
Effects of Vertex Merging & Splitting on Large Coauthorship Networks: A Counterfactual Analysis
Source: arXiv:2605.31555 · Published 2026-05-29 · By Jinseok Kim
TL;DR
This study investigates how author name ambiguity, specifically vertex merging and splitting errors caused by initials-based disambiguation (IBD) methods, distort the structural properties of large-scale coauthorship networks. Using three large empirical coauthorship datasets from computer science (DBLP) and biomedicine (MEDLINE), the author compares network statistics computed on gold-standard algorithmically disambiguated data with those computed under two widely used IBD heuristics: first-initial-based disambiguation (FIBD) and all-initials-based disambiguation (AIBD). The analysis simulates varying error rates of merged or split vertices to quantify the impact on nine network metrics, revealing systematic biases introduced by IBD. Unlike past works limited to small or sampled datasets, this study applies counterfactual error simulations on large real-world data, extending the understanding of how merging especially causes considerable distortions in network analyses. The results demonstrate that IBD methods tend to underestimate vertex counts, assortativity, transitivity, and average shortest path length while overestimating average degree, density, centralization, and largest component size. Consequently, author collaboration appears artificially more concentrated, integrated, and less fragmented, raising concerns about the validity of conclusions drawn from IBD-disambiguated coauthorship studies. The work highlights the necessity for rigorous, algorithmic name disambiguation and careful interpretation of coauthorship network metrics affected by disambiguation errors.
Key findings
- In DBLP, 54.38% of author entities are merged using FIBD, while 40.53% are merged under AIBD (Table 2).
- As merging ratio increases from 0% to 100%, average degree, network density, centralization, and largest component ratio increase, often exceeding 5% measurement error thresholds with as little as 6-11% merging (Figures 1 and 2).
- Vertex count, unique edges, transitivity (clustering coefficient), and average shortest path length decrease as merging increases, reflecting underestimation of these properties.
- Degree assortativity exhibits a U-shaped pattern in response to merging errors due to altered connections involving high-degree vertices.
- Splitting errors have notably smaller effects than merging; even at 100% splitting in MEDLINE, several metrics stay within 5% measurement error (Figure 3).
- FIBD causes more pronounced network distortions than AIBD because it merges a larger fraction of entities.
- The distortion caused by merging is nonlinear and difficult to estimate directly from merging ratio alone, unlike splitting where errors scale roughly linearly.
- Errors induced by IBD may have significantly biased prior findings on power-law degree distributions and triadic closure principles in coauthorship networks.
Threat model
The adversary is the systematic, non-malicious ambiguity in author name strings in bibliographic metadata which causes flawed vertex identity representation in coauthorship networks. These ambiguities lead to merging of distinct authors into a single vertex or splitting a single author into multiple vertices when disambiguation methods rely on simplified heuristics such as initials matching. The adversary cannot prevent access to the full name data or sophisticated disambiguation algorithms but exploits data incompleteness and inconsistency inherent in author name reporting.
Methodology — deep read
Threat Model & Assumptions: The study assumes the adversary is the inherent ambiguity in author name strings as recorded in bibliographic data, which leads to errors in vertex identity resolution. The adversary is not malicious but systemic—existing disambiguation heuristics (IBD) are the cause of errors, merging distinct authors into one vertex or splitting one author into multiple vertices. The benchmark or "ground truth" is algorithmically disambiguated datasets considered highly accurate (>99% accuracy).
Data: The experiment uses three large-scale datasets. DBLP (computer science) contains approx. 1.4 million papers from 1991 to 2009, with 817,628 algorithmically disambiguated authors. MEDLINE (biomedicine physiology papers subset) contains approx. 1.55 million papers from 1991-2009, with 1,839,407 algorithmically disambiguated authors. Author-ity provides a high-accuracy disambiguation for MEDLINE, and DBLP team disambiguates via algorithms plus manual review. Author name strings and disambiguation labels are obtained from these datasets. The author name strings are transformed into IBD formats (FIBD and AIBD).
Architecture / Algorithm: The key methodological innovation is a counterfactual simulation framework that progressively introduces vertex merging or splitting errors into these gold-standard networks. Merging errors combine author vertices sharing the same surname + first-initial (FIBD) or surname + all initials (AIBD). Splitting errors artificially fragment an author's entity into multiple vertices. These errors are introduced randomly in proportions N% = 0 to 100% in increments of 1%. For each error level, the coauthorship network is reconstructed and nine key network metrics recalculated.
Training / Experimental Regime: Rather than model training, the key process is systematic error simulation. For each dataset, vertices are randomly selected to be merged or split according to IBD labels. This controlled procedure enables study of how varying error ratios affect network statistics. Because each analysis depends on random sampling of entities to merge or split, results are averaged or plotted to show continuous trends.
Evaluation Protocol: Nine standard coauthorship network metrics are used: number of vertices, number of unique edges, average degree, network density, degree centralization, ratio of largest connected component, average shortest path length, degree assortativity, and clustering coefficient (transitivity). The gold-standard networks serve as baseline values. For each metric, percentage error relative to baseline is computed under simulated merging/splitting errors. Measurement error below 5% is considered acceptable for illustration. Both FIBD and AIBD are evaluated to show differences. Figures 1-3 visualize metric changes across error levels. Metrics are assessed for nonlinear trends, U-shaped patterns (assortativity), and relative robustness. The study also notes that DBLP data format prevents splitting errors from arising in practice.
Reproducibility: The paper uses publicly available datasets: DBLP XML and Author-ity (MEDLINE disambiguated data). The disambiguation heuristics (FIBD and AIBD) are straightforward string-based transformations. Exact simulation code release is not indicated, but the approach is described in enough detail (steps 1-6 in section 2.4) for replication by researchers with access to data. The Author-ity dataset is publicly accessible though it requires licensing acknowledgment.
A concrete example: For DBLP, the author entities disambiguated by algorithms serve as gold standard. Using FIBD, merging occurs whenever authors share surname + first initial. At 50% merging, 50% of author entities originally uniquely identified are randomly selected and merged into single vertices according to FIBD rules. The coauthorship network is reconstructed with these merged vertices, and metrics like average degree and density are recalculated. The deviation from gold standard shows that average degree increases >5%, indicating significant inflation by merging errors. Similarly, vertex count decreases due to mergers reducing unique nodes. This demonstrates how name ambiguity systematically changes network topology metrics under initial-based disambiguation.
Technical innovations
- Introduction of a counterfactual simulation framework to progressively introduce vertex merging and splitting errors into large-scale empirical coauthorship networks for systematic study of metric distortion.
- Comparative analysis of two commonly used initials-based disambiguation heuristics (FIBD and AIBD) applied on the same gold-standard datasets, quantifying differences in error patterns and their network effects.
- Use of nine diverse coauthorship network metrics measured continuously over 0-100% merging/splitting to identify which metrics over/underestimate properties under disambiguation errors.
- Identification of nonlinear and metric-specific error responses, such as the U-shaped pattern in degree assortativity caused by merging, which had not been clearly reported for large bibliometric networks previously.
Datasets
- DBLP — ~1.4 million papers (1991–2009) — publicly available XML with algorithmic/manual disambiguation
- MEDLINE (Author-ity Physiology subset) — ~1.55 million papers (1991–2009) — publicly available with ML-based disambiguation
Baselines vs proposed
- DBLP algorithmic disambiguation baseline vertex count: 817,628 vs FIBD merged: reduced by up to 54.38%
- MEDLINE algorithmic baseline vertex count: 1,839,407 vs FIBD merged: reduced by up to 58.38%
- Average degree (DBLP) baseline vs FIBD merging causes increase exceeding 5% error at ~11% merged vertices
- Transitivity (clustering coefficient) baseline less affected, errors over 5% appear only beyond ~6% merged (DBLP, MEDLINE)
- At 100% splitting (MEDLINE), measurement errors remain under 5% for multiple metrics, showing less sensitivity to splitting
- Degree assortativity shows U-shaped changes with increasing merging errors, deviating from the baseline by over 5%
- Largest component ratio baseline increases significantly (>5%) even at low merging percentages
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.31555.
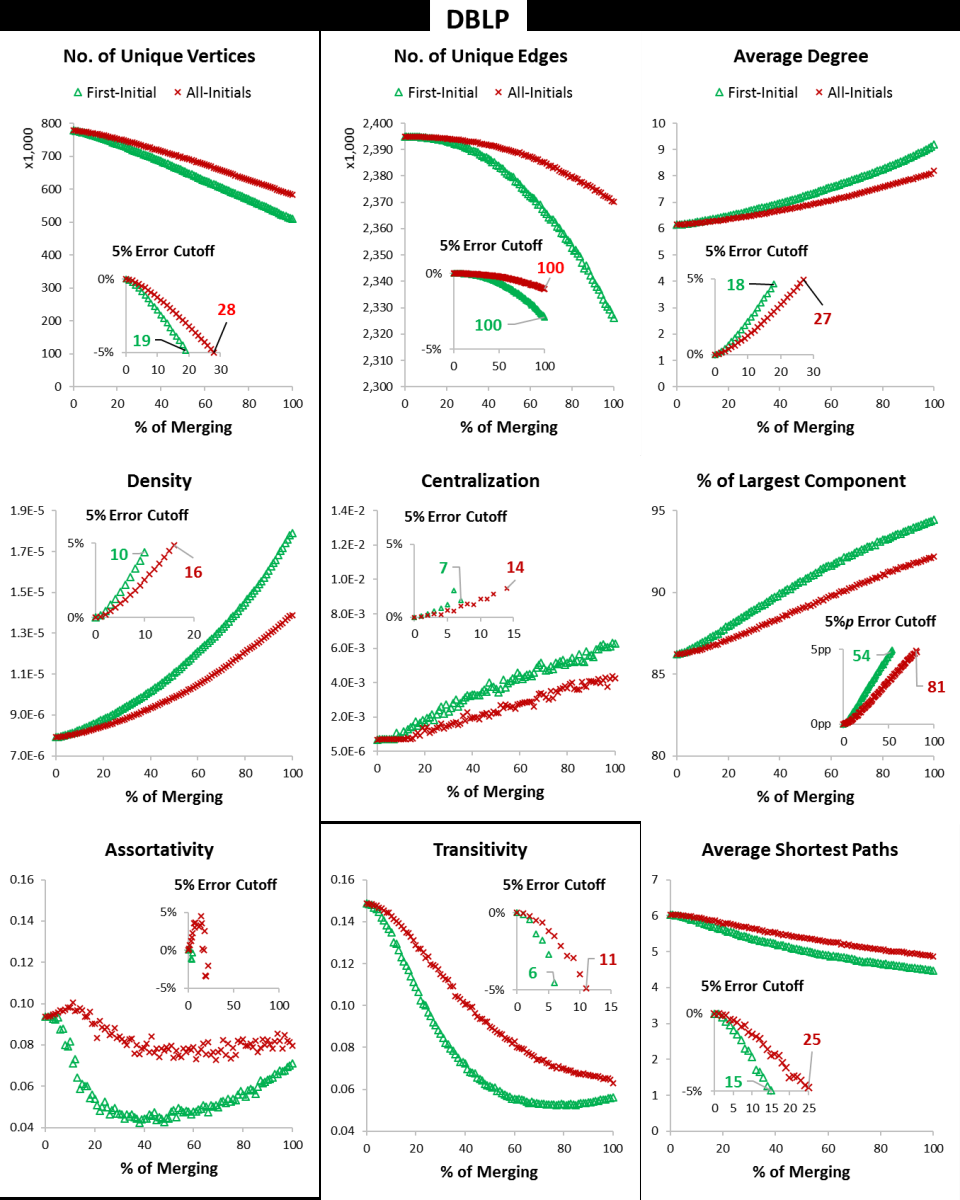
Fig 1: Changes of Coauthorship Network Properties at Various Merging Levels for DBLP
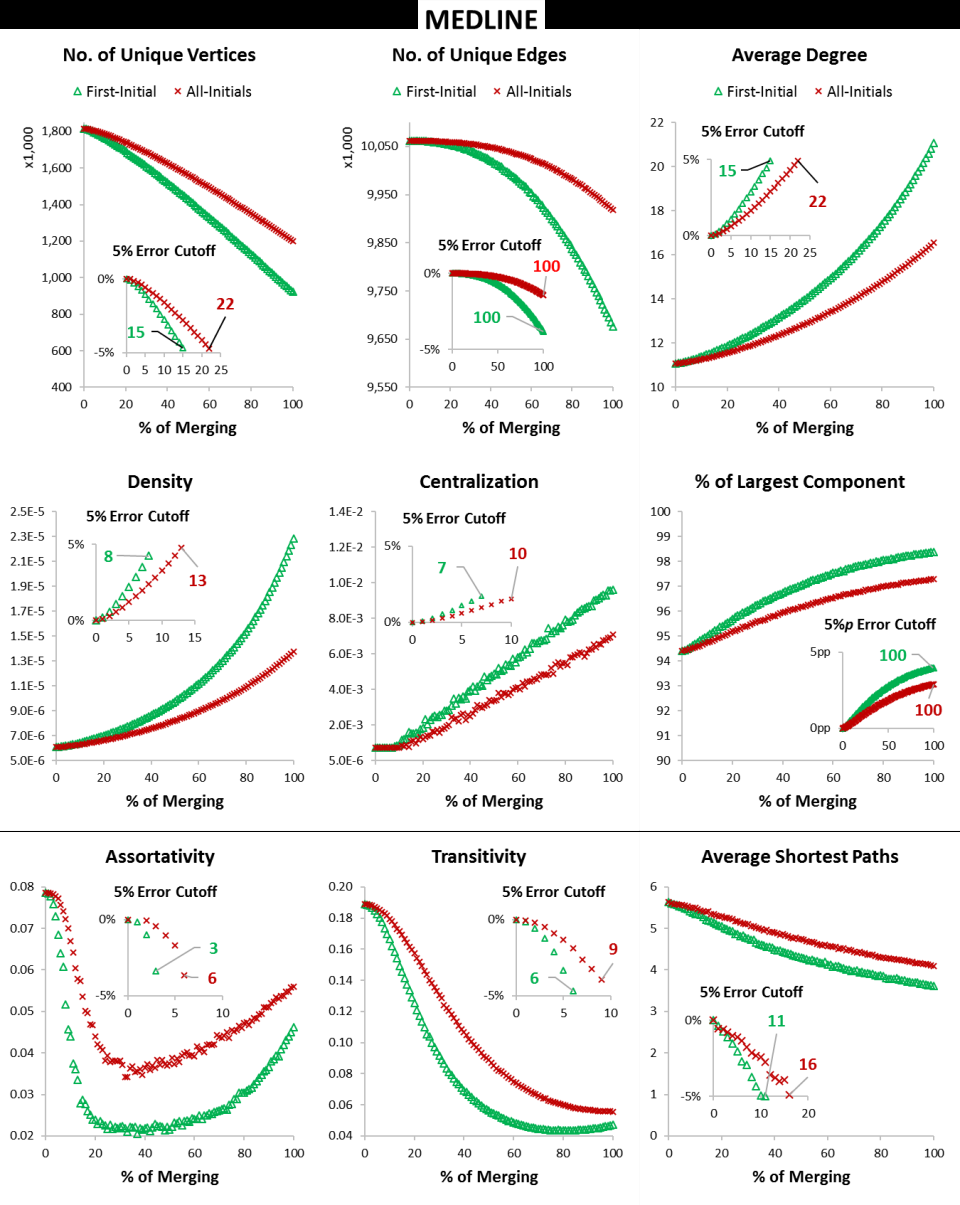
Fig 2: Changes of Coauthorship Network Properties at Various Merging Levels for MEDLINE
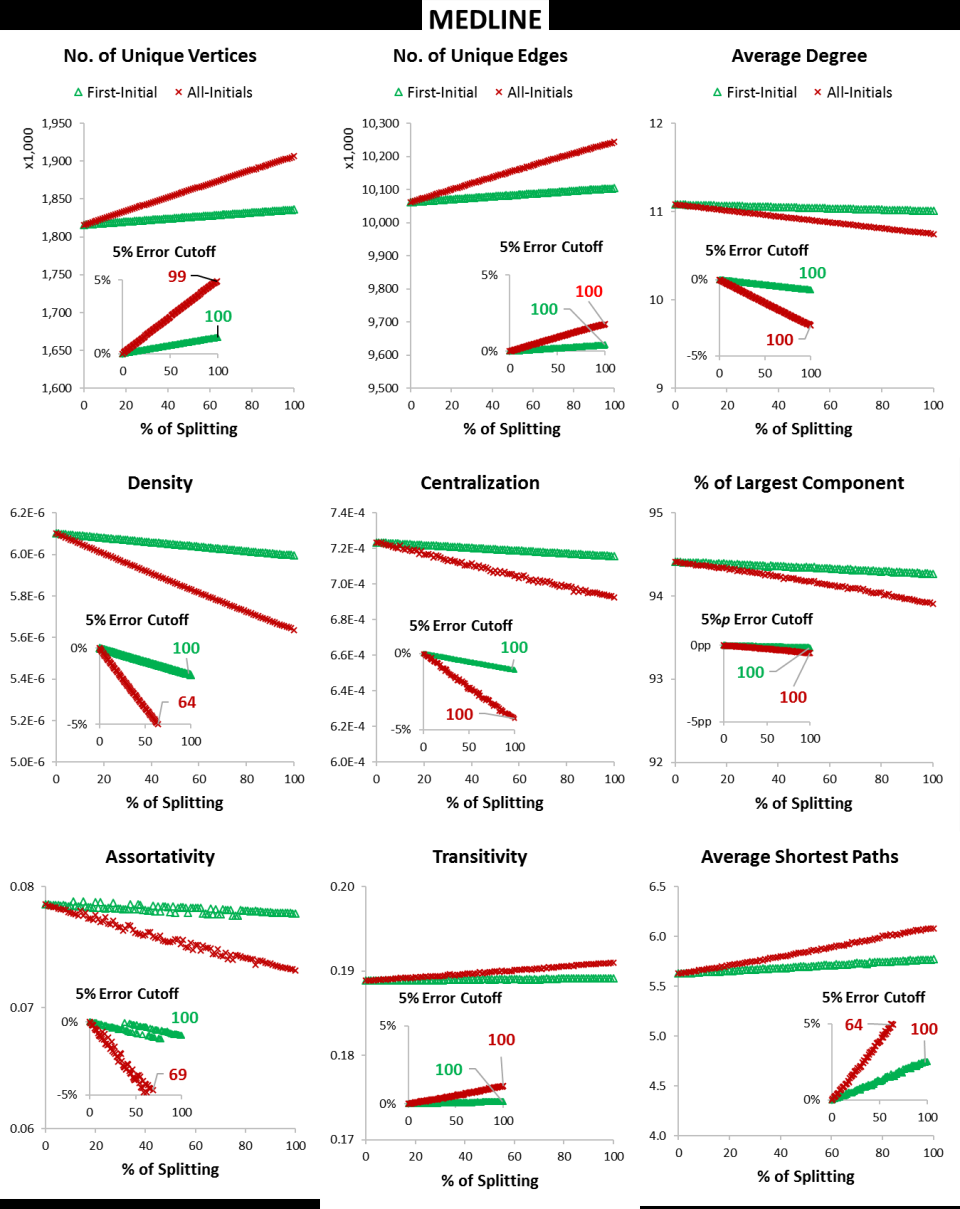
Fig 3: Changes of Coauthorship Network Properties at Various Splitting Levels for MEDLINE
Limitations
- Simulations on only two domains (computer science and biomedicine), so generalizability to other research fields is unknown.
- Splitting and merging effects are simulated separately; combined, interactive impacts remain unexplored.
- The DBLP data format prevents splitting errors, limiting evaluation of splitting on all datasets.
- Degree to which these simulation error rates reflect actual error levels in past studies remains uncertain.
- The 5% measurement error threshold for acceptability is arbitrary and may not apply uniformly across contexts.
- No adversarial or malicious attempts were modeled; only errors due to heuristic disambiguation were studied.
Open questions / follow-ons
- How do combined merging and splitting errors jointly affect network metrics when varied simultaneously?
- What is the impact of these disambiguation errors on dynamic or temporal coauthorship networks over time?
- Can advanced machine learning disambiguation methods be made accessible and easy-to-use for broader coauthorship network practitioners?
- How do network distortions influence downstream bibliometric analyses such as citation impact, career trajectory, or gender bias studies?
Why it matters for bot defense
Although this paper focuses on coauthorship network analyses rather than bot-defense per se, its findings underscore a broader principle highly relevant to CAPTCHA and bot-defense practitioners: data preprocessing and entity resolution errors can fundamentally distort network-based metrics used to profile or detect bots. Just as author name disambiguation error impacts collaboration network properties, analogous identity ambiguity or merging/splitting errors in user or device nodes within fraud detection networks could lead to misestimated connectivity, centrality, or community embedding. Practitioners designing defense systems that rely on graph metrics should be cautious about identity resolution heuristics and validate their robustness to such errors. The nonlinear and metric-specific distortions demonstrated here suggest bot-defense systems should incorporate mechanisms to handle or quantify identification uncertainty. Furthermore, simulating counterfactual errors as done in this study could serve as a diagnostic tool to evaluate feature stability under identity ambiguity in CAPTCHA behavioral analytics or device fingerprinting. While the domain is different, the principle of carefully validating disambiguation and its effects on network-based measures is a key takeaway.
Cite
@article{arxiv2605_31555,
title={ Effects of Vertex Merging & Splitting on Large Coauthorship Networks: A Counterfactual Analysis },
author={ Jinseok Kim },
journal={arXiv preprint arXiv:2605.31555},
year={ 2026 },
url={https://arxiv.org/abs/2605.31555}
}