
Fairness-Aware Federated Learning with Trajectory Shapley Value
Source: arXiv:2605.30336 · Published 2026-05-28 · By Daniel Kuznetsov, Ziqi Wang
TL;DR
This paper addresses the challenge of fairly and robustly aggregating client updates in federated learning (FL) under data heterogeneity and adversarial participation. Traditional aggregation schemes use fixed or dataset-size-based weights that fail to capture the time-varying and unequal contributions of clients, leading to biased, unstable, or vulnerable global models. The authors propose the Trajectory Shapley Value (TSV), a novel contribution metric that evaluates client influence based on how their updates align with a validation-derived optimization trajectory rather than just static performance gains. Building on TSV, they present FedTSV, an adaptive-weighting aggregation algorithm that dynamically adjusts client weights round-by-round using Monte Carlo approximations of TSV, enabling robustness and fairness throughout training. Experimental results on MNIST and CIFAR-10 with a mixture of IID, non-IID, and malicious clients demonstrate that FedTSV converges faster, achieves higher global accuracy, and yields more coherent and robust client contribution estimates than existing baseline methods like FedAvg, CGSV, and Leave-One-Out. The approach effectively suppresses adversarial client influence while favoring reliable data providers, providing a practical, scalable framework for fairness-aware federated learning in heterogeneous environments.
Key findings
- FedTSV achieves higher global accuracy on CIFAR-10 (around 0.65) and MNIST (around 0.75) under heterogeneous and adversarial client settings compared to FedAvg (0.65 and 0.75, respectively) and adaptive baselines like CGSV and LOO, as shown in Figure 1.
- FedTSV yields more stable and consistent convergence with lower loss fluctuations on CIFAR-10 and MNIST than baselines, indicating robustness against noisy and malicious updates.
- The adaptive aggregation weights learned by FedTSV distinctly separate benign IID clients (high weights), benign non-IID clients (medium weights), and malicious clients (very low or zero weights), as visualized in Figure 2.
- TSV utility function bounds per-round client contributions in (0, 1], enabling efficient Monte Carlo approximation of Shapley values with controllable variance.
- Normalization factor σ_t in TSV computation mitigates numerical instability near stationary points, improving robustness of client contribution evaluation.
- FedTSV requires only one client training pass and one server-side validation pass per round, maintaining computational efficiency equivalent to standard FedAvg with adaptive weighting.
- The nonnegative truncation of cumulative contributions in FedTSV prevents adversarial clients from negatively influencing global aggregation at any round.
- CGSV baseline performs poorly under adversarial conditions due to overemphasis on large-norm updates, illustrating limitations of cosine-gradient similarity methods.
Threat model
The adversary is a subset of malicious (Byzantine) clients who have arbitrary control over their local training data and may submit arbitrarily corrupted model updates, e.g., via label shuffling attacks. They do not control the server or the held-out validation data but can otherwise attempt to poison the global model to degrade performance or manipulate client evaluations. The server is honest and uses validation-based evaluation to mitigate adversarial influence.
Methodology — deep read
Threat model and assumptions: The adversary is a set of malicious clients who possess independent local datasets but apply fixed label-shuffling mappings to poison training. These Byzantine clients can submit corrupted updates to degrade global model performance. The server does not access raw client data but can use a held-out validation dataset to guide aggregation. Adversaries do not control the server or validation data.
Data provenance and preprocessing: Experiments utilize MNIST and CIFAR-10 benchmarks with 100 simulated clients per dataset. Among these, 70 clients hold IID data partitions with equally distributed labels, 10 clients hold non-IID data created via Dirichlet distribution with concentration parameter 0.1 to produce heterogeneous label proportions, and 20 clients are malicious with corrupted labels by fixed shuffling. The held-out validation dataset D_0 resides on the server. Clients conduct local SGD on their private datasets.
Algorithm architecture: FedTSV uses a per-round contribution metric called the Trajectory Shapley Value (TSV), derived by comparing coalition-aggregated client updates to a server-side validation reference update over K local SGD steps, both initialized from the same global model parameter θ_t. The utility vt(S) = (1 + ||Δt_S - Δt_val||² / σ_t)^(-1) measures geometric closeness between coalition update Δt_S and validation update Δt_val, bounded between (0, 1]. Here, σ_t normalizes update magnitude to ensure scale invariance.
At each round, Monte Carlo sampling approximates the Shapley value ϕ_i(v_t) of each client i over all coalitions among selected clients S_t. These per-round contributions accumulate cumulatively as φ_{t+1}^i = φ_t^i + ϕ_i(v_t). Aggregation weights α_{t+1}^i = max(0, φ_{t+1}^i) truncate negative values to suppress adversaries. The server aggregates client updates weighted by α_{t+1}.
Training regime: For MNIST, a single-hidden-layer 64-unit neural network is trained using mini-batch SGD with batch size 64 and learning rate 0.001. For CIFAR-10, ResNet-20 architecture is used with batch size 8 and learning rate 0.0005. Each communication round samples 5 clients at random; each performs one local epoch (K=1). Training lasts for 400 (MNIST) and 1000 (CIFAR-10) rounds on an NVIDIA RTX 3080 GPU.
Evaluation protocol: Metrics include global test accuracy and loss, and the distribution of client aggregation weights. Baselines compared are FedAvg (uniform aggregation), CGSV (cosine-gradient Shapley similarity), and Leave-One-Out (LOO) marginal contribution. Stability, convergence speed, separation of benign vs malicious clients by learned weights, and robustness to adversarial clients are analyzed. No explicit statistical tests were reported. The held-out validation set is fixed and used throughout training.
Reproducibility: The paper does not specify code release or frozen weights. Datasets used are standard benchmarks (MNIST, CIFAR-10), and client data splits follow standardized procedures (Dirichlet for non-IID). Monte Carlo approximation of Shapley values follows [20]. Specific random seeds and hyperparameter tuning details are not fully documented.
Concrete example: At communication round t, the server sends model θ_t to selected clients. Each client performs K=1 local SGD step on its data and returns updated θ_{t+1}^i. The server computes validation update θ_{t+1}^0 by applying K=1 SGD steps on held-out validation data from θ_t. For any coalition S ⊆ S_t, the server computes average update Δt_S and utility vt(S) measuring its closeness to Δt_val. Monte Carlo sampling estimates each client’s Shapley value ϕ_i(v_t). These contributions accumulate cumulatively. Adaptive weights α_{t+1} are set by truncation on cumulative contributions. The next global model θ_{t+1} is aggregated weighted by α_{t+1}, better reflecting client quality and adversary suppression, and the training proceeds to round t+1.
Technical innovations
- Introduction of Trajectory Shapley Value (TSV), a validation-induced utility measuring client contributions by geometric alignment of coalition updates with the server-side optimization trajectory, rather than static model accuracy improvements.
- Development of FedTSV, an adaptive federated aggregation algorithm that dynamically updates client weights based on cumulative TSV estimates to ensure fairness and robustness against heterogeneous and adversarial clients.
- Implementation of a bounded per-round utility function with normalization factor σ_t to stabilize Shapley value estimation near stationary points and enable efficient Monte Carlo approximation.
- Design of a recursive cumulative contribution update that truncates negative values to suppress malicious clients’ influence while preserving positive contributions for reliable participants.
Datasets
- MNIST — ~60,000 training, 10,000 test images — public benchmark
- CIFAR-10 — 50,000 training, 10,000 test images — public benchmark
Baselines vs proposed
- FedAvg: MNIST accuracy ≈ 0.75 vs FedTSV ≈ 0.79
- FedAvg: CIFAR-10 accuracy ≈ 0.65 vs FedTSV ≈ 0.70
- CGSV: Lower accuracy with higher sensitivity to adversarial clients compared to FedTSV
- LOO: More scattered client weights and less stable accuracy than FedTSV
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.30336.
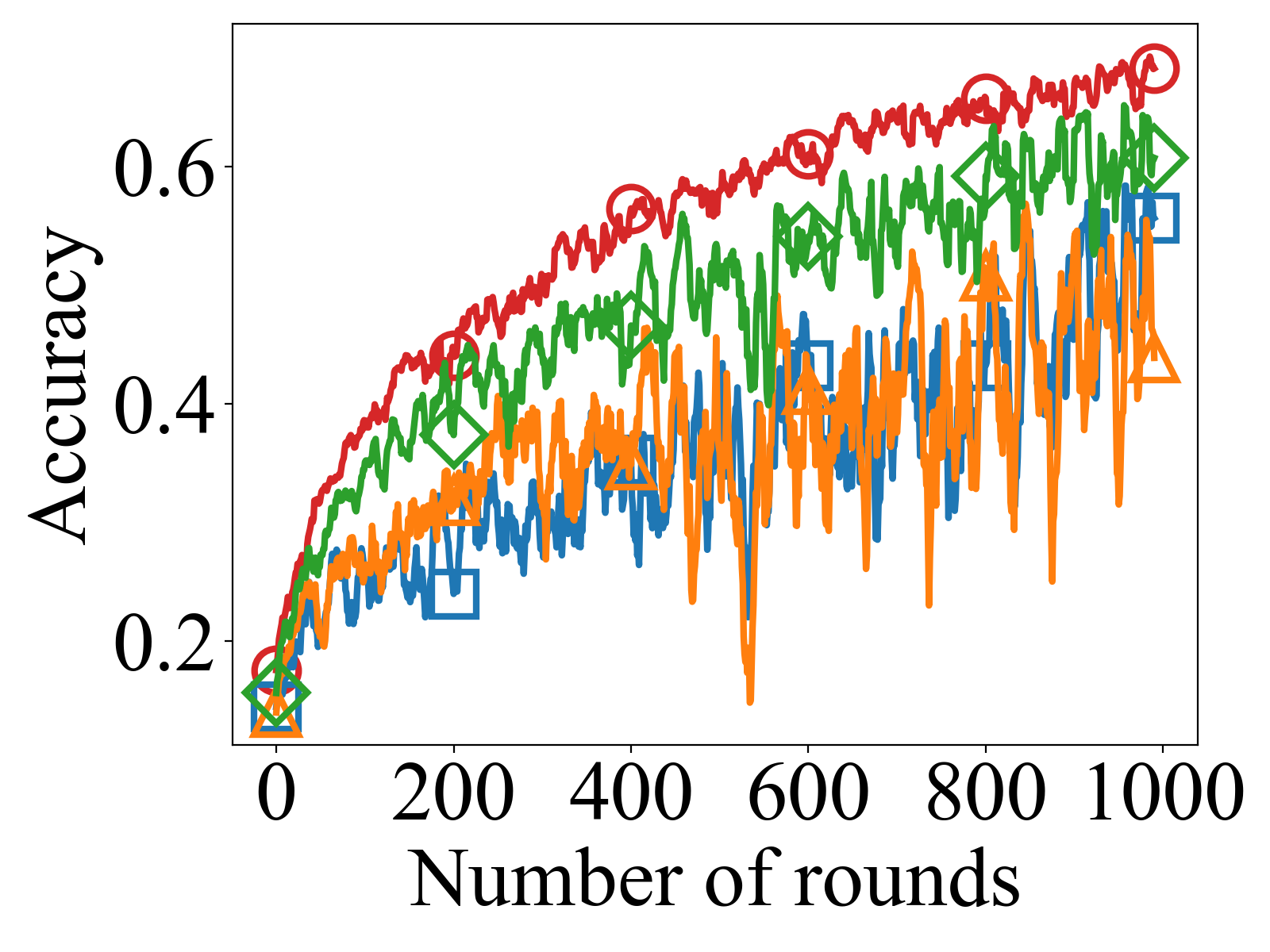
Fig 1: shows the global accuracy and loss trends for the
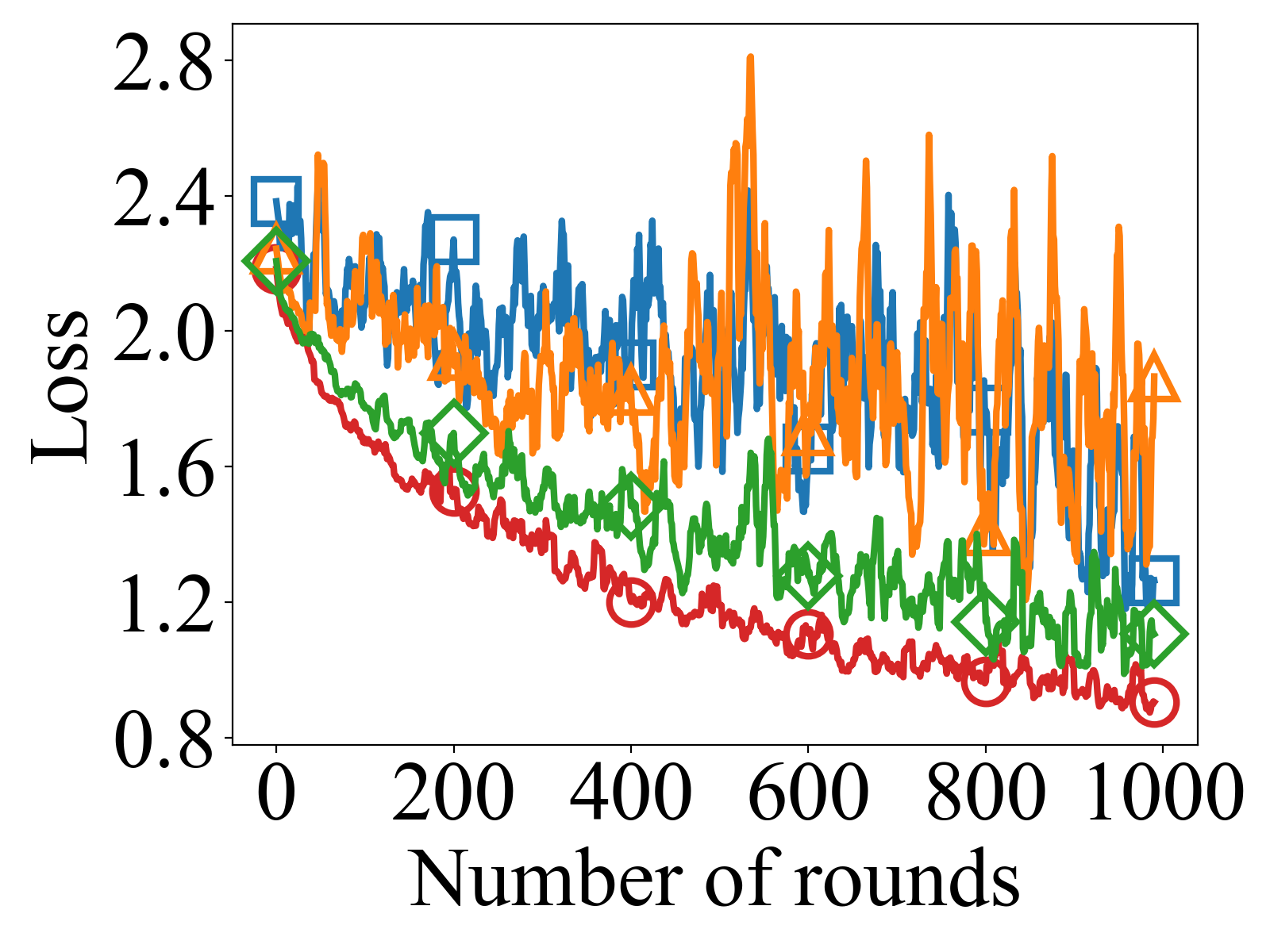
Fig 2: illustrates the final distribution of client weights
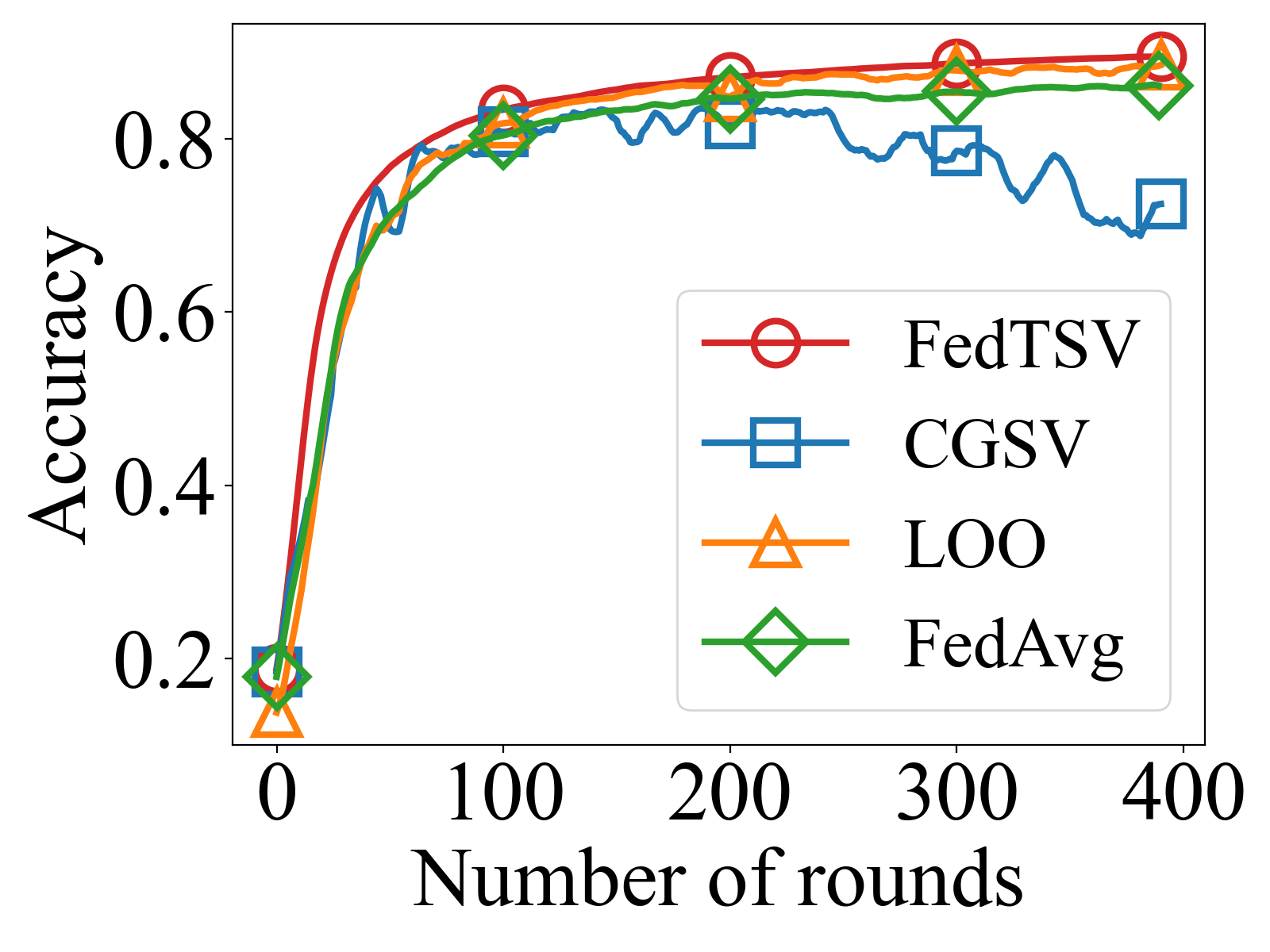
Fig 3 (page 5).
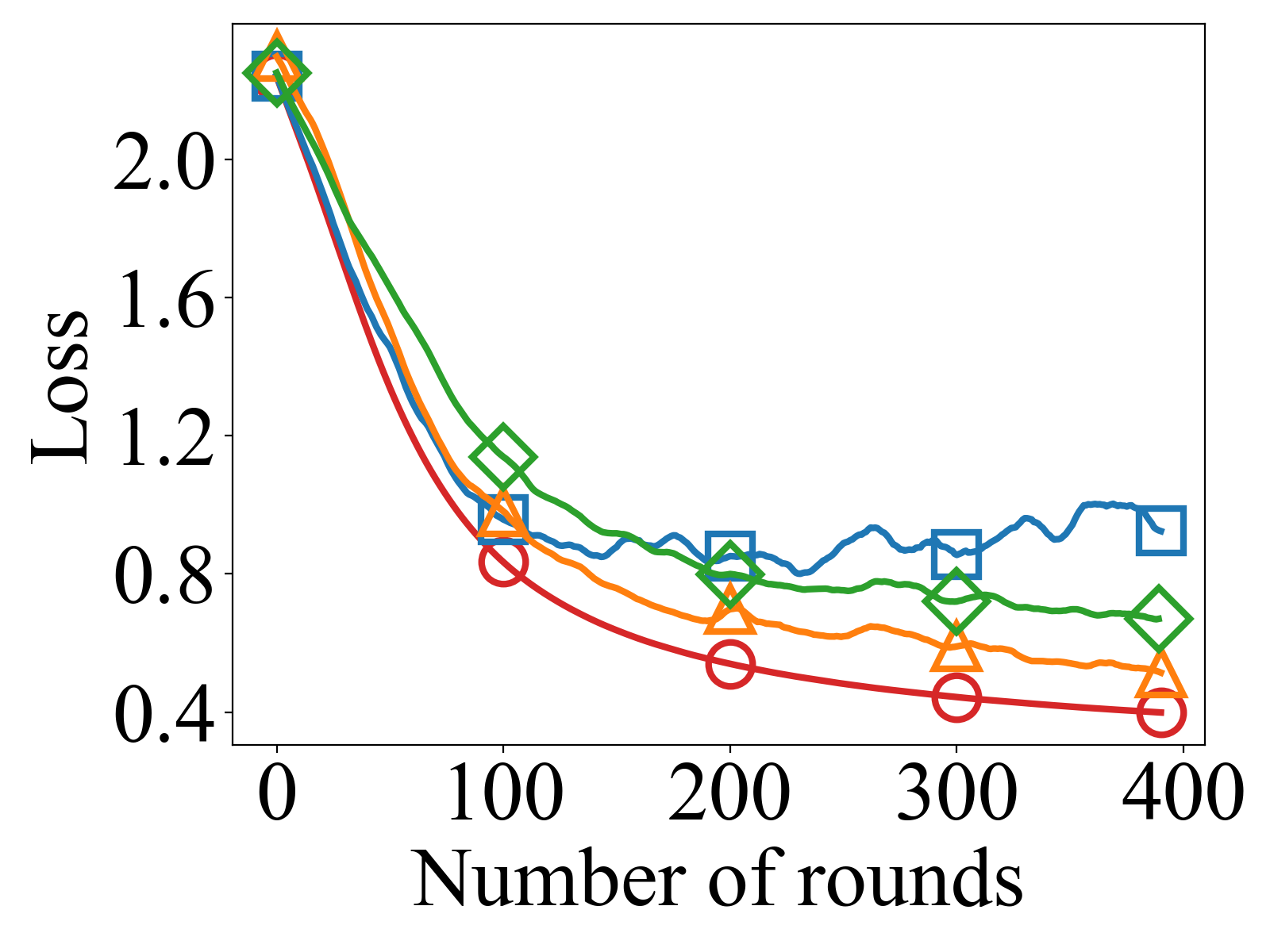
Fig 4 (page 5).
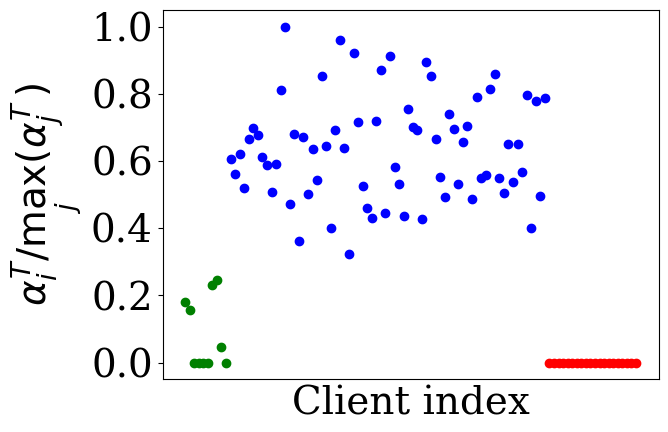
Fig 5 (page 5).
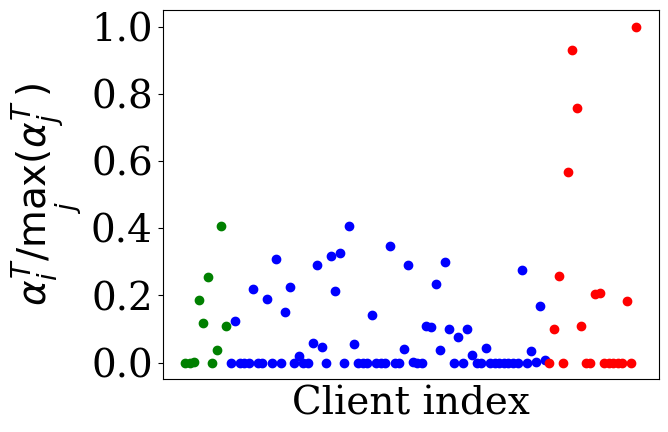
Fig 6 (page 5).
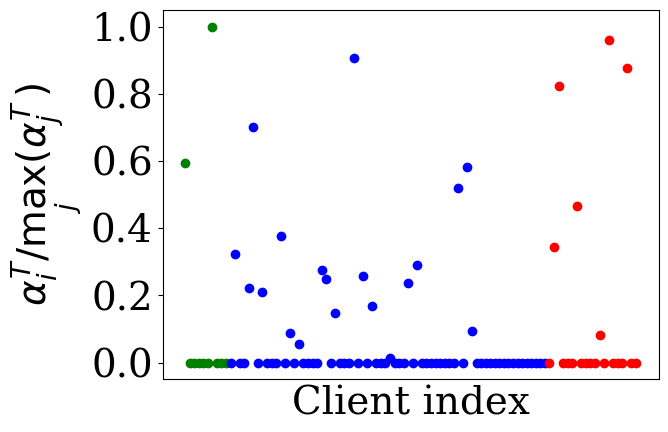
Fig 7 (page 5).
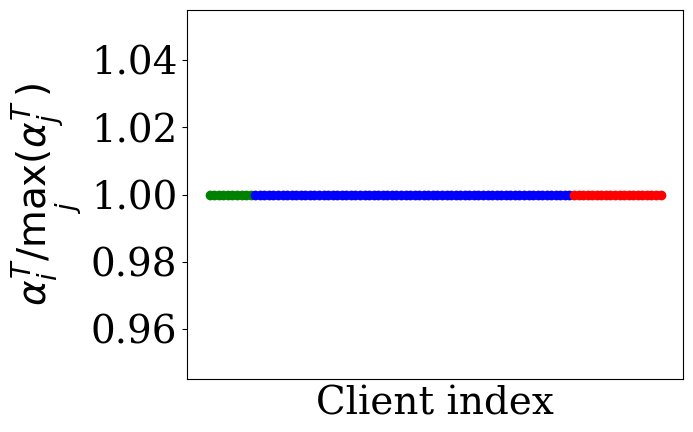
Fig 8 (page 5).
Limitations
- No formal theoretical convergence guarantees or incentive compatibility proofs for FedTSV's time-varying adaptive weighting algorithm are provided.
- Evaluation limited to image classification benchmarks (MNIST, CIFAR-10); generalization to other tasks or modalities is not demonstrated.
- Malicious client attack model assumes fixed label shuffling; robustness against stronger or more adaptive adversaries remains untested.
- Monte Carlo Shapley value estimation introduces approximation variance; methods to reduce estimation noise or computational cost are not explored in depth.
- The approach requires a held-out server-side validation dataset, which may not always be available or representative in real-world deployments.
- No explicit testing of performance or robustness under distribution shifts or dynamic client populations beyond fixed IID/non-IID/malicious splits.
Open questions / follow-ons
- How does FedTSV perform against more sophisticated adversarial attacks beyond label shuffling, such as model poisoning or targeted backdoors?
- Can theoretical guarantees (e.g., convergence, fairness, incentive compatibility) for FedTSV's adaptive weighting based on trajectory Shapley values be established?
- What are the computational tradeoffs of Monte Carlo approximations for real-world large FL client populations and model scales?
- How sensitive is FedTSV to the choice and representativeness of the held-out validation dataset used to compute reference updates?
Why it matters for bot defense
For bot-defense and CAPTCHA systems that rely on federated learning or distributed client contributions, FedTSV offers a principled and efficient approach to quantify and fairly aggregate client input quality in the presence of heterogeneous data and potentially malicious participants. The trajectory-based Shapley value metric better captures time-dependent client impact on optimization, enabling dynamic down-weighting of adversarial or low-quality clients that could otherwise degrade model reliability. CAPTCHA platforms could leverage FedTSV-informed client weighting to improve robustness of federated models used in challenge generation or fraud detection. However, deployment requires access to relevant validation data on the server side and computational resources for Monte Carlo Shapley estimation. Balancing fairness, robustness, and efficiency as FedTSV proposes is crucial given evolving bot behavior and data heterogeneity in live environments.
Cite
@article{arxiv2605_30336,
title={ Fairness-Aware Federated Learning with Trajectory Shapley Value },
author={ Daniel Kuznetsov and Ziqi Wang },
journal={arXiv preprint arXiv:2605.30336},
year={ 2026 },
url={https://arxiv.org/abs/2605.30336}
}