
CoFiDA-M: Concept-Aware Feature Modulation for Cross-Domain Adaptation with Image-Only Inference
Source: arXiv:2605.31591 · Published 2026-05-29 · By Nurjahan Sultana, Moi Hoon Yap, Xinqi Fan, Wenqi Lu
TL;DR
This paper addresses the challenge of domain shift in AI-based skin cancer screening, specifically the drop in performance when models trained on expert dermoscopic images (source domain) are applied to consumer-grade clinical images (target domain). Existing domain adaptation methods fail to leverage crucial clinical semantic concepts such as ulceration or pigmentation, which remain invariant across domains but are rarely used for adaptation. A recent foundation model, MONET, can provide noisy probabilistic concept scores, but these are available only at training time, not at inference, creating a deployment paradox for image-only clinical screening tools.
To solve this, the authors propose CoFiDA-M, a privileged information (PI) framework employing a teacher-student architecture. The teacher network uses MONET concept probabilities to guide a FiLM-based feature modulation that semantically edits intermediate visual features. An image-only student is then trained by knowledge distillation to reproduce the teacher's concept-informed feature space and predictions, thus embedding clinical reasoning directly into the student's weights. At test time, the student requires only images, enabling practical deployment. Evaluated on a challenging multi-dataset, cross-domain benchmark with 6 unseen datasets, CoFiDA-M's image-only student substantially outperforms state-of-the-art methods, especially improving melanoma recall by over 22% absolute on clinical target images. This represents a strong generalizable solution leveraging noisy privileged metadata during training without requiring it at test time.
Key findings
- CoFiDA-M improves average AUROC on clinical target datasets from 58.39% (source-only) to 67.50%, a +9.11% absolute gain over strong baselines including TENT (62.32%) and DALUPI (54.54%) (Table 2).
- Melanoma recall on clinical target images increases by +22.12% absolute from 55.77% (source-only) to 77.89% with CoFiDA-M (Table 3).
- Image-only student achieves 84.92% melanoma recall on dermoscopic source data, improving over 63.55% baseline without degradation on source domain (Table 3A).
- Ablations show the full FiLM + confidence-gating teacher outperforms variants without gating or without FiLM by 7-11% AUROC on clinical data (Table 4B).
- Distillation matching teacher's post-edit features (uT) alongside logits yields better student AUROC and recall than logit-only or pre-edit feature alignment (Table 4C).
- Training uses a confidence-gated embedding of MONET probabilistic concept scores to guide teacher's FiLM modulation, improving semantic invariance across domains (Sec 3.3).
- Two-view consistency losses on unlabeled target data stabilize teacher learning, with dynamic confidence threshold starting at 0.95 decaying to 0.7 to select pseudo-labels (Sec 3.4.2).
- Evaluation uses strict out-of-domain testing on six unseen datasets, showing cross-dataset robustness of CoFiDA-M (Sec 4).
Threat model
The adversary is the domain shift between source expert dermoscopic images and target consumer clinical images, representing unknown changes in camera, lighting, and patient demographics. The adversary does not actively modify images or metadata but causes performance degradation due to distribution mismatch. The system assumes access to privileged semantic concepts (MONET scores) at training only, unavailable at inference, requiring robust feature representations that generalize without concept inputs. Adversarial attacks or tampering capabilities are not considered.
Methodology — deep read
The threat model assumes a domain shift between source labeled dermoscopic images and unlabeled clinical target images. The goal is to build a melanoma classifier robust to target distribution variability without access to privileged metadata at test time.
Data includes MILK datasets for training: MILK Dermoscopic (labeled source) and MILK Clinical (unlabeled target). Testing is performed on six held-out unseen datasets with dermoscopic and clinical images (MIDAS, Derm7pt, Fitzpatrick, HAM10000). Images are labeled with melanoma or other diagnoses. MONET, a foundation model trained on medical literature, provides per-image noisy probabilistic concept scores, which serve as privileged information only at training.
The architecture includes an EfficientNet-B2 backbone extracting a 1408-d penultimate feature vector v=f_θ(x). A teacher network modulates v with concept-derived conditioning via FiLM layers: separate scale (γ) and shift (β) parameters are predicted by applying a 2-layer MLP ψ to a gated embedding vector c_t formed from MONET concept probabilities and confidence gates based on Gini impurity. The modulated feature u=γ⊙v+β is then classified by a linear layer h producing logits ℓ and softmax probabilities p.
The teacher is trained on labeled source images using a focal loss with class weighting addressing melanoma imbalance. Orthogonality and norm constraints regularize the FiLM edit vector e=u−v to prevent trivial solutions and excessive shifts. For unlabeled target data, a Mean Teacher approach maintains an EMA teacher to provide stable weak-view pseudo-labels. Consistency losses enforce agreement between weak and strong augmentations for logits, features, and edits using KL divergence and MSE losses with dynamic confidence thresholding selecting reliable samples.
After teacher convergence, an image-only student replaces FiLM by a residual edit head ψ_edit predicting feature adjustment from image features only: u_S=v_S+ψ_edit(v_S). The frozen teacher's modulated features u_T and logits ℓ_T serve as distillation targets, using a Kullback-Leibler loss on softened class predictions and MSE feature alignment losses. This forces the student to internalize the teacher's concept-guided feature editing without privileged inputs.
At inference, only the image-only student is used, requiring no MONET concepts or teacher updates; melanoma prediction is thresholded at p_1≥0.5.
Training runs for up to 50 epochs with early stopping on validation AUROC; batch size 32; AdamW optimizer; cosine annealing learning rate schedule. Data augmentations match those across baselines, including weak and strong views for consistency loss. Five random seeds support statistical stability. Experiments run on Apple Mac Studio with M3 Ultra GPU.
Evaluation reports AUROC and melanoma recall on test splits for source and six unseen datasets, directly testing cross-domain generalization with no additional adaptation or metadata.
Code and training details are released for reproducibility. Dataset partitions are strictly separated, with no target labels or MONET metadata accessible at evaluation.
As a concrete example, an image with dermoscopic label and MONET concepts is processed by the teacher which modulates intermediate features via FiLM conditioned on the gated concept embedding, producing logits and edited features. The student then learns from these targets using image input only, effectively baking clinical semantic knowledge into the image-only model for robust cross-domain performance.
Technical innovations
- Use of MONET foundation model's noisy probabilistic clinical concept scores as privileged information to guide feature modulation during domain adaptation.
- Confidence-gated embedding scheme based on Gini impurity to weight concept influence in feature modulation to reflect uncertainty.
- Integration of FiLM (Feature-wise Linear Modulation) conditioned by clinical concept embeddings within teacher model to semantically edit image features.
- Novel knowledge distillation scheme where image-only student matches teacher's entire concept-edited feature representation, not just predictions, baking clinical reasoning into student weights.
- Dynamic confidence thresholding and two-view consistency losses applied in a Mean Teacher UDA framework to stabilize adaptation on unlabeled target domain data.
Datasets
- MILK10K (Dermoscopic and Clinical) — 5,244 images (452 melanoma, 4,792 other) — public
- Derm7pt (Dermoscopic and Clinical) — 1,016 images (254 melanoma, 762 other) — public
- Fitzpatrick (Clinical) — 11,603 images (344 melanoma, 11,259 other) — public
- HAM10000 (Dermoscopic) — 7,012 images (780 melanoma, 6,232 other) — public
- MIDAS Dermoscopic — 1,048 images (96 melanoma, 952 other) — public
- MIDAS Clinical — 2,101 images (186 melanoma, 1,915 other) — public
Baselines vs proposed
- Source Only: Clinical AUROC = 58.39% vs CoFiDA-M Clinical AUROC = 67.50%
- TENT: Clinical AUROC = 62.32% vs CoFiDA-M Clinical AUROC = 67.50%
- DALUPI (Privileged Info): Clinical AUROC = 54.54% vs CoFiDA-M Clinical AUROC = 67.50%
- Source Only: Clinical melanoma recall = 55.77% vs CoFiDA-M recall = 77.89%
- Mean Teacher (Standard UDA): Clinical recall = 77.67% vs CoFiDA-M recall = 77.89%
- Ablation no confidence-gating teacher: Clinical AUROC drops from 83.81% to 75.24% (teacher model)
- Ablation distillation (logit KD only): Clinical AUROC = 64.10% vs full distillation = 67.50%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.31591.
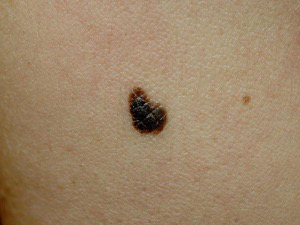
Fig 1: CoFiDA-M resolves the Deployment Paradox: metadata

Fig 2 (page 1).
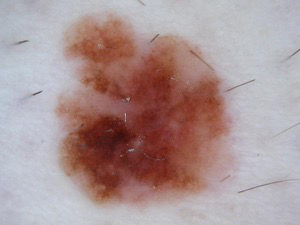
Fig 3 (page 1).
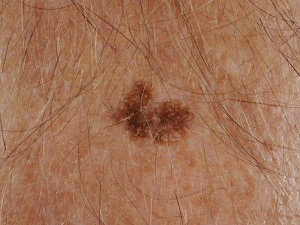
Fig 4 (page 1).
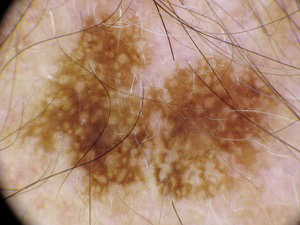
Fig 5 (page 1).

Fig 6 (page 1).
Fig 2: Overview of the CoFiDA-M Framework. Our method has three parts. (A) & (B) Stage 1: Teacher Training. A concept-guided
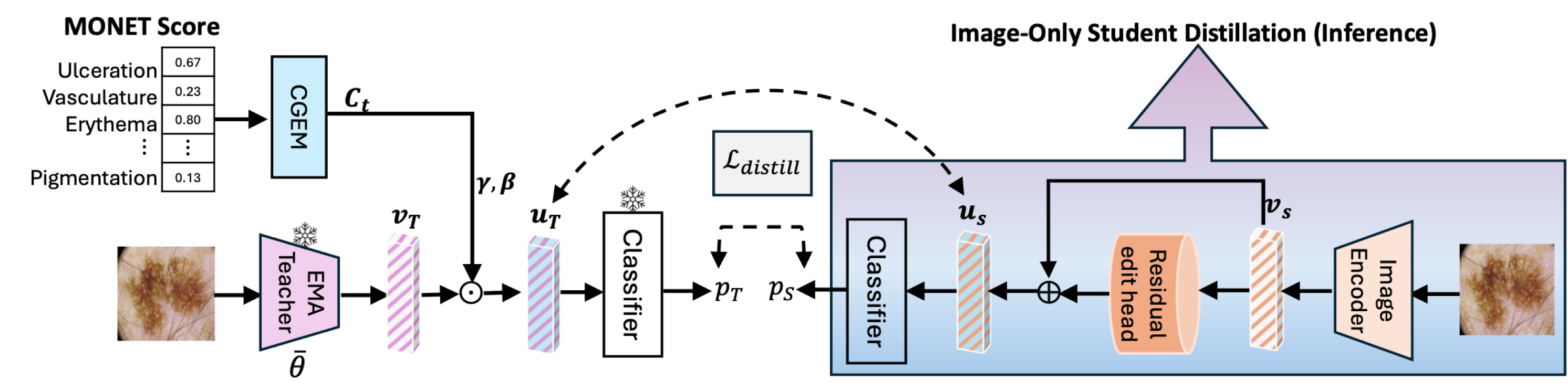
Fig 3: Eight dataset examples across dermoscopic and clinical
Limitations
- MONET clinical concept annotations are noisy probabilistic metadata requiring additional foundation model use at training time, not native to original datasets.
- Evaluation is restricted to dermatology domain; generalization to other medical or non-medical domain shifts unproven.
- No explicit adversarial or targeted worst-case domain attack tested; robustness is empirical on natural dataset shifts only.
- Dependency on MONET concept scores may limit applicability in domains without such foundation model outputs or in resource-limited settings.
- While dynamic confidence thresholds are used, the approach may still be sensitive to pseudo-label noise on unlabeled target data.
- The image-only student inherits teacher biases; interpretability of learned concept modulations at deployment is not deeply analyzed.
Open questions / follow-ons
- Can the CoFiDA-M privileged information framework be extended to other medical imaging domains lacking foundation models like MONET?
- How does the quality and noise level of privileged concept metadata affect adaptation and distillation performance systematically?
- Can the image-only student model retain explicit interpretable clinical rationale without concepts at test time?
- What is the behavior of CoFiDA-M under adversarial domain attacks or more severe distribution shifts beyond natural dataset variation?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the CoFiDA-M approach illustrates a compelling method to leverage privileged side information (noisy, probabilistic metadata) exclusively at training to improve cross-domain robustness, while deploying efficient unimodal models. This paradigm is applicable to CAPTCHA or bot recognition where metadata or annotations may be unavailable at inference but accessible in training. The confidence-gated feature modulation combined with knowledge distillation to an image-only student can enhance resilience to distribution shifts common in real-world bot behaviors without incurring runtime complexity. Furthermore, the paper's design considerations for domain-shifted deployment environments highlight the importance of semantic feature alignment beyond naive domain alignment, a principle relevant for robust bot detection and challenge generation. However, limitations include reliance on suitable privileged metadata during training and the need to verify gains under adversarial attacks, relevant for security-sensitive CAPTCHAs.
Cite
@article{arxiv2605_31591,
title={ CoFiDA-M: Concept-Aware Feature Modulation for Cross-Domain Adaptation with Image-Only Inference },
author={ Nurjahan Sultana and Moi Hoon Yap and Xinqi Fan and Wenqi Lu },
journal={arXiv preprint arXiv:2605.31591},
year={ 2026 },
url={https://arxiv.org/abs/2605.31591}
}