
Revisiting Observation Reduction for Web Agents: Comprehensive Evaluation with a Lightweight Framework
Source: arXiv:2605.29397 · Published 2026-05-28 · By Masafumi Enomoto, Ryoma Obara, Haochen Zhang, Masafumi Oyamada
TL;DR
This paper addresses the challenge of efficiently evaluating HTML observation reduction methods for LLM-based web agents, which is critical to reducing costly long-input latency without sacrificing task success. Existing methods vary widely in computational cost and efficacy in retaining information necessary for completing web-interaction tasks, but comprehensive end-to-end evaluation is prohibitively expensive. To overcome this, the authors propose a novel lightweight evaluation framework based on the Minimal Failure Set (MFS)—the minimal subset of HTML elements whose removal causes task failure. Coverage, defined as the fraction of instances where a reduction method fully retains the MFS, serves as a proxy metric for end-to-end success that requires neither live web access nor LLM inference, enabling over 100× speedup in evaluation time.
Using this framework, the authors conduct a large-scale empirical study across 11 reduction methods, 32 configurations, and two benchmarks (WorkArena L1 and WebLinx). They find that LLM inference-based methods achieve higher retention of critical elements but incur much higher latency compared to retrieval-based or program heuristics. They also demonstrate domain differences in which HTML attributes are important (e.g., text dominates WebLinx whereas tags and CSS attributes matter more on WorkArena). Leveraging MFS data for domain-specific optimization using an LLM-based evolutionary pruning program (GEPA), they achieve significant latency reductions (2.2× on WorkArena, 3.1× on WebLinx) while retaining the majority of success rate (84% and 89%, respectively). This shows that training reduction methods on MFS can produce low-latency, high-performance extractive selectors.
Key findings
- Evaluating 11 reduction methods across 32 configurations on 33 tasks with a 122B parameter policy model took 232.4 cumulative hours end-to-end.
- Coverage, the fraction of instances with full retention of Minimal Failure Sets, correlates strongly with end-to-end success rate (Pearson’s r > 0.8) while enabling over 100× speedup in evaluation time.
- LLM inference-based HTML reduction methods achieve higher coverage than retrieval-based methods but incur 10-100× higher latency per observation (e.g., FocusAgent takes 105s vs 2-3s for dense retrievers on WorkArena).
- HTML elements critical for success differ across benchmarks: text content removal causes a 59.5% coverage drop on WebLinx, whereas CSS-relevant attributes like 'id' and 'class' cause 16.9% and 10.2% drops on WorkArena.
- Domain-specific optimization with the GEPA pruning program on MFS training data achieves 2.2× faster per-step latency on WorkArena L1 and 3.1× faster on WebLinx compared to original HTML input, retaining 84% and 89% of success rate respectively.
- Methods trained on MFS data (e.g., GEPA or fine-tuned dense retriever) improve coverage at low reduction ratios compared to unoptimized counterparts.
- Coverage metric is robust across policy models used for trajectory collection (Claude Sonnet, Gemini, GPT) and evaluation (Qwen3.5-122B, MiniMax-M2.5).
- Program-based reduction methods optimized on MFS data provide the best balance of latency and performance, outperforming costly LLM inference-based methods at aggressive reduction levels.
Threat model
The adversary is implicitly the performance bottleneck caused by large HTML observations in web-based LLM agents that delay task completion. The threat lies in losing task-relevant information when aggressively reducing HTML observations, leading to failure in task completion. The evaluation assumes no active adversarial manipulation of the HTML or observations; the adversary cannot introduce misleading elements or tamper with the agent's internal state. Instead, it is a resource performance-oriented threat to maintain task success under inference and latency constraints.
Methodology — deep read
Threat Model and Assumptions: The studied setting involves LLM-based web agents interacting with web environments via HTML DOM observations. The goal is to reduce the size of HTML inputs to accelerate inference latency without losing elements necessary to complete multi-step tasks. The adversarial aspect is indirect—reduction methods must not discard critical elements essential for task success. The agent’s internal policy model is treated as fixed. MFS construction focuses on elements critical for successful trajectories seen during data collection; elements required by unseen trajectories are not captured.
Data Collection: Successful trajectories were collected on two benchmarks: WorkArena L1 (33 complex multi-step ServiceNow tasks) and WebLinx (300 sampled test-IID single-step interaction tasks). Trajectories were generated using three diverse LLMs—Claude Sonnet 4.6, Gemini 2.5 Flash, and GPT-5.1—to ensure variety. Each trajectory step saved the raw HTML observation, the agent's self-reported relevant HTML (element, attribute) pairs, and the issued action.
Construction of Minimal Failure Sets (MFS): Given a successful trajectory, the MFS is the minimal subset of HTML elements whose removal causes the agent to fail the task. Exact MFS computation is exponential in elements, so an approximate two-phase method is used: (a) Phase 1 prunes candidates by removing all self-reported relevant elements at sampled steps and measuring if failure occurs upon replay; (b) Phase 2 applies the delta debugging (ddmin) algorithm on this reduced candidate set to find a minimal failure subset by iterative group removal and testing. This is done by replaying the agent on fresh browser sessions with appropriate normalization for dynamic content.
Coverage Metric and Evaluation: Coverage is defined as the fraction of MFS instances fully retained by a reduction method over a dataset of instances derived from trajectories. The reduction ratio (proportion of HTML retained) is also measured. Coverage evaluation requires no live inference or web access and can be massively parallelized, resulting in over 100× speedup vs full end-to-end evaluation.
Reduction Methods Compared: Eleven methods are compared, falling into program-based heuristics (e.g., AXTree pruning), retrieval-based ranks by BM25 or dense embeddings, and LLM inference-based selection methods (e.g., Prune4Web, FocusAgent). Some methods are optimized or fine-tuned using MFS data (e.g., GEPA evolutionary optimization, dense retriever fine-tuning).
Training and Optimization: GEPA pruning programs were optimized separately on MFS training splits per benchmark to maximize coverage under reduction ratio constraints (0.2 or 0.6). Dense retriever models were fine-tuned similarly using MFS as supervision. Training details include two-level search using an LLM-based evolutionary framework (GEPA).
End-to-End Evaluation: Confirmed coverage correlates strongly with actual success rate measured by running the policy models (Qwen3.5-122B-A10B and MiniMax-M2.5) end-to-end with the given reduction method applied. Latency was measured including reduction and policy inference, plus web access on WorkArena.
Overall Pipeline Example: For WorkArena, a successful trajectory is collected with all HTML elements. The agent’s self-reported relevant elements at sampled steps are identified. For each step, removal of these reported elements is tested via replay; if failure occurs, ddmin narrows down to a minimal failure set. Coverage is then computed by checking if the MFS is retained by a candidate reduction method’s output HTML. This proxy coverage guides fast comparison and tuning, avoiding full agent runs except for final validation.
Reproducibility: The authors provide detailed procedural descriptions and code implementations for MFS construction and reduction methods. However, MFS data itself is not publicly shared due to licensing restrictions of HTML data from live or proprietary environments.
Technical innovations
- Introduction of the Minimal Failure Set (MFS), a minimal subset of HTML elements whose removal causes task failure, enabling precise identification of critical HTML elements for web agent tasks.
- Definition and validation of coverage as a lightweight proxy metric that strongly correlates with end-to-end success rate yet requires no LLM inference or web access, enabling 100×+ speedups in evaluation.
- Development of a two-phase approximate MFS construction method leveraging agent self-reports and delta debugging (ddmin) to efficiently identify minimal failure subsets from large HTML observations.
- Application of LLM-based evolutionary optimization (GEPA) on MFS training data to produce domain-specific pruning programs that achieve state-of-the-art latency-performance tradeoffs for HTML reduction.
- Comprehensive empirical comparison across multiple reduction method categories and benchmarks with a unified evaluation framework, clarifying the trade-offs between latency, coverage, and success rates.
Datasets
- WorkArena L1 — 33 tasks — serviceNow non-production environment (non-public)
- WebLinx — 300 tasks sampled from test-IID split — third-party websites (dataset public but raw HTML not redistributed)
Baselines vs proposed
- Original (full HTML): success rate = 100% (baseline), latency per step = 65.7s on WorkArena
- FocusAgent (LLM inference-based): latency = 105.69s per reduction step on WorkArena vs Original 0.01s, coverage higher but latency overhead negates gains
- DMR (Dense retriever): latency = 2.95s on WorkArena, coverage less than FocusAgent but much lower latency
- Random baseline at high reduction ratios approaches coverage of complex methods, showing diminishing returns of selection under aggressive reduction
- GEPA pruning program (optimized on MFS, ratio=0.2): achieves 2.2× faster per-step latency than Original on WorkArena retaining 84% success rate; 3.1× faster on WebLinx retaining 89% success
- DMR (finetuned) improves coverage over unoptimized DMR (Dense) but with degraded performance at low reduction ratios compared to GEPA
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.29397.
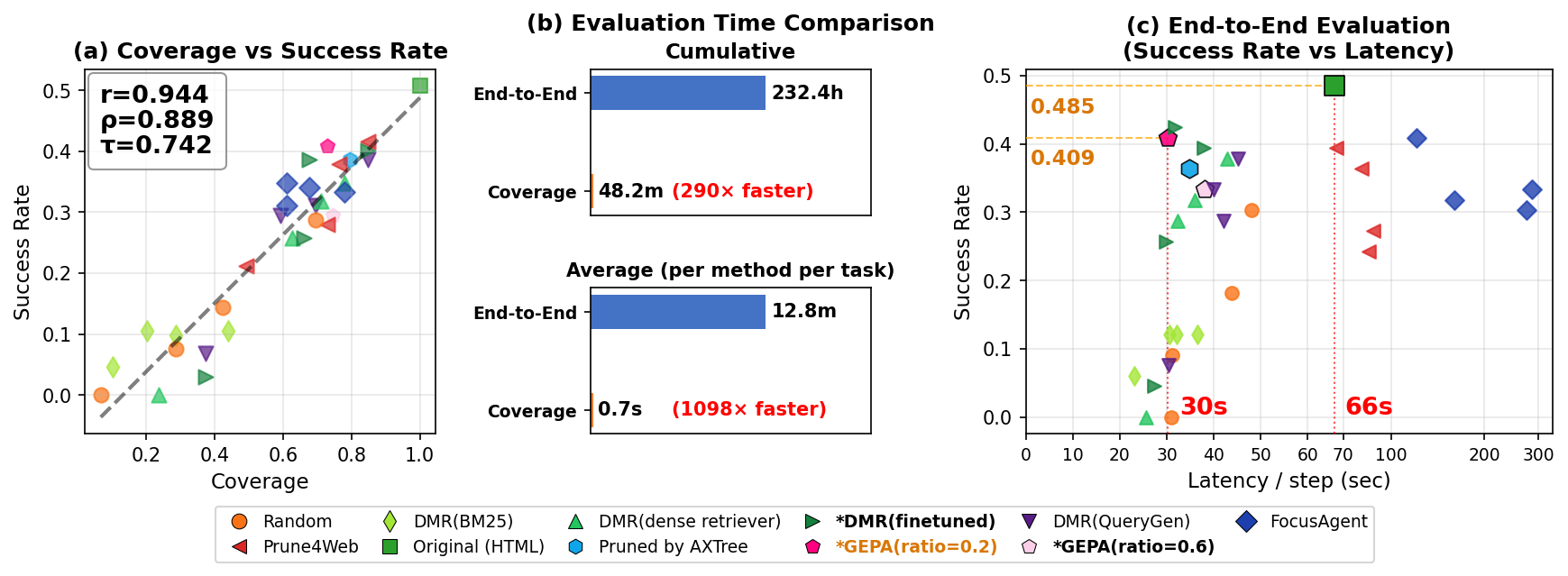
Fig 1: Key results of our framework on WorkArena L1 (33 tasks). (a) Coverage versus end-to-end success
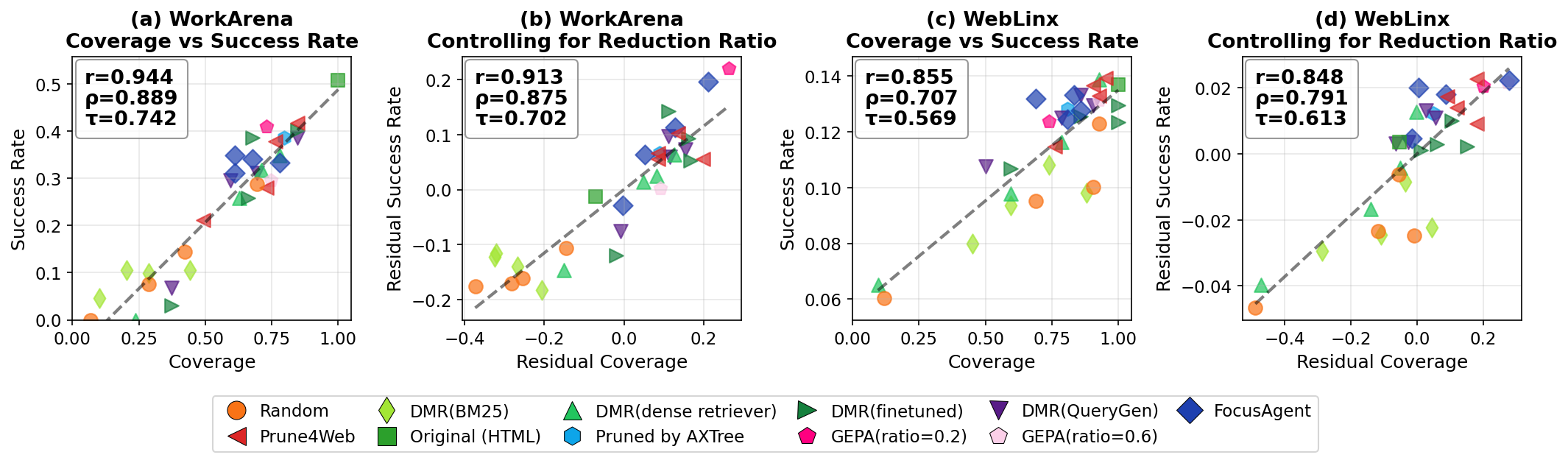
Fig 2: Correlation between coverage and end-to-end success rate across HTML reduction methods. (a, c) Scatter
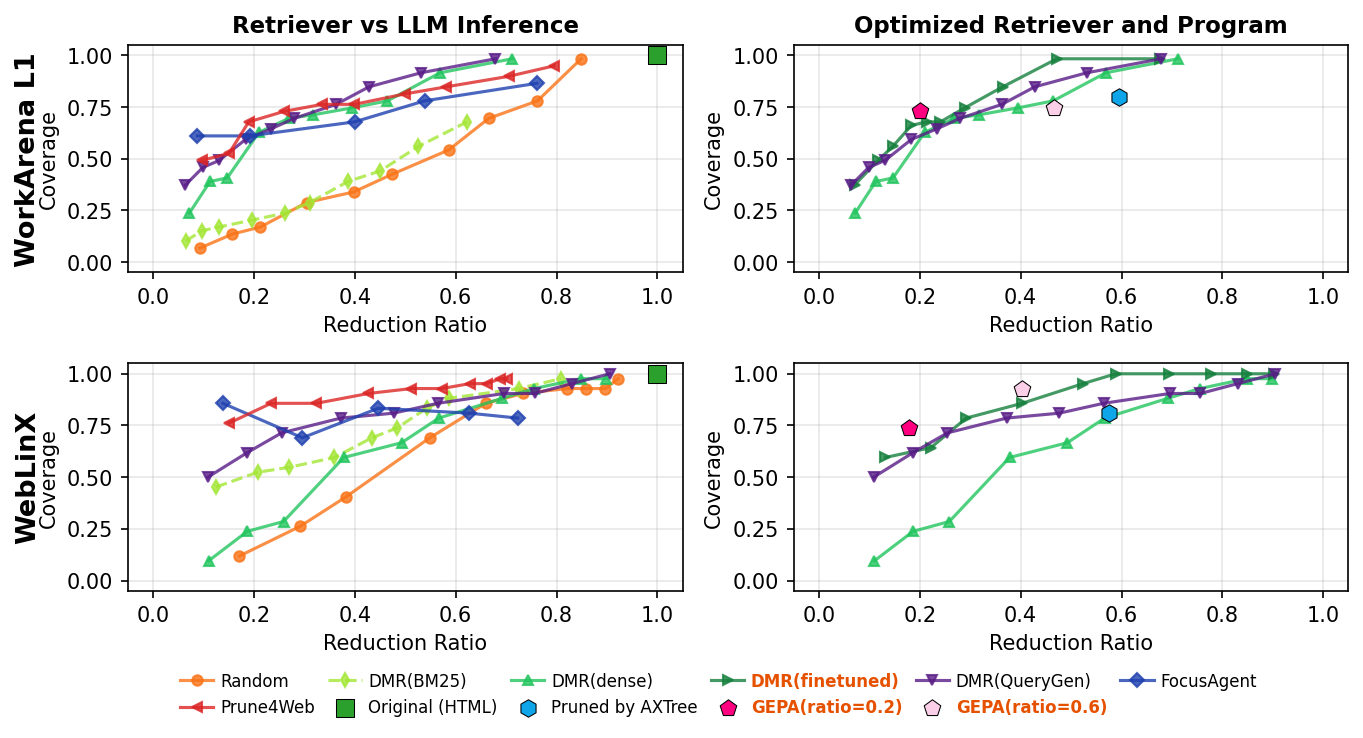
Fig 3: Coverage versus reduction ratio on WorkArena L1 (top) and WebLinx (bottom). Left column compares
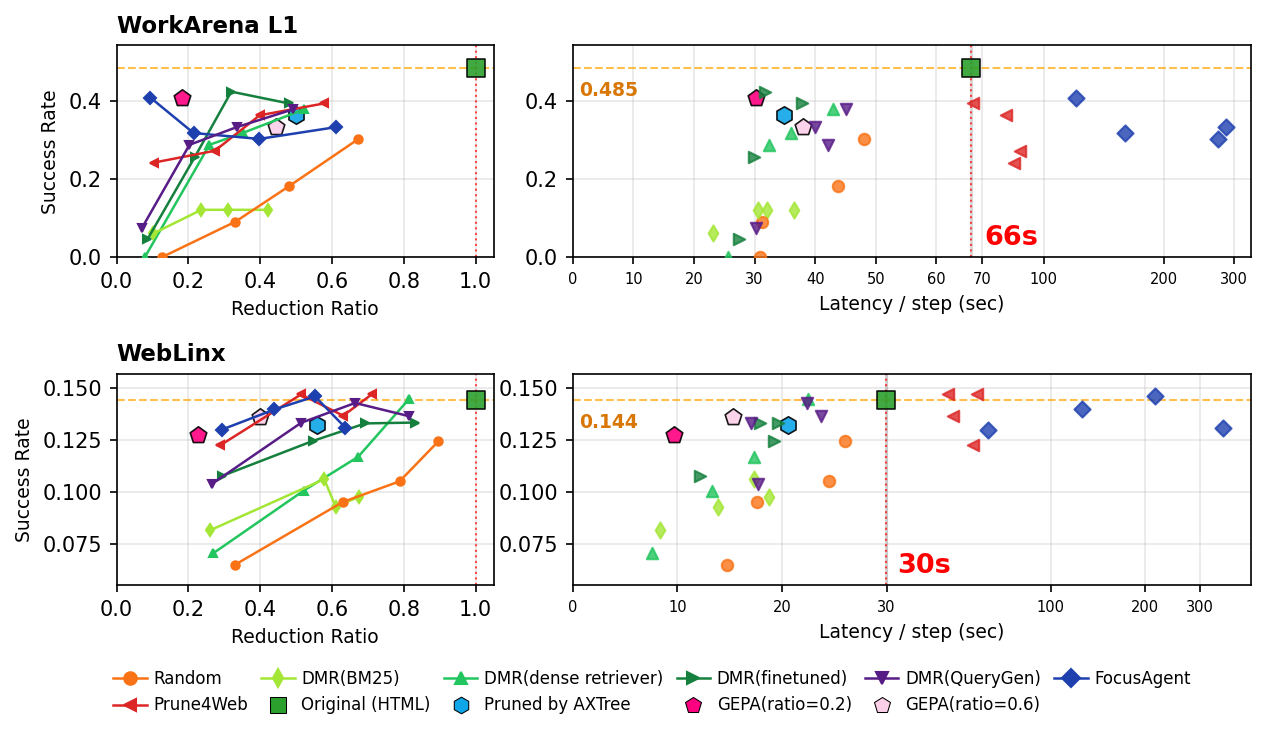
Fig 4: End-to-end evaluation with Qwen3.5-122B-A10B as the policy model on WorkArena L1 (top) and
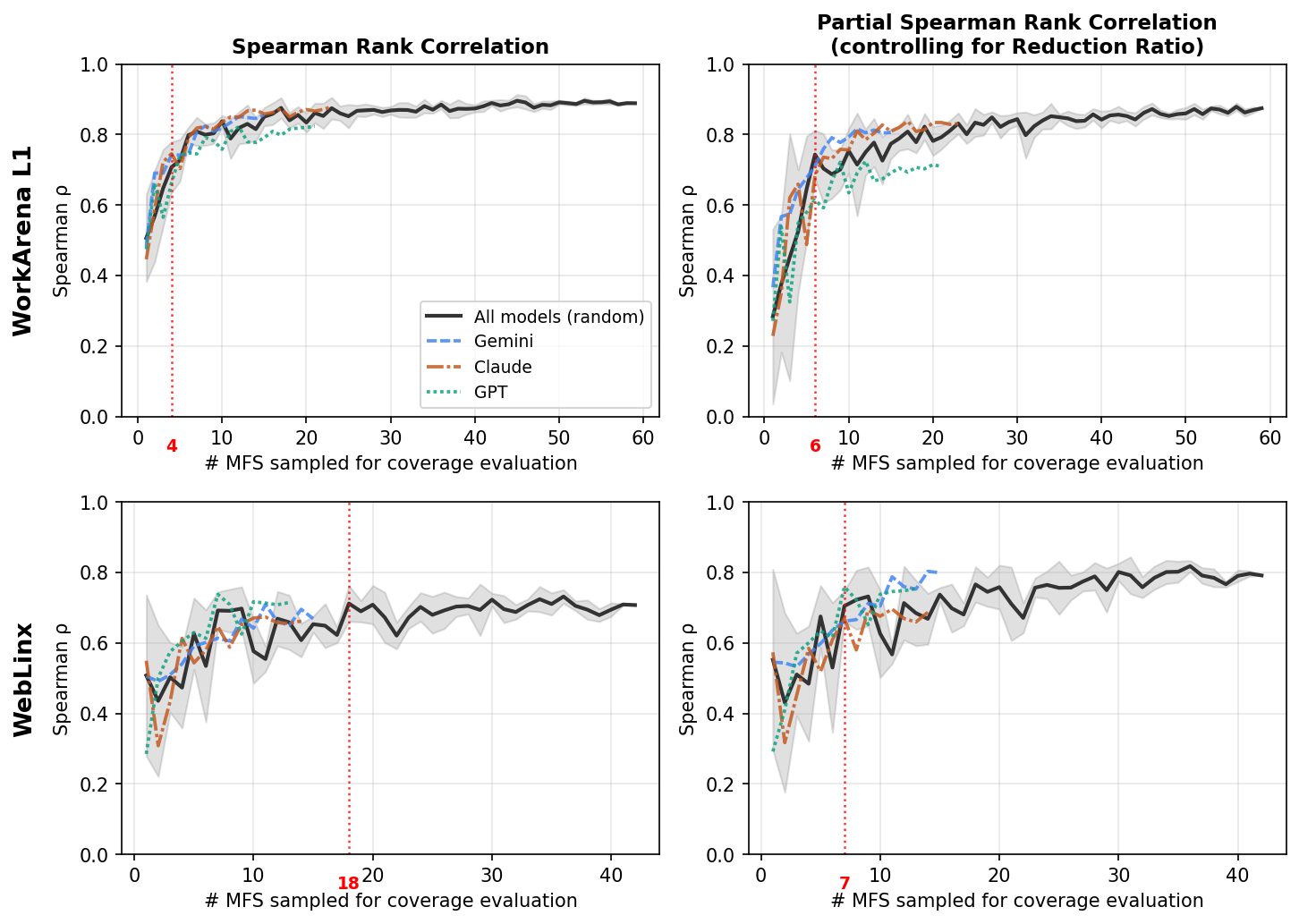
Fig 5: Spearman rank correlation between coverage and end-to-end success rate as a function of the number of
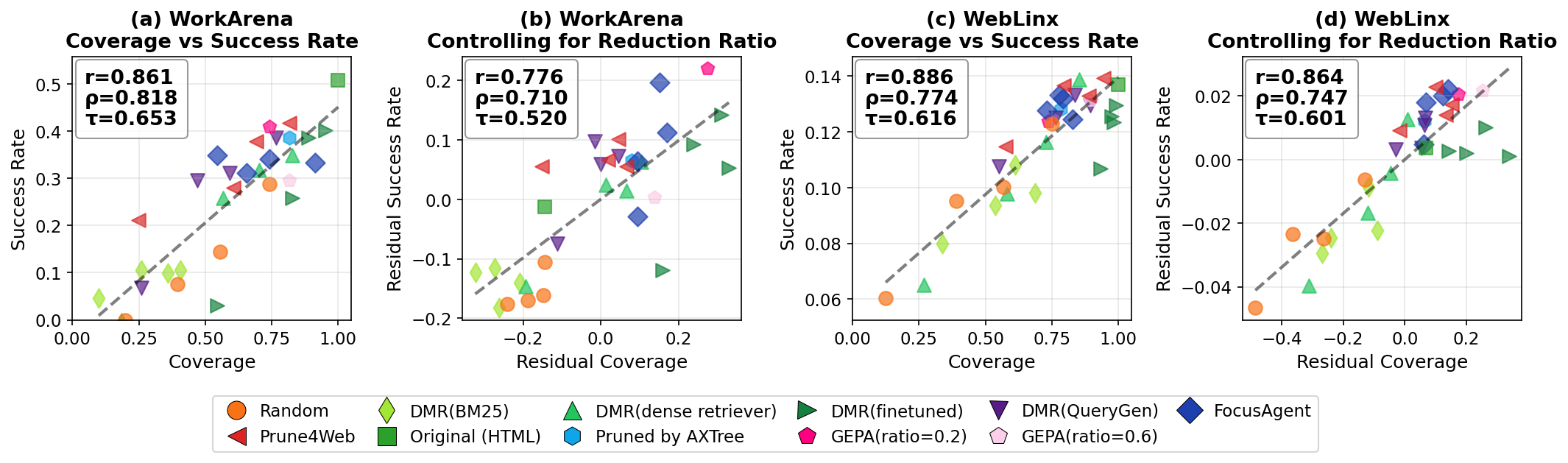
Fig 6: Correlation between coverage and end-to-end success rate when coverage is computed on the MFS
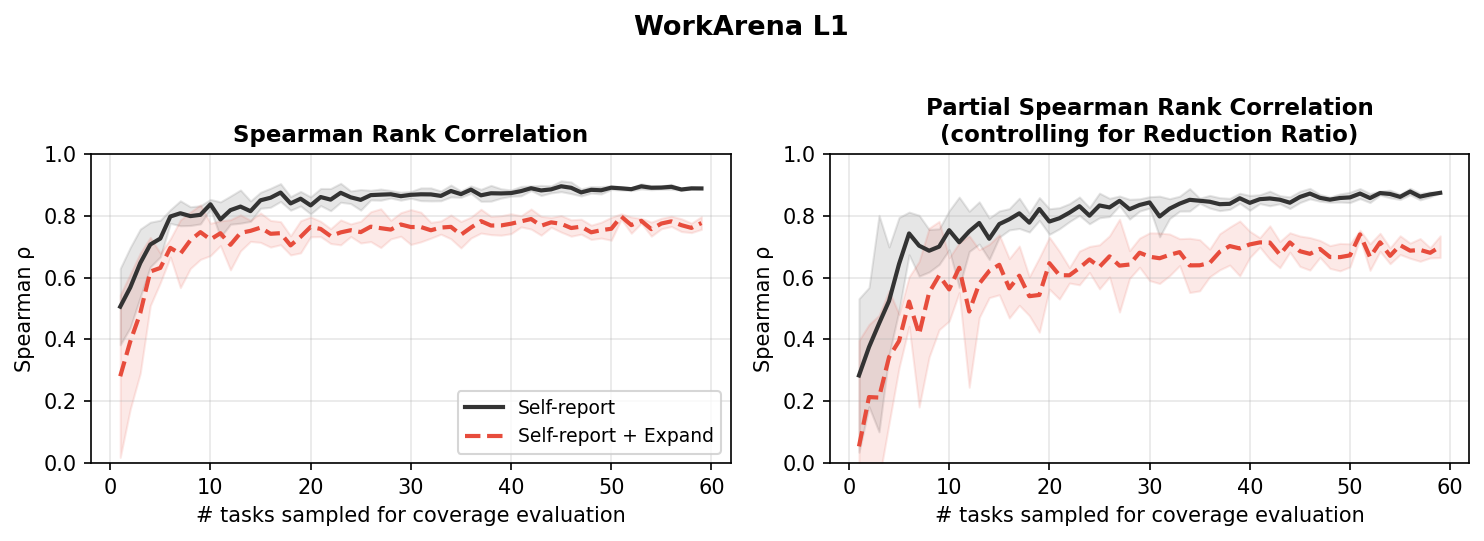
Fig 7: Spearman rank correlation between coverage and end-to-end success rate on WorkArena L1, comparing
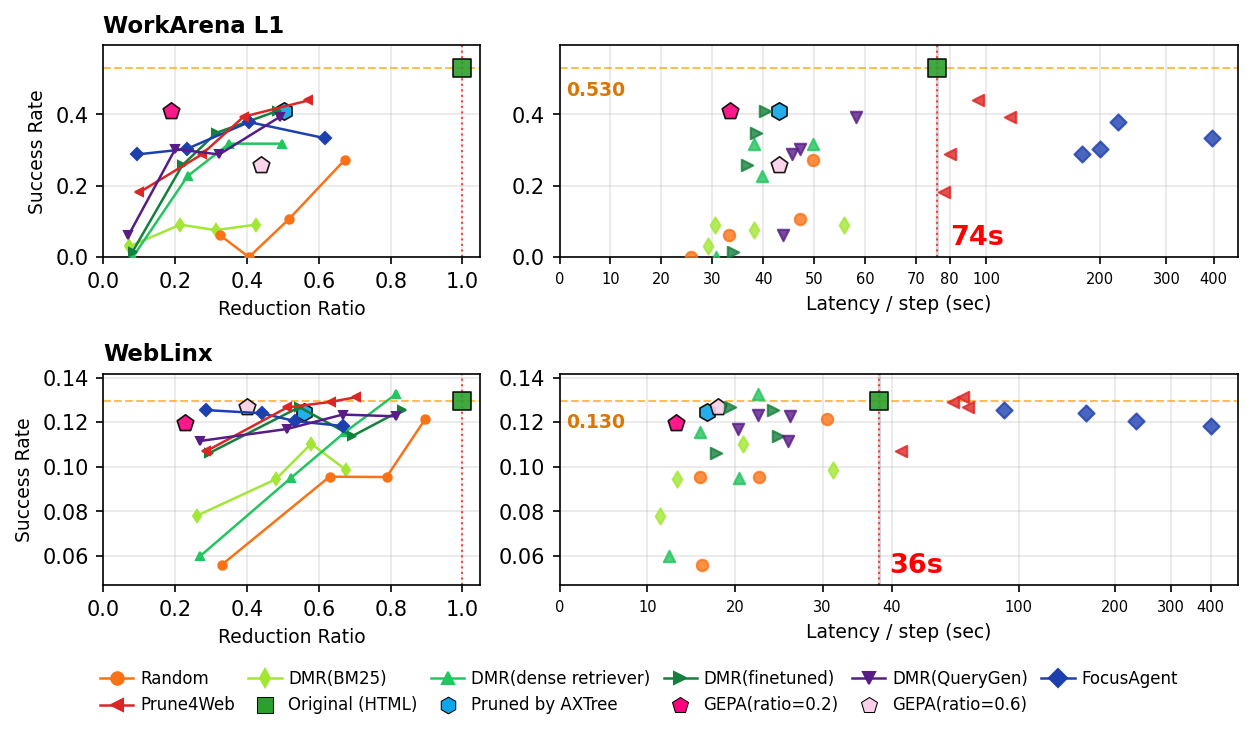
Fig 8: End-to-end evaluation with MiniMax-M2.5 as the policy model. Left column: success rate versus
Limitations
- The coverage metric applies only to extractive HTML element selection methods and cannot evaluate non-extractive transformations like summarization or semantic compression.
- MFS construction depends on observed trajectories; elements required for unseen or alternative successful trajectories may not be represented in the MFS data.
- MFS instances and raw HTML observations are not publicly released due to licensing constraints, limiting reproducibility outside the authors’ environment.
- Approximate MFS construction uses proxies (erroneous actions) for failure detection during delta debugging to reduce cost, which may miss subtle dependencies and thus not yield true minimal sets.
- The evaluation focuses on a limited set of benchmarks (WorkArena L1 and WebLinx) and LLM policy models, leaving generalization to other web domains and agent architectures unverified.
- Live web environment interaction incurs latency and variability, potentially affecting evaluation consistency, although coverage addresses this by removing web dependency.
Open questions / follow-ons
- Can MFS-based evaluation and optimization be extended to non-extractive observation reduction methods, such as semantic compression or learned summarization?
- How stable is the MFS across a wider variety of LLM policy models, web domains, and task types beyond WorkArena and WebLinx?
- Can the MFS be integrated into training objectives of end-to-end policy models to jointly learn observation reduction and action prediction?
- What are effective ways to approximate or capture minimal failure sets in less structured, dynamic, or multi-modal web observations beyond HTML?
Why it matters for bot defense
For practitioners designing bot defenses and CAPTCHA systems that interact with or depend on LLM-based web agents, this paper’s lightweight evaluation framework offers a powerful tool to rapidly benchmark and optimize observation reduction strategies. Reducing agent input latency while ensuring they do not lose critical task-relevant information parallels the challenge of designing defenses that balance usability and robustness against automated agents. The MFS and coverage concepts provide a principled way to identify minimal, critical information sets necessary for a task, which could inspire analogous ideas in CAPTCHA challenge design or bot detection signals.
Moreover, the paper clarifies the trade-offs between computational cost of reduction (not unlike anti-bot challenge costs) and effectiveness, emphasizing domain-specific tuning. Bot defense engineers may apply similar methods for rapid offline assessment of agent capabilities or to optimize challenge presentations dynamically for latency and security. Finally, understanding which HTML or DOM elements are crucial for automated agents to maintain high performance can inform which elements or interactions to harden or monitor in real-world bot detection contexts.
Cite
@article{arxiv2605_29397,
title={ Revisiting Observation Reduction for Web Agents: Comprehensive Evaluation with a Lightweight Framework },
author={ Masafumi Enomoto and Ryoma Obara and Haochen Zhang and Masafumi Oyamada },
journal={arXiv preprint arXiv:2605.29397},
year={ 2026 },
url={https://arxiv.org/abs/2605.29397}
}