
MOOSE-Copilot: A Web-Based Interactive Assistant for Unified Exploratory and Fine-Grained Scientific Hypothesis Discovery
Source: arXiv:2605.29475 · Published 2026-05-28 · By Hongran An, Zonglin Yang
TL;DR
MOOSE-Copilot addresses the challenge of unifying two complementary but traditionally separate tasks in automated scientific hypothesis discovery: exploratory, divergent ideation and fine-grained, convergent refinement. Prior approaches either focus on broad exploratory search or narrowly optimize given research directions, and almost all operate autonomously without meaningful human guidance. This work proposes a novel human–AI interaction (HAII) protocol that formally integrates human expert inputs at three levels: initial blueprint constraints, inter-stage routing decisions between exploration and exploitation phases, and iterative intra-stage targeted feedback. Through this structured human steering, MOOSE-Copilot significantly improves hypothesis discovery quality compared to autonomous baselines. Using an oracle-simulated expert to provide high-quality interventions, the system achieves a clear performance ceiling, revealing how principled human-AI collaboration can both prune the search space and strategically guide generative LLM agents. Additionally, the paper delivers a fully accessible web-based interface with a tree visualization of hypotheses and ranking visualization, lowering the barrier for domain experts to engage interactively without command-line complexity. Overall, MOOSE-Copilot presents the first unified framework to bridge the gap between exploratory and fine-grained hypothesis discovery, formalizes human control signals to mitigate complexity, and operationalizes these concepts into a usable software tool.
Key findings
- Injecting initial blueprints alone improved recall from 11.44% (MC baseline) to 15.37%.
- Oracle-guided inter-stage routing and feedback increased recall further, reaching 26.96% recall with the strongest feedback signal (MC2_with_strong_feedback_x4_oracle_rank).
- Inter-stage routing decisions are critical: user-directed node selection controls search trajectory and final hypothesis quality.
- Iterative regenerative feedback within each stage leads to faster convergence and higher-quality fine-grained hypotheses.
- MOOSE-Copilot reduces hypothesis generation complexity from joint search over exploratory and exploitation spaces to a manageable human-steered state machine (Equation 3).
- Experiments conducted over TOMATO-Chem2 benchmark dataset encompassing 51 top-tier scientific papers with detailed ground-truth hypotheses.
- The web interface enables transparent visualization of complex hypothesis search trees and ranked hypotheses with LLM self-evaluation scores for expert assessment.
Threat model
The adversary is not explicitly defined as this is a scientific knowledge discovery aid rather than a security-focused system. The primary intent is to enable domain experts to steer hypothesis generation while preventing uncontrolled or misleading autonomous outputs by large language models. Potential misuse scenarios discussed include uncritical acceptance of AI-generated hypotheses or use in pseudoscientific contexts, emphasizing the system is designed to keep humans meaningfully in the loop to maintain scientific rigor.
Methodology — deep read
The authors start by defining the problem space as two interconnected scientific discovery phases: exploratory hypothesis discovery and fine-grained hypothesis refinement. Exploratory discovery is framed as a Markov Decision Process where hypotheses are incrementally expanded by incorporating inspiration from a curated corpus of paper titles and abstracts, following the MOOSE-Chem model. Fine-grained discovery is an optimization problem targeting plausibility and coherence of detailed hypotheses, solved via hierarchical coarse-to-fine refinements per MOOSE-Chem2.
They propose a unified framework that couples these phases through a formal Human-AI Interaction Interface (HAII) protocol, which enables scientists to inject three classes of expert guidance signals: (1) initial blueprints that prune the search space early, (2) inter-stage routing to decide when and which exploratory nodes to transition to fine-grained exploitation (and vice versa), and (3) intra-stage regenerative feedback to iteratively critique and refine hypotheses within each stage. This reduces the intractable joint hypothesis search space into a human-steered state machine where user interventions dynamically prune and redirect the search trajectory.
The paper operationalizes this protocol through a web-based interface that accepts user input of a research question, literature context, and optionally a custom inspiration corpus. The system visualizes hypotheses as a tree of incremental expansions, showing provenance from background to inspiration papers. Researchers can select nodes for targeted exploration or exploitation and provide feedback that re-conditions the LLM generation process. Hypothesis ranking with LLM self-evaluation scores assists user selection.
For evaluation, they use the TOMATO-Chem2 dataset containing 51 well-annotated scientific papers with ground-truth hypotheses and research questions. They simulate an oracle expert who supplies initial blueprints, optimal routing decisions, and non-disclosive feedback critiques based on ground truth, to cleanly measure the intrinsic benefit of the HAII signals without human bias or noise. Recall of ground-truth hypothesis elements recovered by generated outputs is the primary performance metric.
Experiments systematically validate the individual and combined effects of the HAII signals by comparing autonomous baselines, single-signal injection, and multi-signal scenarios repeated with increasingly strong oracle feedback. Results demonstrate clear incremental gains and a final ceiling performance under strong oracle guidance. The evaluation assesses the number of search steps (iterations) alongside recall to measure efficiency.
Training details of the underlying LLM agents follow prior MOOSE-Chem / MOOSE-Chem2 setups and are not elaborated fully. The system supports user API key integration instead of running proprietary LLMs.
Reproducibility is supported via an open source web interface and released code at https://moosedemo.com. The TOMATO-Chem2 dataset is publicly documented in associated prior work. Oracle simulation methodology is detailed to enable replicability.
Technical innovations
- Formally unify exploratory (divergent) and fine-grained (convergent) scientific hypothesis discovery into one human-in-the-loop framework.
- Introduce a principled human-AI interaction protocol with three explicit signals: initial blueprints, inter-stage routing, and intra-stage regenerative feedback.
- Model the unified discovery process as a human-intervened state machine that reduces joint search over exploratory and exploitation spaces into a manageable, pruneable trajectory.
- Develop a user-friendly web interface with interactive tree visualization and hypothesis ranking to facilitate transparent, interpretable human steering.
Datasets
- TOMATO-Chem2 — 51 papers with detailed research questions, literature surveys, and annotated fine-grained hypotheses — publicly released in Yang et al. (2025a)
Baselines vs proposed
- baseline_MC (MOOSE-Chem exploratory stage): recall = 11.44%
- baseline_MC2 (MOOSE-Chem2 fine-grained stage): recall = 10.33%
- MC_with_hint (adding initial blueprint): recall = 15.37%
- MC_with_soft_feedback_with_hint: recall = 16.78%
- MC_with_feedback_with_hint: recall = 16.93%
- MC2_with_MC_input_oracle_rank: recall = 18.26%
- MC2_with_feedback_oracle_rank (one feedback iteration): recall = 21.98%
- MC2_with_feedback_x3_oracle_rank (three feedback iterations): recall = 22.35%
- MC2_with_strong_feedback_oracle_rank: recall = 23.10%
- MC2_with_strong_feedback_x4_oracle_rank: recall = 26.96%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.29475.
Fig 1: Overview of MOOSE-Copilot. Yellow rectangles indicate hypotheses actively selected by the user for
Fig 2: shows the input interface of MOOSE-
Fig 3: illustrates the tree view of the generated
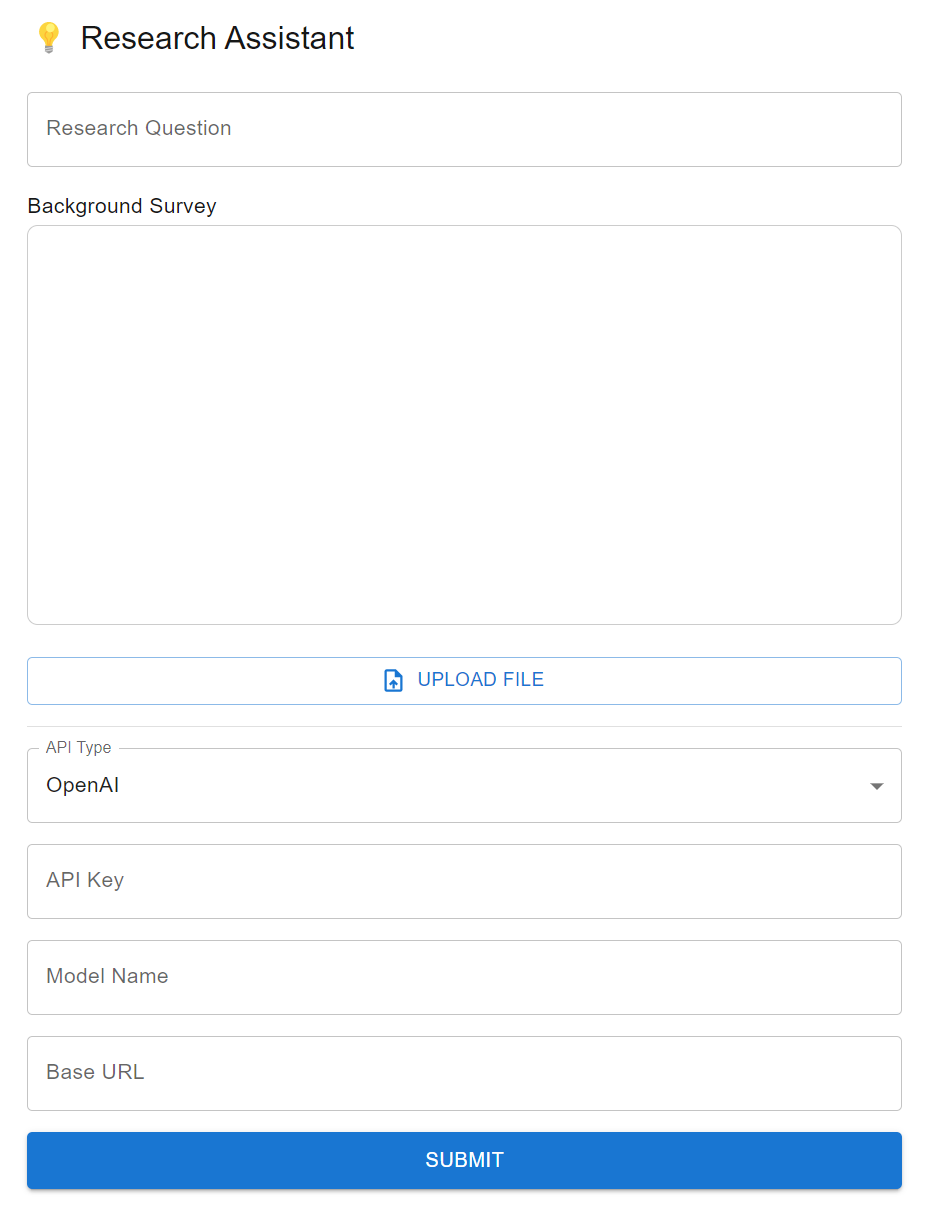
Fig 4: presents the rank view of generated
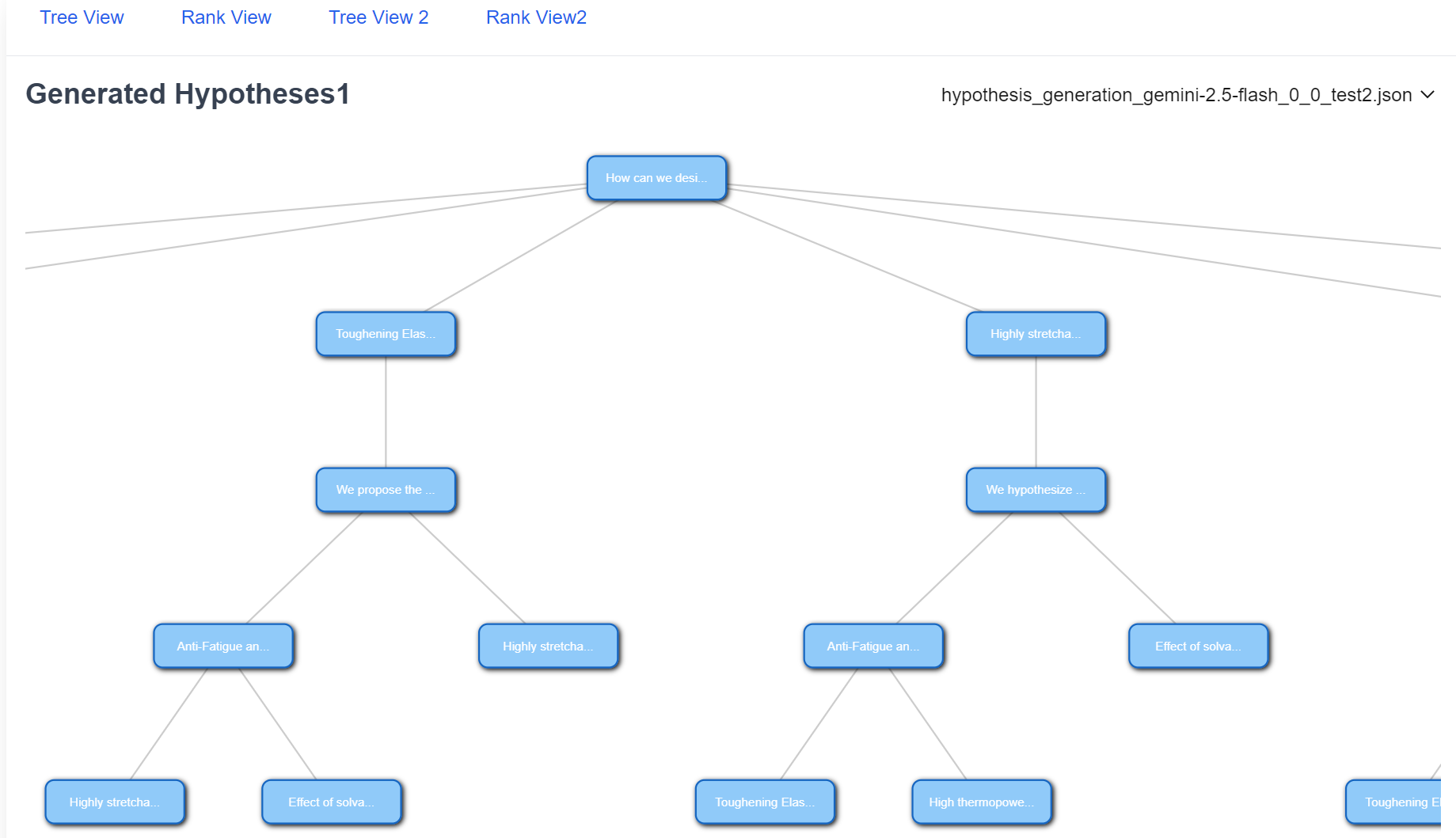
Fig 5: Feedback interface in MOOSE-Copilot.

Fig 6 (page 5).
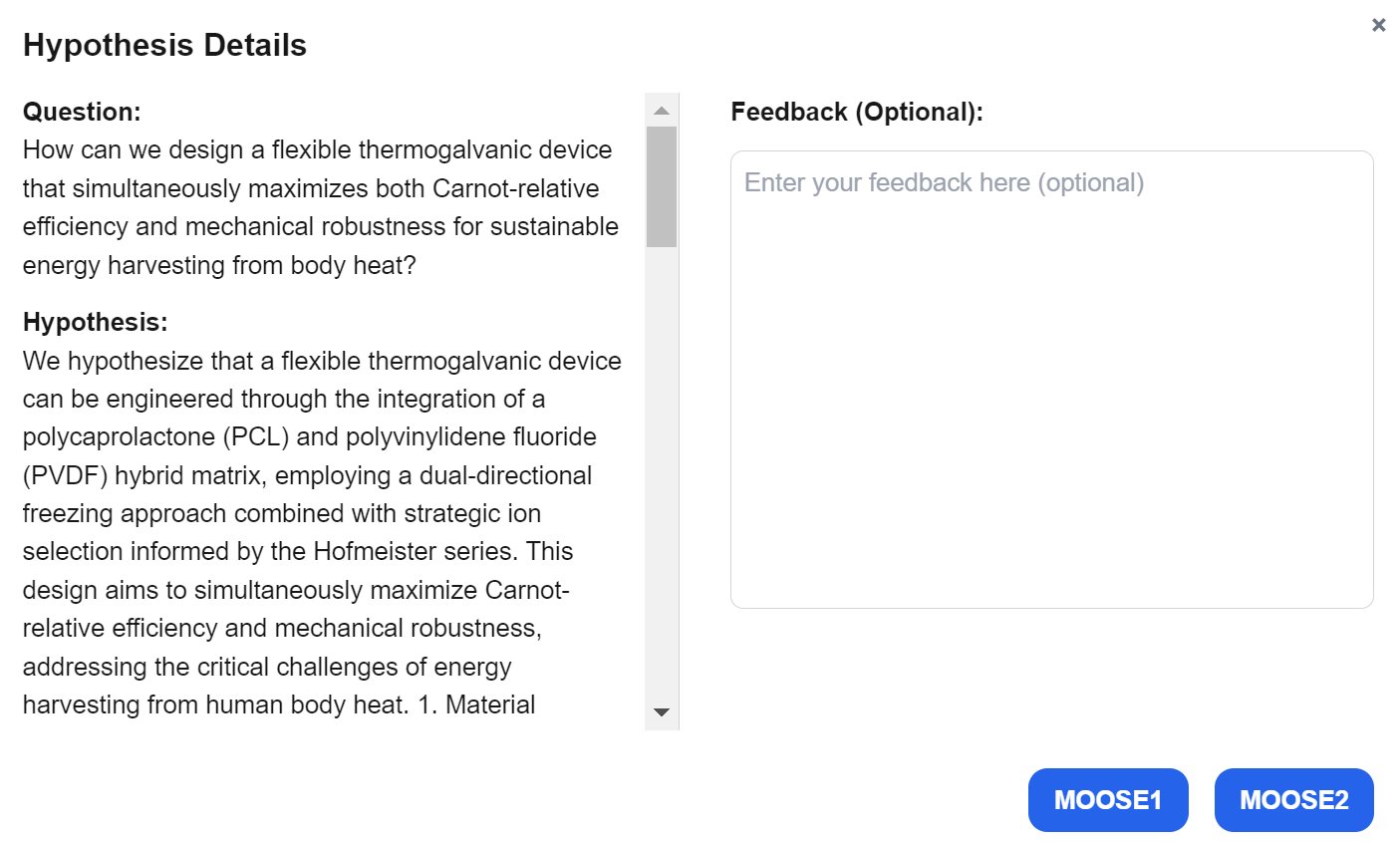
Fig 7 (page 5).
Limitations
- Does not integrate automated experiment execution or empirical validation, limiting closed-loop scientific workflows.
- Relies on oracle-simulated expert feedback in evaluation; real human expert variability and cognitive load remain untested.
- Effectiveness currently demonstrated only on one dataset (TOMATO-Chem2) with 51 papers; limited domain scope and scale.
- Underlying LLMs and training strategies are drawn from prior work; no novel model architecture or scientific domain adaptation is introduced.
- No adversarial analysis or robustness testing against biased or erroneous human feedback is reported.
- User studies assessing actual domain expert usability and impact are not included.
Open questions / follow-ons
- How does MOOSE-Copilot perform with real human experts interacting rather than oracle simulation?
- Can the framework be extended with automated experiment execution linking hypothesis generation to empirical validation for closed-loop scientific discovery?
- What are the effects of adversarial or low-quality feedback signals on system robustness and output trustworthiness?
- How scalable and generalizable is the approach beyond chemistry and the TOMATO-Chem2 benchmark to other scientific disciplines?
Why it matters for bot defense
While MOOSE-Copilot is focused on scientific hypothesis generation rather than bot or CAPTCHA tasks, the core ideas of integrating human-in-the-loop structured signals (initial constraints, routing decisions, feedback) to steer large model-based generation could inform approaches in bot defense to balance automated detection with human oversight. The interactive tree visualization and multi-stage modulation of generative trajectories may inspire more interpretable and user-controllable CAPTCHA generation or challenge-response design. Additionally, the concept of decomposing a complex generation/search space into manageable components under expert direction is broadly applicable for designing robust, controllable AI systems where blind autonomy is risky. However, direct application requires adaptation to threat detection rather than creative discovery.
Cite
@article{arxiv2605_29475,
title={ MOOSE-Copilot: A Web-Based Interactive Assistant for Unified Exploratory and Fine-Grained Scientific Hypothesis Discovery },
author={ Hongran An and Zonglin Yang },
journal={arXiv preprint arXiv:2605.29475},
year={ 2026 },
url={https://arxiv.org/abs/2605.29475}
}