
SURGENT: A Surgical Multi-Agent Assistance System Across the Perioperative Workflow
Source: arXiv:2605.29368 · Published 2026-05-28 · By Dongsheng Shi, Yue Li, Xin Yi, Yongyi Cui, Huawei Feng, Linlin Wang
TL;DR
SURGENT addresses critical challenges in applying large language models (LLMs) to the complex surgical perioperative workflow, where patient histories are extensive and clinical decisions require transparent, multi-department collaboration. Existing web-based LLMs struggle with input length constraints, incomplete memory management, and lack of traceability, limiting their usefulness for surgical assistance. SURGENT proposes a multi-agent system integrating a Tree-of-Thought (ToT) planner, domain-specialized departmental agents, and retrieval-augmented reasoning from clinical guidelines and biomedical literature. A novel dual-memory design maintains both long-term structured patient records and short-term working summaries, enabling more contextualized, consistent, and explainable reasoning.
Extensive experiments on a dataset of 530 perioperative patient records show that SURGENT outperforms single LLM baselines (DeepSeek, GPT-4o, Claude) and state-of-the-art medical multi-agent systems (MedAgents, ReConcile, MDAgents, ColaCare) across five critical tasks: case analysis, surgical plan simulation, intraoperative safety monitoring, complication risk assessment, and rehabilitation guidance. Ablations confirm the pivotal role of the planner agent, memory mechanism, department agents, and the ToT reasoning framework. Notably, SURGENT built on the open-source, locally deployable DeepSeek LLM enables privacy-preserving deployment, addressing data security concerns. The results position SURGENT as a practical and trustworthy intelligent surgical assistant suitable for resource-limited hospitals and settings requiring auditable, knowledge-grounded surgical recommendations.
Key findings
- SURGENT achieves Diagnostic Coverage (DC) of 93.1% and Misdiagnosis Avoidance Rate (MAR) of 83.2%, surpassing next-best ColaCare by 3.4 and 6.8 percentage points respectively.
- Surgical Plan Feasibility Score (PFS) reaches 9.33 and Guideline Adherence Rate (GAR) 95.3%, outperforming strongest baselines by >0.5 in PFS and 3.0 percentage points in GAR.
- Intraoperative safety monitoring shows early warning sensitivity (EWS) of 74.5 and false alarm rate (FAR) of 33.2, improving upon ColaCare by 6.1 and 4.6 points respectively.
- Postoperative complication recall is 69.4%, exceeding the next-best MDAgents by 2.2 percentage points.
- Rehabilitation guidance semantic similarity (Sim) at 61.0 is competitive vs top ColaCare (62.1).
- Ablation removing memory mechanism drops DC by 7.4 percentage points (to 85.7%) and MAR by 5.4 points (to 77.8%), showing criticality of long-term memory.
- Removing department agents decreases DC further to 82.5% and MAR to 74.3%, indicating importance of specialty expertise agents.
- SURGENT with DeepSeek backbone outperforms GPT-4o and Claude by 3.9 points DC, 0.7 MAR, 0.68 PFS, and 3.3 GAR, demonstrating impact of backbone LLM choice.
Threat model
The adversary includes potential malicious actors seeking to interfere with or manipulate surgical decision workflows, but is assumed unable to directly alter clinical data or patient records. The capabilities encompass access to clinical information requiring privacy preservation. The threat model prioritizes protecting sensitive patient data by enabling local and private deployment with open-source LLM backbones, mitigating risks from centralized cloud services. Adversarial attacks on reasoning consistency or input poisoning are not explicitly addressed.
Methodology — deep read
The threat model assumes a medical environment where the adversary cannot compromise clinical data confidentiality or alter patient records but requires trustworthy, privacy-preserving surgical assistance. The system is designed to work with extensive patient perioperative records, including admission notes, daily medical logs, laboratory results, and surgical plans. The study uses a dataset of 530 anonymized patient cases from multiple countries and ethnic groups with comprehensive perioperative metadata. Data was cleaned and anonymized per ethical guidelines.
SURGENT combines several modular components:
Planner Agent: Employs a beam search guided by an LLM generating candidate surgical plan steps; a multi-dimensional scoring function weights criteria of task alignment, safety, logical order, operability, and clarity. Beam search prunes candidates to identify an optimal surgical plan sequence. The planner assigns execution to task-level and local clinical department agents.
Memory Mechanism: Utilizes dual memory stores—working memory preserves short-term dialogue and reasoning steps, long-term memory indexes structured patient cases, longitudinal records, and lab results. Agents retrieve relevant long-term memory entries via learned neural queries and semantic similarity matching, then incorporate this information into working memory for coherent reasoning.
Department Agents: Domain-specific modules (internal medicine, surgery, laboratory, cardiology, etc.) execute specialized reasoning. Each agent retrieves relevant historical records and exemplar cases from long-term memory and generates concise recommendations relating to its specialty. Laboratory agents focus on abnormality detection, filtering for clinically relevant tests, retrieval of biomedical evidence from PubMed and guidelines, and synthesis of structured analyses.
Aggregation Module: Synthesizes outputs from individual agents under a task-specific agent via learned summarization functions. A reflection mechanism checks for logical consistency and completeness in aggregated results. Human-in-the-loop oversight allows clinical experts to review and amend recommendations.
Training and testing involved repeated trials with random seeds. Backbone LLMs evaluated include DeepSeek (open-source, privacy-preserving), GPT-4o, and Claude, serving both as standalone baselines and as components within SURGENT. Temperature for sampling kept at 0.7, ToT planner configured with search depth 3, length 5, beam width 2. Embedding model for retrieval was bge-large-zh-v1.5 optimized for Chinese. Experimental evaluation spans five surgical workflow tasks and multiple domain-specific metrics to capture clinical relevance and decision quality.
Evaluation protocol emphasizes comparison against strong single-agent baselines (zero-shot and few-shot) enhanced by prompting strategies such as chain-of-thought and self-consistency, plus medical multi-agent frameworks. Ablation studies isolate the impact of each architectural component on clinical decision coverage and safety metrics. The system implementation supports deployment as a secure local web service enabling privacy-preserving inference.
One typical example: For a kidney transplant patient with extensive lab results and longitudinal records, the planner generates multiple candidate surgical steps scored for safety and logic; department agents specializing in nephrology, cardiology, and laboratory data retrieve relevant case histories and guidelines to reason collaboratively; the aggregation module synthesizes recommendations with reflection checks; a clinician reviews and finalizes plans, ensuring safe transplant perioperative strategy. This pipeline ensures a transparent, auditable, and patient-specific surgical plan.
Technical innovations
- Integration of a Tree-of-Thought (ToT) planner with beam search and multi-criteria plan scoring to generate optimized surgical plan sequences.
- Dual-memory architecture explicitly managing both long-term patient histories and short-term working summaries to overcome LLM context window limitations.
- Multi-agent system design with specialized department agents that perform domain-specific reasoning using retrieval-augmented patient records and biomedical knowledge.
- Aggregation module combining reflective reasoning and human-in-the-loop oversight to ensure consistent, auditable, and clinically valid surgical recommendations.
Datasets
- Perioperative Clinical Records — 530 anonymized cases — sourced from top-tier tertiary hospitals across five countries and 19 ethnicities
Baselines vs proposed
- Vanilla single-agent GPT-4o zero-shot: DC=68.4%, MAR=55.7% vs SURGENT: DC=93.1%, MAR=83.2%
- Vanilla single-agent DeepSeek few-shot: DC=79.8%, MAR=65.4% vs SURGENT: DC=93.1%, MAR=83.2%
- Advanced single-agent MedPrompt (DeepSeek): PFS=8.27, GAR=85.4% vs SURGENT: PFS=9.33, GAR=95.3%
- Multi-agent ColaCare (DeepSeek): EWS=68.4, FAR=37.8, Recall=67.2, Sim=62.1 vs SURGENT: EWS=74.5, FAR=33.2, Recall=69.4, Sim=61.0
- SURGENT DeepSeek backbone vs Claude backbone: DC 93.1% vs 89.2%, MAR 83.2% vs 82.5%, PFS 9.33 vs 8.65, GAR 95.3% vs 92.0%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.29368.

Fig 3: Ablation Study of ToT

Fig 2 (page 6).

Fig 3 (page 6).
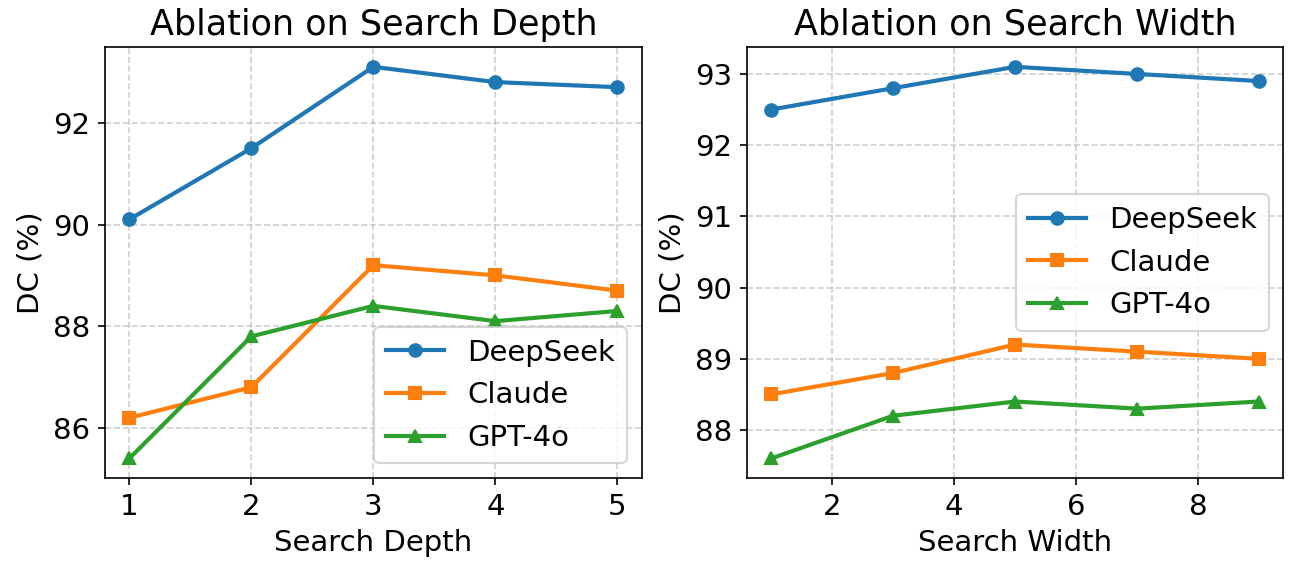
Fig 4 (page 8).
Limitations
- Evaluation performed on a limited dataset of 530 anonymized cases, which may not capture all real-world surgical complexity or rare conditions.
- No explicit adversarial robustness or worst-case scenario testing reported for manipulations or noisy patient data.
- Performance focus on Chinese-optimized DeepSeek backbone may limit generalizability to other languages or clinical settings without retraining.
- The system relies on human-in-the-loop oversight for final validation, so full automation and trustworthiness in absence of clinical review remains unproven.
- Potential scalability challenges when extending to larger patient populations with even longer longitudinal histories are not fully addressed.
- Code and model availability unspecified in the text, hindering immediate reproducibility or deployment by third parties.
Open questions / follow-ons
- How does SURGENT perform under distributional shifts, such as rare surgical conditions or novel complications?
- What are the robustness properties of the multi-agent system against adversarial patient data or noisy input?
- Can the dual-memory mechanism be scaled effectively to incorporate multimodal data like images or real-time sensor streams intraoperatively?
- How well does SURGENT generalize to languages and clinical contexts outside the Chinese-optimized DeepSeek backbone?
Why it matters for bot defense
From a bot-defense perspective, SURGENT exemplifies a sophisticated multi-agent architecture tackling context length limits and traceability challenges in LLM applications. Key lessons for CAPTCHA and bot-defense engineering include the value of decomposing complex workflows into specialized agents with memory-augmented reasoning to handle rich historical data while maintaining auditability. The planner agent's Tree-of-Thought approach offers insight into structured exploration strategies to improve reasoning quality under constrained input windows. Furthermore, SURGENT’s privacy-preserving design using a locally deployable backbone model addresses data security considerations vital for sensitive environments, analogous to protecting CAPTCHA mechanisms from centralized adversarial control. Although surgical assistance differs in domain goals from CAPTCHA, the architectural principles of modular multi-agent coordination, memory management, retrieval-augmented grounding, and human-in-the-loop reflect transferable system design strategies for constructing robust, transparent, and accountable AI defenses against bots requiring multi-stage decisioning.
Cite
@article{arxiv2605_29368,
title={ SURGENT: A Surgical Multi-Agent Assistance System Across the Perioperative Workflow },
author={ Dongsheng Shi and Yue Li and Xin Yi and Yongyi Cui and Huawei Feng and Linlin Wang },
journal={arXiv preprint arXiv:2605.29368},
year={ 2026 },
url={https://arxiv.org/abs/2605.29368}
}