
TunerDiT: Training-free Progressive Steering of Diffusion Transformer for Multi-Event Video Generation
Source: arXiv:2605.31590 · Published 2026-05-29 · By Ruotong Liao, Guowen Huang, Qing Cheng, Guangyao Zhai, Lei Zhang, Xun Xiao et al.
TL;DR
TunerDiT addresses the challenge of generating long-horizon, multi-event videos from text prompts using diffusion transformer (DiT) based video generators. Existing DiT models struggle to maintain event boundaries, ordering, smooth transitions, and semantic consistency when asked to generate multiple events in a single long video. This work first probes DiT models and reveals an intrinsic "turning point" in the denoising process where the influence of the conditioning text shifts from controlling global layout to refining fine-grained details. Exploiting this, TunerDiT introduces a training-free, progressive steering method composed of two control handles: Event-Partitioned Masking (to enforce event boundaries with smooth transition bands) and Cross-Event Prompt Fusion (to inject neighboring event semantics during refinement). These modules operate aligned with the intrinsic turning point in the diffusion to balance the competing needs of event separation and global consistency. A new multi-event video benchmark called MEve is curated to evaluate multi-event generation up to 4 events. TunerDiT achieves state-of-the-art performance across 8 complementary quantitative metrics, vision-language model judges, and human studies, outperforming recent zero-shot baselines such as MEVG, DiTCtrl, and FreeNoise. The method requires no retraining and is efficient at inference.
The experimental results demonstrate that TunerDiT improves text-video alignment substantially with more events, indicating scalability to long-horizon multi-event scenarios. Ablation studies confirm that Event-Partitioned Masking increases event separation but reduces global consistency, while Cross-Event Prompt Fusion helps restore consistency, achieving a favorable balance. Overall, TunerDiT leverages a principled understanding of diffusion denoising dynamics to deliver multi-event video generation that respects ordering, boundaries, semantic coherence, and transition smoothness without additional training.
Key findings
- Intrinsic turning point in DiT denoising steps lies within the first ~30% of diffusion, where text conditioning influence switches from global layout to detail refinement (Fig 1, 3d).
- TunerDiT achieves state-of-the-art text alignment (TA) scores of 0.210–0.219 across 2 to 4 event generation settings, outperforming zero-shot baselines like MEVG (0.201–0.205) and DiTCtrl (0.186–0.216) (Table 1a).
- TunerDiT improves identity consistency (IC) and background consistency (BC) metrics significantly compared to baselines, e.g., IC rises from 0.280 (DiTCtrl) to 0.411–0.516 (TunerDiT) at 4 events.
- Vision-language model judge metrics (Event Isolation and Text-Video Alignment) show TunerDiT (Open-Sora 2.0) achieves EI=0.572 and TVA=1.533, best among tested methods (Table 1b).
- Human evaluation of 18 users ranks TunerDiT highest on quality, motion naturalness, transition smoothness, and text alignment, with gains exceeding +0.85 points over best baselines.
- Ablation shows Event-Partitioned Mask (EM) greatly improves multi-event separation (TA/TIS) but reduces BC/IC/CSCV, while Cross-Event Prompt Fusion (PF) recovers consistency without losing separation (Fig 6,7).
- Performance gaps (improvement in TA) versus base DiT models increase with event counts, indicating TunerDiT scales better with number of events (Fig 9).
- Optimal prompt fusion gating occurs early in diffusion steps (~0.0–0.2), while event mask gating peaks mid-range (~0.1–0.2), and moderate transition band widths (~0.1–0.3) balance smooth transitions with event isolation (Fig 8).
Threat model
n/a - This work does not address adversarial or malicious threat models but focuses on improving zero-shot multi-event text-to-video generation quality and consistency.
Methodology — deep read
Threat Model & Assumptions: TunerDiT targets the zero-shot, training-free multi-event text-to-video generation scenario without assuming adversarial attacks. The focus is on improving multi-event synthesis fidelity, order, and transitions using off-the-shelf DiT models and does not consider adversaries or robustness to manipulation.
Data & Benchmark: The authors curate MEve, a multi-event prompt suite with up to 4 events per prompt, collected from multiple sources including LLM-generated instructions, VBench 2.0 expansions, and Ego-Exo4D video narrations. MEve covers diverse event types, viewpoints (1st and 3rd person), and provides ground truths for quantitative evaluation. Detailed data statistics and splits are in Appendix A.
Architecture & Algorithm: TunerDiT operates on pretrained video diffusion transformers (DiTs) like OpenSora 1.2/2.0, and Wan 2.2, with no model parameter changes or training. The key technical insight is the intrinsic "turning point" in diffusion denoising steps where text conditioning shifts from global scene layout (early steps) to fine-grained detail refinement (later steps).
TunerDiT has two main progressive steering modules aligned with this point:
- Cross-Event Prompt Fusion (PF): Before a tunable gating step τ_PF (near turning point τ*), all event prompts are fused by conditioning all video tokens on the first event's prompt embeddings. After τ_PF, conditioning switches to individual event prompts for their corresponding video segments, thus building a coherent global layout early, then refining event details separately.
- Event-Partitioned Diagonal Mask (EM): Activated after a gating step τ_EM (after τ_PF), this binary mask restricts cross-attention so that video tokens attend only to matching event prompts (a diagonal block structure), preventing semantic leakage across events and preserving event boundaries. Soft "transition bands" allow limited attention near event boundaries to enable smooth transitions. Masking applies in both video-text cross-attention and video self-attention.
Training Regime: No training or fine-tuning is performed; the method operates fully at inference time. Progressive steering is applied per diffusion step during iterative denoising (typically ~1000 steps). Prompt fusion and masking parameters (τ_PF, τ_EM, band width ratio r) are tuned over candidate values on MEve to maximize Text Alignment (TA).
Evaluation Protocol: The authors evaluate on MEve with 2 to 4 event prompts. Metrics include:
- Automatic embedding-based: Text Alignment (TA), Text-Image Similarity (TIS), Background Consistency (BC), Identity Consistency (IC), Clip Similarity Coefficient of Variation (CSCV).
- Vision-language model as a judge: Event Isolation (EI) accuracy and Text-Video Alignment (TVA) using Gemini-2.5-Flash and Sentence-BERT.
- Human studies with 18 subjects rating overall quality, motion naturalness, transition smoothness, and text-video alignment on 5-point Likert scales. Baselines include state-of-the-art zero-shot multi-event T2V methods: MEVG, DiTCtrl, FreeNoise, and vanilla DiT backbones.
- Reproducibility: The paper references open-source pretrained DiT models OpenSora and Wan. MEve benchmark prompts and evaluation code are presumably released (not explicitly stated in summary). Algorithm pseudocode is provided. Detailed architectural parameters, gating ratios, and hyperparameters are in Appendix B-D.
Example end-to-end generation: Given a multi-event prompt (e.g. cooking steps), TunerDiT first applies prompt fusion early in diffusion steps to create a global, coherent layout, then progressively activates the event-partitioned mask to isolate events and enable smooth transitions. The final video shows clear event boundaries, correct temporal order, semantic consistency, and smooth motions matching the prompt, surpassing prior zero-shot baselines.
Technical innovations
- Discovery and exploitation of an intrinsic turning point in DiT denoising steps where text conditioning transitions from controlling global layout to fine detail refinement.
- Cross-Event Prompt Fusion technique that fuses all event prompts early in diffusion to establish a shared global layout, then progressively refines individual events to improve semantic separation.
- Event-Partitioned Diagonal Mask that constrains cross-attention to isolate events yet permits transition bands near event boundaries, balancing event separation and smooth transitions.
- A training-free progressive steering framework applied at inference time leveraging diffusion step conditioning schedules and attention masking for scalable multi-event video generation.
Datasets
- MEve — multi-event text prompts with up to 4 events per prompt, curated from LLM-generated instructions, VBench 2.0 expansions, and Ego-Exo4D video narrations (private/public not explicitly stated).
Baselines vs proposed
- MEVG baseline: Text Alignment (TA) ranges from 0.201 to 0.205 vs TunerDiT Open-Sora 2.0 TA 0.210–0.219
- DiTCtrl baseline: Identity Consistency (IC) at 0.280 vs TunerDiT Wan2.2 IC 0.516 at 4 events
- FreeNoise baseline: Background Consistency (BC) at 0.275 vs TunerDiT Wan2.2 BC 0.619 at 2 events
- VLM-as-judge Event Isolation (EI): DiTCtrl 0.375 vs TunerDiT Open-Sora 2.0 0.572
- Human study Q1 (overall preference): DiTCtrl 2.11 vs TunerDiT Wan 2.2 3.01 (5-point scale)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.31590.

Fig 1: Different denoising steps utilize text inputs differently. TunerDiT finds this insight by probing prompt conditioning of video
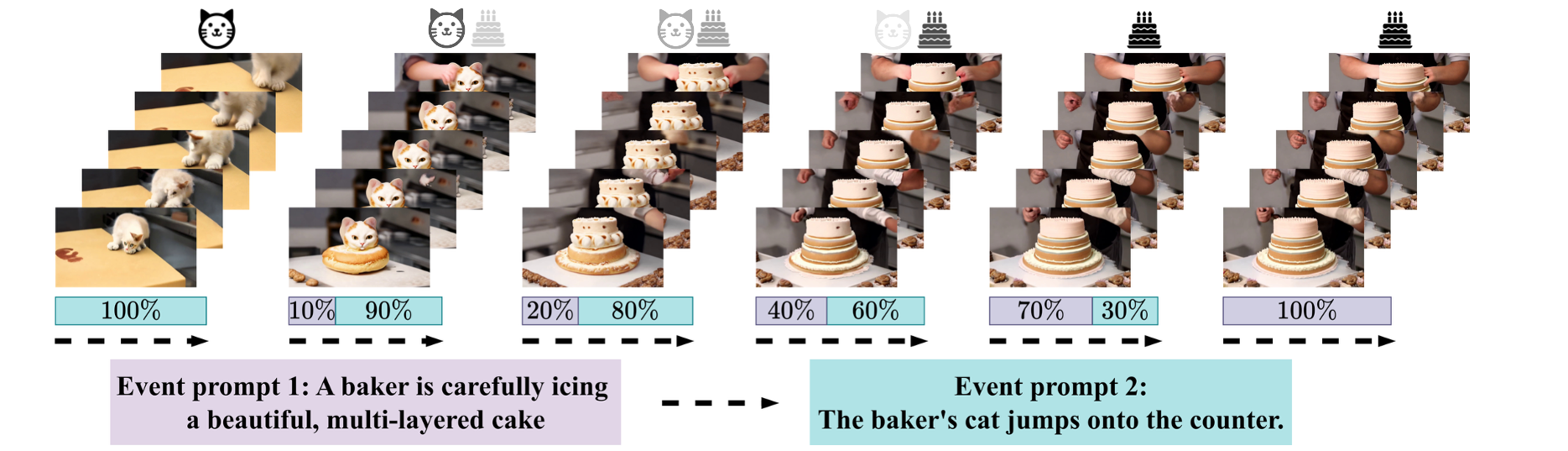
Fig 2 (page 1).

Fig 2: DiT video diffusion models failed with multi-event prompting.
Fig 3: MEve and turning-point analysis. (a,c) Dataset structure: category and view distribution statistics. (b) Position of MEve among
Fig 4: TunerDiT progressively steers multi-event generation over diffusion steps. Cross-Event Prompt Fusion (PF) first shares a
Fig 6 (page 5).

Fig 7 (page 5).

Fig 8 (page 5).
Limitations
- The approach relies on an intrinsic turning point stable per model, which may vary across other architectures or future DiT variants and could require tuning.
- Event boundaries and transition smoothing depend on manually tuned gating parameters and mask widths, potentially lowering generalization to very complex event structures.
- No adversarial robustness or attack analyses are provided, so effectiveness against stealthy bot or manipulation attacks is unknown.
- MEve benchmark is newly introduced but not stated to be fully public or large-scale; results may reflect biases in prompt design or category coverage.
- The method assumes that diffusion denoising strictly separates layout and detail refinement phases, which might not hold for all video diffusion architectures.
- While tested up to 4 events, scalability beyond this number remains to be empirically verified.
Open questions / follow-ons
- How stable and transferable are the intrinsic turning points across different diffusion architectures and training regimes?
- Can the progressive steering paradigm be extended to more than four events or to more complex long-horizon video planning tasks?
- What are the trade-offs or improvements possible by integrating limited lightweight training or fine-tuning with TunerDiT's inference-time steering?
- How does TunerDiT perform under noisy or ambiguous prompts, or with real-world multi-event video datasets beyond curated synthetic prompts?
Why it matters for bot defense
From a bot-defense or CAPTCHA standpoint, TunerDiT's insights on controlled multi-event video generation via training-free inference steering could illuminate better defenses against synthetic video content that attempts to mimic complex event sequences. Understanding how diffusion models internally separate layout from detail refinement may suggest novel avenues for detecting forged or algorithmically manipulated videos that fail to respect these intrinsic temporal generation dynamics. Furthermore, the modular progressive control of event boundaries and cross-event semantic consistency might inspire new CAPTCHA generation schemes that challenge bots with temporally complex dynamic visual content that is harder to fake consistently. Overall, TunerDiT shows that improved interpretability and fine-grained steering of multi-event generative diffusion models is achievable without added training, which is valuable knowledge for generating robust synthetic visual challenges or for detecting synthetic content pipelines in bot defense scenarios.
Cite
@article{arxiv2605_31590,
title={ TunerDiT: Training-free Progressive Steering of Diffusion Transformer for Multi-Event Video Generation },
author={ Ruotong Liao and Guowen Huang and Qing Cheng and Guangyao Zhai and Lei Zhang and Xun Xiao and Thomas Seidl and Daniel Cremers and Volker Tresp },
journal={arXiv preprint arXiv:2605.31590},
year={ 2026 },
url={https://arxiv.org/abs/2605.31590}
}