
Towards Verifiable Multimodal Deep Research: A Multi-Agent Harness for Interleaved Report Generation
Source: arXiv:2605.29861 · Published 2026-05-28 · By Chenghao Zhang, Guanting Dong, Yufan Liu, Tong Zhao, Zhicheng Dou
TL;DR
This paper addresses the challenge of generating verifiable multimodal deep research reports, which synthesize open-ended textual and visual evidence into professional, long-form outputs. Existing systems struggle with two key issues: lack of stage-wise verification causing accumulated factual errors, and loose integration of visual evidence leading to subpar interleaved image–text reports. The authors propose PTAH, a multi-agent harness that systematically orchestrates Planning, Research, and Writing stages, where specialized agents cooperatively construct structured plans, collect grounded textual and visual evidence managed in a Visual Working Memory, and compose declarative multimodal reports. A dedicated Verifier Agent enforces factual grounding, citation fidelity, and cross-modal consistency with both rule-based and LLM-based checks throughout the workflow. To measure performance on these multimodal dimensions, the authors also introduce PTAHEval, an evaluation protocol augmenting existing benchmarks with image-level and presentation-level metrics.
Experiments on two deep research benchmarks show PTAH consistently outperforms strong baselines in textual insight/depth and readability as well as image content quality and multimodal presentation quality, achieving 45.16 overall score on DeepResearch Bench—significantly higher than previous single-agent and text-only methods. The Verifier Agent and a test-time scaling refinement process are shown essential for system stability, factual citation accuracy (87.53%), and delivered image quality. Human evaluations validate the improved clarity and professional organization of PTAH reports. Overall, PTAH advances verifiable, professionally interleaved multimodal deep research report generation by tightly integrating planning, research, multimodal evidence management, and verification into a unified multi-agent framework.
Key findings
- PTAH achieves an overall score of 45.16 on DeepResearch Bench, outperforming baselines like WebThinker (45.00) and ReAct (43.70) (Table 1).
- On Multimodal Evaluation (PTAHEval), PTAH scores 4.39 average on Image Content Quality (VC/CMA/IC/ES) vs 1.97 for multimodal baseline LLM-I (Table 2).
- PTAH attains 87.53% citation accuracy with 9.64 effective citations per task, far exceeding WebThinker (60.74%) and ReAct (37.28%) (Table 3).
- Removing the Verifier Agent reduces task completion from 100 to 68 out of 100 tasks and drops citation accuracy drastically from 87.53% to 30.29% (Table 3).
- Test-Time Scaling (TTS) improves DeepResearch Bench score by 3.03 points, raises image quality, and decreases failed image generations from 0.38 to 0.12 per report (Table 4).
- Human evaluation shows PTAH preferred over LLM-I and WebThinker by majority on Image Content Quality and Multimodal Presentation Quality criteria (Fig 4).
- PTAH’s multi-agent decomposition enables deeper insight and clearer structure compared to single-agent or direct generation baselines.
Threat model
The paper does not explicitly define a traditional security adversary; rather, the threat consists of intrinsic model failures leading to hallucinated facts, invalid citations, and inconsistent multimodal outputs during open-ended deep research synthesis. The Verifier agent is tasked with mitigating these internal failure modes, ensuring factual correctness and cross-modal consistency despite the inherently uncertain, open-domain environment.
Methodology — deep read
Threat Model & Assumptions: The system targets open-domain deep research tasks where synthesis lacks deterministic ground truth. Adversaries here are not explicitly modeled as attackers but the focus is on ensuring factual grounding, citation fidelity, and cross-modal consistency to prevent hallucinations and misinformation in long-form multimodal reports.
Data: Experiments use publicly known benchmarks DeepResearch Bench (Du et al., 2025) and DeepConsult (you.com, 2025). These benchmarks provide queries and expected textual content quality metrics but originally lack multimodal evaluation. The authors augment with PTAHEval adding image quality and presentation metrics. Queries are from these benchmarks; external knowledge is retrieved from top-5 web pages per query uniformly. Details on dataset size are not explicit but DeepResearch Bench uses 100 tasks for evaluation.
Architecture / Algorithm: PTAH consists of multiple specialized agents orchestrated in three sequential stages:
- Planning Agent: Creates a multi-section, visual-aware research plan specifying expected text coverage and visual evidence roles. Outputs structured JSON plans verified by Verifier.
- Researcher Agents: Independently conduct section-level investigation using web search and retrieval to collect claim-grounded textual evidence, numerical data, and source-aligned images stored in a Visual Working Memory. Images are filtered (rule-based) and selected via a vision-language model to meet visual specifications.
- Writer Agent: Generates final interleaved report using declarative multimodal tool commands embedding image references, image search, and image generation. The writer follows verified plan and evidence with tight image-text integration. Verifier Agent: Combines rule-based and LLM-based rubric checks enforcing protocol compliance, factual correctness, citation validity, visual relevance, and cross-modal consistency continuously to accept/reject outputs at each step.
Training / Implementation: The core language models used are Qwen3-32B for planning, research, and verification, and Qwen3-VL-32B-Instruct as the multimodal writer and image selector. No training regime details are given—models are likely used in few-shot or zero-shot prompting. The verifier uses an LLM-based rubric checker and rule-based tests.
Evaluation Protocol: Text evaluation follows the original benchmark metrics (Comprehensiveness, Insight, Instruction-Following, Readability). Multimodal report outputs are additionally scored by PTAHEval, which uses a Vision-Language Model (Qwen3-VL-235B-A22B-Instruct) to score Image Content Quality (visual clarity, cross-modal alignment, information complementarity, evidentiary support) and Multimodal Presentation Quality (density-legibility balance, informational saliency, visual encoding diversity, visual ergonomics) on rendered webpage screenshots. Human evaluations with four annotators carry out pairwise comparisons following PTAHEval criteria.
Reproducibility: Models used are large proprietary or semi-open Qwen3 variants; code release is not discussed explicitly. Dataset benchmarks are public but PTAH’s Visual Working Memory and Web image extractions may add complexity for exact reproduction. The system’s multi-agent workflow is described in detail but exact prompting and integration scripts are not provided.
Concrete Example - Generating a Multimodal Research Report: Given a query, the Planner agent initiates a structured plan specifying desired sections and visual elements (e.g., charts, figures). Researcher agents perform parallel searches per section, extract textual evidence and candidate images from retrieved web pages, filter and score images, and store them alongside citations in Visual Working Memory. The verifier checks each research package for factual and citation validity. The Writer then composes the final report embedding images via tool commands, optionally generating charts or retrieved images when needed. After initial draft, the system applies test-time scaling refinements improving sections, filtering images, optimizing layout and spacing in HTML before final rendering as a user-facing web page. The process ensures each step meets acceptance criteria via the verifier, preventing errors cascading downstream.
Technical innovations
- Introducing a multi-agent harness architecture (PTAH) that decomposes multimodal deep research report generation into Planning, Research, Writing, and Verification stages with dedicated specialized agents.
- Developing a Visual Working Memory to maintain source-aligned image candidates as intermediate, inspectable research state rather than treating images as post-hoc decorations.
- Designing declarative multimodal composition in the Writer agent that embeds image tool commands for reference reuse, web image search, and generation, enabling tightly interleaved image-text reports.
- Implementing a Verifier Agent combining rule-based constraints with LLM-based rubric verification that enforces stage-wise factual grounding, citation fidelity, visual relevance, and cross-modal consistency.
- Introducing PTAHEval, an evaluation protocol extending existing benchmarks with image content and layout/presentation quality metrics scored by Vision-Language Models on rendered reports.
Datasets
- DeepResearch Bench — approx. 100 tasks — public, used for textual and multimodal evaluation
- DeepConsult — unspecified size — public, used for textual evaluation
Baselines vs proposed
- Direct Generation Qwen3-32B: overall = 42.22 vs PTAH: 45.16 on DeepResearch Bench
- ReAct (text-only agent): overall = 43.70 vs PTAH: 45.16 on DeepResearch Bench
- WebThinker (single-agent search): overall = 45.00 vs PTAH: 45.16 on DeepResearch Bench
- LLM-I (multimodal agent baseline): Image Content Quality avg = 1.97 vs PTAH: 4.39 on DeepResearch Bench
- WebThinker: Citation Accuracy = 60.74% vs PTAH: 87.53% on DeepResearch Bench
- PTAH w/o Verifier: Citation Accuracy = 30.29% vs PTAH: 87.53%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.29861.
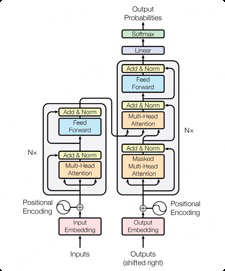
Fig 1: Illustration of how images enhance report

Fig 2 (page 1).

Fig 2: Overview of PTAH, a multi-agent harness for verifiable multimodal deep research.
Fig 3: An illustration of our PTAHEval evaluation.
Fig 5 (page 4).

Fig 6 (page 4).

Fig 7 (page 4).

Fig 8 (page 4).
Limitations
- Current open-source LLM and VLM models limit stable long-horizon autonomous workflows, requiring manual stage decomposition rather than end-to-end agentic generation.
- PTAH modular design relies on manually defined boundaries between Planning, Research, and Writing that may reduce adaptability or smoothness of the pipeline.
- Evaluation is limited to benchmarks with queries and metrics primarily text-focused and does not test adversarial inputs or robustness under attack.
- Visual Working Memory management and retrieval may not scale well or handle highly diverse visual domains beyond web images.
- No code or preset weights published, which hinders exact reproducibility and independent validation.
Open questions / follow-ons
- How to extend PTAH to adversarial scenarios where malicious inputs or misinformation sources actively attempt to deceive the system?
- Can the multi-agent framework dynamically adapt or learn optimal decomposition policies rather than rely on fixed Planning, Research, Writing stages?
- How to improve scaling and generalization of Visual Working Memory across very large, diverse visual corpora beyond web images?
- What are the trade-offs between modular verification and end-to-end learned verification to balance flexibility and reliability?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners focused on guarding against autonomous agents that generate convincing but potentially misleading research reports, PTAH presents a valuable architectural blueprint demonstrating effective integration of multimodal evidence and rigorous verification. Its multi-agent harness approach with explicit visual-aware planning and stage-wise verification shows how a system can maintain traceability, cross-modal consistency, and citation fidelity despite the open-ended nature of deep research synthesis. This is directly applicable to detecting or mitigating advanced forgery or misinformation generation by bots attempting sophisticated content fabrication. The Visual Working Memory concept highlights the importance of linking visual cues tightly to textual claims rather than treating images as afterthoughts, critical for verifying authenticity in complex multimodal outputs. PTAHEval also provides an instructive multimodal evaluation framework extending beyond pure text quality metrics, important for benchmarking robustness against visually grounded bot manipulations. Overall, PTAH suggests architectural and evaluation directions worth adapting for defensive measures against evolving AI-powered content fabrication bots.
Cite
@article{arxiv2605_29861,
title={ Towards Verifiable Multimodal Deep Research: A Multi-Agent Harness for Interleaved Report Generation },
author={ Chenghao Zhang and Guanting Dong and Yufan Liu and Tong Zhao and Zhicheng Dou },
journal={arXiv preprint arXiv:2605.29861},
year={ 2026 },
url={https://arxiv.org/abs/2605.29861}
}