
Can Generative AI help people navigate Radical Moral Disagreements? The CONSIDER prototype
Source: arXiv:2605.31574 · Published 2026-05-29 · By William Hohnen-Ford, Sarah Chen, Kathryn B. Francis, Madeline G. Reinecke, Ilina Singh, David Lyreskog
TL;DR
This paper addresses the challenge of Radical Moral Disagreements (RMDs), highly polarizing issues that are identity-relevant, resistant to compromise, and often censored in public discourse. These disagreements have significant social and psychological costs, including increased affective polarization, self-censorship, and mental health impacts. Existing AI tools for deliberation, including depolarization chatbots and artificial moral advisors, are poorly suited to RMDs as they either seek consensus/moderation or focus only on individual moral reasoning without facilitating genuine engagement with opposing value systems.
The authors propose a novel AI system, CONSIDER, designed specifically to help individuals navigate RMDs through value clarification via structured disagreement. Drawing on John Stuart Mill’s epistemic theory of disagreement, CONSIDER engages users in multi-agent, stepwise interactions: clarifying the user’s position, generating a coherent opposing viewpoint, facilitating sustained reasoned disagreement, and providing reflective post-analysis of the exchange. The prototype uses Llama-3 models to instantiate these components with care to preserve a low-risk epistemic space that avoids antagonistic or identity-threatening dynamics.
While empirical evaluation is pending, the authors identify ethical, social, and psychological risks—such as tool displacement supplanting human dialogue, belief offloading to the AI’s framing, limited ideological diversity in AI-generated opposition, potential entrenchment of users’ views, and gaming the interaction as a debate. The paper’s key contribution is articulating a carefully grounded philosophical and interaction design framework for AI tools tailored to the unique challenges of RMDs, and providing an open-source prototype as an initial instantiation to guide future research and development.
Key findings
- Radical Moral Disagreements exhibit seven core features: collision, intransigence, intensity, polarization, censure, social disruption, and contested epistemologies (Table 1).
- Existing AI deliberation tools focus on reducing positional extremity or improving reasoning within individual frameworks, but fail to provide safe spaces for engaging with genuinely opposing coherent value systems.
- CONSIDER’s multi-agent architecture separates user opinion calibration, opposing value profile generation, structured disagreement, and post-conversation reflection to maintain coherent, low-risk disagreement.
- Mill’s epistemic account underpins the design goal: engagement aims at value clarification, not convergence or moderation.
- In February 2026, an interdisciplinary expert seminar with 16 participants identified risks including displacement of human discussions, belief offloading via AI framing, and the entrenchment paradox where challenge deepens convictions rather than fosters reflection.
- CONSIDER’s confirmation step partially mitigates risk of belief offloading, requiring user validation of AI-generated summaries.
- Separate agents prevent sycophantic or mirroring behavior in opposing views by using a stable, fixed opposing value profile in the disagreement stage.
- Post-interaction analysis using multiple LLMs provides users with visual summaries of agreement, disagreement, epistemic humility, and moral dimensions engaged.
Threat model
The adversary is primarily the social and psychological barriers that inhibit individuals from engaging productively with opposing moral viewpoints in highly polarized, identity-relevant RMD topics. This includes affective polarization, social censure, emotional threat, and epistemic bubbles or echo chambers. The system assumes access to user inputs and interactive dialogue but does not consider malicious attackers or adversarial exploits of the AI system itself.
Methodology — deep read
Threat Model & Assumptions: The adversary is conceptualized as the social and psychological forces discouraging engagement with opposing views in radical moral disagreements (RMDs), including identity threat, social censure, and affective polarization. The system assumes the user is willing to engage with AI to clarify values but is cautious of antagonism. It does not address active adversarial attacks or malicious manipulation but focuses on aiding individuals in epistemically risky, socially fraught moral conflicts.
Data: No large dataset is used. The system utilizes Llama-3 large language models with prompting and multi-agent orchestration. The curated set of RMD-relevant topics (e.g. immigration, abortion, war) was designed to instantiate prototypical RMDs. Users select specific concrete sub-questions to increase real-world relevance and engagement authenticity.
Architecture/Algorithm: CONSIDER employs a multi-agent LLM architecture: an opinion calibration agent elicits and summarizes the user’s stance with clarifying dialogue; an opposing profile generation agent constructs a coherent value-opposed profile including core values, non-negotiable commitments, and key counterclaims; a disagreement agent conducts rich conversational engagement from the opposing profile perspective using structured reasoned challenges and reflective questioning; finally, an analysis agent provides post-conversation reflection summarizing agreement/disagreement areas, epistemic humility, and moral dimensions present. The separation of agents and outputs ensures stable, non-reactive, genuine opposing positions and reduces sycophancy.
Training Regime: CONSIDER relies on commercially or publicly released Llama-3 models. The authors did not train new models but engineered detailed prompts and agent instructions. The system was tested empirically in an expert seminar with 16 participants who interacted with the prototype to identify risks and limitations.
Evaluation Protocol: No formal empirical user study or quantitative evaluation yet. The initial expert seminar provided qualitative feedback on usability, ethical risks, and interaction dynamics. The authors discuss open questions regarding entrenchment, reflection, and epistemic outcomes that require future formal empirical trials.
Reproducibility: The full prompting codebase and design rationale are publicly available on GitHub. Model weights (Llama-3) are external and proprietary. The curated topic list is documented. The system is a prototype; no frozen weights or large public datasets were created.
Example end-to-end flow: A user selects an RMD topic (e.g. immigration policy), specifies a concrete question (e.g. moral justification of deportations). The opinion calibration agent asks the user to state their belief, reasons, and strength of conviction, clarifies vagueness, then summarizes back for confirmation. The opposing profile generator produces a stable counter-position highlighting core opposing values and arguments. The disagreement agent engages the user in a back-and-forth conversation presenting reasoned challenges grounded in the opposing value system, reflects user reasoning, and seeks to clarify disagreement loci. After the conversation ends, an analysis agent produces a visual summary of the conversation’s structure, epistemic humility displayed, and moral dimensions emphasized, aiding the user’s reflection and value clarification.
Technical innovations
- A multi-agent LLM architecture that separates opinion elicitation, opposing position generation, structured disagreement, and reflective analysis to maintain coherence and reduce sycophancy.
- Application of Mill’s epistemic theory of disagreement as a design principle to support value clarification rather than convergence or moderation in AI-assisted moral deliberation.
- Use of a stable, AI-generated opposing value profile to prevent reactive mirroring or framing biases during live conversations.
- Incorporation of post-conversation LLM-based reflection tools analyzing agreement, epistemic humility, and moral dimensions to consolidate user insight.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.31574.
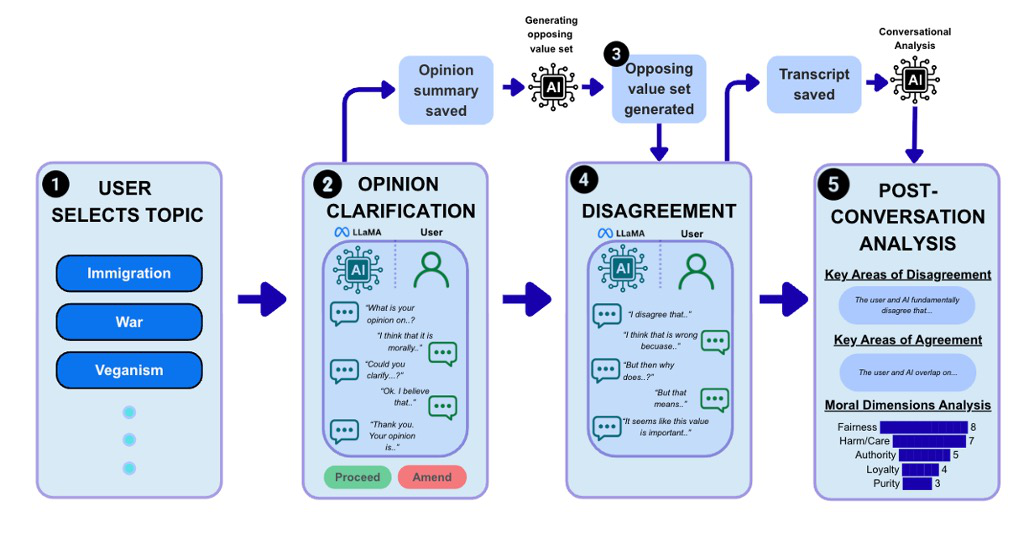
Fig 1: Overview of the CONSIDER prototype interaction flow. The system guides users
Limitations
- No formal quantitative user evaluation or randomized controlled trial to empirically measure effects on moral reasoning, belief change, or polarization.
- Potential risk of displacement, where users may prefer AI interaction over real human dialogue, undermining democratic deliberation.
- Belief offloading risk especially during opinion calibration phase, where users may adopt system-generated framing unconsciously.
- Limited diversity risk in AI-generated opposing profiles due to documented LLM political and moral biases, possibly narrowing exposure to genuine plurality.
- Unclear if exposure to disagreement leads to greater reflection or entrenchment of preexisting views (the entrenchment paradox) — needs empirical study.
- Users may treat interaction competitively (play-to-win) rather than reflectively, reducing epistemic benefits.
- The prototype currently only supports a curated set of RMD topics and a single LLM backend (Llama-3), limiting generalizability.
Open questions / follow-ons
- How do repeated uses of CONSIDER affect users’ values, epistemic humility, and willingness to engage with RMDs over time?
- Does structured engagement with AI-generated opposing views reduce or exacerbate entrenchment of identity-relevant beliefs?
- What strategies best diversify AI-generated opposing value profiles to reflect broader pluralistic moral frameworks?
- How can tools like CONSIDER be integrated effectively as bridges back to human-to-human deliberation without promoting displacement?
Why it matters for bot defense
For bot-defense and CAPTCHA engineers focused on user integrity and security, this work highlights the complexity of designing AI interactions aimed at fostering genuine user reflection rather than simplistic moderation or persuasion. The multi-agent architecture and use of structured disagreement suggest ways to design AI interactions that resist manipulation and sycophancy — considerations important for safeguarding AI-assisted user engagement in adversarial contexts. Furthermore, the ethical and psychological risks flagged underscore the need for careful evaluation when deploying AI systems that influence user’s core values or beliefs, analogous to concerns about user autonomy and consent in security-sensitive AI systems.
Practitioners aiming to build next-generation conversational agents or AI moderators might draw inspiration from CONSIDER's principled approach to disagreement, structured dialogue, and reflection facilitation, recognizing that robust AI-human interaction in high-stakes settings requires balancing challenge with user safety and trust. The paper also reminds security engineers that interactions designed with epistemic humility and transparency, as opposed to opaque persuasion, might better align with democratic principles and user respect, informing ethical AI use policies for CAPTCHA or bot-detection deployments that rely on conversational components.
Cite
@article{arxiv2605_31574,
title={ Can Generative AI help people navigate Radical Moral Disagreements? The CONSIDER prototype },
author={ William Hohnen-Ford and Sarah Chen and Kathryn B. Francis and Madeline G. Reinecke and Ilina Singh and David Lyreskog },
journal={arXiv preprint arXiv:2605.31574},
year={ 2026 },
url={https://arxiv.org/abs/2605.31574}
}