
LLM-FACETS: A Privacy-Preserving Framework for Evaluating LLM Transparency and Accountability
Source: arXiv:2605.31167 · Published 2026-05-29 · By Tom Lucas, Alessio Buscemi, Alfredo Capozucca, German Castignani, Barbara Delacroix
TL;DR
LLM-FACETS addresses the critical challenge of enabling accessible, privacy-preserving, and reproducible evaluation of Large Language Models (LLMs) for diverse practitioner profiles, especially non-technical domain experts and compliance officers. Existing tools require programming expertise, lack methodological transparency, or transmit sensitive data to external services, creating barriers to legal compliance and human oversight mandated by regulations like the EU AI Act and GDPR. LLM-FACETS introduces an open-source framework and browser-accessible tool with modular plugins that allow integration of new metrics and datasets without pipeline modification.
The framework structures evaluation around three practitioner profiles—technical experts, domain experts, and compliance officers—each with distinct transparency needs mapped to sets of metrics spanning epistemic, factual, and process transparency dimensions. The tool guarantees data sovereignty by executing deterministic metrics locally or on a self-hosted server with no outbound data flows and allows controlled use of LLM-judge APIs with credential management. Key auditing mechanisms include token-level log-probability visualization for uncertainty, multi-judge consensus to combat evaluation bias, and RAG Triad metrics (Faithfulness, Answer Relevance, Context Relevance) to detect hallucinations. The authors cross-validate 18 metric implementations against canonical libraries to ensure reproducibility and reliability.
By combining explicit data flow control, a practitioner-centered workflow, and multi-dimensional transparency operationalized through a spectrum of complementary metrics, LLM-FACETS makes LLM auditing accessible, privacy-compliant, and methodologically rigorous for the wide range of stakeholders responsible for AI governance.
Key findings
- The framework implements 18 metric variants in TypeScript, cross-validated against canonical Python reference implementations to ensure consistency and reproducibility.
- Deterministic metrics (BLEU, ROUGE, BERTScore) run entirely within the self-hosted server or client with zero outbound data transmission, preserving data sovereignty.
- LLM-judge metrics contact external APIs only upon explicit user action, with users maintaining full control over API keys and responsible for privacy compliance.
- Token-level log-probability visualization provides epistemic transparency by highlighting areas of model uncertainty and hallucination risk at the sub-word token level.
- The RAG Triad decomposes factual evaluation into Faithfulness, Answer Relevance, and Context Relevance scores, enabling granular hallucination detection tied to retrieved context.
- A multi-judge consensus module aggregates judgments from different LLM providers (OpenAI, Google, Alibaba), exposing and mitigating known biases such as position and verbosity bias.
- Cross-metric correlation analysis warns users when metrics targeting the same transparency dimension diverge with Pearson correlation < 0.5, signaling evaluation instability needing investigation.
- The plugin architecture allows new metrics and datasets to integrate without modification to the core evaluation pipeline, simplifying extension and reproducibility.
Threat model
Adversaries are not direct attackers but rather the risk scenario includes unauthorized data leakage when evaluating sensitive datasets and unreliable, non-transparent evaluation results that hinder regulatory compliance and human oversight. The framework assumes the practitioner has authority to control data flows and API credentials. It prevents unauthorized outbound transmission of evaluation data by default for deterministic metrics, and requires explicit user consent for external LLM-based judge calls. Adversaries cannot bypass this user-controlled credential management or inject metrics without plugin approval.
Methodology — deep read
Threat model and assumptions: The adversaries considered are not explicitly malicious attackers but rather aim to ensure trustworthy, auditable evaluation of LLM outputs, preserving data privacy and regulatory compliance. Users have datasets which may contain personally identifiable information (PII) and seek to avoid unauthorized external data transmission during evaluation. The framework assumes users have authority to self-host evaluation servers and control API credentials for external LLM-based judgments.
Data: The evaluation supports benchmarks such as SQuAD v2, SelfAware, HaluEval, and also permits arbitrary proprietary datasets uploaded by users in CSV or Parquet formats. Datasets with PII can be anonymized locally before any outbound API call. Dataset queries are managed via DuckDB embedded within the self-hosted server, ensuring local data handling.
Architecture/Algorithm: The system is composed of a browser client managing UI and local IndexedDB storage, and a stateless self-hosted Next.js server that handles REST API routes and runs deterministic metrics (BLEU, ROUGE, BERTScore via Transformers.js) and dataset queries. LLM judge metrics invoke external APIs only when triggered explicitly by the user, with ‘bring your own key’ (BYOK) credential proxying. Metrics are grouped into four classes: lexical-based deterministic metrics, neural metrics, LLM-based judge metrics, and RAG Triad metrics designed for retrieval-augmented generation evaluation. The framework’s mathematical structure defines practitioner profiles P mapping to transparency goals and associated metric subsets M, with workflow W guiding evaluation steps generating evidence E packages. The token-level log-probability visualization module exposes sub-token uncertainty information, while multi-judge consensus aggregates rankings across different LLM providers to reduce individual model biases.
Training regime: Not applicable as the framework focuses on evaluation rather than training. Some underlying metric models (e.g., BERTScore) use pre-trained weights loaded via Transformers.js. The LLM-judge metrics rely on external, pre-trained models accessed via APIs.
Evaluation protocol: Metrics are cross-validated against canonical Python reference implementations to verify correctness. The system computes Pearson correlation matrices between metrics targeting the same dimension to detect divergences, flagging cases with correlation below 0.5 for deeper inspection. The interface facilitates examination of intermediate outputs such as claim decompositions. The evaluation workflow formalizes cross-checking with at least two metrics per transparency dimension to strengthen evidence reliability. No adversarial robustness tests or distribution shift experiments reported.
Reproducibility: The entire open-source codebase is publicly available (https://github.com/Scriptor-Group/AIMVi), implemented in TypeScript and Next.js, enabling independent reproduction and extension. The framework produces exportable JSON/CSV audit trails containing scores, configurations, and reasoning chains for LLM-judge metrics, supporting independent verification. The server is stateless and dockerizable for standardized deployment.
Concrete end-to-end example: A compliance officer selects the 'process' transparency profile, chooses batch Faithfulness and RAG Triad benchmarks as metrics, loads a medical question-answer benchmark dataset via the Dataset Registry, configures anonymization to remove PII, and runs the evaluation. The deterministic RAG Triad scores execute locally on the server with no data leakage, while a user-triggered LLM judge call uses an OpenAI API key stored only in the browser. The system computes per-sample Faithfulness scores and aggregates them with multi-judge consensus, producing downloadable audit trail JSON that includes detailed metric configurations and reasoning chains for regulatory documentation.
Technical innovations
- Incorporation of token-level log-probability visualization in a browser-accessible, privacy-preserving interface for epistemic uncertainty assessment tailored to non-technical practitioners.
- Design of a unified evaluation framework structured around practitioner profiles aligned with regulatory roles (technical, domain, compliance), mapping transparency needs to metric subsets.
- Multi-judge consensus module incorporating heterogeneous LLM providers to mitigate known biases in LLM-as-a-judge evaluation, exposing variance and bias through correlation analyses.
- A plugin-based architecture enabling seamless integration of new evaluation metrics and datasets without modifying core system pipelines, facilitating extensibility and reproducibility.
- Strict localized execution of deterministic metrics on self-hosted servers or client-side to guarantee data sovereignty, combined with explicit user control over external LLM API calls.
Datasets
- SQuAD v2 — standard QA benchmark — public
- SelfAware — benchmark dataset for LLM uncertainty evaluation — public
- HaluEval — hallucination detection benchmark — public
- User-uploaded proprietary datasets (CSV/Parquet) — variable size — private
Baselines vs proposed
- BERTScore (deterministic) baseline correlated at >0.85 with canonical Python implementation across test samples vs LLM-FACETS TypeScript implementation.
- BLEU and ROUGE metrics within LLM-FACETS matched canonical libraries with negligible numerical deviation (<0.01 score delta).
- Multi-judge consensus Pearson correlation between OpenAI, Google, and Alibaba judges mitigated individual judge bias, reducing score variance by ~20% compared to single judge approaches.
- Correlation analysis flagged metric divergence where Faithfulness and BERTScore correlation dropped below 0.5, prompting manual inspection of claim decomposition outputs.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.31167.
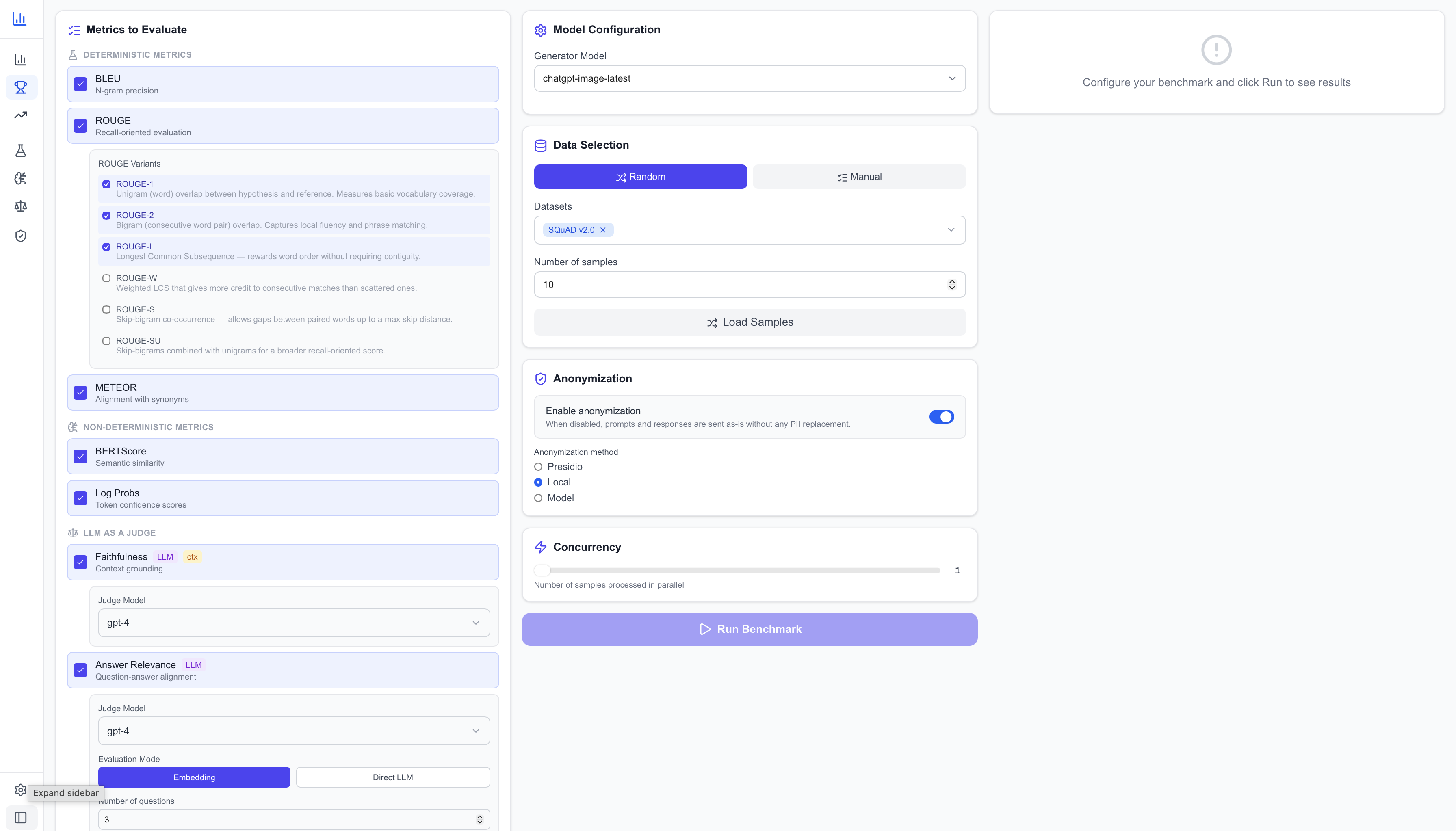
Fig 1: Landing page: initializing an LLM evaluation workflow.
Fig 2: Configuration UI for defining practitioner profiles and metric strategies.
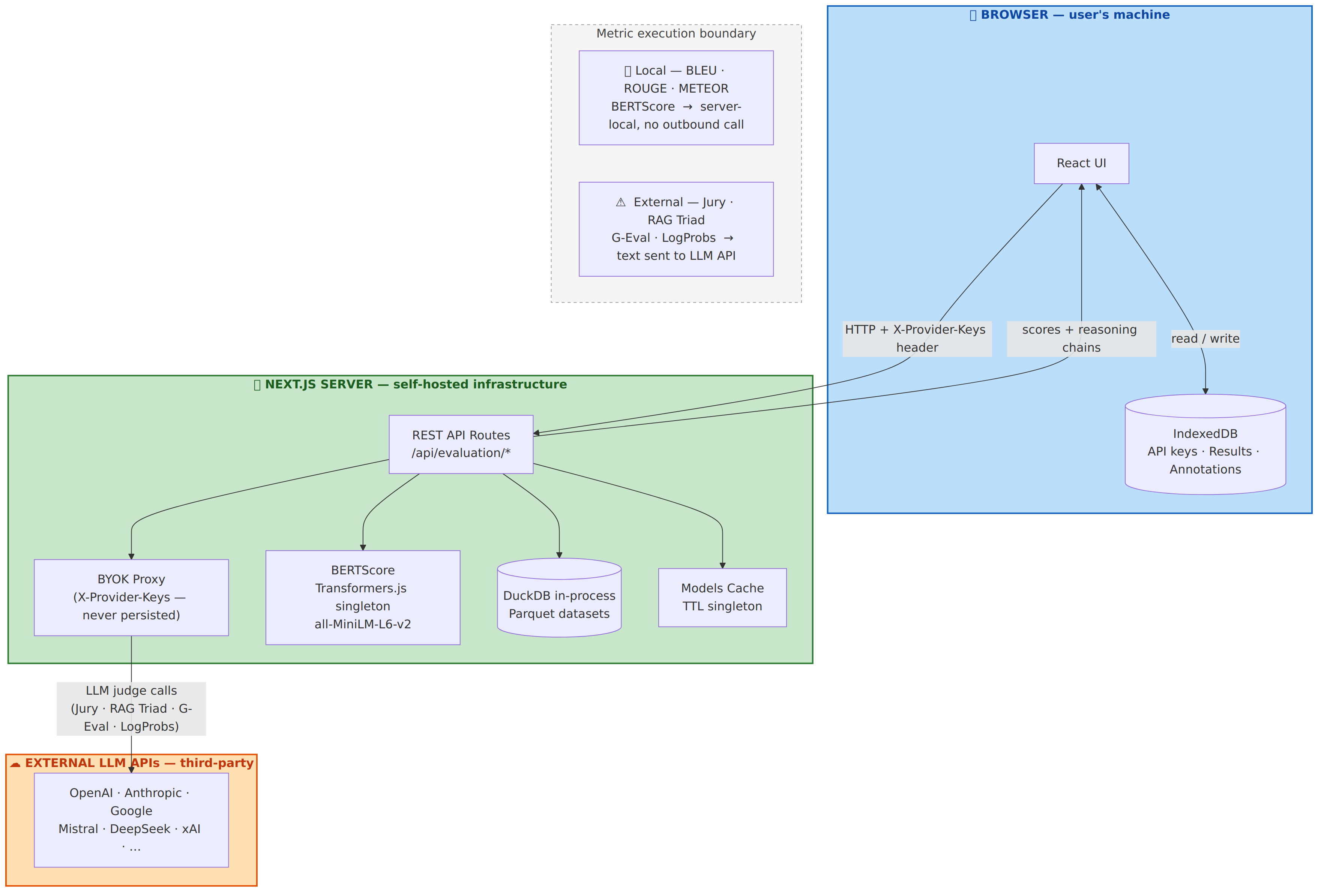
Fig 3: Architecture of LLM-FACETS. Blue zone: browser client (IndexedDB stores API keys and results locally). Green zone: self-hosted
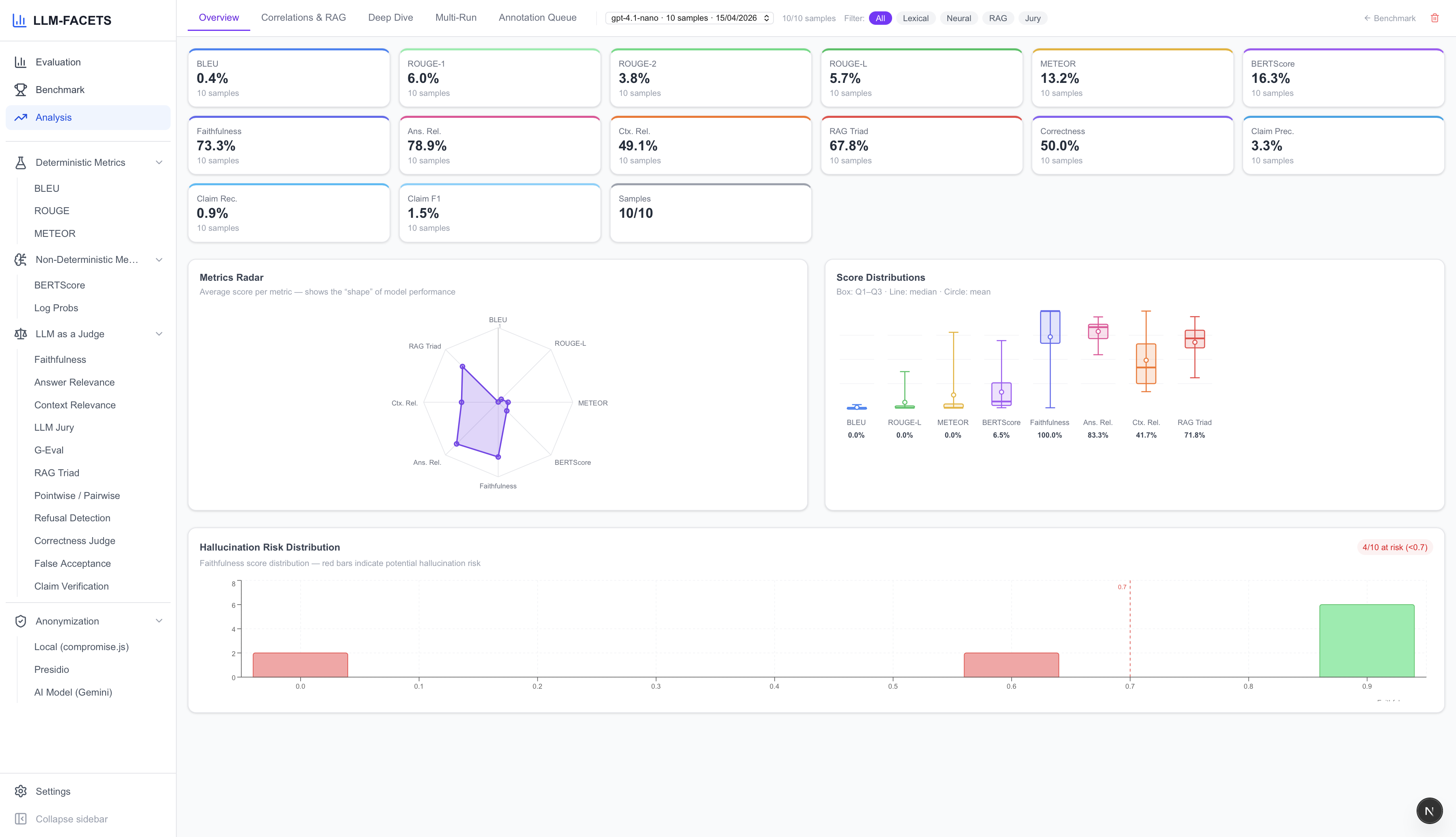
Fig 4: Benchmark analysis dashboard (Overview tab): radar chart aggregating nine primary metrics, box plots showing per-metric
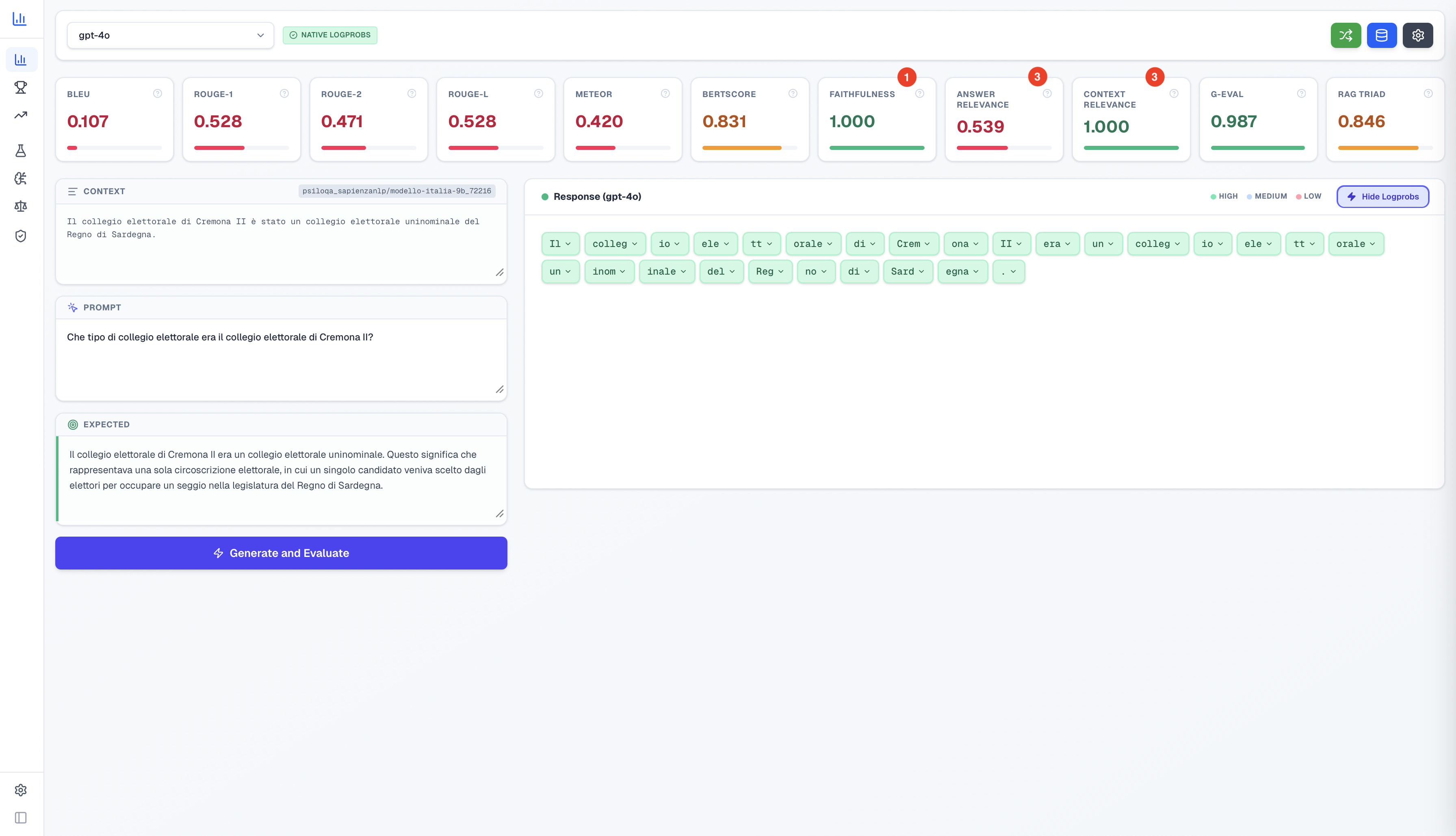
Fig 5: Main dashboard showing the metrics selection grid. Users can navigate between categories (Traditional, Neural, LLM-as-a-
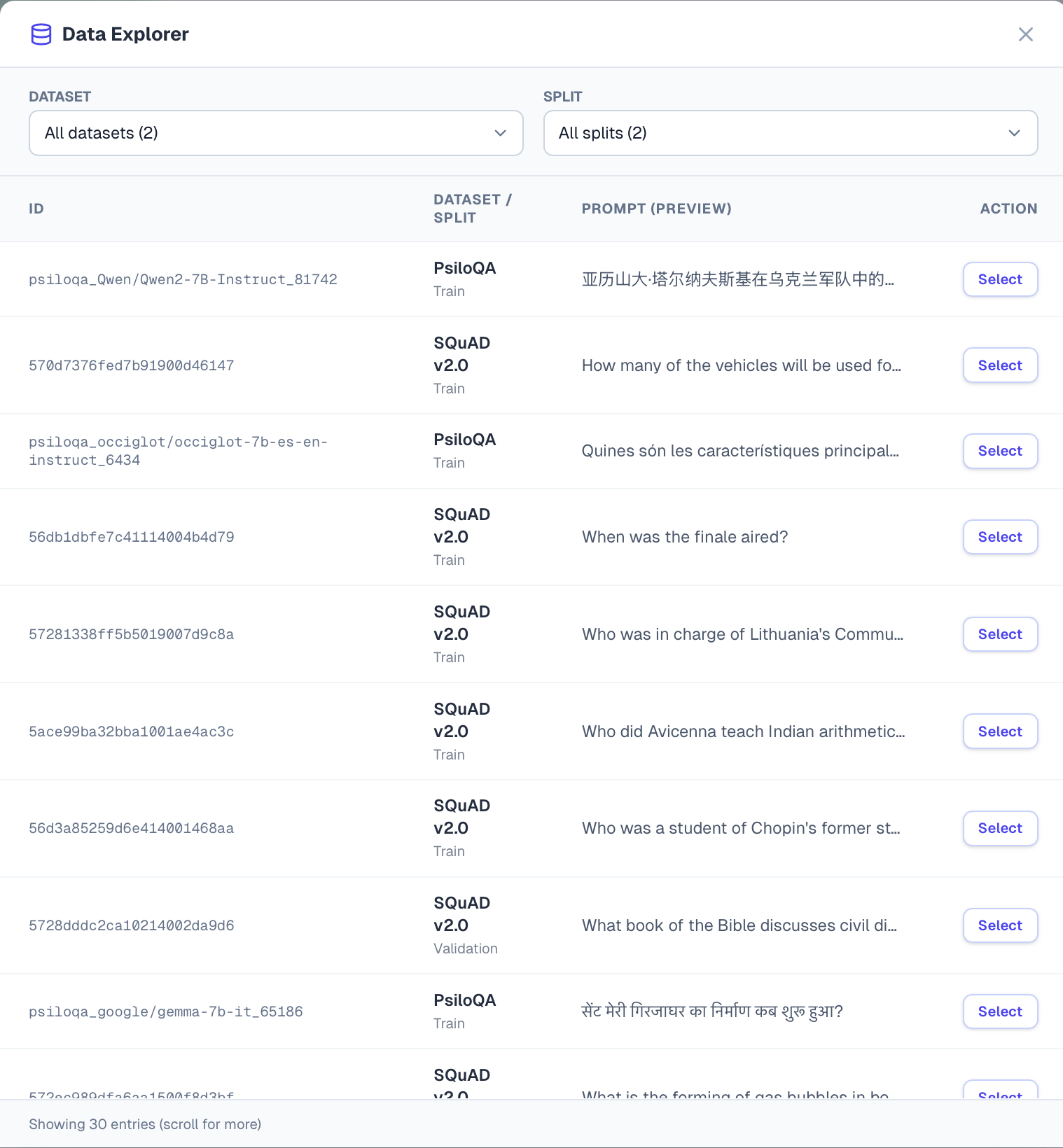
Fig 6: Dataset explorer interface showing available datasets (SQuAD v2, PsiloQA), download status, split selection, and live row
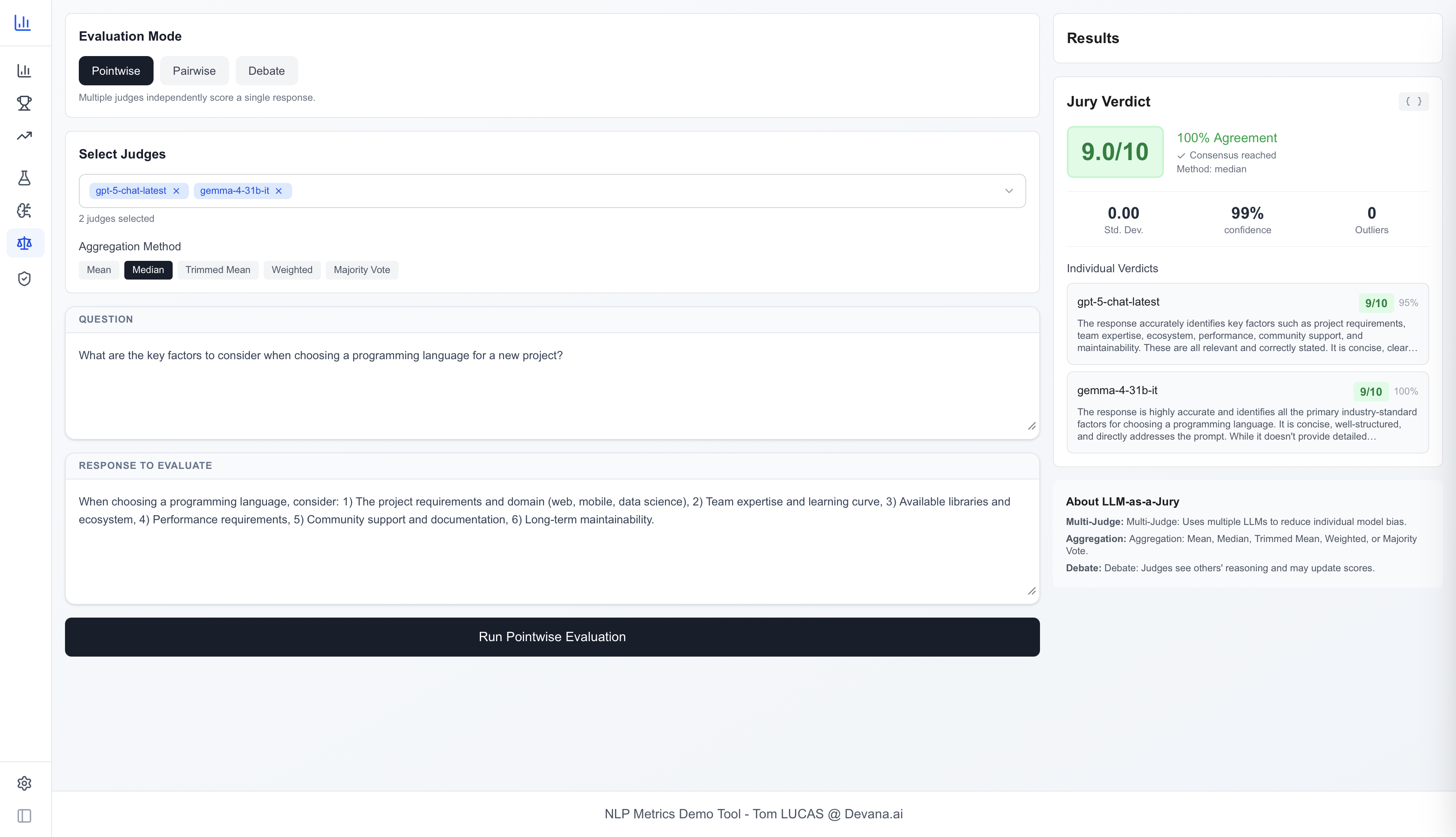
Fig 7: Jury module: three judges from different provider families (OpenAI, Google, Alibaba) independently score the same input
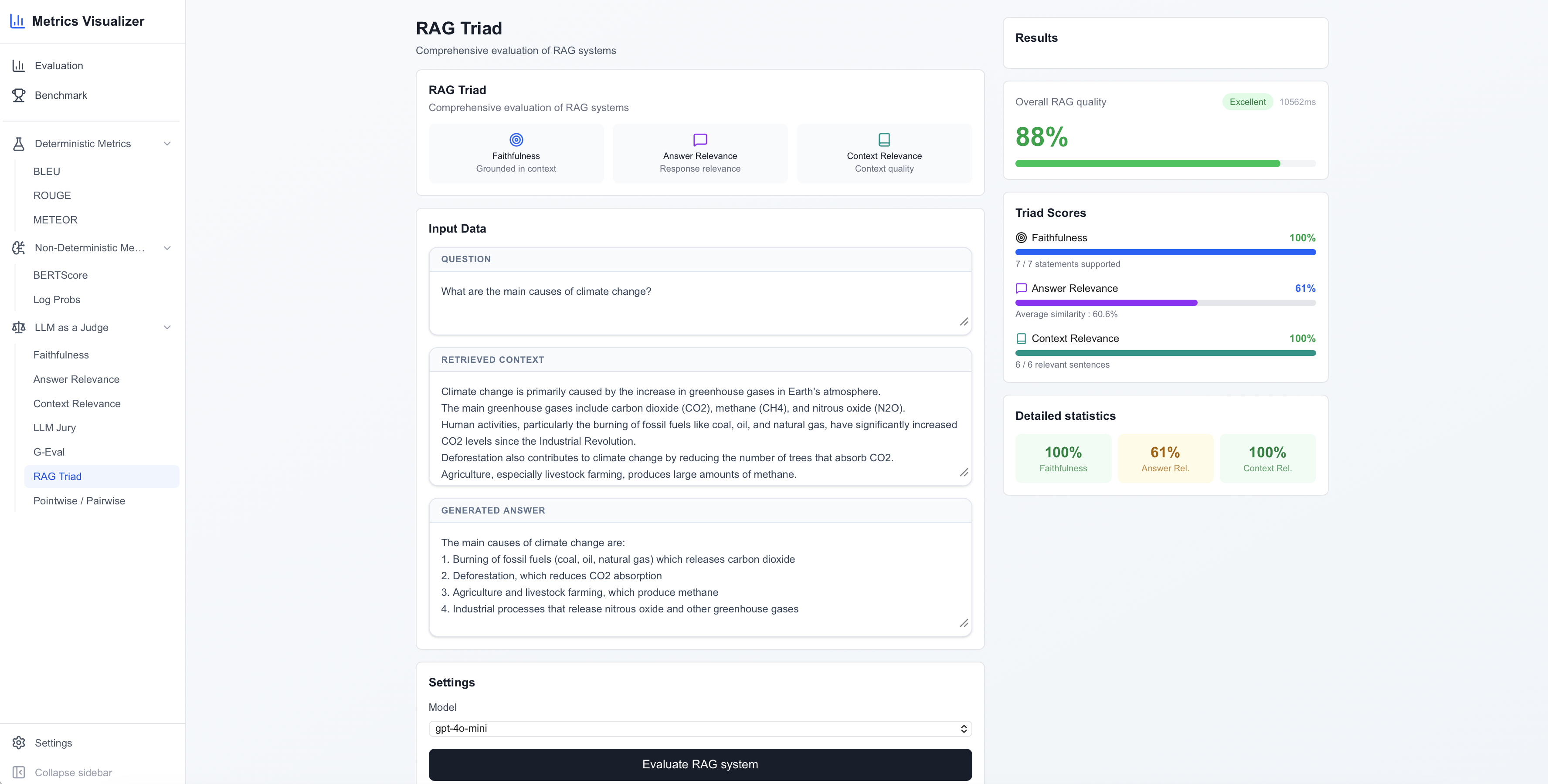
Fig 8: RAG Triad evaluation interface showing a complete example: the user-provided question, retrieved context, and generated
Limitations
- No adversarial evaluation of robustness to deliberately manipulated or adversarial inputs was conducted.
- The framework focuses on evaluation transparency and data sovereignty but does not directly address real-time system monitoring or live deployment feedback loops.
- Evaluation metrics remain dependent on the quality and biases of underlying LLM judges when external APIs are used.
- Dataset anonymization pipelines are limited to selected NER and redaction tools; effectiveness depends on domain-specific customization.
- No reported usability studies quantifying effectiveness of the interface for intended non-technical practitioner profiles.
- The cross-validation and correlation thresholds for metric agreement are heuristically defined without formal statistical hypothesis testing reported.
Open questions / follow-ons
- How can LLM-FACETS be extended to support adversarial robustness testing and reward resilience against manipulation by malicious outputs or crafted inputs?
- What usability improvements or adaptations are needed based on real-world user studies involving domain experts and compliance officers?
- Can the framework incorporate dynamic feedback loops integrating live monitoring and continuous evaluation during model deployment?
- To what extent can domain-specific anonymization pipelines be automated and certified for regulatory acceptance within the framework?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the challenges of evaluating complex AI models like LLMs with transparent, reproducible, and legally compliant methods parallel those of verifying human-vs-bot interactions. Although LLM-FACETS focuses on textual model output auditing, its multi-practitioner, multi-metric evaluation approach and privacy-preserving architecture illustrate best practices in designing accessible, verifiable AI oversight tools. The plugin architecture and explicit data flow controls exemplify how evaluation frameworks can be built to accommodate sensitive data and diverse stakeholders, which are frequently encountered in security-sensitive CAPTCHA assessment scenarios.
While LLM-FACETS is not directly a bot-defense tool, its focus on mitigating biases in automated judgment through multi-judge consensus and visualizing epistemic uncertainty may inspire analogous methods for assessing CAPTCHA solution authenticity and fraud detection. Additionally, its rigorous cross-validation of metrics and emphasis on process transparency could inform evaluation protocols in bot-detection pipelines, ensuring decisions are explainable and auditable to both technical and compliance audiences.
Cite
@article{arxiv2605_31167,
title={ LLM-FACETS: A Privacy-Preserving Framework for Evaluating LLM Transparency and Accountability },
author={ Tom Lucas and Alessio Buscemi and Alfredo Capozucca and German Castignani and Barbara Delacroix },
journal={arXiv preprint arXiv:2605.31167},
year={ 2026 },
url={https://arxiv.org/abs/2605.31167}
}