
Reliable Multilingual Orthopedic Decision Support from Clinical Narratives: Language-Aware Adaptation and Verification-Guided Deferral
Source: arXiv:2605.31512 · Published 2026-05-29 · By Danish Ali, Li Xiaojian, Sundas Iqbal, Farrukh Zaidi
TL;DR
This paper addresses the challenge of building reliable multilingual orthopedic clinical decision support systems from free-text narratives in English, Hindi, and Punjabi. Such settings are difficult due to specialized terminology, mixed script usage, label imbalance, and language-dependent documentation patterns, especially in low-resource healthcare contexts. The authors propose IndicBERT-HPA, a domain-adaptive multilingual transformer model that augments the pretrained IndicBERT encoder with language-aware orthopedic adapter modules specialized for Hindi and Punjabi, while English leverages the shared representation directly. They also design a deterministic selective-verification layer that combines confidence thresholds, evidence consistency checks, and language-risk screening to defer uncertain predictions for human review instead of accepting them automatically.
A large curated orthopedic clinical corpus containing 134,979 naturally authored notes with structured diagnostic categories (spinal, musculoskeletal, bone, hip, other, unknown) is used. The data supports both a controlled, balanced label distribution setting (18,000 records evenly sampled) and a natural-prevalence setting. Evaluations include accuracy, per-class metrics, ROC-AUC, AUPRC, expected calibration error (ECE), and cross-language stability. IndicBERT-HPA consistently outperforms task-only fine-tuned multilingual transformers and zero-shot instruction-tuned large language models (LLMs) on all metrics, especially under natural prevalence with substantial class imbalance. With selective verification, automatic acceptance accuracy improves from 71.5% to 84.4% at 72.3% coverage, reducing unsafe errors by routing uncertain cases to clinicians.
These results underscore the benefit of joint domain- and language-aware adaptation combined with calibrated confidence and evidence-driven deferral for enhancing reliability and safety in multilingual clinical decision support.
Key findings
- IndicBERT-HPA achieves average Macro-F1 of 0.8792, Macro-AUROC of 0.894, and AUPRC of 0.902 on the natural-prevalence orthopedic dataset across English, Hindi, and Punjabi.
- Zero-shot instruction-tuned LLMs perform substantially worse than task-adapted encoders with language-dependent instability and lower closed-set classification accuracy.
- The deterministic selective verification layer improves selective accuracy to 84.4% and selective Macro-F1 to 0.76 at 72.3% coverage on a 5,000-record held-out subset.
- Accept-all baseline accuracy is 71.5% with Macro-F1 of 0.65, demonstrating that selective verification reduces unsafe automatic acceptance.
- Natural-prevalence class distributions show strong language-conditioned label skew (e.g., spinal complaints dominate Punjabi, hip complaints dominate English/Hindi).
- Expected calibration error (ECE) analysis demonstrates improved confidence calibration via domain adaptation and selective verification.
- Language-specific adapter routing with bottleneck residual adapters in IndicBERT-HPA enables targeted orthopedic domain specialization for Hindi and Punjabi without duplicating the whole encoder.
- Cross-language stability and per-class performance metrics reveal that domain-adaptive models better handle language-dependent variability compared with task-only fine-tuned baselines.
Threat model
The adversary context is a low-resource healthcare scenario with clinical notes in multiple regional languages and mixed scripts. The model must reliably classify orthopedic diagnoses without adversarial tampering but faces challenges from incomplete evidence, linguistic variability, label imbalance, and distribution shifts across languages. The system assumes no direct adversarial attacks but addresses reliability and uncertainty issues to avoid overconfident mistakes that could harm clinical decisions.
Methodology — deep read
The study focuses on multilingual orthopedic diagnosis classification from free-text clinical narratives in English, Hindi, and Punjabi, with diagnostic categories including spinal, musculoskeletal, bone, hip, other, and unknown. The threat model assumes a low-resource clinical environment with heterogeneous language use and no adversarial manipulation; the goal is reliable and calibrated predictions to support clinician decision-making rather than autonomous diagnosis.
Data were collected from a tertiary-care hospital in Pakistan with Indian hospital collaboration, comprising over 60,000 de-identified orthopedic clinical notes per language. After cleaning and label refinement by orthopedic physicians, 134,979 notes were retained for natural-prevalence evaluation. A controlled balanced subset of 18,000 records was created by sampling 1,000 instances per class per language to enable fair evaluation under uniform class distribution. The natural-prevalence dataset retained real-world class imbalance reflective of clinical reality.
Four transformer-based models were evaluated as baselines: XLM-RoBERTa (multilingual general purpose), IndicBERT (Indic language pretrained), mDeBERTa (multilingual with disentangled attention), and DistilBERT (task-fine-tuned English-centric lightweight model). The main novel model, IndicBERT-HPA, extends IndicBERT by introducing lightweight language-specific orthopedic adapter heads for Hindi and Punjabi only, implemented as bottleneck residual modules with ReLU activations, projecting the shared IndicBERT [CLS] representation into a domain-specialized space. English inputs bypass the adapter to retain the general shared encoder.
Training used supervised cross-entropy loss on diagnostic labels, optimizing all encoder and adapter parameters end-to-end. The training regime, hyperparameters, optimizer details, hardware specifics, and random seed control were not fully detailed in the source but involved standard practices for fine-tuning transformer encoders with classification heads.
Evaluation employed multiple metrics: accuracy, precision, recall, class-specific and macro-averaged F1 scores, ROC-AUC, area under precision-recall curve (AUPRC), and expected calibration error (ECE). Critically, the evaluation distinguished results on the controlled balanced distribution versus the natural-prevalence distribution to assess robustness and calibration under realistic label skew. Language-conditioned performance was computed per language (English, Hindi, Punjabi) to expose cross-lingual stability.
Zero-shot instruction-tuned large language models (LLMs) were also evaluated on the task, applying prompts for fixed-label classification without task-specific training, to contrast with fine-tuned specialized encoders.
A deterministic selective-verification layer analyzed model predictions post-hoc to decide whether to automatically accept or defer for human review. It combined three signals: prediction confidence (confidence gating with threshold), symptom–diagnosis evidence consistency (assessing whether model output symptoms matched expected category), and language-consistency risk (higher deferral for riskier languages or language-model mismatches). The verification function thus outputs accept or defer decisions, separating diagnostic prediction from decision authorization.
Selective accuracy, coverage (percentage auto-accepted), deferral rate, accepted error count, and unsafe accepted error reduction were reported to quantify the tradeoff between performance and human-in-the-loop oversight.
End-to-end, a test instance in Hindi would be tokenized and encoded by IndicBERT, then passed through the Hindi-specific orthopedic adapter module, followed by the linear classification layer producing a probability distribution over diagnostic classes. The highest probability label is chosen as prediction and its confidence score evaluated by the verification layer rules. If confidence is low or evidence checks fail, the case is deferred for review, otherwise accepted.
No explicit code release or model weights were mentioned. The dataset is not public due to clinical sensitivity but described in detail to support reproducibility. The paper provides sufficient architectural and methodological detail to replicate IndicBERT-HPA and the verification layer given access to similar data.
Technical innovations
- Introduction of IndicBERT-HPA, a domain-adaptive multilingual encoder augmenting IndicBERT with language-aware orthopedic adapter heads specialized for Hindi and Punjabi clinical narratives.
- Deterministic selective-verification layer combining confidence gating, symptom–diagnosis evidence consistency checking, and language-risk screening to decide automatic acceptance or deferral for human review without modifying the base classifier.
- Evaluation protocol incorporating controlled balanced and natural-prevalence data distributions to analyze multilingual orthopedic decision support under realistic label skew and cross-language variability.
- Systematic comparison of task-fine-tuned multilingual transformer encoders, zero-shot instruction-tuned large language models, and domain-adaptive architectures in a low-resource multilingual clinical domain.
Datasets
- Multilingual Orthopedic Clinical Narrative Corpus — 134,979 records — sourced from tertiary-care hospital in Pakistan with Indian hospital collaboration, includes English, Hindi, Punjabi clinical notes with curated diagnostic labels.
- Controlled Balanced Subset — 18,000 records — constructed by sampling 1,000 per diagnostic class per language for balanced evaluation.
Baselines vs proposed
- DistilBERT fine-tuned baseline: accuracy ~71.5%, Macro-F1 ~0.65 (accept-all prediction) vs IndicBERT-HPA: 84.4% selective accuracy, 0.76 selective Macro-F1 at 72.3% coverage.
- Zero-shot instruction-tuned LLMs: substantially lower Macro-F1 and unstable cross-language performance vs task-fine-tuned IndicBERT-HPA achieving Macro-F1 0.8792 and Macro-AUROC 0.894.
- XLM-RoBERTa and mDeBERTa: inferior natural-prevalence performance compared with IndicBERT-HPA, indicating adapter-based domain adaptation benefits.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.31512.
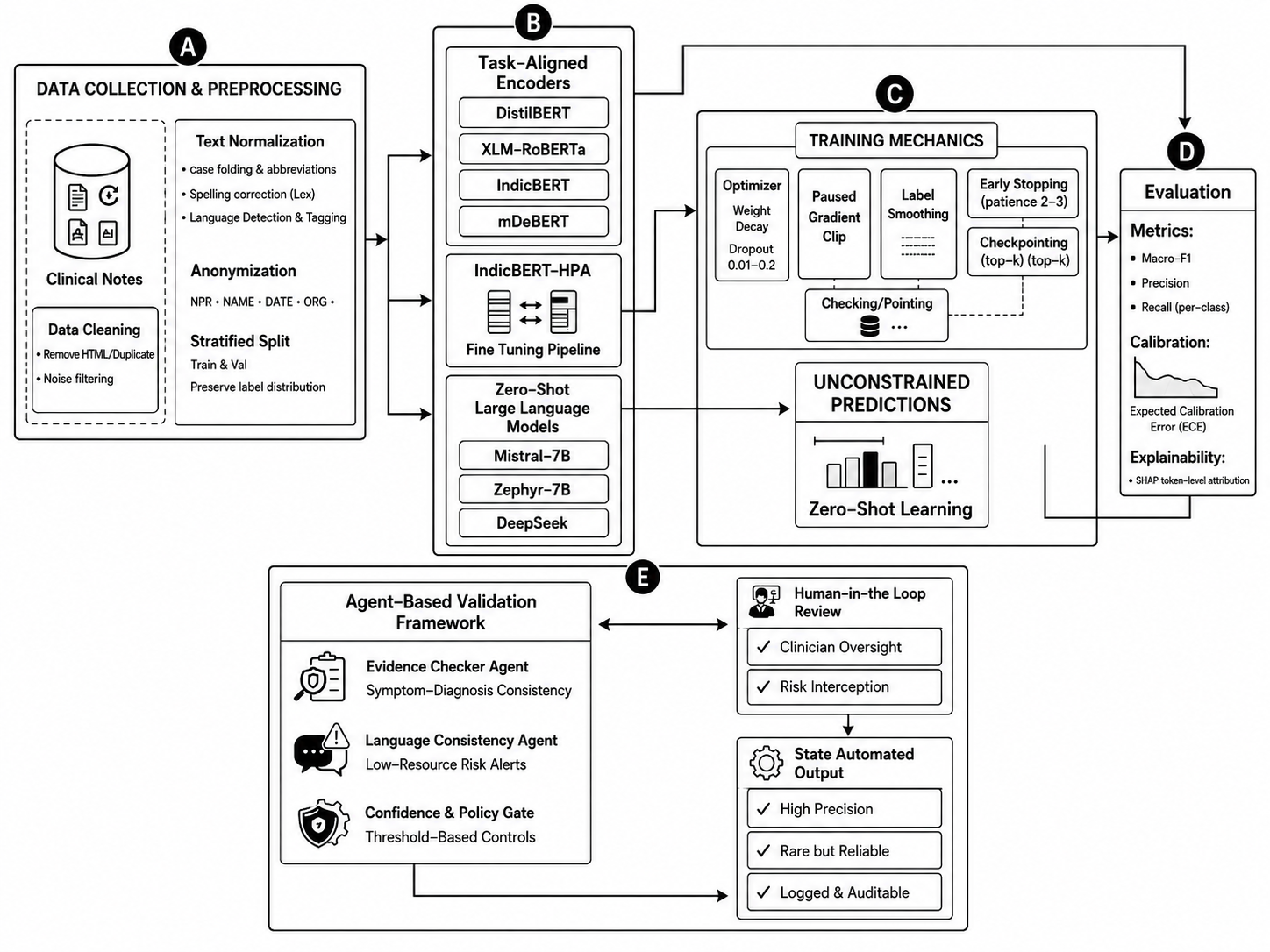
Fig 1: Overview of the proposed multilingual orthopedic decision-support framework. The pipeline integrates task-aligned trans-
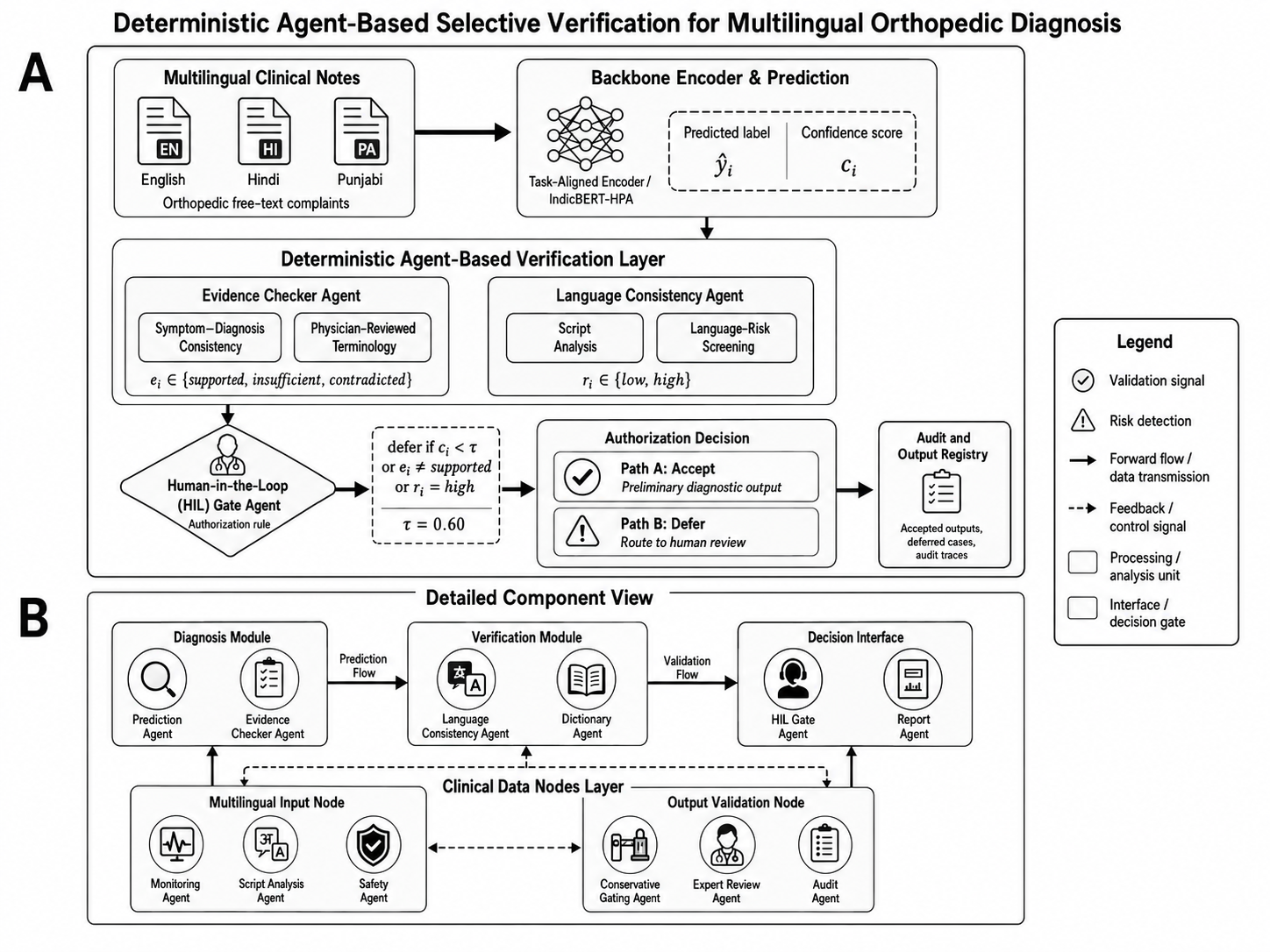
Fig 3: Deterministic selective-verification layer combining confidence gating, symptom–diagnosis evidence checking, language-risk
Limitations
- Dataset derived from a single tertiary-care hospital with collaboration but limited geographic diversity, which may limit generalizability.
- No prospective clinical evaluation or human-in-the-loop validation reported; selective verification effectiveness demonstrated only retrospectively.
- Training and evaluation details such as hyperparameters, optimizer choices, random seeds, and hardware environments are incompletely specified, limiting reproducibility precision.
- Selective verification does not generate alternative predictions or actively improve base model after deferral; it defers but does not adapt.
- Natural-prevalence setting class imbalance poses difficulty for minority category recognition despite macro-averaged metrics.
- Zero-shot LLM evaluation includes no task-specific fine-tuning or prompt engineering optimizations, possibly underestimating LLM potential.
Open questions / follow-ons
- How would the system perform in real-time prospective deployment with active clinician-in-the-loop validation and feedback?
- Can the selective verification framework be extended to incorporate automated corrective suggestions or alternative candidate outputs rather than only deferral?
- What is the impact of adapting or fine-tuning zero-shot instruction-tuned LLMs with small in-domain multilingual clinical data for orthopedic diagnosis?
- How generalizable is the IndicBERT-HPA domain-adaptive approach to other low-resource clinical specialties or languages beyond Hindi and Punjabi?
Why it matters for bot defense
From a bot-defense and CAPTCHA engineering perspective, this work highlights critical lessons about handling multilingual, low-resource text inputs in safety-sensitive classification tasks. The approach of integrating language-aware adaptation modules into a shared multilingual encoder offers a blueprint for improving model robustness to linguistic heterogeneity and label skew, common in real-world user-generated data. Moreover, the deterministic selective verification layer exemplifies a lightweight, rule-based mechanism to defer uncertain automated decisions, reducing error rates when full autonomous prediction confidence is insufficient. This strategy aligns with CAPTCHAs' goals of balancing automation with human review where ambiguity exists.
Practitioners could adapt similar modular adapter architectures for language-specific feature extraction and apply post-classification verification layers to enforce reliability constraints on suspicious or low-confidence predictions. Such designs help manage distributional shifts and multilingual challenges by explicitly modeling language risk and evidence consistency. The careful evaluation under both controlled and natural prevalence distributions also stresses the importance of robustness testing beyond aggregate accuracy metrics in bot-detection pipelines that deal with diverse language populations and data imbalances.
Cite
@article{arxiv2605_31512,
title={ Reliable Multilingual Orthopedic Decision Support from Clinical Narratives: Language-Aware Adaptation and Verification-Guided Deferral },
author={ Danish Ali and Li Xiaojian and Sundas Iqbal and Farrukh Zaidi },
journal={arXiv preprint arXiv:2605.31512},
year={ 2026 },
url={https://arxiv.org/abs/2605.31512}
}