
MonoPhysics: Estimating Geometry, Appearance, and Physical Parameters from Monocular Videos
Source: arXiv:2605.30320 · Published 2026-05-28 · By Daniel Rho, Jun Myeong Choi, Matthew Thornton, Biswadip Dey, Roni Sengupta
TL;DR
MonoPhysics addresses the challenging problem of inferring geometry, appearance, and physical parameters of deformable objects solely from monocular videos. Unlike prior inverse physics methods that rely on multi-view inputs to resolve scale and 3D geometry ambiguities, MonoPhysics introduces novel mechanisms to overcome the inherent scale ambiguity, inaccurate geometry, and weak coupling between appearance and physical simulation that plague monocular settings. By jointly optimizing a differentiable particle-based simulation (Material Point Method) and 3D Gaussian Splatting representation, the framework recovers accurate object shape and material properties from a single camera view. The method is enabled by three key innovations: a learnable global scale factor to resolve scale ambiguity, a physics-aware geometry refinement process that adapts particle volumes and locations during optimization, and a differentiable position map enabling direct silhouette alignment gradients.
Evaluated on both the Vid2Sim benchmark and a newly introduced synthetic dataset of elastic and plastic deformable objects, MonoPhysics significantly outperforms existing monocular inverse physics methods in predicting accurate geometry, physical parameters, and future state simulations. Notably, its single-view physical parameter estimation achieves accuracy comparable to multi-view baselines using 12 cameras, demonstrating that the proposed visual-physical bridges successfully compensate for missing multi-view constraints. Ablations confirm the complementary value of optical flow and silhouette losses, as well as the critical role of physics-aware geometry refinement and position map gradients.
Key findings
- MonoPhysics reduces the Chamfer Distance (CD) for geometry reconstruction on elastic objects from 420-1263 (baselines) to 220 and on plasticine objects from 430-555 to 54 (Tab. 2), indicating substantially improved 3D accuracy.
- Physical parameter estimation error (MAE in log Young’s modulus) is reduced by ~0.4 compared to the best baselines on Vid2Sim monocular setting (0.52 vs 0.80 for GIC; Tab. 1).
- The single-camera MAE for Poisson’s ratio and yield stress on Vid2Sim rivals multi-view methods with 12 cameras (MAE ν of 0.06 vs 0.06; Tab. 1).
- Ablation study (Tab. 3) shows silhouette loss reduces geometry error (CD) from 964 to 151 and optical flow reduces material parameter error (MAE log E) from 0.60 to 0.36, with complementary effects when combined.
- Physics-aware geometry refinement reduced initial Chamfer Distance from 11.41 to 7.23 on the synthetic dataset (Tab. 4), consistent across object types.
- Global scale scalar enables recovery of correct global scale regardless of initial scale estimate, resolving a major monocular ambiguity (Fig. 2).
- Differentiable position map provides direct gradients for shape alignment, enabling particles to move towards correct silhouette shapes even when predictions and targets do not overlap spatially (Fig. 6).
Threat model
The primary 'adversary' here is the monocular input setting itself, which lacks multi-view geometric constraints and absolute scale references. The framework assumes adversaries cannot alter camera parameters or ground plane knowledge, and that object dynamics are faithfully captured by the assumed constitutive models. The method is not designed to defend against active attackers or spoofing, but rather to resolve fundamental ambiguities and uncertainties in monocular inverse physics inference.
Methodology — deep read
Threat Model & Assumptions: The adversary in this case is the inherent ambiguity and information loss in monocular video capture of deformable objects. The system assumes known camera intrinsics and extrinsics, a known ground plane, a known constitutive physical model (e.g., Neo-Hookean elasticity), and availability of foreground alpha masks per frame (obtained via segmentation). The setting explicitly addresses the problem of reconstructing geometry and physical properties without multi-view constraints.
Data: The method uses monocular RGB videos of deforming objects. Evaluation employed two datasets: Vid2Sim (existing multi-view dataset but evaluated in single-view mode by taking only one camera's video) with elastic objects; and a newly introduced synthetic dataset derived from Google Scanned Objects featuring 5 elastic and 5 plasticine objects with randomized material parameters, initial velocities, scales, and camera distances. Ground-truth 3D point clouds and physical parameters are available for evaluation. Alpha masks are used for silhouette supervision.
Architecture / Algorithm:
- Initialization: Starting from monocular 3D reconstruction [27], initial 3D Gaussian Splatting (3DGS) representation is created from the first frame. Each Gaussian acts as both a rendering primitive and a physical particle.
- Forward Model: Particle-based differentiable MPM physics simulator simulates object deformation over time under current material parameters.
- Rendering: At each frame, differentiable 3D Gaussian Splatting renders the deformed particles to image space via alpha compositing.
- Visual-Physical Bridges Introduced:
- Global Scale Scalar s: A learnable scalar in camera space that rescales particle positions coherently along projection rays, resolving scale ambiguity by coupling image-space losses to scale-dependent physical dynamics.
- Physics-Aware Geometry Refinement: Particle volumes are adaptively updated at each step via iterative partition-of-unity over the simulation grid rather than fixed at initialization. Particle relocation uses a combined visual and physical importance metric to split or remove particles, ensuring adaptation to simulation-derived physical constraints.
- Differentiable Position Map: Defines pixel positions as a differentiable function of Gaussian parameters, enabling direct gradient flow from silhouette alignment losses to particle positions, even when predicted and target shapes do not overlap.
- Training Regime: Joint optimization proceeds in two stages: (i) joint optimization of particle physical parameters (material parameters, initial velocity), Gaussian positions, opacities, covariance and global scale s using differentiable simulation and image-based losses; (ii) refinement of appearance parameters (colors) using image color and opacity losses. Losses include L1+SSIM image reconstruction, silhouette loss via Sinkhorn divergence on differentiable position map, probabilistic optical flow loss supervising particle velocity fields, and particle distribution regularizer preventing particle clustering or drifting.
Optimization uses gradient-based methods through differentiable simulation and rendering. Hyperparameters and hardware details are in the supplementary and not fully specified here.
Evaluation Protocol: Metrics on future frame prediction include PSNR, SSIM, LPIPS for rendering quality, Chamfer Distance (CD), Earth Mover's Distance (EMD) for geometry accuracy. Physical parameters are evaluated by Mean Absolute Error (MAE) on initial velocity, log Young's modulus, Poisson's ratio, and yield stress (plasticine only). Comparisons include monocular variants of PAC-NeRF, SpringGaus, GIC baselines. Ablations examine the roles of individual loss components and refinements. Both qualitative visualizations and quantitative metrics are reported. Multi-view Vid2Sim results are used as upper bounds.
Reproducibility: Code and project page are available as per the paper (project link provided), but no mention of frozen weights or closed dataset restrictions. The newly created synthetic dataset details and construction procedure are described in the appendix. The method builds on publicly available monocular 3D reconstruction and differentiable physics frameworks.
Example End-to-End Pipeline: Given a monocular video and alpha masks, initialize a 3DGS representation from the first frame using a monocular 3D foundation model. Sample MPM particles from it. Introduce the learnable scale factor s in camera space. Simulate particle deformation forward with current physical parameters and render frames via 3DGS. Compute losses: color reconstruction, silhouette alignment via differentiable position map, optical flow matching, and particle distribution regularization. Backpropagate gradients through rendering and differentiable physics simulation to jointly update all parameters including s, the particle positions, volumes, appearance, and material parameters. Continue until convergence, then refine colors separately. The optimized parameters yield an estimate of the object geometry and materials consistent with the observed monocular video dynamics.
Technical innovations
- Learnable global scale scalar in camera space that enables coherent scale optimization from monocular videos by moving particles along their projection rays.
- Physics-aware geometry refinement that adaptively updates per-particle volumes from current particle distribution and redistributes particles based on combined visual and physical importance.
- Differentiable position map formulation that enables direct gradient flow from silhouette alignment losses to particle positions, overcoming the weak gradient issue in standard Gaussian splatting.
- Joint end-to-end optimization framework combining differentiable MPM physics simulation, 3D Gaussian splatting rendering, and a suite of visual and physical losses tailored for monocular inverse physics.
Datasets
- Vid2Sim — elastic deformable objects dataset, multi-view video source
- Synthetic Elastic and Plasticine Objects Dataset — 10 objects with randomized parameters and monocular video rendered synthetically, built from Google Scanned Objects (GSO, CC-BY 4.0)
Baselines vs proposed
- PAC-NeRF (monocular): PSNR = 16.46 vs MonoPhysics: 21.42 (Vid2Sim future frame, Tab. 1)
- GIC (monocular): MAE log E = 0.80 vs MonoPhysics: 0.52 (Vid2Sim physical parameter error, Tab. 1)
- Vid2Sim multi-view (12 views): MAE ν = 0.06 vs MonoPhysics monocular: 0.06 (poisson ratio error, Tab. 1)
- On synthetic Plasticine: GIC CD = 458 vs MonoPhysics CD = 54 (geometry error, Tab. 2)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.30320.
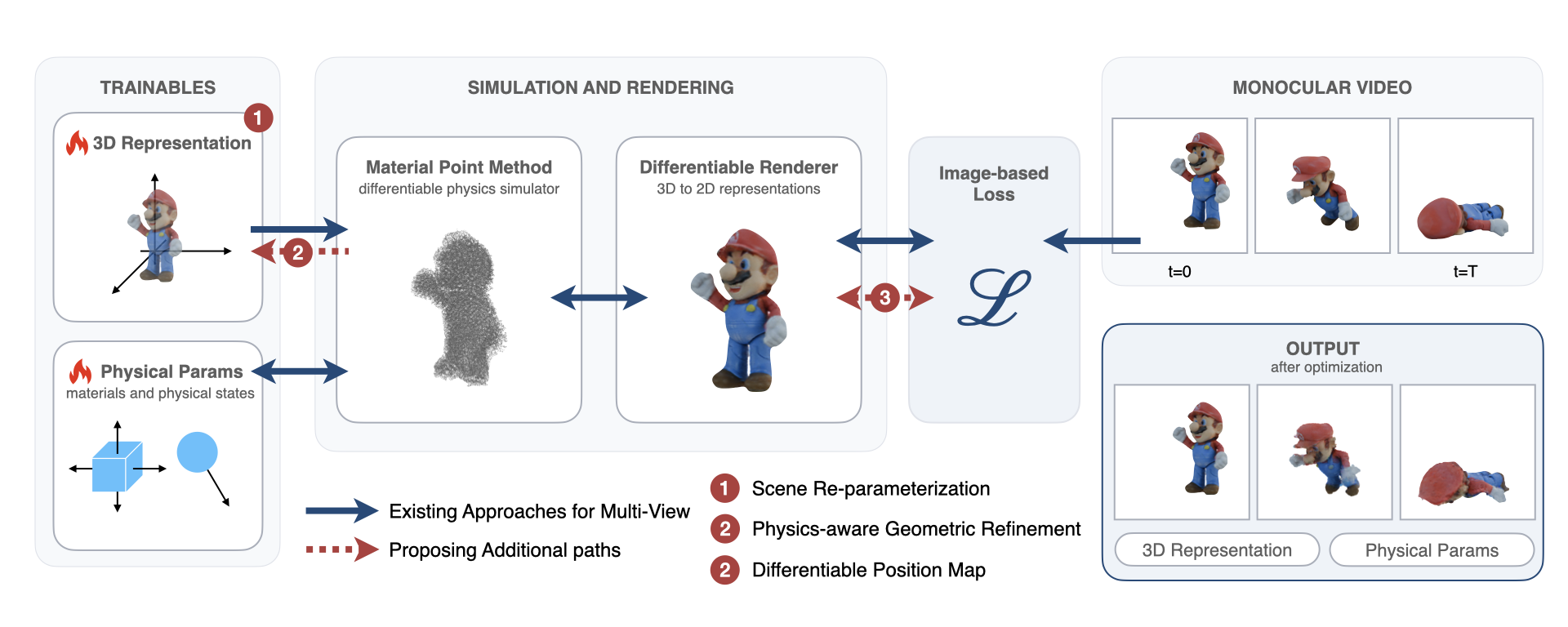
Fig 1: Overview of MonoPhysics. A trainable 3D representation and physical parameters are
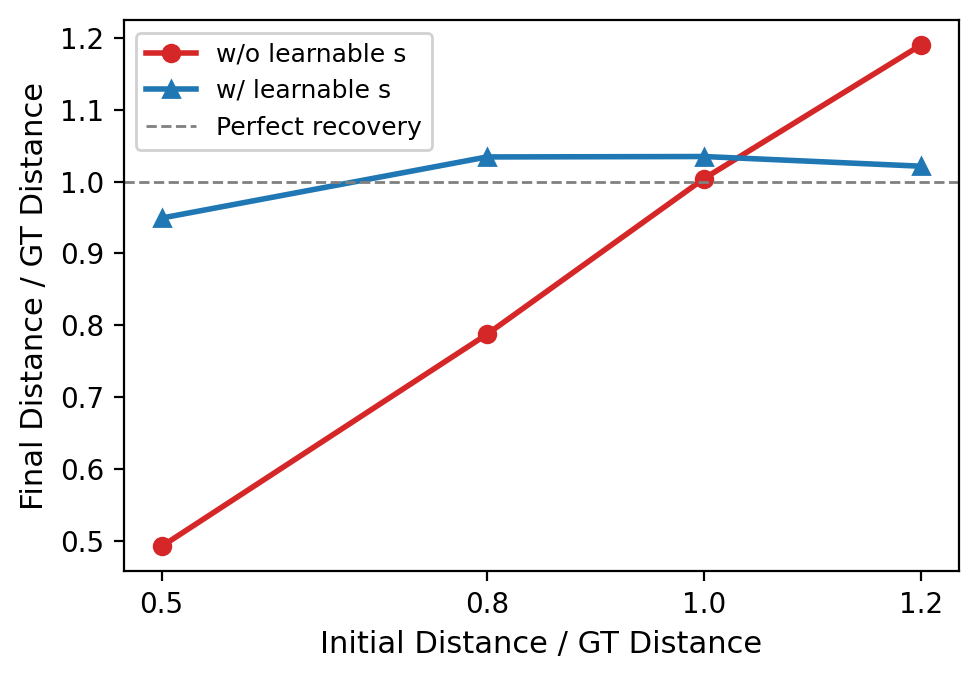
Fig 2: Effect of the learnable scale factor s

Fig 3: Qualitative comparison on Vid2Sim dataset. We compare the rendered image trajectory

Fig 4: Qualitative comparison on our synthetic dataset. We compare the rendered image

Fig 5: Per-region geometric error before (top

Fig 6: Effect of the differentiable position map. The per-Gaussian position gradient −∂Lsil/∂xi

Fig 7 (page 8).

Fig 8 (page 8).
Limitations
- Geometry refinement improves but does not completely eliminate inaccuracies, especially in visually or physically ambiguous regions.
- The method requires known camera intrinsics and extrinsics as well as a known ground plane, limiting applicability to fully unconstrained in-the-wild videos.
- The approach currently assumes known constitutive physical model types (e.g., Neo-Hookean elasticity) and requires foreground alpha masks, which may not always be available or accurate.
- No explicit adversarial or robustness evaluation is conducted; performance under substantial occlusions or noisy segmentation is unclear.
- The synthetic dataset may not capture the full diversity or complexity of real-world deformable objects and physical interactions.
Open questions / follow-ons
- How to relax dependence on known camera parameters and ground plane for fully unconstrained monocular videos?
- Can the approach generalize beyond predefined constitutive models to learn arbitrary physical behaviors from monocular videos?
- How robust is the method to noisy or missing foreground segmentation masks, and can mask estimation be integrated jointly?
- Can the proposed framework be extended to handle non-rigid objects with complex appearance changes or occlusions in real-world in-the-wild videos?
Why it matters for bot defense
For bot-defense engineers and CAPTCHA practitioners focusing on physical interaction verification or challenge design involving deformable objects, MonoPhysics provides a significant advancement toward reconstructing and validating physical object parameters from monocular video alone. Such capability could enable deployment of physical CAPTCHA challenges requiring understanding of 3D geometry and material properties from a single camera, reducing hardware complexity compared to multi-view setups. The differentiable coupling of visual and physics signals along with scale disambiguation insights informs methods for linking observed appearance changes to underlying physical behavior. However, practical deployment should note current reliance on ground plane knowledge and accurate segmentation, and the method's sensitivity to scale and geometry estimation errors that might affect robustness against spoofing or adversarial manipulations. Overall, this research expands the technical foundation around monocular physical state estimation relevant to developing novel bot defenses grounded in physical simulation fidelity.
Cite
@article{arxiv2605_30320,
title={ MonoPhysics: Estimating Geometry, Appearance, and Physical Parameters from Monocular Videos },
author={ Daniel Rho and Jun Myeong Choi and Matthew Thornton and Biswadip Dey and Roni Sengupta },
journal={arXiv preprint arXiv:2605.30320},
year={ 2026 },
url={https://arxiv.org/abs/2605.30320}
}