
SOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models
Source: arXiv:2605.31597 · Published 2026-05-29 · By Olaf Dünkel, Basavaraj Sunagad, Haoran Wang, David T. Hoffmann, Christian Theobalt, Adam Kortylewski
TL;DR
This paper addresses the challenge of evaluating structured object understanding in vision foundation models (VFMs) by focusing on semantic object correspondence (SOC), the ability to match semantically corresponding parts across different object instances and categories despite large appearance and geometric variations. Prior benchmarks suffered from inconsistent protocols, ambiguous keypoint annotations, and no evaluation of cross-category transfer. To overcome these limitations, the authors propose a taxonomy-driven formulation of semantic correspondence that disentangles matching the same semantic concept (concept correspondence, CC), matching with geometric object-relative identity (SOC), and matching across related but different categories (Cross-SOC). Based on this formalism, they introduce SOCO, a large-scale benchmark with 100 diverse categories, over 1 million keypoint correspondence pairs, and hierarchical keypoint annotations with accompanying natural language descriptions. Extensive experiments on SOCO reveal that (i) strong VFMs encode local semantic concepts well but struggle to encode geometry needed for uniquely identifying repeated parts and transfer across categories, (ii) large vision-language models (LVLMs) excel at text-prompted single-image part localization but underperform at visual-reference cross-image matching, and (iii) SOC performance correlates more strongly with dense downstream tasks like segmentation, tracking, and 3D pose estimation than ImageNet classification accuracy, highlighting SOC as a practical diagnostic for structured part-level representation quality. SOCO thus provides a unified, systematic evaluation framework for fine-grained visual understanding and multimodal alignment applicable to modern foundation models.
Key findings
- SOCO contains 100 object categories organized into 4 super-categories, with over 1 million keypoint correspondence pairs, including cross-category pairs.
- Median per-keypoint annotation standard deviation across annotators is 0.85% normalized image dimension, indicating high annotation consistency.
- Across 3 tasks (concept correspondence CC, semantic object correspondence SOC, and cross-category correspondence Cross-SOC), all models show substantial accuracy drops moving from CC to SOC and further to Cross-SOC, indicating difficulty capturing geometric and cross-category part correspondence.
- DINOv2 achieves top correspondence accuracy with 78.9% on CC, 60.4% on SOC, and 55.0% on Cross-SOC ([email protected]), showing a 18.5% and 23.9% absolute drop from CC to SOC and SOC to Cross-SOC respectively.
- Models trained with dense self-supervised objectives (DINO family, iBOT, C-RADIOv3) outperform global image alignment models (CLIP) on SOCO by wide margins (e.g., CLIP SOC accuracy 16.1% vs DINOv2 60.4%).
- LVLMs perform better at text-prompted keypoint localization within an image (up to ~54% accuracy) than at visual reference cross-image matching (~30% accuracy), revealing a gap between language-grounded localization and fine-grained visual correspondence.
- SOC scores correlate more strongly with dense downstream tasks (segmentation, tracking, 3D pose/detection) than ImageNet classification accuracy across 37 vision models, with positive Pearson correlation deltas consistent across dense SSL-trained models.
- Large models (e.g., Qwen3-VL-8B) improve LVLM correspondence accuracy substantially, but still lag behind vision-only models on cross-image matching.
Threat model
n/a – The work is focused on benchmarking semantic object correspondence capabilities for vision and vision-language models rather than analyzing adversarial threats or attacks.
Methodology — deep read
Threat Model & Assumptions: The authors consider evaluating semantic correspondence capabilities of vision foundation models and large vision-language models without adversary constraints. The focus is on probing representational quality for structured, part-level matching across large intra-class and cross-category variations. No explicit adversarial attacks or robustness tests were conducted.
Data: SOCO is built on samples from ImageNet, with man-made object images verified with ImageNet3D pose annotations and animal images from Animal3D datasets. It contains 100 categories grouped into four super-categories (Transportation, Hand-held Objects, Furniture, Animals), with 40 images annotated per category (total 4,000 images). Keypoint annotations follow a novel semantic taxonomy, disambiguating semantic concepts and geometric part instances. More than 1 million correspondence pairs are generated for three tasks (CC, SOC, Cross-SOC). Annotation was crowdsourced via Mechanical Turk, followed by manual verification. Annotation agreement is strong (median per-keypoint std dev 0.85% of image size).
Architecture / Algorithm: The benchmark evaluates pretrained vision and vision-language foundation models without additional fine-tuning. Keypoint correspondences are computed by extracting dense feature maps from models, then matching a query point's feature in the source image to the nearest neighbor in the target image via cosine similarity. For LVLMs, semantic correspondence is formulated as a multiple-choice visual question answering (VQA) task with 4 candidate keypoints (A/B/C/D) on the target image, prompted by either a visual source marker, textual description, or both.
Training Regime: Not applicable as models are evaluated in a zero-shot manner. The chosen models include self-supervised vision encoders (DINOv1/v2/v3, iBOT, MAE, PIXIO), text-supervised encoders (CLIP, Qwen-VL), and large LVLMs (Qwen3-VL, GPT4o). No additional model training described.
Evaluation Protocol: Models are assessed on three tasks: concept correspondence (CC), semantic object correspondence (SOC), and cross-category SOC (Cross-SOC) using the SOCO benchmark subsets of 20k image pairs each. Matching accuracy is measured by Percentage of Correct Keypoints (PCK) at α=0.1 (keypoint prediction within 10% of object max dimension). LVLMs use accuracy with a strict circular evaluation preventing answer bias. Correlations against downstream dense tasks (segmentation, tracking, pose estimation, 3D detection) were computed via Pearson's r across 37 vision models.
Reproducibility: SOCO dataset and evaluation code are publicly available at https://genintel.github.io/SOCO/ but model code and weights for some LVLMs may be proprietary. Three fixed SOCO evaluation subsets are released to standardize testing. The dataset includes semantic keypoint annotations with textual descriptions allowing benchmarking vision and multilingual models.
Concrete example: Given a source image of a car with a marked front left wheel keypoint, a model's dense features are extracted; cosine similarities identify the matching keypoint on a different car instance. For LVLMs, a multiple choice question with the target image showing candidate points is posed and model's answer accuracy recorded. This procedure is repeated for ~20k image pairs per task to compute PCK metrics and compare models systematically.
Technical innovations
- Taxonomy-driven formulation of Semantic Object Correspondence (SOC) that disentangles concept-level, geometric part identity, and cross-category transfer correspondences for more precise benchmarking.
- SOCO dataset with 100 diverse categories, hierarchical semantic keypoint annotations, and over 1 million correspondence pairs enabling standardized evaluation of semantic correspondence across instances and categories.
- Inclusion of natural language descriptions paired with keypoints to enable unified evaluation of vision foundation models and large vision-language models on fine-grained part-level understanding.
- Zero-shot evaluation protocol using dense feature similarity for vision models and multiple-choice VQA for LVLMs to isolate visual reference and language grounding capabilities.
Datasets
- SOCO — 4000 images, 100 categories, 1 million keypoint correspondences — constructed from ImageNet and Animal3D sources with novel semantic keypoint annotations
- ImageNet3D — used for pose metadata and validation of man-made object images (source for SOCO)
- Animal3D — used for initial keypoint annotations for animal categories (source for SOCO)
Baselines vs proposed
- DINOv2: CC [email protected] = 78.9%, SOC = 60.4%, Cross-SOC = 55.0% vs DINOv1: CC = 43.8%, SOC = 30.6%, Cross-SOC = 23.9%
- CLIP: SOC accuracy = 16.1% vs DINOv2 = 60.4%, showing global alignment objectives lag dense SSL on correspondence
- MAE: SOC = 9.4% vs PIXIO = 37.5%, showing scaling and architecture differences impact dense correspondence
- Qwen3-VL-8B LVLM: Visual-reference cross-image matching (Vis.) accuracy 34.2%, text-prompted keypoint localization (Desc.) 54.0%
- Random++ baseline for LVLM multiple-choice task = 25%, indicating chance performance without vision
- Pearson correlation of SOC with dense tasks (segmentation, tracking, 3D pose) surpasses ImageNet kNN classification by ~0.2 absolute r across 37 models
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.31597.
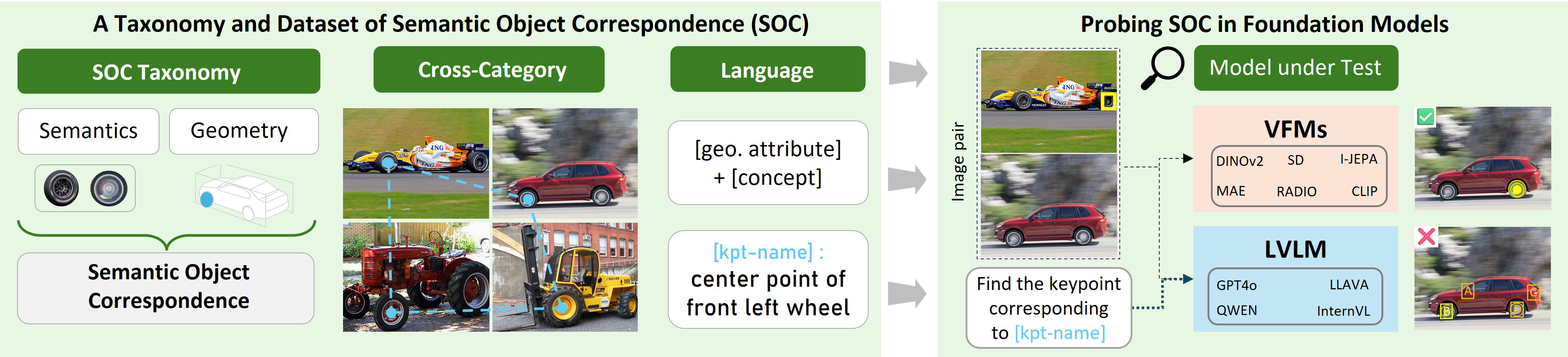
Fig 1: SOCO provides the first taxonomy-driven, language-grounded formulation of
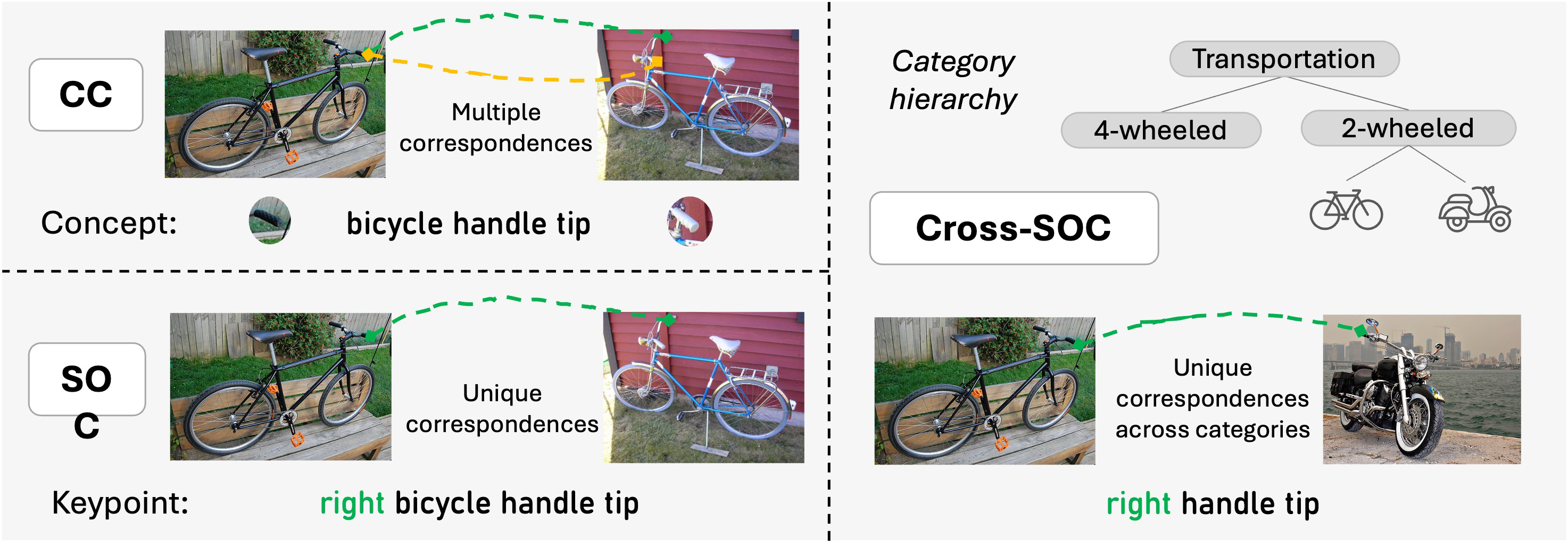
Fig 2: Illustration of concept correspondence (CC), semantic object cor-

Fig 3: Statistics of labeled keypoints. Keypoints in SOCO are annotated for a
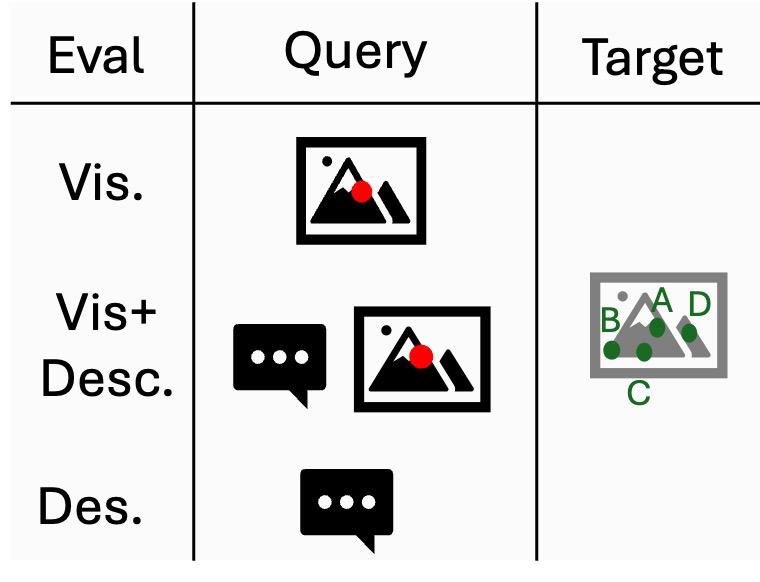
Fig 4: Per-task Pearson r across 37 vision models, with 95% bootstrap CIs.

Fig 5 (page 24).
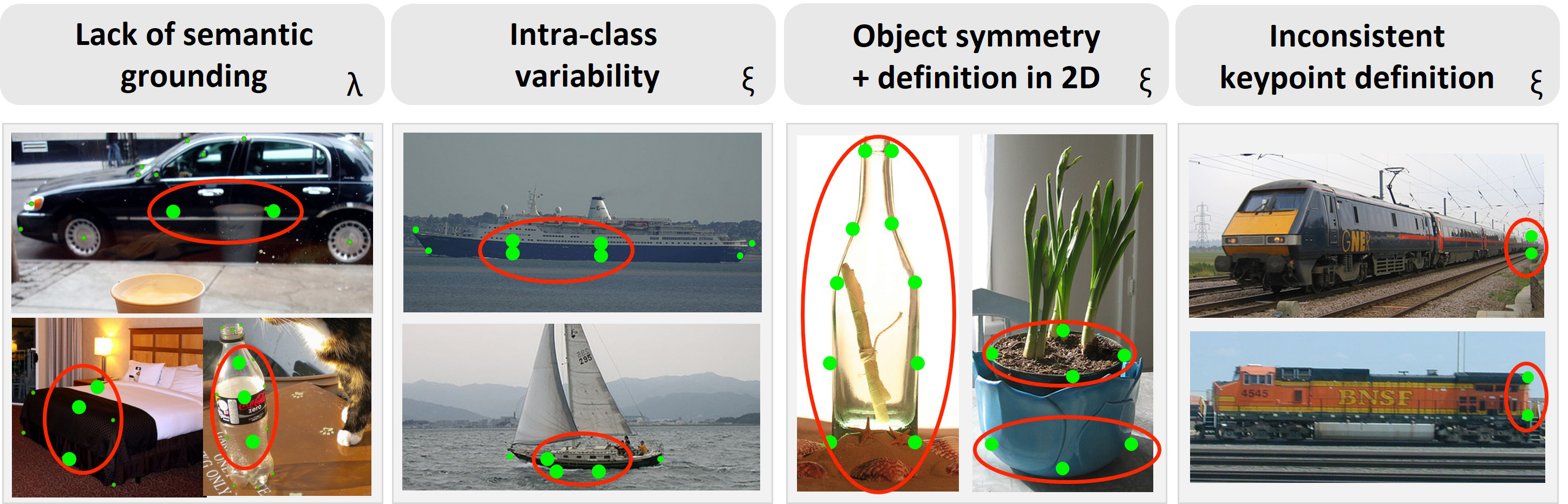
Fig 6 (page 24).
Fig 7 (page 29).

Fig 8 (page 30).
Limitations
- SOCO’s annotations and benchmark focus primarily on keypoint-level correspondences and do not evaluate full object segmentation or dense correspondence.
- The benchmark evaluates zero-shot capability without fine-tuning, which may under-represent potential model performance after adaptation.
- Large LVLMs evaluated show substantial gaps on visual-reference cross-image matching, indicating current multimodal models are still limited in joint spatial grounding.
- Cross-category correspondence is challenging due to visual and geometric variations; many strong vision models still perform below 60% accuracy on this task.
- While SOCO covers 100 categories, it is biased towards ImageNet classes and lacks real-world domain shifts like occlusion or cluttered scenes.
- No adversarial or robustness evaluation was conducted to assess semantic correspondence under challenging conditions.
Open questions / follow-ons
- How can future models improve encoding of object-level geometric configuration to reduce repeated-part confusion in semantic correspondence?
- Can fine-tuning or multi-task learning with SOCO improve cross-category transfer and part-level reasoning in vision and multimodal models?
- What architectural or training modifications help close the gap between language-grounded localization and visual-reference cross-image matching in LVLMs?
- How well do semantic correspondence capabilities generalize under real-world domain shifts (e.g., occlusion, clutter) not covered by SOCO?
Why it matters for bot defense
For bot-defense engineers and CAPTCHA developers, SOCO offers a rigorous benchmark to evaluate whether vision or vision-language models can robustly identify and match fine-grained object parts across instances and categories. This is relevant for designing CAPTCHAs that require robust object part reasoning beyond simple recognition, potentially increasing resistance to automated attacks using foundation models that excel only at classification or retrieval. Understanding failure modes such as repeated-part confusion or limited cross-category transfer helps in crafting puzzles that exploit such weaknesses. Additionally, the gap identified between language-prompted localization and visual-reference matching in LVLMs signals that multimodal models may be vulnerable to CAPTCHAs requiring precise visual correspondence rather than language-based clues. Thus, SOCO can serve as a diagnostic tool to benchmark candidate ML models for CAPTCHA generation and verification tasks requiring structured, part-level object understanding.
Cite
@article{arxiv2605_31597,
title={ SOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models },
author={ Olaf Dünkel and Basavaraj Sunagad and Haoran Wang and David T. Hoffmann and Christian Theobalt and Adam Kortylewski },
journal={arXiv preprint arXiv:2605.31597},
year={ 2026 },
url={https://arxiv.org/abs/2605.31597}
}