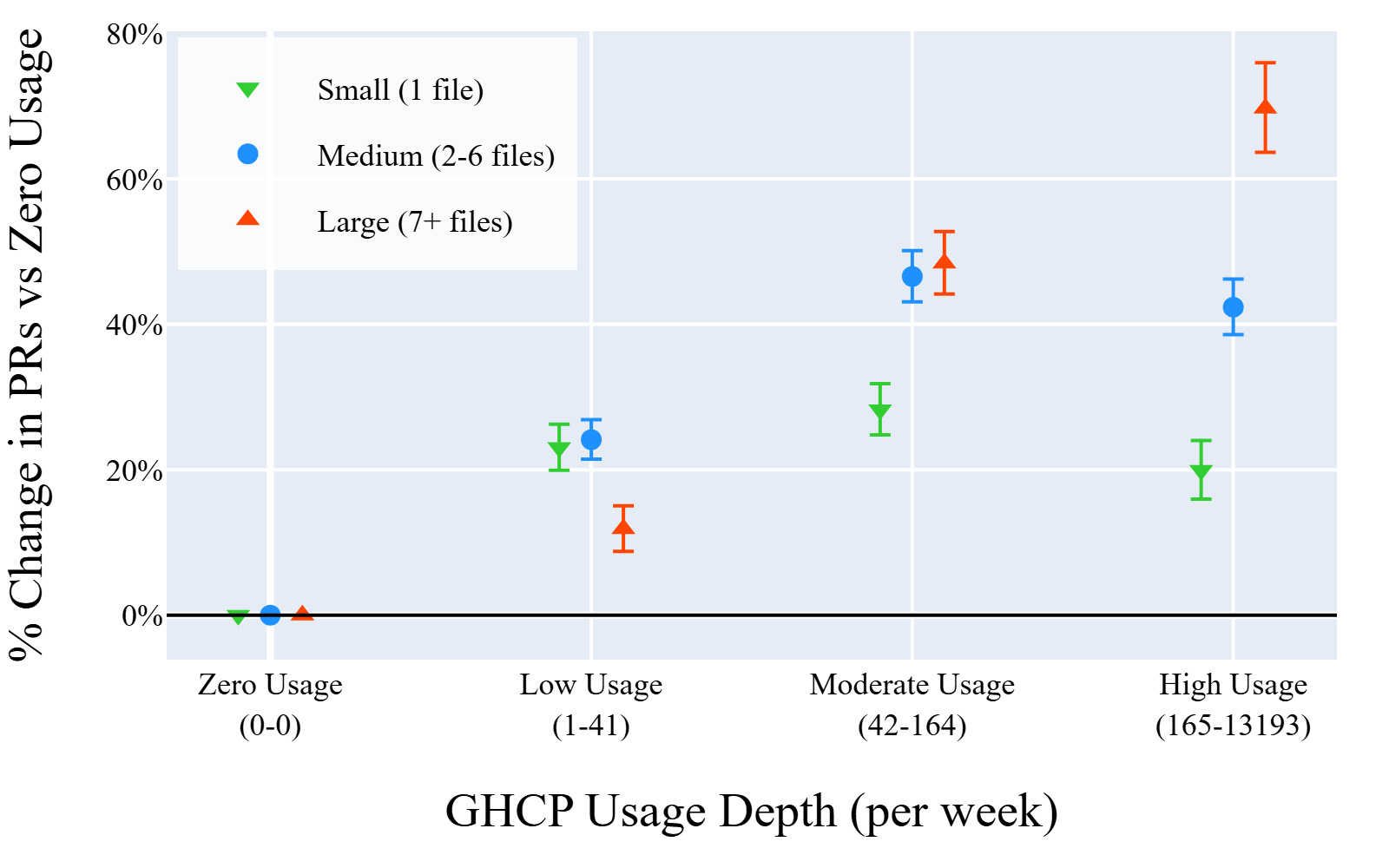
Fig 8: PR size decomposition: dose-response by files
Limitations
- Key causal assumption (conditional independence) about unobserved confounders cannot be directly tested, limiting causal certainty.
- PR count outcome captures activity and efficiency dimensions but omits developer satisfaction, code quality, and communication aspects.
- Measurement of GHCP and outcomes is contemporaneous weekly window, which may blur lead-lag effects in PR development cycles.
- Potential unobserved week-to-week shifts in task difficulty or motivation may still confound estimates despite robustness.
- Data is restricted to Microsoft Cloud+AI org internal telemetry, limiting generalizability and open reproducibility.
- Alternative explanations related to task complexity shifts beyond file count or documentation categories remain possible but unmeasured.
Open questions / follow-ons
- Can similar within-person causal identification be supported by randomization or quasi-experiments in production settings?
- How does GHCP usage affect other developer productivity dimensions, such as code quality, review cycles, or satisfaction?
- What are the longer-term impacts of GHCP on engineering collaboration and task allocation dynamics?
- How generalizable are these findings across different organizations, codebases, and LLM coding assistant versions?
Why it matters for bot defense
While not directly related to bot defense or CAPTCHA, this paper exemplifies rigorous observational causal inference on developer tool efficacy using large-scale telemetry with fine-grained fixed effects and multiple falsification strategies. Bot-defense practitioners interested in designing or evaluating automated defenses that integrate developer productivity tools or telemetry may benefit from its methodological framework for handling confounding and robustness testing. The paper’s emphasis on dose-response analysis and effort controls offers transferable insights for measuring efficiency gains in other workflows involving human-AI interaction.
Cite
@article{arxiv2606_00438,
title={ GitHub Copilot and Developer Productivity: An Observational Dose-Response Analysis },
author={ Alex Heilman and Alex Kyllo and Emerson Murphy-Hill },
journal={arXiv preprint arXiv:2606.00438},
year={ 2026 },
url={https://arxiv.org/abs/2606.00438}
}