
K-FinHallu: A Hallucination Detection Benchmark for Multi-Turn RAG in Korean Finance
Source: arXiv:2605.29523 · Published 2026-05-28 · By Eunbyeol Cho, Yunseung Lee, Mirae Kim, Jeewon Yang, Youngjun Kwak, Edward Choi
TL;DR
K-FinHallu addresses a significant gap in reliable hallucination detection for Retrieval-Augmented Generation (RAG) systems operating in high-stakes multi-turn financial dialogues in Korean. Existing benchmarks largely focus on single-turn, English-centric tasks and do not capture the complex dialogue dynamics, regulatory context, and linguistic features unique to the Korean financial domain. This benchmark introduces a hierarchical hallucination taxonomy based on context answerability, explicitly modeling justified abstention (refusal) and several subtle hallucination types relevant to multi-turn RAG.
The authors build K-FinHallu from authentic Korean financial documents and design an automated pipeline that simulates faithful multi-turn dialogues with user and assistant LLM roles, followed by targeted hallucination injection informed by real-world failure patterns. Extensive evaluation across closed-source, open-source, and Korean-centric LLMs reveals broad struggles in fine-grained hallucination diagnostics and refusal behaviors despite reasonable binary detection performance. Fine-tuning a moderately sized open-source model with rationale supervision substantially closes the gap with frontier closed-source models, though refusal detection remains the hardest challenge overall.
Key findings
- K-FinHallu consists of 808 test samples with balanced 404 faithful and 404 hallucinated dialogues, each averaging 3.72 turns, and 11.4% unanswerable scenarios requiring justified abstention.
- Among off-the-shelf models, Gemini-2.5-Flash achieves top binary hallucination detection with F1=0.860, followed by Gemini-2.5-Pro at 0.849 and GPT-5 at 0.823 (Table 3).
- Fine-tuning Qwen3-8B with rationale supervision improves four-class classification accuracy from 0.688 to 0.896 overall, surpassing GPT-5 and Gemini baselines (Table 4).
- Refusal detection (distinguishing false vs true refusal) is the weakest axis across all models, with base models below 0.50 accuracy and fine-tuned models achieving only 0.750 (Table 4).
- Contradictory hallucinations, the most common type (39.1%), decompose into four subtypes where financial term misunderstanding remains high error (>70%) even at the largest Qwen3-32B scale (Figure 5).
- Multi-class hallucination type diagnosis shows a clear scaling improvement in the Qwen3 family (macro-F1 improving from 0.387 to 0.492 between 8B and 32B), but GPT-5 and Korean-centric models struggle to disentangle hallucination categories (Table 9).
- Cross-source hallucination injections from GPT-4o and Gemini-2.5-Flash induce complementary difficulty patterns, with Gemini-2.5-Flash generating harder-to-detect irrelevance hallucinations, validating source diversity (Table 11).
- The pipeline’s LLM-in-the-loop quality control achieves strong human agreement (Gwet’s AC1 > 0.7 across dialogue and injected hallucination quality dimensions) verifying dataset reliability (Table 1).
Threat model
The adversary is an automated LLM-based financial RAG system that may generate intrinsically hallucinated (unfaithful) responses during multi-turn dialogue. The adversary has no control over the retrieval documents, which are assumed to be trusted ground truth. The system is expected to discern hallucinated outputs and refuse to answer when evidence is insufficient, ensuring compliance and factual accuracy in high-stakes Korean financial interactions.
Methodology — deep read
The paper’s threat model assumes an adversary that can deploy or exploit LLM-based RAG systems in Korean financial multi-turn dialogues but cannot manipulate retrieval documents, as retrieval is simulated with controlled passage sets to isolate hallucination detection.
Data is derived from Korean Financial and Legal Document Machine Reading Comprehension dataset from AI-Hub, filtered for financial domains. The training split contains 2,732 documents and 42,364 queries from various institutions, while the test split uses disjoint institutions (Financial Supervisory Service and Korea Consumer Agency) with 272 documents and 2,064 queries to prevent leakage (Table 2).
The construction pipeline has two key phases: (1) Faithful dialogue generation using a user and assistant LLM (both GPT-4o). The user LLM generates coherent multi-turn questions referencing real passages, including reconfirmation turns to test context tracking. The assistant LLM generates responses strictly grounded on gold passages and clue spans.
(2) Hallucination injection systematically modifies faithful dialogues based on five hallucination types: Contradictory, Unverifiable, Irrelevance, False Refusal, and False Acceptance (Figure 2). Injection uses minimal edits of keywords, phrasing, numbers, or refusal behaviors, guided by domain experts and real failure patterns observed in deployed Korean financial RAG systems. Two models (GPT-4o, Gemini-2.5-Flash) generate hallucinations on the test split for artifact diversity; only GPT-4o is used for training split injection.
Passage retrieval contexts Pn are simulated with top-10 passages per turn, varying answerability by including gold passages or only semantically similar hard negatives to simulate unanswerable scenarios. The model’s task is to detect hallucination presence and type at every turn given dialogue history, current query, retrieved passages, and response.
Training uses LoRA fine-tuning of Qwen3-8B on 2,624 training samples with rationale supervision formulated as templated two-step classification reflecting the taxonomy: first judge answerability, then classify hallucination subtype. Evaluation metrics include accuracy, precision, recall, and F1 both for binary detection and multi-class hallucination classification.
The evaluation covers multiple LLM families: Korean-centric, open-source (Llama-3, Qwen3), and closed-source (GPT-4o, GPT-5, Gemini-2.5). Models are tested at zero temperature with no further tuning aside from Qwen3 fine-tuning. Human annotators and LLM-as-a-judge quality filters validate dataset quality with Gwet’s AC1 agreement statistics.
A concrete example workflow: For turn n, the user LLM selects/generates a question qn with coreference from document p, retrieval context Pn with gold or negative passages is formed, assistant LLM produces a faithful response an aligned with clue spans, then hallucination injection modifies an or Pn to create a hallucinated response for benchmarking detector models.
Reproducibility is supported by releasing K-FinHallu under CC-BY-NC 4.0 license with detailed data statistics and annotation protocols. Code release and frozen weights are not explicitly mentioned.
Technical innovations
- Hierarchical hallucination taxonomy tailored for multi-turn RAG dialogues in finance, explicitly modeling context answerability and justified abstention.
- Automated multi-turn faithful dialogue generation pipeline using dual LLM roles incorporating document-grounded question generation and context-dependent paraphrasing.
- Targeted hallucination injection pipeline inducing subtle financial hallucinations including numeral, terminology, and dialogue history contradictions, plus refusal failures.
- Use of dual-injection source models (GPT-4o, Gemini-2.5-Flash) to mitigate model-specific artifacts and diversify failure modes in evaluation.
- Fine-tuning with rationale supervision reflecting the taxonomy’s two-step reasoning, significantly improving multi-class hallucination detection accuracy.
Datasets
- Korean Financial and Legal Document Machine Reading Comprehension — 272 documents test / 2,732 train — AI-Hub public dataset
- K-FinHallu benchmark — 808 test dialogues, 2,624 train dialogues — constructed from above with injection
Baselines vs proposed
- Kanana-2-30b-a3b-instruct: binary detection F1 = 0.650 vs Qwen3-8B SFT-R fine-tuned 4-class detection accuracy = 0.896
- EXAONE-4.0-32B: binary detection F1 = 0.728 vs GPT-5 binary detection F1 = 0.823
- Llama 3.1-8B: binary detection F1 = 0.674 vs Llama 3.3-70B: 0.756
- Qwen3-8B: binary detection F1 = 0.655 vs Qwen3-32B: 0.732
- GPT-4o: binary detection F1 = 0.733 vs Gemini-2.5-Flash: 0.860
- Qwen3-8B SFT (fine-tuned): four-class overall accuracy = 0.822 vs base Qwen3-8B overall accuracy = 0.688
- Qwen3-8B SFT-R (with rationale): four-class overall accuracy = 0.896 vs GPT-5 base: 0.855
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.29523.

Fig 1: Example of a contradictory hallucination in
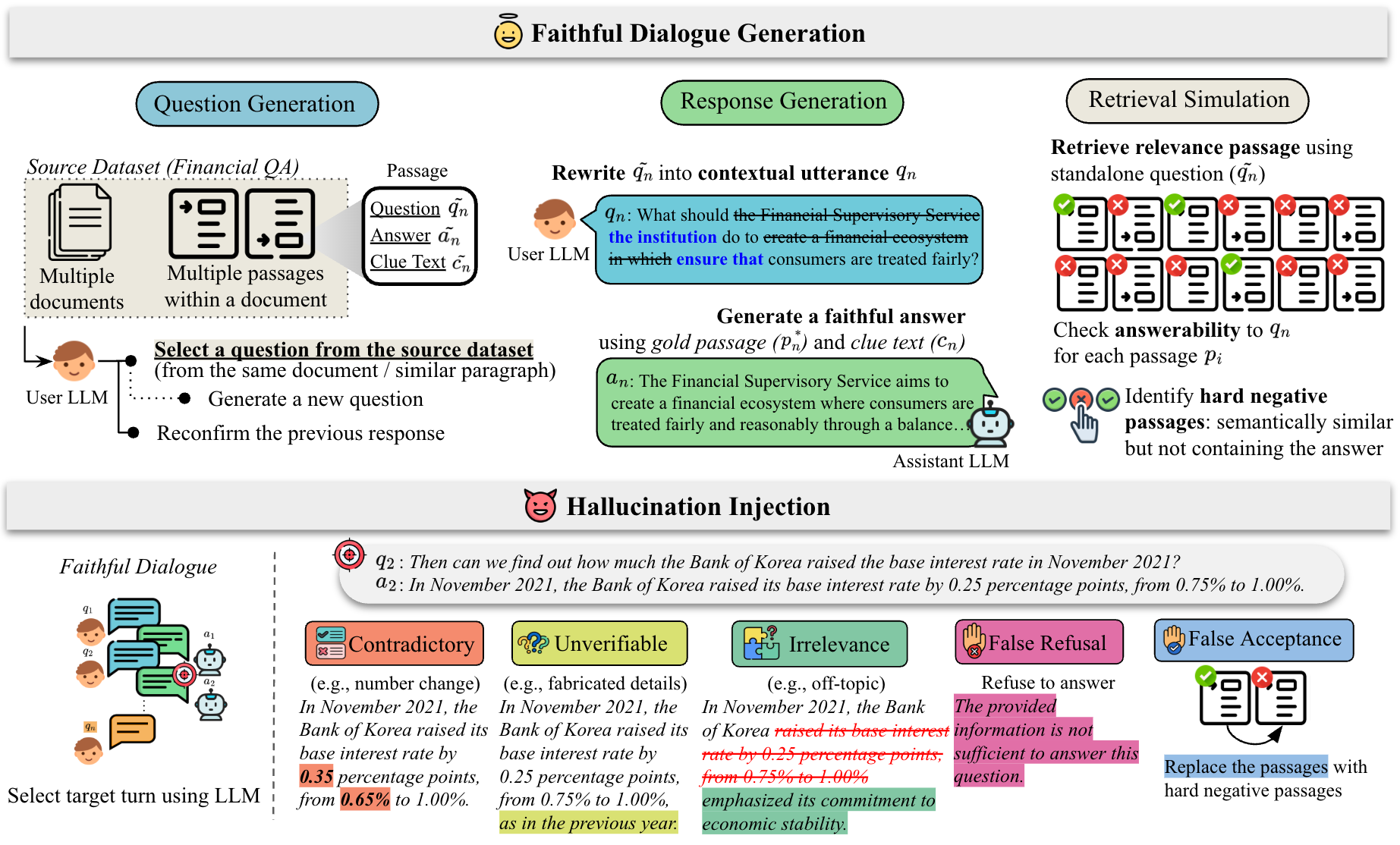
Fig 3: Overview of the K-FinHallu construction pipeline. We first generate faithful dialogues and then inject
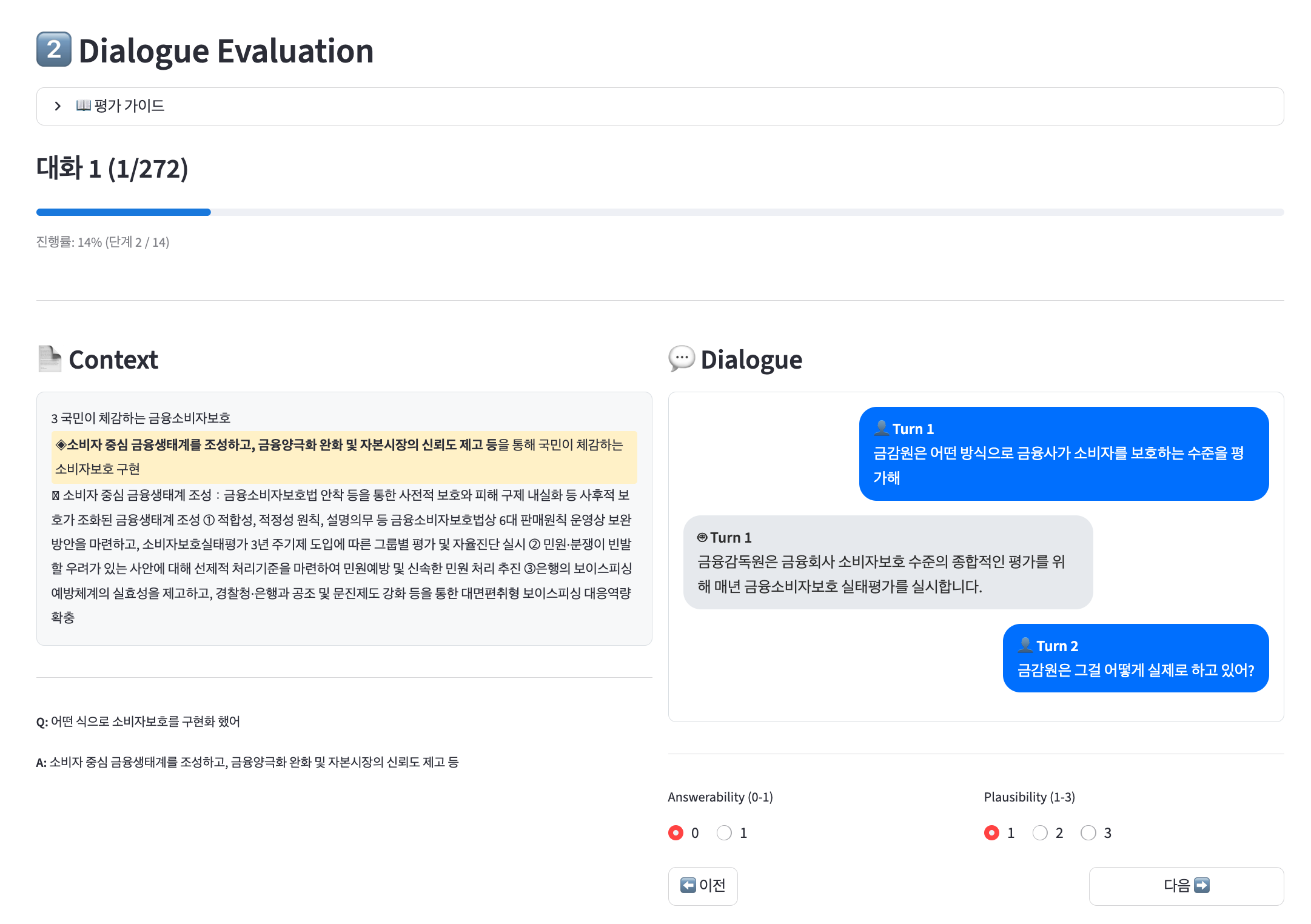
Fig 7: Screenshot of the annotation interface for dataset quality control.
Limitations
- K-FinHallu covers core Korean financial domains but may underrepresent niche or complex sub-sectors like derivatives or investment banking.
- Each dialogue contains only one hallucination to enable precise turn-level diagnosis, limiting realism regarding co-occurring or compounded hallucinations.
- Dialogues are generated via LLM simulation, potentially passing down generator-specific linguistic patterns or artifacts.
- Findings and terminology are grounded in Korean regulatory and market context, limiting direct transferability to other languages or jurisdictions.
- The benchmark does not evaluate adversarial or malicious model behaviors beyond detection, nor the integration with live retrieval engines.
- Refusal detection remains challenging with limited accuracy gains, suggesting limitations in current taxonomy or training data coverage.
Open questions / follow-ons
- How can hallucination detection models distinguish subtle semantic shifts in domain-specific jargon more effectively, especially for financial term misunderstandings?
- Can training data be expanded to support detection of co-occurring or compounded hallucinations spanning multiple turns?
- What are more effective methods for detecting and calibrating refusal behaviors (true vs false refusals) in multi-turn RAG?
- How transferable are the hierarchical taxonomy and detection approaches to other languages, financial regimes, or regulatory contexts?
Why it matters for bot defense
Bot-defense and CAPTCHA teams monitoring financial or high-value multi-turn conversational AI systems can apply K-FinHallu methods and taxonomies to benchmark and improve hallucination detection in domain-specific RAG settings. Particularly, the dataset highlights key failure modes such as justified abstention (refusal) which is critical in finance but often overlooked in general benchmarks. The hierarchical taxonomy provides a nuanced framework for flagging not just the presence but the underlying cause of hallucinations, helping design more transparent risk controls.
Moreover, adopting an injection-based benchmark created from authentic documents and multi-turn dialogue simulation offers a robust, controlled evaluation paradigm that can be adapted for bot-detection scenarios where multi-turn contextual consistency and domain-specific nuance matter. Fine-tuning smaller open-source LLMs with task-specific rationale supervision also suggests a viable path for deploying lightweight, interpretable hallucination detectors integrated within RAG pipelines in production environments.
Cite
@article{arxiv2605_29523,
title={ K-FinHallu: A Hallucination Detection Benchmark for Multi-Turn RAG in Korean Finance },
author={ Eunbyeol Cho and Yunseung Lee and Mirae Kim and Jeewon Yang and Youngjun Kwak and Edward Choi },
journal={arXiv preprint arXiv:2605.29523},
year={ 2026 },
url={https://arxiv.org/abs/2605.29523}
}