
LoMo: Local Modality Substitution for Deeper Vision-Language Fusion
Source: arXiv:2605.30265 · Published 2026-05-28 · By Feng Han, Zhixiong Zhang, Zheming Liang, Yibin Wang, Jiaqi Wang
TL;DR
This paper addresses a critical limitation in current Vision-Language Models (VLMs) termed “carrier sensitivity,” where model performance degrades substantially when semantically equivalent content is presented via different modalities (e.g., text question vs. rendered-image question). The authors identify this problem as stemming from the inherent modality bias in prevalent image-text corpora, where text and images often serve asymmetric roles (text as queries, images as references). This leads VLMs to poorly align representations across different modality carriers, making them fragile to modality substitution.
To mitigate this, the authors propose Local Modality Substitution (LoMo), a data-centric training paradigm that reformulates single-modality textual inputs into interleaved text–image–text sequences by rendering selected semantically coherent text spans (e.g., formulas or key phrases) as images. Perceptual distortions simulate real-world visual noise on these images. This implicitly teaches the model cross-modal representational invariance during standard supervised fine-tuning without architectural changes or inference cost. Extensive experiments on 13 diverse multimodal benchmarks demonstrate consistent accuracy gains (+2.67/+2.82 points on LLaVA-OneVision-1.5-8B and Qwen3.5-9B) and substantially improved representation alignment metrics, addressing the carrier sensitivity problem.
LoMo thus provides a lightweight, compatible, and effective data augmentation technique for deeper vision-language fusion, strengthening semantic alignment between visual and textual information streams and enhancing model robustness under modality substitutions.
Key findings
- Rendering semantically equivalent text questions as images causes accuracy drops up to -11.68 points on LLaVA-OV1.5-8B across 5 VLMs (Fig 1a).
- Pairwise cross-modal distance between text and rendered images correlates with accuracy degradation, with the largest distance bin showing 21.23% accuracy drop (Fig 1b).
- LoMo reduces average pairwise cross-modal representation distance by 14.2% compared to standard supervised fine-tuning (Fig 1c).
- LoMo outperforms standard SFT by +2.68 points average on 13 benchmarks using LLaVA-OneVision-1.5-8B and +2.82 points using Qwen3.5-9B (Fig 3, Table 1).
- Under challenging rendered evaluation (text replaced by rendered image input), LoMo boosts average accuracy by +18.86 (LLaVA) and +11.92 (Qwen3.5) over standard SFT, improving robustness to modality substitution (Table 1).
- LoMo yields statistically consistent improvements across reasoning, math, factuality, instruction, document/OCR, and visual perception tasks, with an accuracy gain in 23 of 26 comparisons (Table 1).
- Component ablation shows structure-aware span localization contributes most to gains (+2.22 vs +1.19 for naïve full-text rendering), and perceptual distortion adds an additional +0.46 gain (Table 2).
- LoMo reduces the Modality Integration Rate (MIR) by 0.122 and the pairwise cross-modal distance by 0.08 at 4M training scale relative to standard SFT, indicating deeper cross-modal fusion (Fig 4).
Threat model
The adversary considered is an entity that can supply input queries or prompts semantically equivalent to original text but realized in alternate modalities, such as rendered images of the text (text-as-pixels). Their goal is to degrade VLM reasoning performance or induce errors via carrier substitution. They cannot modify ground-truth answers or internal model parameters. The threat is the model’s sensitivity to input carrier modality mismatch, not direct white-box or adversarial attacks.
Methodology — deep read
Threat model & assumptions: The implicit threat addressed here is the fragility of VLMs to modality carrier substitution, where an adversarial or accidental change in input format (text questions replaced by images of the questions) can cause substantial reasoning performance degradation. The authors assume that the adversary can supply semantically equivalent content in different modalities, but cannot change ground truth answers. The focus is on fixing the model's internal representational alignment rather than adversarial robustness per se.
Data: Training samples come from a large multimodal corpus derived from the official LLaVA-OneVision1.5 SFT dataset, with 2 million multimodal instruction examples and 2 million text-only instruction examples. LoMo uses the same data pool but reformats some fraction of text-only examples into interleaved text-image-text by substituting selected spans. Evaluation is done on 13 public benchmarks covering a broad range of multimodal reasoning tasks, including MMMU, MathVista, DocVQA, etc., all with standard question-answer pairs and images.
Architecture/algorithm: LoMo is a data curation method applied during standard supervised fine-tuning (SFT) without modifying model architecture or loss. It transforms a text-only input x as follows: (a) Structure-Aware Span Localization splits x into three parts (x_pre, x_mid, x_suf), selecting the middle semantically coherent span for substitution. This uses formula-aware chunking preserving atomic units (e.g., LaTeX math expressions).
(b) Visual Rendering converts x_mid into a rendered image using a pipeline that routes to LaTeX rendering if math is present or to text rendering otherwise, with a fallback if rendering fails.
(c) Perceptual Distortion applies randomized, semantics-preserving visual noise such as rotation, blur, shadows, or geometric waves to simulate real-world degradations in image capture.
The final reassembled input is (x_pre, I', x_suf), a seamless text–image–text sequence forcing joint cross-modal fusion.
Training regime: LoMo fine-tunes VLM backbones LLaVA-OneVision1.5-8B and Qwen3.5-9B. The only difference from standard SFT is that a predefined fraction (e.g., 50%) of text-only samples undergo modality substitution. Optimization hyperparameters, learning rate, batch size, training steps, and hardware match standard SFT. Multiple data scales (1M-4M samples) are tested.
Evaluation protocol: Models are evaluated on 13 benchmarks under two input protocols: Standard (original text + image) and Rendered (text question replaced entirely by rendered image). Accuracy on question answering and reasoning tasks is reported. Additionally, cross-modal alignment metrics are introduced:
- Modality Integration Rate (MIR): measures distributional gap between visual and textual token embeddings using Fréchet Distance.
- Pairwise Cross-Modal Distance: cosine distance between hidden states of paired text tokens and rendered image tokens per sample. LoMo's gains are confirmed across these metrics and data scales.
Reproducibility: Code, models, and detailed hyperparameters are referenced as released in the appendix and linked project webpage (https://maplebb.github.io/LoMo). The training data is publicly derived from existing LLaVA datasets. Rendering pipelines and augmentation code are also described in detail. Still, exact random seeds and training environment details are not fully enumerated.
Concrete End-to-End Example: A math instruction question containing LaTeX formulas is processed by LoMo as follows: the question text is segmented at formula boundaries, the middle text/formula span is rendered into an image with LaTeX renderer, noise is applied simulating capture distortions, then the image is inserted into the text, forming a text-image-text input. The VLM must jointly attend to both text tokens and the embedded image to predict the correct answer, implicitly forcing alignment of semantic representations across the modalities through standard likelihood loss.
Technical innovations
- Identification and systematic diagnosis of the carrier sensitivity problem in VLMs caused by modality-specific data bias leading to misaligned cross-modal representations.
- Introduction of Local Modality Substitution (LoMo), a data-centric training paradigm that dynamically replaces local semantically coherent text spans with their rendered-image counterparts within single training instances, preserving semantic supervision.
- Development of a lightweight, content-aware rendering pipeline that distinguishes math vs non-math spans for accurate modality substitution, combined with perceptual distortion augmentations to enhance robustness to real-world visual noise.
- Establishment of an implicit cross-modal alignment supervision signal through the standard SFT objective by interleaving text-visual-text inputs, requiring models to fuse modalities tightly without architectural changes or additional inference cost.
Datasets
- LLaVA-OneVision1.5 SFT corpus — approximately 4 million examples (2M multimodal + 2M text-only) — public dataset from LLaVA training releases
- MMMU, MMMU-Pro, MathVista, ZeroBench, WeMath, SimpleVQA, HallusionBench, MM-IF Eval, MMLongBench-Doc, DocVQA, CC-OCR, V*, CountBench — collectively 13 multimodal benchmarks for evaluation — publicly available (varies by benchmark)
Baselines vs proposed
- Standard SFT baseline (LLaVA-OneVision-1.5-8B): average accuracy = 40.88%; LoMo: 43.56% (+2.68)
- Standard SFT baseline (Qwen3.5-9B): average accuracy = 54.43%; LoMo: 57.25% (+2.82)
- Under Rendered Evaluation, LLaVA-OneVision-1.5-8B: Standard SFT average = 15.24%; LoMo = 34.10% (+18.86)
- Under Rendered Evaluation, Qwen3.5-9B: Standard SFT average = 43.26%; LoMo = 55.18% (+11.92)
- Full-Text Rendering baseline (render entire input as image) yields +1.19 improvement over Standard SFT; LoMo w/o Perceptual Distortion yields +2.22; full LoMo yields +2.68 (Table 2).
- LoMo reduces Modality Integration Rate (MIR) by 0.122 and pairwise cross-modal distance by 0.08 compared to Standard SFT at 4M training scale (Fig 4).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.30265.
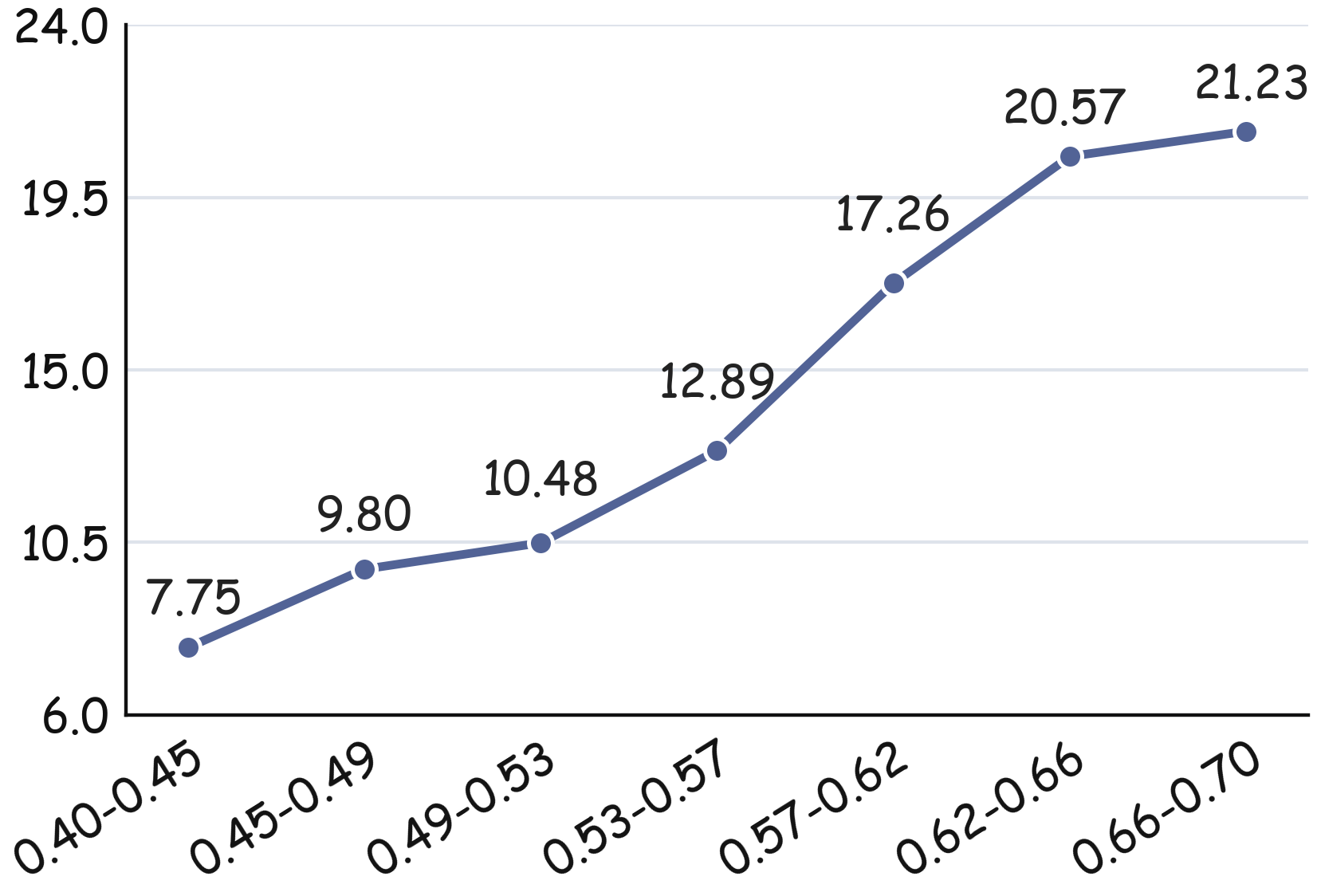
Fig 1: Current Vision-Language Models exhibit carrier sensitivity driven by an underlying
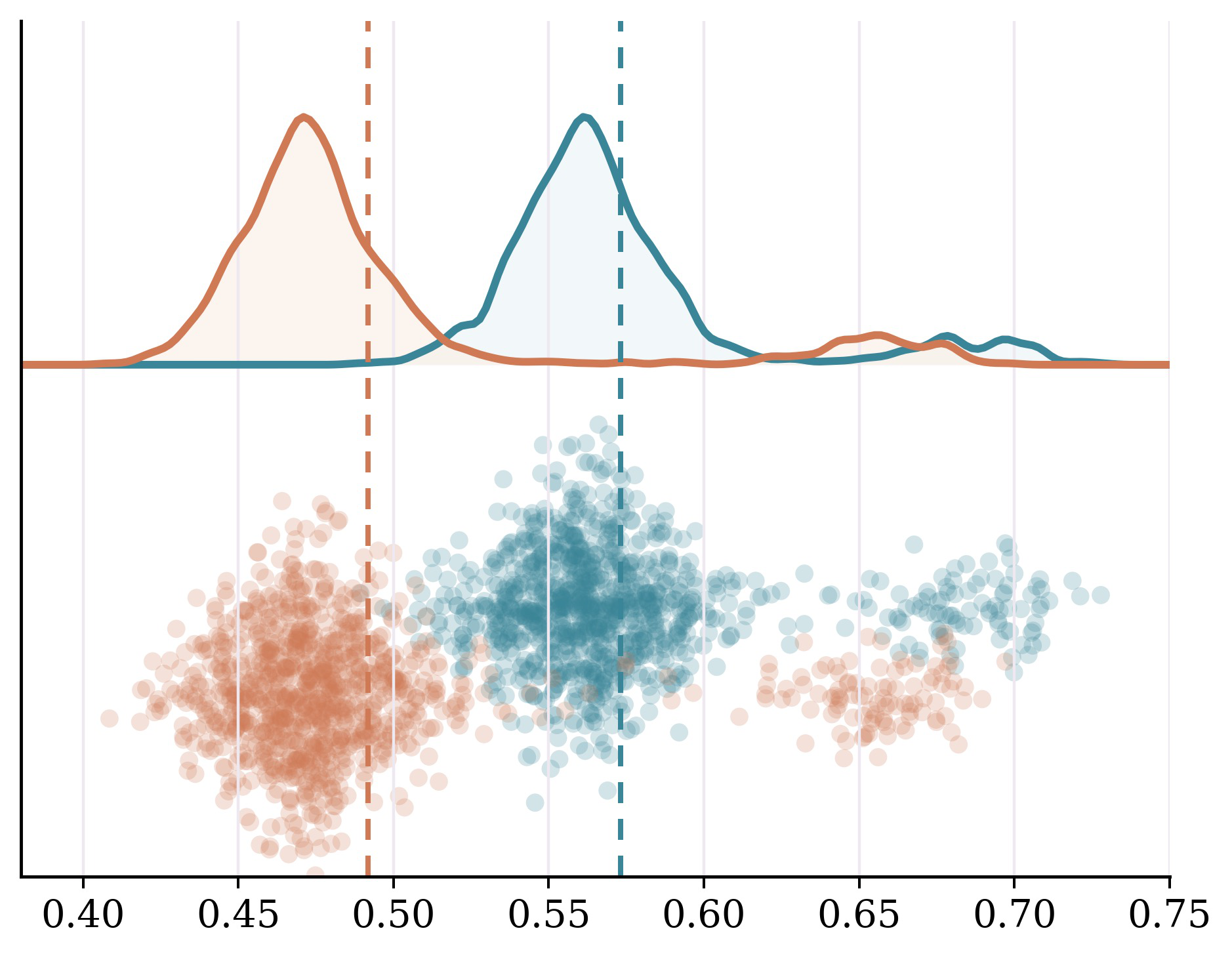
Fig 2: Overview of LoMo. LoMo reformulates a text-only instance into a text–image interleaved

Fig 3: LoMo yields consistent improvements over Standard SFT across two backbones ((a) +2.68

Fig 4 (page 3).

Fig 5 (page 3).

Fig 6 (page 3).

Fig 7 (page 3).

Fig 8 (page 3).
Limitations
- The method requires rendering text spans into images, which may introduce some computational overhead during training, though none at inference.
- While LoMo uses perceptual distortions to simulate real-world noise, it may not capture all possible visual variations or adversarial manipulations of rendered text images.
- Evaluation focuses on open-domain and academic benchmarks; performance and robustness in fully deployed, large-scale web or production multi-modal settings remains untested.
- The approach relies on a semantically coherent span localization heuristic which may occasionally mis-select inappropriate text spans, affecting quality of substitution.
- There is limited analysis of LoMo’s impact on model calibration, hallucination tendencies, or effects on downstream tasks outside the tested benchmarks.
- The study assumes alignment issues stem primarily from data modality bias, without fully exploring whether architectural adjustments could further improve cross-modal fusion.
Open questions / follow-ons
- Can architectural innovations complement or further enhance the cross-modal alignment gains provided by LoMo's data-centric approach?
- How does LoMo-like local modality substitution impact other VLM capabilities such as grounded generation, multimodal explanation, or hallucination reduction?
- Can this modality substitution approach be extended beyond text-to-image rendering to other cross-modal pairs (e.g., audio, video) for broader fusion improvements?
- What are the limits of perceptual distortion realism and diversity needed to maximize robustness without degrading semantic supervision quality?
Why it matters for bot defense
Bot-defense and CAPTCHA systems increasingly rely on vision-language models to understand and interpret content combining images and text. LoMo’s findings highlight a critical vulnerability: that models can perform inconsistently when input semantics shift modality carriers (e.g., text questions vs images of the same questions). For CAPTCHA designers, this exposes risk that adversaries might bypass protections by switching carriers or presenting text visually rather than as tokens.
Applying LoMo’s local modality substitution method during model training could help produce VLMs with more robust, modality-invariant representations, preserving accuracy regardless of carrier shifts. This would reduce false negatives in bot-detection scenarios where input formats vary or are adversarially manipulated. Moreover, LoMo’s lightweight and architecture-agnostic nature make it a practical augmentation for enhancing existing bot detection or CAPTCHA-understanding models without complex redesigns. However, practitioners should note LoMo’s reliance on accurate span detection and perceptual distortions to simulate real-world conditions, suggesting careful design around CAPTCHA content rendering and noise simulation to maximize benefit.
Cite
@article{arxiv2605_30265,
title={ LoMo: Local Modality Substitution for Deeper Vision-Language Fusion },
author={ Feng Han and Zhixiong Zhang and Zheming Liang and Yibin Wang and Jiaqi Wang },
journal={arXiv preprint arXiv:2605.30265},
year={ 2026 },
url={https://arxiv.org/abs/2605.30265}
}