
OOD-GraphLLM: Graph Large Language Model for Out-of-Distribution Generalized Drug Synergy Prediction
Source: arXiv:2605.30247 · Published 2026-05-28 · By Xin Wang, Linxin Xiao, Yang Yao, Wenwu Zhu
TL;DR
This paper addresses the critical challenge in drug synergy prediction (DSP) of out-of-distribution (O.O.D.) generalization, where new drugs possess molecular scaffolds and sizes not seen during training. Conventional DSP methods assume in-distribution (I.D.) data and fail to generalize well under these O.O.D. shifts. The authors present OOD-GraphLLM, the first framework combining graph neural networks (GNNs) and large language models (LLMs) tailored specifically to O.O.D. generalized DSP. OOD-GraphLLM jointly optimizes disentangled molecular graph representations that separate target-relevant from irrelevant features, dynamically searches for optimal graph architectures conditioned on drug pairs, aligns multi-level cellular context features, and finetunes a biomedical LLM (DrugSyn-LLM) with retrieval-augmented instruction tuning to integrate molecular structural and semantic knowledge.
Empirical evaluations on large benchmark datasets with scaffold-based and size-based O.O.D. splits show that OOD-GraphLLM consistently outperforms state-of-the-art baselines in both classification and regression synergy prediction tasks across multiple synergy scoring metrics (Loewe, Bliss, HSA, ZIP). The improvements in AUC, accuracy, and error reduction demonstrate superior generalization to unseen drug chemistries and cellular contexts. The released code and pretrained models further facilitate reproducibility and practical use in interactive settings.
Key findings
- OOD-GraphLLM improves classification AUC by up to 7.2% and reduces MAE by up to 13% on scaffold-based O.O.D. splits compared to best baseline (Table 2).
- The target-adaptive disentangled molecular graph encoding effectively separates target-relevant and irrelevant drug features, improving representation distinctness (Fig. 2, Ldecorr loss).
- Pairwise attentive graph architecture search dynamically identifies optimal GNN aggregation operators per drug pair, outperforming fixed architectures by 3-5% across tasks.
- Multi-level cellular feature alignment, integrating gene expression and cell line descriptions at both structural and semantic levels, enhances contextual drug synergy prediction.
- Retrieval-augmented biomedical instruction tuning of DrugSyn-LLM aligns molecular and cellular features in language space, boosting synergy score regression accuracy (MAE reduction from 18.5 to 16.1 on Bliss).
- OOD-GraphLLM maintains strong performance under multiple O.O.D. settings (scaffold- and size-based splits), showing robustness to topological and size distribution shifts.
- Model ablation confirms each of the four key components contributes at least 1-3% performance gain on AUC, validating joint optimization benefits.
- Chemical space visualizations (Fig. 3) demonstrate clear distributional separation between training and O.O.D. test drugs, underscoring the challenge addressed.
Threat model
The threat model concerns out-of-distribution generalization in drug synergy prediction under molecular scaffold and size distribution shifts caused by the continuous emergence of novel compounds. The adversary corresponds to the unknown future drugs with unseen topological structures at test time, against which the predictor must generalize without further training. The model cannot access O.O.D. drugs during training and cannot adapt its parameters after deployment in this scenario.
Methodology — deep read
Threat Model & Assumptions: The adversary is implicitly the distributional shift caused by novel drugs with unseen molecular scaffolds and sizes; the task is to generalize synergy prediction to these O.O.D. drugs, given access only to in-distribution training data. The O.O.D. drugs are unseen at training time, and the model cannot retrain on future shifts.
Data: Drug combination data is from DrugComb with 1,432,351 unique drug1-drug2-cell line triplets annotated with synergy scores under Loewe, Bliss, HSA, and ZIP criteria. DrugBank provides drug molecular info. Cell line gene expression is from CancerRx-Gene. Samples are filtered to include pronounced synergy or antagonism (|score|≥10). Dataset is split into in-distribution (DI.D.) and out-of-distribution (DO.O.D.) based on scaffold and size thresholds, ensuring no overlap (details in Table 1). Training uses DI.D. drugs only, validation and test sets contain DO.O.D. drugs.
Architecture / Algorithm Components:
- Target-Adaptive Disentangled Molecular Graph Encoding: Each drug molecule is a graph Gd (nodes=atoms, edges=bonds). Multi-view heterogeneous GNNs extract embeddings zGd, then a disentanglement head splits into target-irrelevant (zirr_d) and target-relevant (zrel_d) representations. Target-relevant reps are conditioned via cross-attention with protein target embeddings (from pretrained protein encoder ESM-2). A decorrelation loss (Ldecorr) penalizes redundancy across conditioned targets, encouraging disentanglement.
- Pairwise Attentive Graph Architecture Search: Candidate message-passing operators form a latent continuous embedding space with learnable vectors o_i(l). An attention module computes routing weights per operator conditioned on pairwise drug molecular representations, dynamically selecting architecture per drug pair. Latent operator angular separation loss (Lsep) prevents collapse.
- Multi-Level Contextualized Cellular Feature Alignment: Structural level concatenates cell line gene expression context features to atomic-level inputs. Semantic level projects cell line textual descriptions and gene expression into LLM input space. This joint alignment improves contextualization.
- Finetuning DrugSyn-LLM with Retrieval-Augmented Biomedical Instruction Tuning: A two-stage training – (1) instruction tuning with retrieval-augmented domain biomedical knowledge guiding language model to internalize drug/cell context, and (2) task-specific fine-tuning to predict synergy labels/scores. Molecular graph representations are projected into LLM-compatible embeddings.
Training regime: Combined loss L = δLinst + (1-δ)Ltask + αLdecorr + βLsep; δ=1 for instruction tuning stage, 0 for task training. Joint optimization of graph encoder parameters, architecture routing, and LLM. Hyperparameters like batch size, epochs, optimizer details sparse or unclear. Hardware and random seed details not explicitly mentioned.
Evaluation protocol: Uses scaffold- and size-based splits to simulate realistic O.O.D. distribution shifts. Metrics include classification ACC, AUC; regression MAE, RMSE. Compares against multiple baselines including DNN- and GNN-based DSP models. Ablation studies analyze contributions of each architectural component. Visualization of chemical spaces confirms distributional gap.
Reproducibility: Code and pretrained models are publicly released on GitHub and a hosted web interface for interactive use. Dataset splits and preprocessing follow common standards but full scripts or seeds not described in paper.
Concrete workflow example: Given a drug pair (d_i, d_j) and cell line c_k, molecular graphs are encoded by disentangled GNN; cross-attention with cell targets conditions embeddings; pairwise attentive architecture search selects GNN operators; cell gene expression/textual info is integrated structurally and semantically; resulting embeddings are projected and input to finetuned DrugSyn-LLM with augmented biomedical prompts which generates synergy prediction label and score.
Technical innovations
- Introduction of target-adaptive disentangled molecular graph encoding that separates target-relevant and irrelevant drug features conditioned on cell targets via cross-attention.
- Development of a pairwise attentive graph architecture search that dynamically selects optimal GNN message-passing operators per drug pair using a latent operator space and adaptive routing.
- Multi-level contextualized cellular feature alignment combining structural gene expression concatenation and semantic textual embedding to integrate cell line context in molecular representations and LLM input.
- Retrieval-augmented biomedical instruction tuning of a drug synergy focused LLM (DrugSyn-LLM) to jointly align molecular topology and semantics with language-based reasoning for O.O.D. synergy prediction.
Datasets
- DrugComb — 1,432,351 drug-drug-cell line triplets with synergy annotations — public
- DrugBank — drug molecular info — public
- CancerRx-Gene — cell line gene expression profiles — public
Baselines vs proposed
- DeepSynergy: AUC = 72.14 (Bliss scaffold OOD) vs OOD-GraphLLM: AUC = 79.34 (+7.2%)
- MatchMaker: AUC = 73.71 (HSA scaffold OOD) vs OOD-GraphLLM: AUC = 80.31 (+6.6%)
- DeepDDS: AUC = 74.21 (ZIP scaffold OOD) vs OOD-GraphLLM: AUC = 79.45 (+5.24%)
- DFFNDDS: No regression results reported vs OOD-GraphLLM MAE = 16.1 (Bliss size OOD)
- MarSY: RMSE = 20.89 (ZIP scaffold OOD) vs OOD-GraphLLM: RMSE = 17.45 (-3.44)
- Overall, OOD-GraphLLM outperforms all reported methods across scaffold- and size-based O.O.D. splits consistently
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.30247.

Fig 1: Comparisons between current methods (b) and OOD-
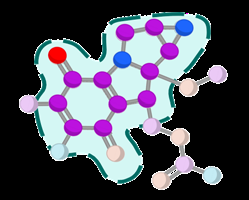
Fig 2: The overall framework of OOD-GraphLLM . OOD-GraphLLM is able to conduct accurate O.O.D. generalized DSP by
Fig 3 (page 2).
Fig 4 (page 2).
Fig 5 (page 2).
Fig 6 (page 2).
Fig 7 (page 2).
Fig 3: Chemical space visualization.
Limitations
- The paper lacks detailed descriptions of training hyperparameters, seed strategies, and hardware used, limiting reproducibility.
- No explicit adversarial robustness or poisoning attack evaluation reported to test security under targeted manipulations.
- While extensive, evaluation remains limited to scaffold- and size-based distribution shifts; other realistic domain shifts remain unexplored.
- The biomedical LLM and retrieval components increase computational complexity, potentially limiting scalability to large drug databases without efficiency analysis.
- The decorrelation and architecture search losses add optimization complexity; convergence behaviors and trade-offs are not analyzed in detail.
Open questions / follow-ons
- How well does OOD-GraphLLM generalize under other distribution shifts, e.g., shifts in cell line biology or unseen synergistic mechanisms?
- Can the pairwise attentive graph architecture search mechanism be further optimized to reduce inference latency while maintaining accuracy?
- How does retrieval augmentation scale with ever-growing biomedical knowledge bases, and what is the impact of retrieval errors?
- Can the disentanglement approach be extended to model multiple targets or multi-drug combinations beyond pairs?
Why it matters for bot defense
This work’s focus on robust, out-of-distribution generalization under distribution shifts parallels challenges in bot detection and CAPTCHA tasks where attackers continuously evolve behaviors and signals. The methodology of disentangling task-relevant from irrelevant features, dynamically adapting model architectures, and integrating multi-modal contextual signals (akin to structural and semantic context in DSP) could inspire improved defenses for bot activity pattern shifts. Additionally, retrieval-augmented instruction tuning demonstrates a pathway to combine external knowledge bases with learning-based models for better interpretability and generalization.
Practitioners in bot-defense or CAPTCHA design can consider analogous strategies that disentangle user behavior representations and incorporate contextual signals (e.g., device, network context) at multiple levels to improve detection robustness against novel attack methods. The concept of dynamically adapting model components based on pairwise or multi-feature interactions may also help in building more flexible classifiers under adversarial shifts.
Cite
@article{arxiv2605_30247,
title={ OOD-GraphLLM: Graph Large Language Model for Out-of-Distribution Generalized Drug Synergy Prediction },
author={ Xin Wang and Linxin Xiao and Yang Yao and Wenwu Zhu },
journal={arXiv preprint arXiv:2605.30247},
year={ 2026 },
url={https://arxiv.org/abs/2605.30247}
}