
Cookie-Bench: Continuous On-screen Key Interaction Evaluation for Web Generation
Source: arXiv:2605.30000 · Published 2026-05-28 · By Haoyue Yang, Zhangxiao Shen, Fan Ding, Hangting Lou, Yifeng Kou, Haoqing Yu et al.
TL;DR
This paper addresses the challenging problem of evaluating interactive front-end web code generated by large language models (LLMs). Current human-judged leaderboards such as Arena provide high-quality assessments but are prohibitively expensive and slow for iterative development. Automated proxies often rely on brittle reference implementations, static test suites, or checklist scoring that miss holistic reasoning and runtime interaction defects. To overcome these limitations, the authors propose a novel, reference-free, autonomously driven, and meta-cognitively inspired evaluation regime instantiated by two main artifacts: Cookie-Bench, a large 1,000-query benchmark spanning 11 domains with both static and interactive web tasks across multiple languages and difficulty tiers; and Cookie, a three-stage judge agent that separates (1) Static Perception by passively observing the rendered page, (2) Agent-Driven Interaction by autonomously exploring runtime behaviors with multi-modal evidence capture (video, screenshots, audio, traces), and (3) Dynamic Scoring by holistically reasoning over gathered evidence to produce final functionality and aesthetics scores with failure attribution. On Cookie-Bench, Cookie achieves substantial alignment with human expert judgment and exposes notable capability gaps across 13 state-of-the-art LLMs generating web code in both React scaffold and direct HTML output modes. The results demonstrate that the integrated static plus interactive evaluation approach surfaces defects undetectable by static-only benchmarks, especially on dynamic interactive tasks. An ablation study confirms that each evaluation stage contributes meaningfully to agreement with humans, validating the metacognitive framework. This work offers a scalable, principled alternative to costly human leaderboard evaluation for web generation.
Key findings
- Cookie-Bench covers 11 domains, 54 leaf categories, 1,000 queries spanning static and dynamic web tasks balanced across 3 difficulty tiers and 3 target language groups.
- Cookie's three-stage evaluation pipeline (Static Perception, Agent-Driven Interaction, Dynamic Scoring) achieves 61.6% average agreement with human judgments on 132 queries, outperforming ablated variants by 4.9-23.4 points.
- React scaffolded code generation shows a 22-point win-rate spread across 13 frontier LLMs, while direct HTML generation shows a 21-point spread; scaffold complexity benefits stronger models but raises the floor.
- Dynamic interaction evaluation detects emergent defects (e.g., physics tuning in a Super Mario query) not apparent in static snapshots, revising down functionality scores after runtime exploration.
- Model performance varies by page type: most models do better on static tasks in React scaffold mode but better on dynamic tasks in direct HTML mode, indicating architectural trade-offs.
- Cost analysis shows React scaffolding consumes 2.5-3.5× more input tokens and costs significantly more per query than HTML direct generation, with diminishing returns at top models.
- Failure analysis reveals that most installation failures are infrastructural (port conflicts, verifier timeouts) rather than genuine code errors, indicating a lower true failure ceiling.
- Ablation confirm that omitting deferred (holistic) scoring drops agreement with humans by about 21 points, highlighting the importance of whole-evidence reasoning.
Threat model
The adversary is not explicitly modeled as malicious; rather, the evaluation aims to emulate an honest, expert human judge assessing model-generated web code. The system assumes no access to ground-truth implementations or test suites and no adversarial attempts to evade detection. The focus is on capturing typical functional and aesthetic defects in code outputs, not on security exploits or active evasion.
Methodology — deep read
The evaluation regime is motivated by the metacognitive monitoring concept, modeling human reviewer behavior as sequential evidence accumulation followed by holistic judgment. The threat model assumes an honest but fallible reviewer proxy aiming to align with expert human judgment; adversarial manipulation is not directly addressed.
Data: Cookie-Bench contains 1,000 queries selected to cover a fixed 11-domain, 54-leaf taxonomy of web development scenarios, spanning both static presentation and dynamic interactive tasks. Queries are sourced from two regimes: 514 naturalistic queries sampled from real user traffic and public evaluation channels, preserving authentic user intent and colloquial phrasing; and 486 crowd-synthesized queries authored under a taxonomy-guided role-play protocol to ensure uniform coverage including rare edge cases. Queries are stratified by difficulty assessed on six orthogonal axes and balanced across three target language groups (Chinese, English, and six others) with quality assurance via deduplication (SimHash + TF-IDF), LLM-judge filtering on safety and executability, plus expert review for final filtering and label arbitration.
Evaluation Architecture & Algorithm: Cookie, the evaluation agent, operates in three stages: (1) Static Perception captures a full-page screenshot, runtime error logs, and structural interface metadata, generating initial functionality and aesthetics priors from a vision-language model; (2) Agent-Driven Interaction deploys a computer-using autonomous agent that executes an observe-think-act loop to explore the application interactively, dynamically generating interaction trajectories without human-scripted paths and capturing continuous video, step screenshots, audio, and interaction traces; (3) Dynamic Scoring defers all final scoring until the entire multi-modal evidence package is assembled offline, then synthesizes holistic continuous scores for functionality and aesthetics with structured defect attribution, allowing reversals of prior stage judgments. This design prevents confirmation bias and imitates human metacognition.
Training & Hyperparameters: Not applicable as the evaluation agent integrates multiple pretrained components such as vision-language models and LLMs for planning and scoring. No explicit machine learning training is described.
Evaluation Protocol: 13 frontier LLMs spanning closed/open models and large parameter scales are tested on both React agent scaffold generation (using a code sandbox with tool calls) and direct HTML output. The Cookie pipeline evaluates each model’s outputs across dynamic and static tasks, producing aggregated functionality and aesthetics scores. Human annotations on a held-out 132-query slice use a 16-item binary rubric for finer-grained evaluation to validate Cookie's alignment. Pairwise agreement rates between humans and Cookie serve as evaluation metrics. Ablations isolate static perception, video evidence, static scoring, and deferred scoring to measure contribution to agreement.
Reproducibility: Code and evaluation protocols (Cookie, Cookie-Bench) are documented and released with comprehensive appendices. No frozen weights or closed data are specified beyond internal dataset provenance. The benchmark data and agent design enable independent replication.
Worked example: The paper walks through a "Super Mario" query where static perception initially assigns a high functionality score based on completeness of source code. However, the agent-driven interaction reveals a physics tuning defect where the jump arc is too short to clear an obstacle, leading dynamic scoring to revise the functionality score downward. This showcases the value of runtime exploration.
Technical innovations
- A reference-free, autonomously driven, multi-stage evaluation framework combining static perception, agent-driven interaction, and deferred holistic scoring, inspired by human metacognitive monitoring.
- Construction of Cookie-Bench: a large-scale, cross-lingual, multi-difficulty web development benchmark explicitly balancing static and dynamic tasks to probe frontier model capabilities.
- Design of an adaptive autonomous agent that explores generated web applications without requiring pre-authored scripts or test suites, collecting continuous multi-modal runtime evidence.
- Holistic dynamic scoring that defers final judgment until full evidence accumulation, enabling structured failure attribution and reducing confirmation bias present in reactive scoring.
Datasets
- Cookie-Bench — 1,000 queries — sourced from internal WebDev product user traffic plus crowd-synthesized queries under taxonomy-guided role-play, quality filtered with LLM judge and expert review
Baselines vs proposed
- Ablated pipeline without vision input: human agreement drops by 7.8 points average vs full Cookie pipeline (61.6% to 53.8%).
- Ablated pipeline without video evidence: agreement drops 4.9 points vs full pipeline.
- Ablated pipeline without static score prior: drops 3.8 points agreement.
- Ablated pipeline without deferred (holistic) scoring: largest drop of 21.0 points agreement.
- Top model Claude-Opus-4.7 React agent scaffold total score = 83.3 vs HTML direct chat total = 84.2; gap among 13 models spans 21-22 points.
- Mid-tier model DeepSeek-V4-Flash cost $6.75 per query vs Claude-Opus-4.6 cost $802.97 in React mode, with score gap within single digits.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.30000.

Fig 1: Top: Query “Super Mario” flowing through deployment, autonomous agent-driven

Fig 2 (page 1).

Fig 3 (page 1).

Fig 4 (page 1).

Fig 5 (page 1).

Fig 6 (page 1).
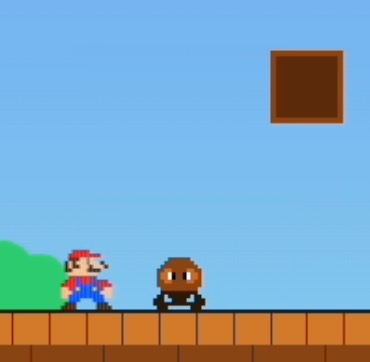
Fig 7 (page 1).

Fig 8 (page 1).
Limitations
- Human agreement rates peak around 61.6%, leaving substantial room for improvement in automated scoring fidelity.
- Evaluation is not adversarially robust; threat model omits worst-case or malicious input scenarios.
- Failure analysis focuses on infrastructural errors in code deployment; code semantic correctness errors less frequent but may be under-explored.
- The benchmark’s 1,000 queries, though large, may not cover all real-world web development edge cases or fully generalize beyond 11 domains.
- The scoring system reduces complex multidimensional quality to two axes (functionality and aesthetics), possibly missing finer-grained error typologies.
- Dynamic interaction agent uses heuristic planning; more sophisticated exploration policies or human-like interaction models may improve coverage.
Open questions / follow-ons
- Can the deferred holistic scoring stage be further improved with end-to-end learned policies integrating multi-modal evidence?
- How robust is the evaluation against adversarially crafted generated code that tries to fool the autonomous interaction agent or scoring heuristics?
- Could the agent-driven interaction be enhanced with human-in-the-loop guidance or advanced RL methods for broader exploration?
- How well do the human agreement rates generalize across other languages, domains, or evolving front-end development paradigms not covered by Cookie-Bench?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, Cookie-Bench and Cookie offer a rigorous framework for evaluating web application code generation beyond static frame-based metrics, importantly capturing interactive state transitions and user-driven behaviors. This approach highlights the value of autonomous, multi-modal interaction monitoring and deferred holistic judgment to detect defects that only manifest during live use, which closely parallels challenges in assessing bot-resilience in dynamic front-end environments. The separation of evidence accumulation from final scoring reduces premature judgments, a useful principle when designing AI-assisted CAPTCHA or bot-detection tools that must evaluate complex client-side behaviors reliably without reference grounds or fixed scripts. However, the benchmark’s focus on developer-facing web code generation differs from typical user-facing bot detection workflows, so adaptation might be needed to model malicious bot interactions specifically. Overall, the methodology supports building more nuanced and scalable evaluation proxies for bot-defense models that must understand interaction flows rather than static snapshots.
Cite
@article{arxiv2605_30000,
title={ Cookie-Bench: Continuous On-screen Key Interaction Evaluation for Web Generation },
author={ Haoyue Yang and Zhangxiao Shen and Fan Ding and Hangting Lou and Yifeng Kou and Haoqing Yu and Jingyao Li and Zhengfan Wu and Siqi Bao and Jing Liu and Hua Wu },
journal={arXiv preprint arXiv:2605.30000},
year={ 2026 },
url={https://arxiv.org/abs/2605.30000}
}