
Authentication of Copy Detection Patterns via Cross-Camera Dual-Synthetic Referencing
Source: arXiv:2605.31292 · Published 2026-05-29 · By Ivan Oleksiyuk, Roman Chaban, Slava Voloshynovskiy
TL;DR
This paper addresses the challenge of authenticating Copy Detection Patterns (CDPs), which are printed binary patterns used for low-cost anti-counterfeiting. Traditional authentication methods compare a verification camera capture directly to the original digital template, but stochastic printing variations and distortions from different cameras reduce robustness to counterfeiting and impede performance on low-end devices. Prior work modeled imaging distortions by synthesizing references in the verification camera domain but neglected printer-induced variability. The authors propose a novel cross-camera dual-synthetic referencing approach that leverages both a digital template and an enrollment capture from a controlled camera to create a high-quality synthetic reference in the verification camera's domain. Their information-theoretic analysis proves this combined reference is more informative about the verification capture than the template alone. Empirical experiments on a diverse mobile camera dataset demonstrate significant improvements in image similarity metrics and authentication accuracy (AUC) compared to previous methods, especially on small CDP patches and low-end devices. The method also withstands machine-learning-based cloning attacks and reduces dependency on expensive enrollment equipment.
Key findings
- Dual-synthetic references combining digital template t and enrolled image xC2 increase mutual information with verification capture xC1, outperforming template-only references.
- Authentication AUC on 64x64 pixel blocks reaches 0.990 and 0.989 on iPhone XS and iPhone 15 Pro Max devices with dual-synthetic referencing, improving over synthetic ˆxC1 by >0.1 AUC.
- Dual-synthetic references achieve lower MSE and higher PCC and SSIM similarity metrics vs synthetic-only references across diverse devices.
- Authentication performance with dual-synthetic referencing achieves near-perfect AUC ≈0.999 on only 9% of the full CDP area, enabling robust verification from small partial CDP regions.
- The enrollment capture images, even from lower-quality devices, significantly improve authentication by encoding printer stochasticity absent in digital templates alone.
- Empirically, dual-synthetic references outperform physical enrollment images from different cameras (xC2, C1≠C2), synthetic references ˆxC1, and digital templates t, validating cross-camera translation approach.
- Training the model requires only 51 minutes on an NVIDIA RTX 2080 Ti GPU with inference time of 0.66 s per CDP, enabling practical deployment.
- Robustness verified across 7 imaging devices including Epson scanners and iPhone models ranging from XS to 15 Pro macro.
Threat model
The adversary aims to counterfeit CDPs by either reproducing the original digital template or by reconstructing templates via machine learning from high-quality scans. They cannot access the enrollment camera capture used to encode printing stochasticity, nor perfectly mimic the stochastic printer noise patterns captured at enrollment. The defender uses a verification camera distinct from the enrollment camera, with knowledge of the digital template and enrollment capture for each genuine CDP. The adversary is limited to producing fake physical copies that lack the unique printer noise captured in enrollment images.
Methodology — deep read
Threat model & assumptions: The adversary attempts to counterfeit CDPs by reproducing the digital template or by machine-learning-based recovery of template from captured images. The defender assumes availability of an enrollment capture of each printed CDP taken by a controlled camera (C2) that reveals printer-specific stochastic effects. The verification occurs on a verification camera (C1) with different imaging characteristics. The adversary cannot access the enrollment capture or perfectly replicate printer stochasticity.
Data: The authors use an open dataset [8] with 228x228 binary digital templates printed via an industrial HP Indigo 5500 offset printer. The dataset contains original printed CDPs and machine-learning-generated fake copies printed under same conditions. Multiple captures per CDP were made with mobile phone cameras representing low-end (iPhone XS wide-angle) and high-end (iPhone 15 Pro Max macro) devices. Captures were preprocessed by scaling to 684x684 pixels, and patches of 128x128 pixels with stride 64 were extracted for training.
Architecture / algorithm: Three models are key: (a) Synthetic CDP generator GC1(t) trained per verification camera to synthesize reference images modeling only camera distortions ignoring printing stochasticity, (b) Cross-camera dual-synthetic CDP translator G2(t, xC2, C2, C1) which comprises an encoder E to extract printer modulation from enrollment capture xC2 and a decoder D to apply this modulation onto digital template t to produce a synthetic reference in the verification camera domain. Both E and D use ResNet50 U-net architectures with sigmoid activations. The encoder outputs a latent representation z = E(xC2, C2) capturing printer-specific traits, while the decoder produces ˆxC2→C1 = D(t, z, C1).
Loss functions are primarily L2 reconstruction losses between the verification capture yC1 and corresponding synthetic reference (either GC1(t) or G2(t,xC2,...)). The cross-camera translator optimizes L2 loss jointly over encoder and decoder.
Training regime: Models are trained on overlapping 128x128 patches augmented with flips and rotations. Camera identity is encoded as a trainable 3D vector concatenated with inputs for conditioning. Training uses standard supervised regression minimizing L2 error. Training completed within 51 minutes on a single NVIDIA RTX 2080 Ti GPU. Inference time per CDP is approximately 0.66 seconds.
Evaluation protocol: Evaluation uses similarity metrics MSE, Pearson correlation coefficient (PCC), and structural similarity (SSIM) computed patch-wise and averaged over patches. Authentication performance is assessed by ROC AUC for distinguishing genuine vs fake CDPs based on similarity scores. Evaluations vary window sizes from 64x64 up to larger block aggregations. Baselines include direct comparison with digital template t, synthetic references ˆxC1, physical enrollment image xC2, and dual-synthetic reference ˆxC2→C1.
Experiments test cross-camera references by swapping enrollment and verification cameras, including low-to-high and high-to-low-end device pairs. Additional studies extend to 7 camera models beyond the main two. Ablations confirm dominance of L2 loss over combined losses.
- Reproducibility: Dataset and code are publicly available at https://github.com/romaroman/cdp-synthetics-dataset and https://github.com/IvanOleksiyuk/cdp-dual-synthetics/, enabling reproduction. Models and training details, including conditioning schemes and optimizer parameters, are provided in the paper.
Concrete example end-to-end: To authenticate a CDP printed with template t, first capture it with enrollment camera C2 yielding xC2. Input (t,xC2) into cross-camera translator G2 to generate ˆxC2→C1, a synthetic reference image simulating verification camera C1's viewpoint including printer stochasticity. Capture the verification CDP with C1 as yC1, subdivide into 64x64 patches, compute similarity metrics (e.g., PCC) between ˆxC2→C1 patches and yC1 patches, aggregate scores, and classify as genuine or fake by ROC threshold. This pipeline improves authentication robustness vs using t or ˆxC1 alone because ˆxC2→C1 incorporates real printer noise information from enrollment capture.
Technical innovations
- A cross-camera dual-synthetic referencing framework that synthesizes verification camera domain references from both digital template and enrollment capture to encode printer stochasticity.
- Use of a joint encoder-decoder deep network to extract printer modulation from one camera's capture and translate it to another camera's domain conditioned on the template.
- Information-theoretic analysis proving that dual references have strictly higher mutual information with verification captures than template-only references.
- Demonstration that dual-synthetic references enable robust authentication even on small CDP patches and low-end imaging devices.
Datasets
- CDP-synthetics dataset — several thousand printed CDPs with digital templates and scans from 7 camera devices including iPhone XS and iPhone 15 Pro Max — publicly available at https://github.com/romaroman/cdp-synthetics-dataset
Baselines vs proposed
- Digital template t: authentication AUC = 0.500 (PCC metric, iPhone XS) vs dual-synthetic reference: 0.990
- Synthetic reference ˆxC1,L2: AUC = 0.828 (iPhone XS) vs dual-synthetic ˆxC2→C1: 0.990
- Physical enrollment image xC2 (C1 ≠ C2): AUC = 0.944 (iPhone XS) vs dual-synthetic ˆxC2→C1: 0.990
- Physical enrollment image same camera xC1 (idealized): AUC = 0.996 (iPhone XS) vs dual-synthetic ˆxC2→C1: 0.990
- Dual-synthetic ˆx15→XS similarity metrics exceed even consecutive XS image similarity due to higher resolution enrollment capture.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.31292.
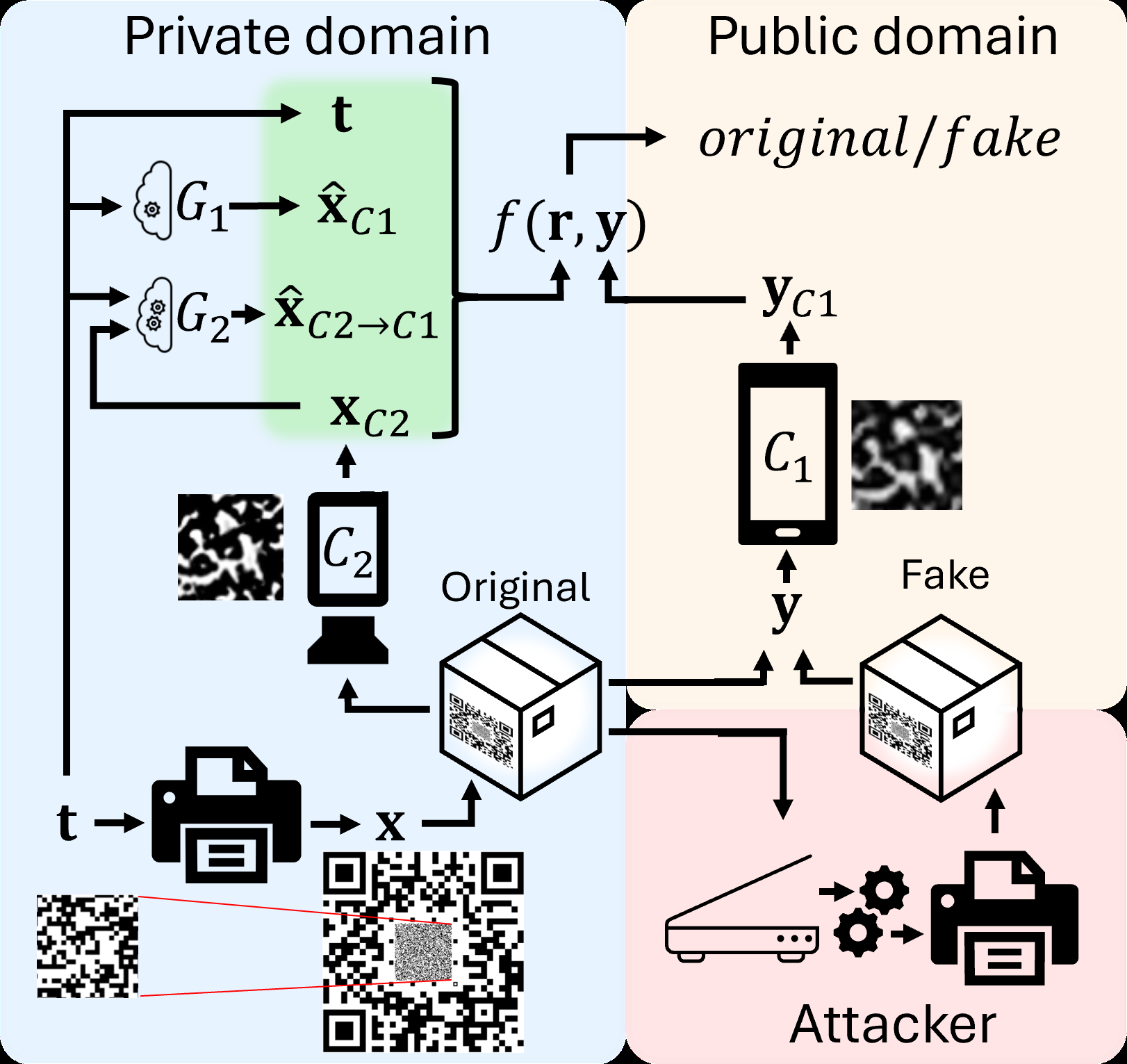
Fig 1: Diagram demonstrating the lifecycle of a CDP x in-

Fig 2: A small patch of a probe CDP from iPhone XS and
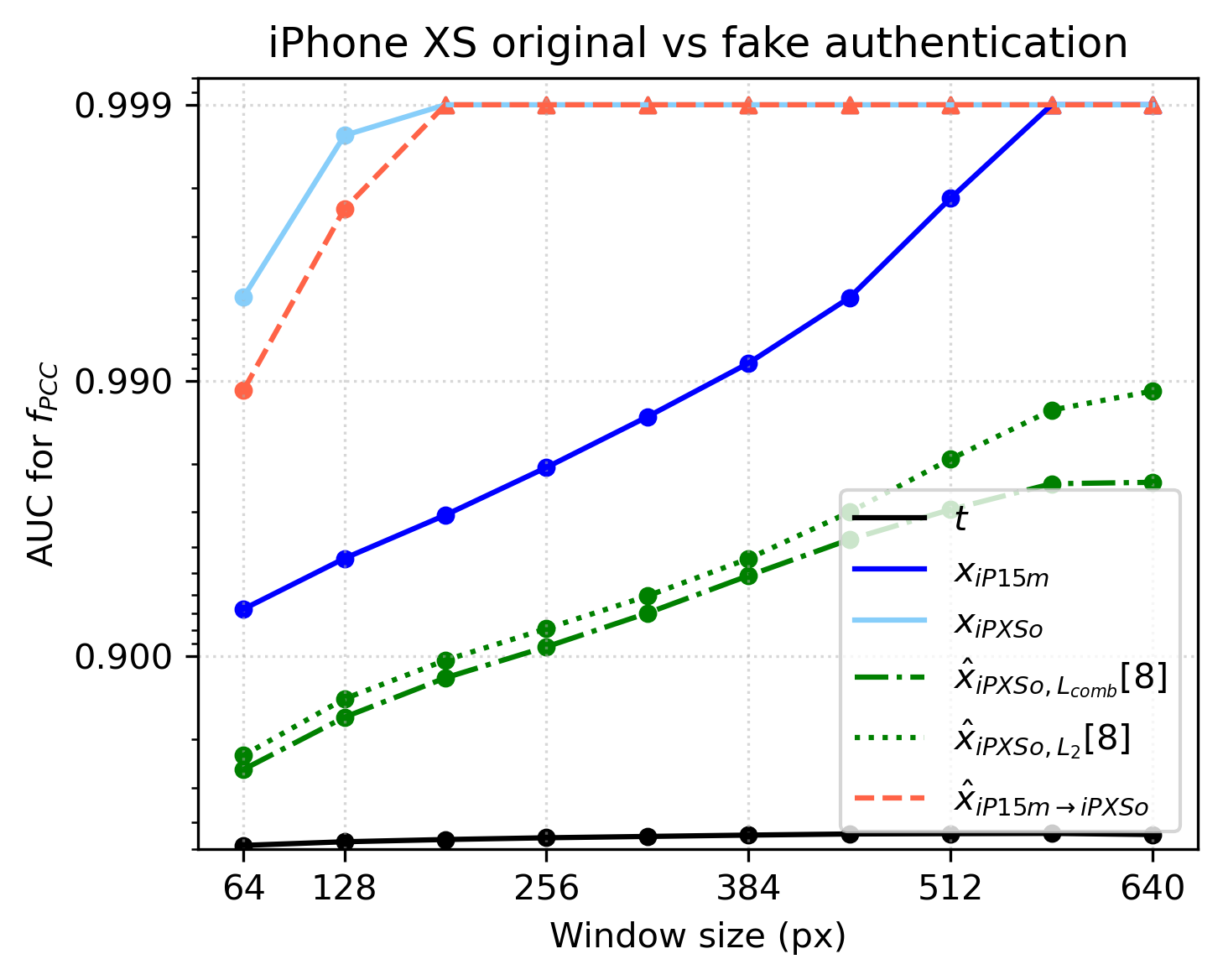
Fig 3: ROC AUC of authentication performance depending on the window size, shown for 5 different references used. The
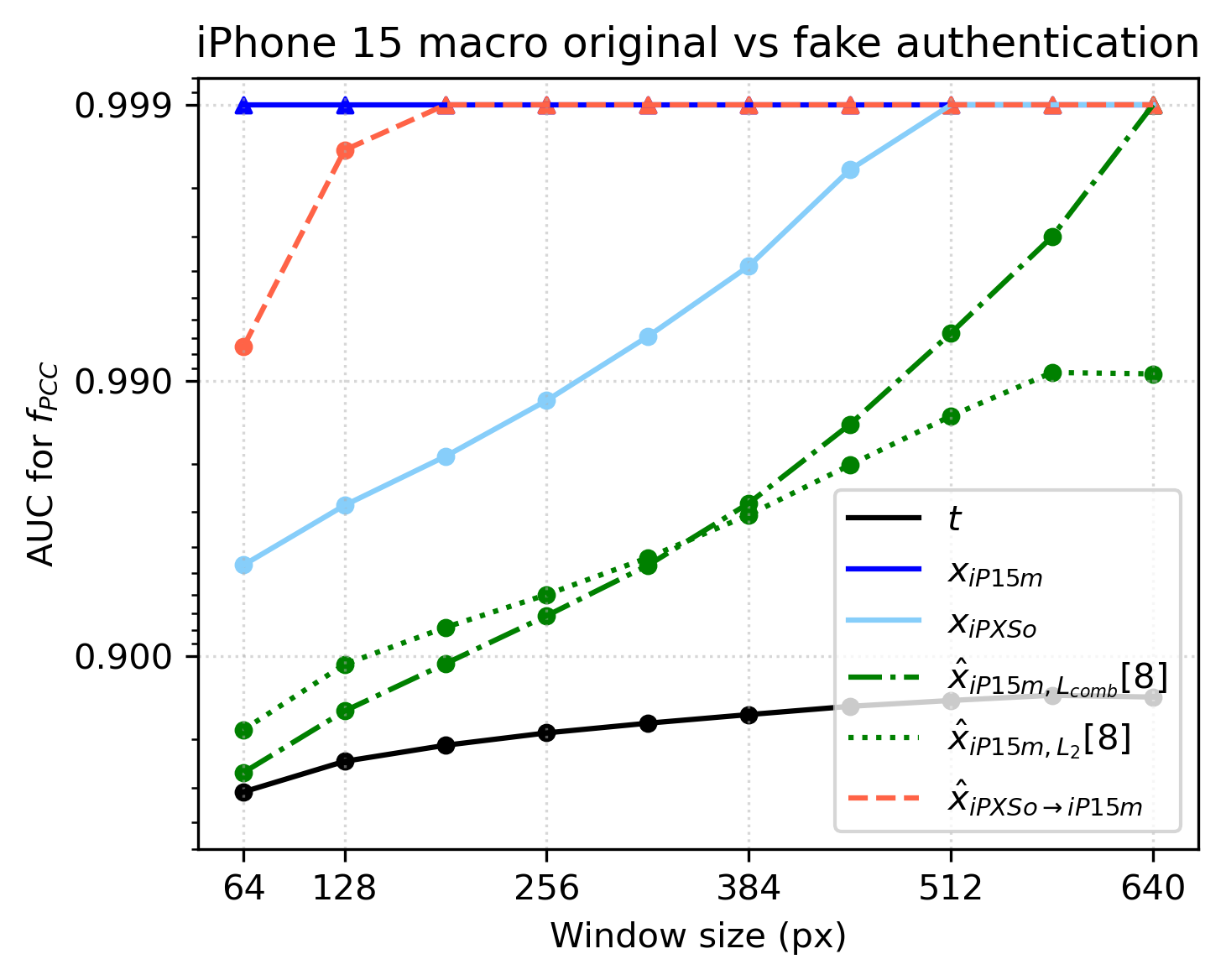
Fig 4 (page 5).

Fig 4: A patch of digital template of a CDP and the captures of the same patch by 7 devices available in the dataset.
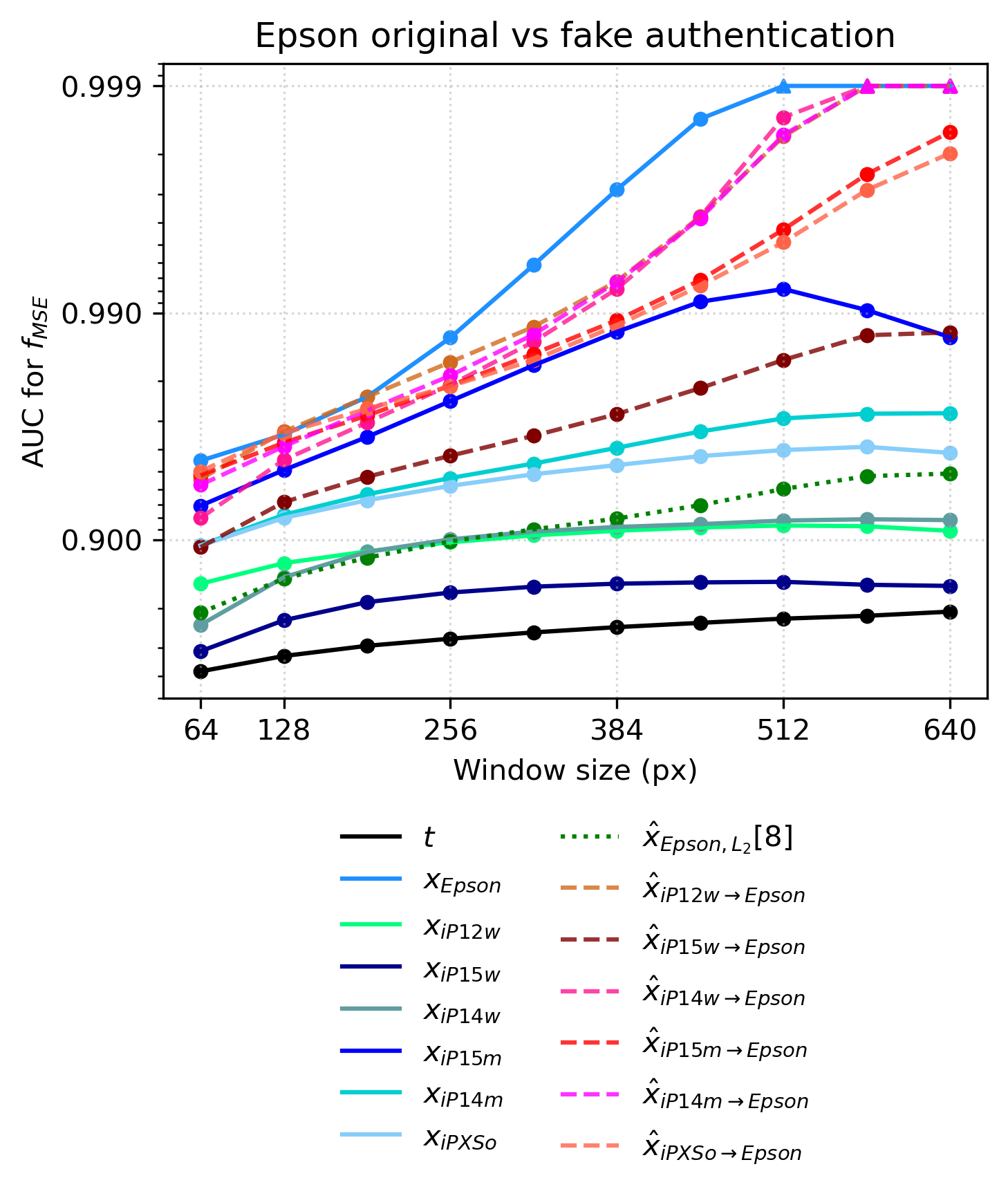
Fig 5: ROC AUC of authentication performance depending on the window size, shown for different references used. The
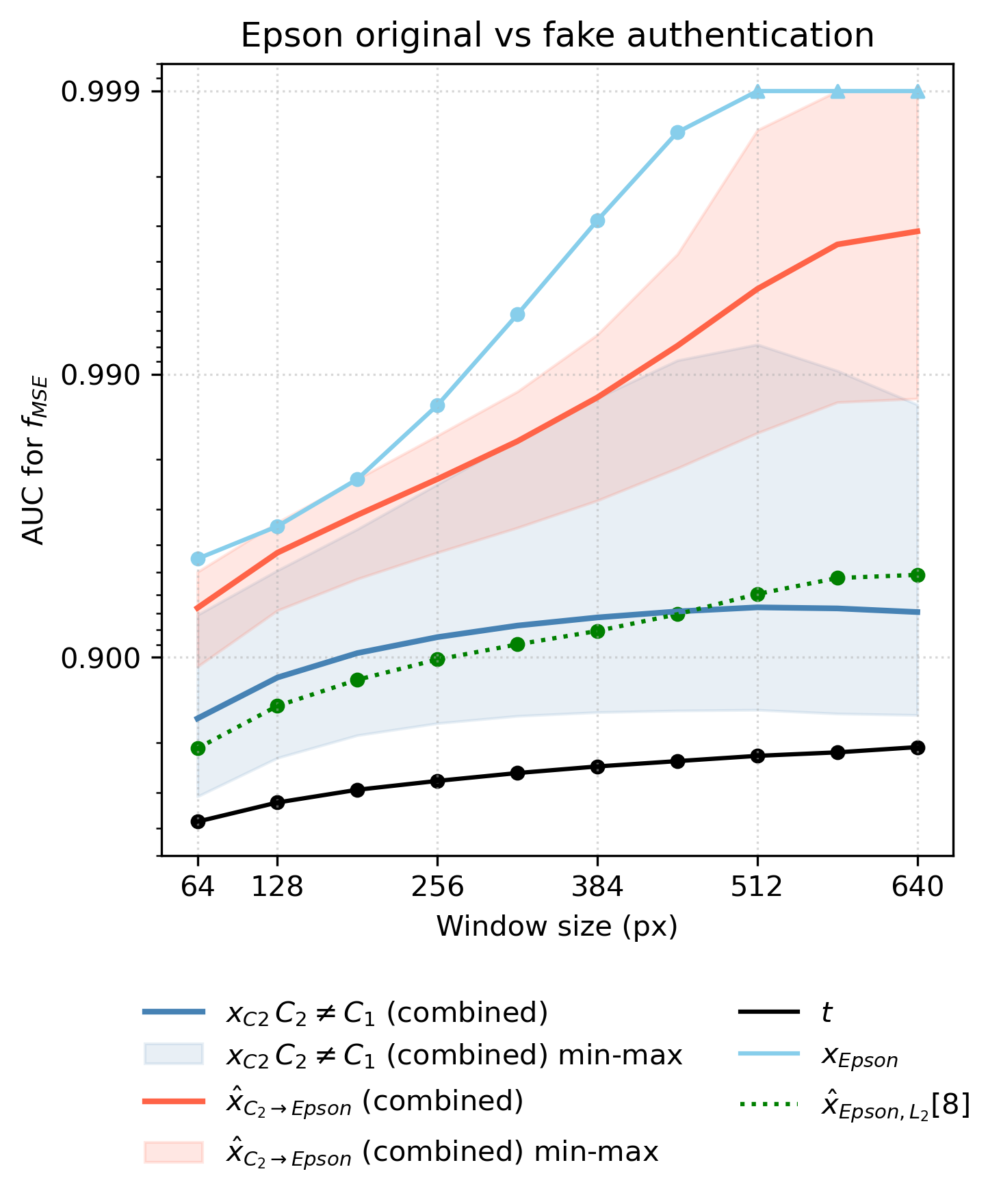
Fig 7 (page 8).
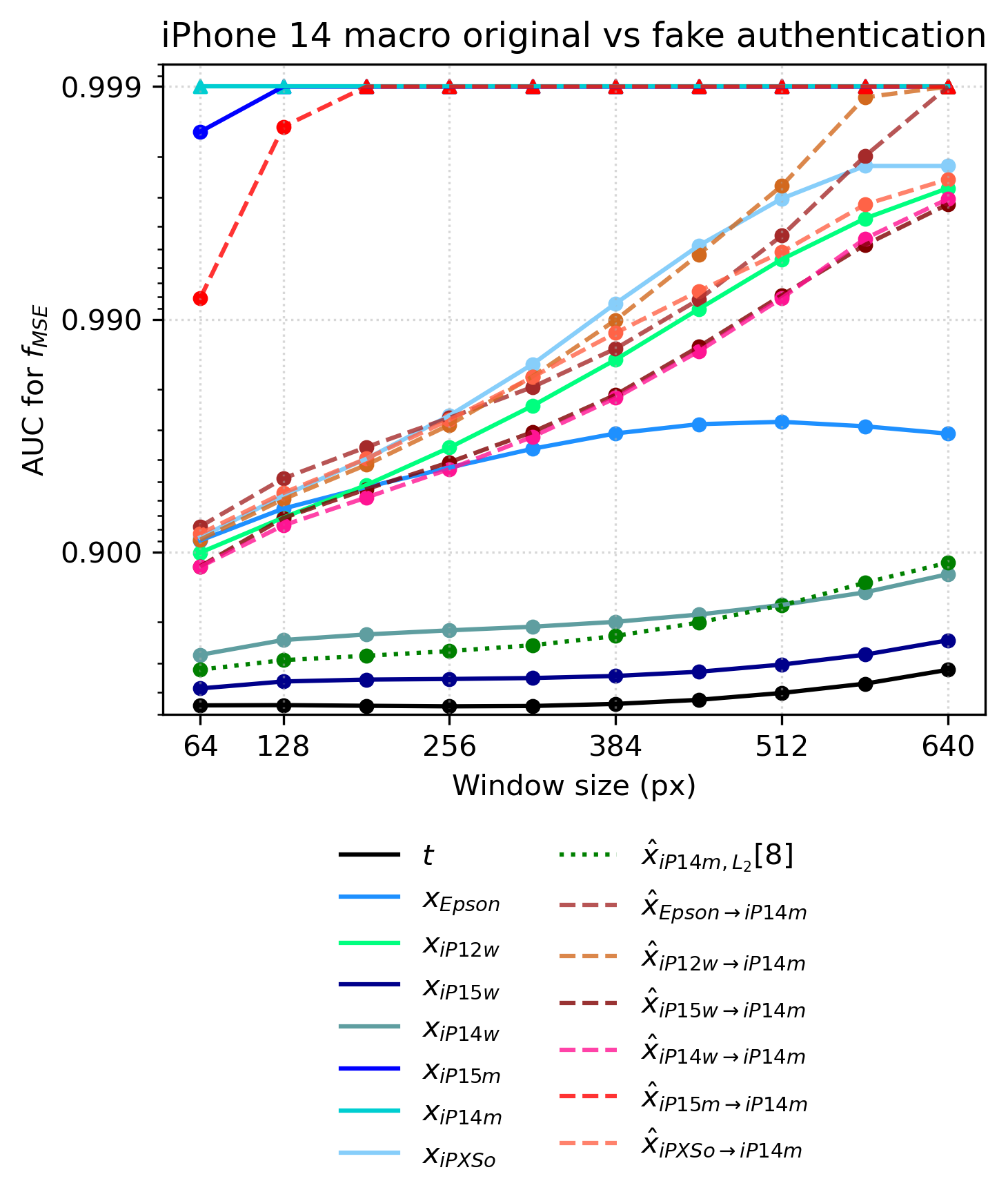
Fig 8 (page 9).
Limitations
- Per-CDP enrollment capture is required, adding overhead to the production process.
- The method relies on availability of controlled enrollment camera(s); quality trade-offs exist but low-end enrollments diminish performance gains.
- Evaluation covers a limited number (7) of imaging devices and one industrial printer; generalization to other printers and cameras not yet fully validated.
- No explicit adversarial testing beyond ML-based cloning attacks discussed; robustness against adaptive adversaries or unknown attack vectors remains untested.
- Authentication uses purely unsupervised similarity-based scoring; supervised classification could potentially improve performance but is future work.
- Quantitative performance drops slightly when expanding to multi-class camera conditioning, indicating model scaling challenges.
Open questions / follow-ons
- How effective is the method under domain shift to printers other than the HP Indigo 5500 or with different printing parameters?
- Can supervised or semi-supervised classification using dual-synthetic references surpass unsupervised similarity metrics for counterfeit detection?
- What is the robustness to an adaptive adversary who attempts to model or replicate printer stochastic effects?
- How well does the approach generalize across wider camera models, lighting conditions, and physical damage scenarios?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work presents a rigorous methodology for improving physical artifact authentication through novel reference generation leveraging dual-camera enrollment. It clearly shows how combining both digital templates and physically enrolled captures can encode printer-specific noise invisible in templates alone, boosting robustness against cloning and copy attacks — a core challenge in anti-counterfeiting and physical bot-proof systems. Practitioners applying physical pattern-based verification can adopt this dual-synthetic referencing concept to improve true vs fake discrimination, especially on low-quality devices or with partial pattern visibility. The information-theoretic analysis grounds the benefits beyond heuristics, helping engineers understand why multi-source referencing is superior. However, the requirement of enrollment captures and controlled cameras may pose practical deployment constraints. Future work on domain adaptation and classifier-based scoring could enable more flexible defenses in diverse operational environments. Overall, this study advances the state of reliable physical pattern verification, a critical subcomponent in hardware-based bot-detection architectures.
Cite
@article{arxiv2605_31292,
title={ Authentication of Copy Detection Patterns via Cross-Camera Dual-Synthetic Referencing },
author={ Ivan Oleksiyuk and Roman Chaban and Slava Voloshynovskiy },
journal={arXiv preprint arXiv:2605.31292},
year={ 2026 },
url={https://arxiv.org/abs/2605.31292}
}