
Demystifying Data Organization for Enhanced LLM Training
Source: arXiv:2605.30334 · Published 2026-05-28 · By Yalun Dai, Yangyu Huang, Tongshen Yang, Yonghan Wang, Xin Zhang, Wenshan Wu et al.
TL;DR
This paper addresses the underexplored but important problem of how the temporal organization of training data influences Large Language Model (LLM) training dynamics and final performance. While much prior work has focused on data selection, the authors argue and demonstrate that the sequence in which training samples are presented during typically one-or-few-epoch LLM training significantly affects outcomes. Leveraging pre-computed sample-level scores that characterize data quality, difficulty, or learnability, they identify four key guidances for effective data organization: Boundary Sharpening (start with easier data, finish with harder data), Cyclic Scheduling (periodically revisit simpler samples to reduce forgetting), Curriculum Continuity (smooth transitions to reduce optimization shocks), and Local Diversity (maintain sample diversity within mini-batches to avoid overfitting). From these principles, they propose two novel data ordering strategies—STR and SAW—that integrate subsets of these guidances to produce optimized data sequences.
Extensive experiments spanning different model scales (160M to 1.7B parameters), dataset sizes (1B to 50B tokens), and training stages (pre-training and supervised fine-tuning) validate the effectiveness of the proposed strategies. STR and SAW consistently outperform baselines including random ordering, vanilla Curriculum Learning, and DELT on a variety of reasoning, coding, and language modeling tasks, improving final accuracy scores and training stability. The methods show robustness across scale and data types and align with extrapolated gains predicted by the Chinchilla scaling law for much larger LMs. The work highlights the importance of not just what data is used but how it is temporally ordered to optimize LLM training dynamics with negligible additional overhead.
Key findings
- Ending training with high-scoring (harder/higher-quality) samples boosts final model accuracy compared to ending with low-scoring data (Table 1).
- Cyclic Scheduling (FO-3) that periodically reintroduces low-score data reduces forgetting and improves average accuracy by up to 1% over vanilla curriculum learning (Tables 2, Fig 4).
- Curriculum Continuity achieved via Zig-zag ordering (ZIG) yields more stable training gradients and outperforms folding ordering (FO) by ~0.1-0.2% accuracy across tasks (Table 3, Fig 5).
- Local Diversity via Jittering Ordering (JIT) within mini-batches improves generalization and robustness, increasing accuracy by 0.1–0.3% and flattening loss basins (Table 4, Fig 6).
- Cross-guidance strategies STR (G1,G2,G4) and SAW (G1,G2,G3,G4) outperform prior data organization methods like Curriculum Learning and DELT by up to 2% absolute on average across pretraining and SFT (Table 5).
- STR and SAW scale effectively to large 50B-token datasets and model sizes up to 1.7B, continually outperforming random ordering by 1–3% accuracy on FineWeb-Edu and QuRatedPajama datasets (Table 6).
- Extrapolation via Chinchilla scaling law shows consistent test loss reductions for large LMs including GPT-3 175B and Llama variants when trained with ordered data over random (Table 7).
- Training loss curves on real and curated corpora demonstrate stable, lower test loss trajectories for STR/SAW ordered data across multiple model sizes (Fig 7).
Methodology — deep read
Threat Model & Assumptions: The adversary model is not applicable here as this study focuses on improving LLM training efficacy through data organization. The work assumes access to a large raw dataset D and pre-computed sample-level scores (γ) for each data point. These scores characterize metrics like difficulty or quality, obtained from prior data selection or scoring methods, incurring no extra compute overhead.
Data: Datasets used include FineWeb-Edu (~1B tokens), QuRatedPajama (~50B tokens, detailed in appendix), DeepMath-103K (for math reasoning tasks), and OpenCodeInstruct (for coding tasks). The data is split into training, validation sets as commonly done in LLM training. Examples are labeled by precomputed scores, used as optimization signals for ordering but not labels for supervised learning. Preprocessing details appear standard but not extensively specified.
Architecture / Algorithm: Models are variants of the Mistral architecture for pretraining and Qwen3 for supervised fine-tuning, ranging from 160M to 1.7B parameters. The core novel algorithms are data ordering permutations fo based on precomputed scores γ. Four guidances are formalized leveraging these scores:
- Boundary Sharpening (G1): Create discrete segments from sorted data and reorder such that initial and final segments contain low- and high-score samples respectively, with random shuffling within segments (SEG algorithm).
- Cyclic Scheduling (G2): Divide sorted data into L folds distributed in a strided manner to ensure periodic revisit of samples across score ranges (Folding Ordering FO algorithm).
- Curriculum Continuity (G3): Improve upon FO by reversing ordering in odd folds to ensure smooth transitions and reduce abrupt attribute shifts (Zig-zag Ordering ZIG algorithm).
- Local Diversity (G4): Within fixed-size windows, shuffle samples to maintain heterogeneity in mini-batches (Jittering Ordering JIT). Cross-guidance strategies STR (integrating G1,G2,G4) and SAW (integrating all four guidances) partition the data into stable and transition regions and apply folding or zig-zag ordering with optional JIT to produce globally progressive yet stable and diverse ordering.
Training Regime: Pretraining and SFT used respective architectures with official pre-trained checkpoints for SFT. Exact epochs, batch size, optimizer details are in appendices but roughly include training tokens at billion-scale quantities. Multiple model sizes were used for scalability evaluation. Score re-use allowed minimal overhead.
Evaluation Protocol: Metrics include average accuracy across diverse benchmarks: ARC (challenge/easy), HellaSwag, LAMB, OBQA, PIQA, SciQ, Wino, and task-specific metrics for AIME24/25 (math) and HumanEval/MBPP (coding). Baselines include random ordering, vanilla curriculum learning (CL), and DELT (prior review strategy). Ablations evaluated individual guidances (G1-G4) and their combination (STR, SAW). Analysis included training perplexity curves, gradient norm visualizations, and robustness under weight noise. Cross-validation or distribution shift tests not explicitly reported.
Reproducibility: The code is publicly released at GitHub (https://github.com/microsoft/data-efficacy/). Model weights for large-scale experiments appear unavailable. Some datasets are public (e.g., QuRatedPajama, DeepMath-103K), others constructed internally but from public sources.
Example walkthrough: Given a sorted dataset Dsort with scores γ, the SAW strategy partitions Dsort at K transition points. Within stable regions, samples remain sorted by scores. In each transition region (of size 2ρ), samples are reordered using the ZIG algorithm to ensure smooth score transitions. Finally, JIT shuffles samples locally within windows of size w to preserve local diversity. This permutation π defines Dord. Training proceeds normally on Dord with standard optimization but benefits from improved stability and generalization due to ordering.
Technical innovations
- Formalization of four key guided principles (Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, Local Diversity) specifically for organizing LLM training data sequences as opposed to just selecting data.
- Design of Segment Ordering (SEG), Folding Ordering (FO), Zig-zag Ordering (ZIG), and Jittering Ordering (JIT) algorithms implementing these guidances using pre-computed data scores with near-zero compute overhead.
- Development of cross-guidance strategies STR and SAW that integrate multiple guidances into unified ordering schemes, achieving robust gains across pre-training and supervised fine-tuning at up to 1.7B scale.
- Comprehensive empirical validation that reusing existing data scoring metrics to inform training data temporal sequencing can systematically improve LLM training stability, performance, and robustness.
Datasets
- FineWeb-Edu — ~1 billion tokens — public dataset used for general pre-training experiments.
- QuRatedPajama — ~50 billion tokens — large-scale web data corpus available publicly.
- DeepMath-103K — 103,000 samples — publicly available math reasoning benchmark for SFT.
- OpenCodeInstruct — Unknown size, coding instruction data — publicly available or derived datasets used for supervised fine-tuning.
Baselines vs proposed
- Random ordering baseline: average accuracy 37.09% pre-training (FineWeb-Edu), improved to 38.78% by SAW (Table 5).
- Vanilla Curriculum Learning (CL): average accuracy 37.61% pre-training, improved to 38.29% with ZIG and 38.32% with ZIG+JIT (Table 3 & 4).
- DELT: average accuracy 37.35% pre-training, improved to 38.65% with STR and 38.78% with SAW (Table 5).
- FO-3 (folding cycles=3): outperforms CL by ~0.6% accuracy in pre-training and SFT settings (Table 2).
- Adding JIT (local diversity) improves accuracy by ~0.1–0.3% over sorting methods consistently across datasets (Table 4).
- STR and SAW outperform strongest baselines by approximately 1–2% average accuracy across multiple benchmarks and scales (Table 5).
- STR and SAW beat random ordering by 1–3% accuracy on large 50B token datasets across model sizes from 160M to 1.7B (Table 6).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.30334.
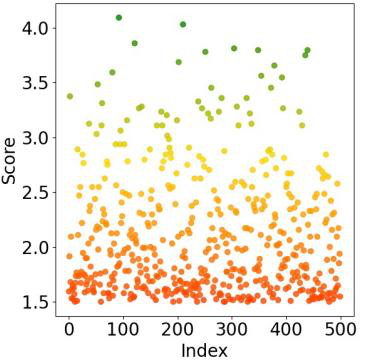
Fig 1: Performance comparison of different data or-
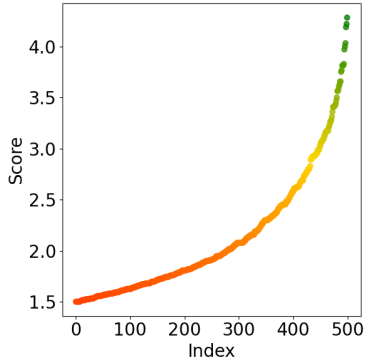
Fig 2 (page 1).
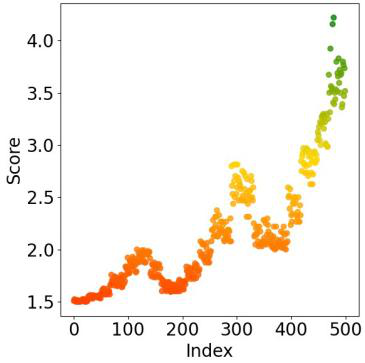
Fig 3 (page 1).
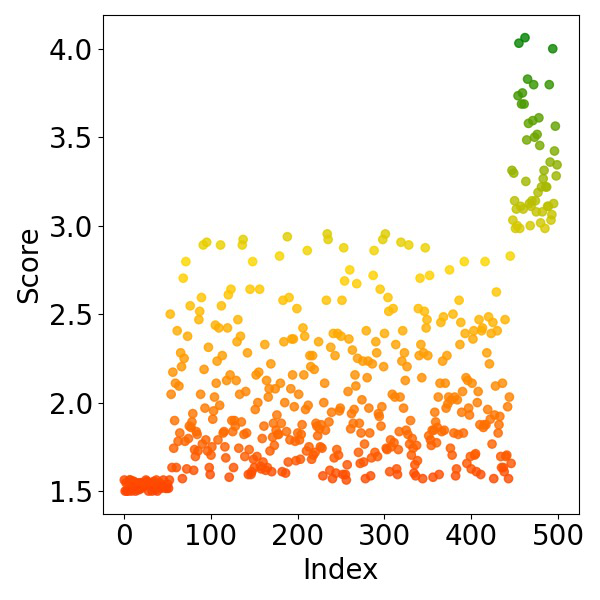
Fig 2: Visualization of score-index distribution under
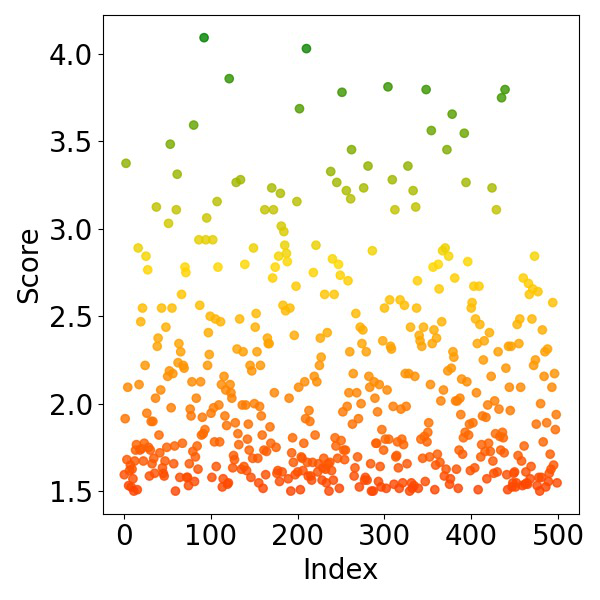
Fig 3: Comparison of accuracy trajectories for SEG.
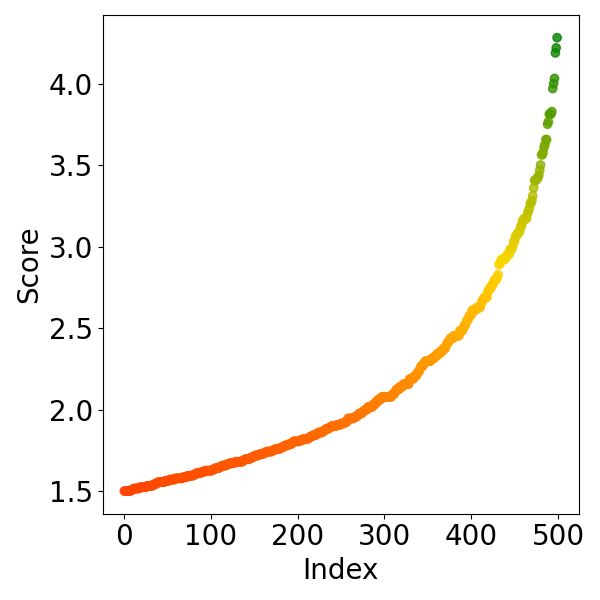
Fig 4: The LMs’ perplexity (PPL) for De. Results
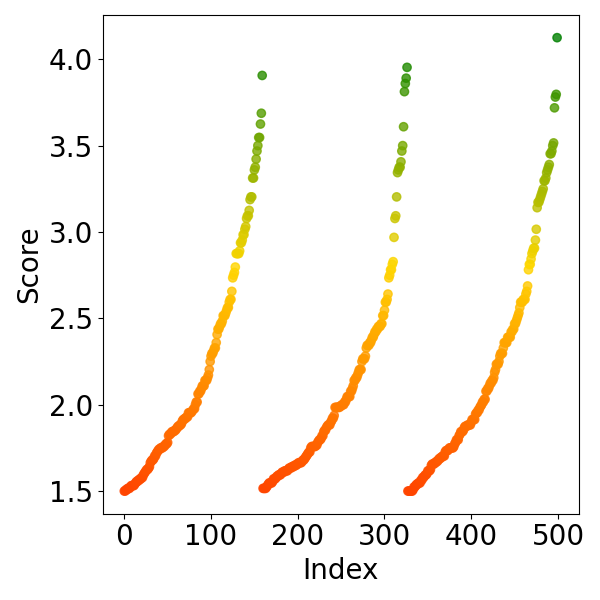
Fig 7 (page 4).
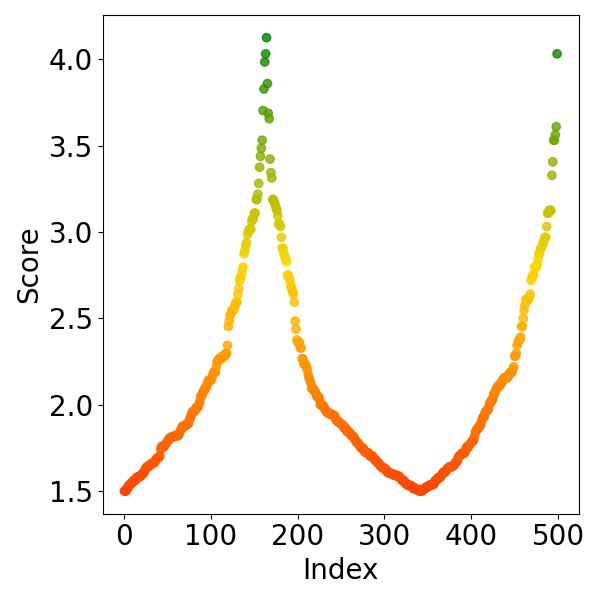
Fig 8 (page 4).
Limitations
- Dependence on the quality and relevance of pre-computed sample-level scores: if scores poorly reflect sample difficulty or quality, ordering benefits may reduce or vanish.
- Experiments focus mainly on general and fine-tuning data for language and code; handling multimodal or more diverse modalities remains untested.
- No adversarial robustness or manipulation resistance evaluations—reordering strategies may be vulnerable in hostile training environments.
- Limited reporting on batch size and epoch-based training effects; only few epochs typical for LLM training considered.
- Ablations do not fully clarify interactions between guidances under distributional shifts or noisy labels.
- Model architectures are confined to Mistral and Qwen3 variants; generality to other backbones needs verification.
Open questions / follow-ons
- How would data organization guidances perform under multi-epoch training regimes common in non-LLM setups?
- Can adaptive or learned data ordering policies improve upon the manually designed guidances STR/SAW, possibly using reinforcement learning?
- How do these data organization strategies interact with other training efficiency techniques like mixed precision, gradient accumulation, or distributed sampling?
- What is the impact of imperfect or noisy data scoring functions on the robustness and gains of these ordering methods?
Why it matters for bot defense
Although this work is primarily focused on improving LLM training efficiency and stability through data ordering, the core insights about careful sequencing of sample presentation have broader relevance for bot-defense and CAPTCHA tasks. In CAPTCHA or bot-detection systems that involve training machine learning models or neural classifiers, the order of training examples may bias or destabilize learning if not properly managed. The principles of Boundary Sharpening and Cyclic Scheduling could guide staged training where easy-to-distinguish examples are presented first and harder, more confusing instances later, while periodic re-exposure mitigates forgetting. Curriculum Continuity can prevent oscillations in model confidence across training, enhancing classifier reliability. Local Diversity ensures mini-batches expose the model to heterogeneous negative examples, reducing overfitting to bot-like behavior patterns. Thus, bot-defense ML teams might adapt these data organization techniques to improve training stability and robustness, especially when working with limited or expensive labeled data.
Cite
@article{arxiv2605_30334,
title={ Demystifying Data Organization for Enhanced LLM Training },
author={ Yalun Dai and Yangyu Huang and Tongshen Yang and Yonghan Wang and Xin Zhang and Wenshan Wu and Qihao Zhao and Hao Li and Yuanyuan Gao and Kim-Hui Yap and Scarlett Li },
journal={arXiv preprint arXiv:2605.30334},
year={ 2026 },
url={https://arxiv.org/abs/2605.30334}
}