
LLMSurgeon: Diagnosing Data Mixture of Large Language Models
Source: arXiv:2605.30348 · Published 2026-05-28 · By Yaxin Luo, Jiacheng Cui, Xiaohan Zhao, Xinyi Shang, Jiacheng Liu, Xinyue Bi et al.
TL;DR
This paper introduces the problem of Data Mixture Surgery (DMS), which aims to infer the domain-level composition of a large language model's (LLM) pretraining corpus solely from the model's generated text outputs. Existing membership inference attacks work at the instance level and cannot reliably characterize global data mixture. To solve this, LLMSurgeon frames DMS as a label-shift inverse problem, calibrating domain classification outputs with a learned soft confusion matrix to correct domain confusion and recover the latent data mixture prior. The authors also present LLMScan, a benchmark suite comprising open-source LLMs with known, transparent pretraining data mixtures for evaluation under three granularity levels (coarse, mid, fine). Empirical results show LLMSurgeon significantly outperforms baseline aggregate heuristics, achieving overlap accuracies over 90% on general-purpose models and maintaining robustness across scales and granularity. Ablations confirm the importance of calibrated inverse correction, neutral prompt sampling, and classifier selection. Controlled experiments further demonstrate generalization to held-out model checkpoints and utility for detecting injected toxic data proportions, validating LLMSurgeon as a practical post-hoc auditing tool for LLM training data provenance without requiring access to training datasets or model internals.
Key findings
- LLMSurgeon achieves 94.46% and 95.14% domain mixture overlap accuracy on OLMo-1B and LLaMA1-7B respectively under coarse-grained taxonomy, vastly outperforming adapted membership inference baselines capped near 50% (Table 2).
- Inverse correction via calibrated soft confusion matrix improves overlap accuracy by up to 15% relative on fine-grained tasks compared to direct aggregation of classifier outputs (Table 6a).
- Fine-tuned DistilBERT proxy classifiers outperform other backbones with up to 4.92% absolute gain in overlap accuracy (Table 3).
- LLMSurgeon remains robust across model scale, showing stable performance from 1B to 65B parameters and retains >60% accuracy in mid- and fine-grained granularities despite semantic overlap challenges (Table 2 & Fig 3).
- Neutral prompt sampling is critical to minimize stylistic bias and preserve the latent domain prior, yielding the highest and most stable mixture recovery performance compared to instructional, coding, or expository styles (Table 5).
- Performance saturates at about 5,000 labeled reference samples per domain for classifier training; more samples do not improve or can slightly degrade performance (Table 4).
- LLMSurgeon generalizes to unseen mixtures and held-out model checkpoints, maintaining 86.41% overlap accuracy on OLMo-3 without retuning from earlier checkpoints (Table 7).
- Controlled toxic injection experiments show monotonic recovery of toxic data proportion with >97% accuracy, suggesting practical utility for safety auditing triage (Table 9).
Threat model
An adversary with black-box query access to a target LLM attempts to infer the relative proportions of semantic domains in the model's pretraining corpus. The adversary cannot access model parameters, training data, or internal representations. They assume the target LLM generates text according to a latent mixture prior over known domain categories and that conditional domain-specific language distributions remain approximately fixed (label-shift assumption). Adversary relies solely on generated text samples prompted neutrally and a proxy external classifier trained on labeled reference data.
Methodology — deep read
The authors frame Data Mixture Surgery (DMS) as the problem of estimating the latent pretraining domain distribution π from generated text samples of the target LLM. Under the label-shift assumption, the conditional distribution of text given a domain remains invariant between training and generation, though the prior mixture proportions shift.
Threat Model and Assumptions: The adversary only has black-box query access to the target LLM and obtains generated outputs triggered by neutral prompts. The adversary knows a predefined taxonomy of K disjoint semantic domains that cover the pretraining data. No access to model internals, weights, or training data is assumed. The label-shift assumption presumes fixed conditional distributions p(x|y) and changes only in prior π. Model can generate text reflecting its effective internal domain mixture.
Data and Reference Sets: External proxy domain classifiers are trained on reference datasets with known domain labels (Dref). These datasets vary by granularity: SlimPajama-627B-DC for coarse (6 domains), The Pile for mid (17 domains), and The Stack for fine (87 domains). Typically 5,000 samples per domain are used for training. The benchmark LLMScan uses 8 open-source LLMs with fully transparent pretraining mixtures obtained from published reports to provide ground-truth domain proportions α for evaluation.
Architecture and Algorithm: A proxy classifier f_ϕ maps input text x to a soft probabilistic domain prediction vector in Δ_K-1. DistilBERT fine-tuned for domain classification is chosen as default backbone for best performance. The classifier is imperfect; a soft confusion matrix C is estimated on validation data as C_ij = E_{x~p_i}[f_ϕ(x)_j], encoding the probability that a sample truly from domain i is predicted as j.
When sampling the target LLM with neutral prompts, generated samples X_gen are classified by f_ϕ and averaged to produce an observed distribution p¯ = (1/N) ∑ f_ϕ(x_n). The relationship p¯ ≈ C^T π holds by linearity. The latent prior π is recovered by solving a constrained quadratic program minimizing ||C^T π - p¯||^2 with sum-to-one and nonnegativity constraints, effectively inverting the calibrated confusion to correct systematic bias.
Training Regime: Proxy classifiers are trained on the respective reference domain datasets. Classifier hyperparameters, epochs, batch sizes, and seeds are mentioned but specifics not fully enumerated; fine-tuning DistilBERT is prioritized. LLM samplings are done with neutral prompt templates to minimize generation distribution distortion. Evaluation uses fixed prompt templates and sampling temperatures.
Evaluation Protocol: Overlap accuracy (1 - 0.5 Σ |α_k - π̂_k|), mean absolute error (MAE), and coefficient of determination (R^2) are used. Benchmarks compare adapted membership inference attack heuristics, dataset-level estimators (DUCI), and a direct aggregation baseline (no inverse correction). Cross-model and cross-granularity evaluation on LLMScan dataset suite is conducted. Held-out generalization to unseen mixtures and model checkpoints is tested via OLMo-3 and a GPT-2 sandbox. Statistical correlations link classifier accuracy with DMS accuracy.
Reproducibility: Code and data for LLMSurgeon and LLMScan are released to enable replication. Models and reference datasets are all open-source or publicly documented, supporting end-to-end verification. Hyperparameters for the inverse solver and classifier training are partially detailed. The evaluation methodology is fully described.
Concrete example: For LLaMA-1 7B model in coarse-grained (6 domain) setting, a proxy DistilBERT classifier is fine-tuned on 5,000 docs per domain from SlimPajama-627B-DC. Generated samples under neutral prompts are classified, averaged, then the known confusion matrix C is used to solve the inverse problem for π̂. The recovered mixture π̂ matches official documented α with 95.14% overlap accuracy, demonstrating high-fidelity data mixture estimation.
Technical innovations
- Formalization of Data Mixture Surgery (DMS) as an inverse problem under the label-shift assumption to recover latent domain priors from generated text alone.
- Introduction of LLMSurgeon framework that estimates a soft confusion matrix for proxy classifier systematic bias and performs constrained inverse correction rather than naive aggregation.
- Construction of LLMScan benchmark covering multiple domain granularities with open-source LLMs having transparent training data mixtures for verifiable evaluation.
- Demonstration that neutral prompt sampling mitigates stylistic distributional shifts, preserving the latent domain prior for accurate post-hoc auditing.
Datasets
- SlimPajama-627B-DC — ~30k samples per coarse domain (6 domains) — open-source reference corpus
- The Pile (Gao et al., 2020) — 17 domains — public diverse text dataset
- The Stack (Kocetkov et al., 2022) — 87 programming languages — open-source code dataset
- LLMScan Benchmark — 8 open-source LLMs (1B to 65B parameters) with documented training corpora
Baselines vs proposed
- Neighbor (Mattern et al., 2023): overlap accuracy ≈ 41.74% vs LLMSurgeon: 94.46% on OLMo-1B (coarse)
- Recall (Xie et al., 2024): overlap ≈ 48.05% vs LLMSurgeon: 94.46% on OLMo-1B (coarse)
- Direct estimation (no inverse correction): 93.42% vs LLMSurgeon: 95.14% on LLaMA1-7B (coarse)
- GradNorm (Wang et al., 2024): 27.54% vs LLMSurgeon: 30.37% on StarCoder-15.5B (fine)
- MIA Joint-Logit (Carlini et al., 2022): 35.20% vs LLMSurgeon: 94.46% on OLMo-1B (coarse)
- Dual setting: GPT-2 balanced overlap 75.62% vs Book-heavy 50.15%, demonstrating robustness variability.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.30348.

Fig 1: Overview of Data Mixture Surgery problem

Fig 2: Overview of our proposed LLMSurgeon framework to address the Data Mixture Surgery problem.

Fig 3 (page 1).
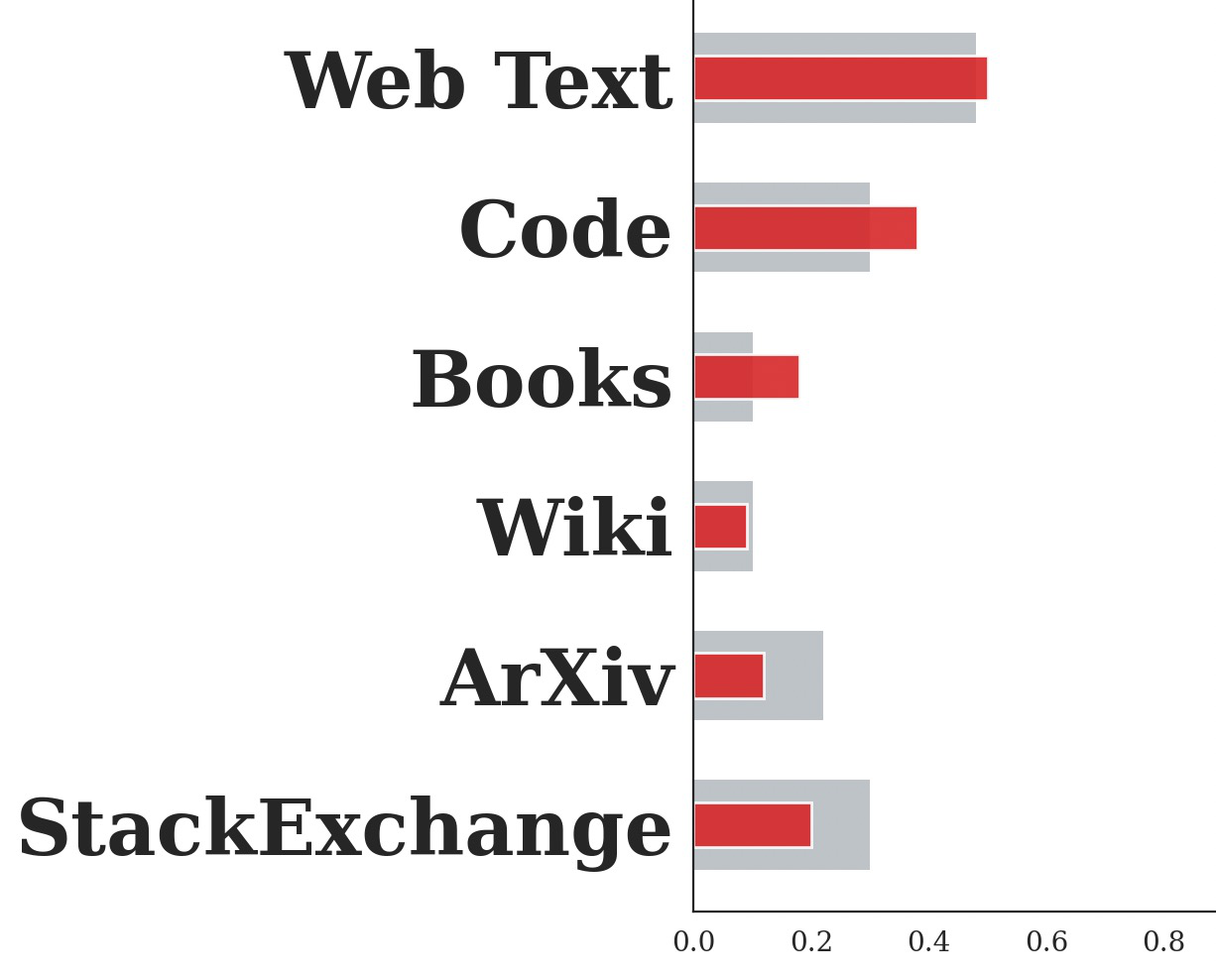
Fig 4 (page 1).

Fig 5 (page 1).

Fig 6 (page 2).

Fig 7 (page 2).
Fig 8 (page 2).
Limitations
- The method relies on a predefined set of disjoint semantic domains; performance degrades if real domains overlap semantically (e.g., C4 and Common Crawl) necessitating domain merging.
- Fine-grained recovery accuracy suffers dramatically (≈30%) due to high semantic similarity and an ill-conditioned inverse problem among closely related domains (e.g., programming languages).
- Label-shift assumption may not hold perfectly in presence of prompt-engineering or alignment interventions affecting conditional language distributions.
- Robustness limited on domain-specialized models with strongly biased generation styles where neutral prompt sampling is less effective.
- The approach requires building and tuning domain classifiers with sufficient labeled reference data, which may limit applicability to novel or proprietary domain taxonomies.
- Evaluation focuses on open-source LLMs with transparent data; closed-source models' unknown training strategies may introduce unknown confounds.
Open questions / follow-ons
- How does LLMSurgeon perform under adversarially manipulated or targeted prompt attacks designed to distort generation distributions?
- Can the framework be extended to handle overlapping or hierarchical domain taxonomies rather than strictly disjoint categories?
- What are the robustness and applicability limits when auditing closed-source commercial LLMs with opaque or proprietary data recipes?
- Could incorporating higher-order features or learned domain embeddings improve fine-grained domain separability beyond linear inverse corrections?
Why it matters for bot defense
For bot-defense and CAPTCHA engineering, understanding the training data composition of foundation models underlying adversarial bots can aid in forensic attribution, detecting data leakage or bias, and tailoring defenses sensitive to domain-specific model behaviors. LLMSurgeon provides a practical, post-hoc auditing tool that does not require access to proprietary training data or model internals, making it valuable for reverse-engineering the "digital DNA" of black-box language models powering bots. Its calibrated inverse approach mitigates biases in naive membership inference aggregation, yielding more reliable estimates of domain knowledge distribution, which could help predict model failure modes or robustness in bot interactions. Neutral prompt sampling as a best practice highlights the importance of careful query design when probing adversarial models. However, domain granularity and semantic overlap limit fine-grained auditing, suggesting that bot-defense practitioners should focus on coarser domain-level signals for reliable insights. Overall, LLMSurgeon advances transparency and accountability for foundation models vital to understanding and mitigating bot risks.
Cite
@article{arxiv2605_30348,
title={ LLMSurgeon: Diagnosing Data Mixture of Large Language Models },
author={ Yaxin Luo and Jiacheng Cui and Xiaohan Zhao and Xinyi Shang and Jiacheng Liu and Xinyue Bi and Zhaoyi Li and Zhiqiang Shen },
journal={arXiv preprint arXiv:2605.30348},
year={ 2026 },
url={https://arxiv.org/abs/2605.30348}
}