
Classification of non-analyzable word types in web documents to implement an effective Korean e-learning system
Source: arXiv:2605.29638 · Published 2026-05-28 · By Sang-Taek Park, Ae-Lim Ahn, Eric Laporte, Jee-Sun Nam
TL;DR
This paper addresses the challenge of incorporating informal, real-world Korean language expressions found in web documents into Korean e-learning systems targeted at high-level learners. Unlike existing systems that use formal, standardized Korean, the authors emphasize the diversity and prevalence of non-standard word forms in informal texts like online customer reviews or blogs, which pose comprehension barriers to foreign learners. To study this, the authors construct two corpora representing formal (news articles) and informal (customer reviews) Korean text, comparing the frequency and types of non-analyzable words by a standard Korean lexical analyzer.
Their main finding is that informal web texts contain a much higher proportion (27%) of non-analyzable or non-standard word types versus only 3.8% in formal texts. The authors categorize these non-standard words into several types including missing word spacing, abbreviations, deviant spellings, diverse loanword transliterations, newly coined words, and emoticons. To effectively handle these variations, they propose using Local Grammar Graphs (LGGs), a formalism based on finite-state automata able to capture linguistic phenomena violating regular syntactic rules. Constructing LGGs with the Unitex system, they demonstrate how these graphs can map non-standard forms to their standard counterparts, enabling an e-learning system to better support learners in understanding informal Korean expressions.
Key findings
- Corpus of formal news articles (10,488 tokens, 3,967 types) has only 152 (3.8%) non-analyzable word types.
- Corpus of informal customer reviews (10,608 tokens, 3,792 types) contains 1,062 (27%) non-analyzable word types.
- Non-analyzable words in informal corpus reflect intentional rule violations like spacing omission, abbreviations, spelling deviations, and loanword variation.
- Examples include the abbreviated form 강추 (gangchu) instead of 강력 추천 (ganglyeog chucheon) and varied transliterations of "chocolate" such as 쵸콜렛, 쪼꼬렛, 초코렛.
- LGGs implemented with finite-state transducers in Unitex can automatically normalize these non-standard words to standard forms.
- In formal corpus, non-analyzable tokens mainly include typos and dictionary gaps like proper nouns, while in informal corpus intentional variations are dominant.
- LGGs offer a flexible, local linguistic modeling approach well suited to describing partially ungrammatical or non-standard text phenomena.
Threat model
The threat model centers on foreign Korean learners as users confronted with informal, non-standard language forms in web documents that impede comprehension. The learner has limited knowledge of Korean spelling variations and slang. The system aims to automatically identify and normalize these forms so learners can understand and memorize them. The adversary is the informal language variation itself, not a malicious attacker.
Methodology — deep read
The authors first establish their threat model as addressing the difficulty non-standard Korean expressions in informal web documents pose to foreign learners. The adversary is implicitly the learner confronted with linguistic variation outside formal norms, with the goal of enabling automated normalization and understanding.
For data, two corpora were constructed: Corpus A includes formal Korean news articles (~10,488 tokens, 3,967 types) from the social issues section; Corpus B includes informal customer reviews (~10,608 tokens, 3,792 types) about cosmetic products collected from web blogs. These corpora were processed using the Korean lexical analyzer Geuljabi, which relies on a machine-readable dictionary for morphological parsing.
This analysis flagged words that were non-analyzable due to absence from the dictionary. Statistical comparison identified a low 3.8% rate of non-analyzable types in formal corpus versus 27% in informal corpus, underscoring the prevalence of informal variants.
To characterize these variants, the authors manually categorized them into missing spaces, abbreviations, deviant spellings, loanword transliteration diversity, neologisms, and emoticons. For example, the abbreviation 강추 replaces the standard 강력 추천. The paper provides concrete examples with translations.
To automate handling, the authors apply the Local Grammar Graph (LGG) formalism as introduced by Gross (1997, 1999). LGGs are finite-state automata that describe local syntactic patterns and can encode non-standard variants and their transformations to standard forms. Using the Unitex graph editor and compiler, LGGs were constructed for each non-standard type and compiled into finite-state transducers capable of mapping variants to canonical forms.
An end-to-end example given is the LGG that maps multiple transliterations of "chocolate" — such as 쵸콜렛, 쪼꼬렛, 초코레트 — to the standard 초콜릿 form. This finite-state normalization can be integrated into e-learning systems to aid comprehension and vocabulary memorization.
Evaluation is mainly qualitative in nature by corpus analysis and LGG construction; quantitative results focus on non-analyzable token rates before and after normalization. The paper does not describe formal accuracy metrics, statistical tests, or cross-validation. No code or dataset release is indicated. The approach is language- and domain-specific but compatible with the Unitex multilingual environment.
Overall, the methodology is a corpus-driven linguistic analysis combined with formal grammar engineering to build practical normalization modules for informal Korean text in e-learning contexts.
Technical innovations
- Classification and detailed typology of informal non-standard Korean word types in web documents, with empirical quantification.
- Application of Local Grammar Graphs (LGGs), finite-state automata modeling local syntactic/orthographic deviations, to Korean informal language normalization.
- Construction of LGGs using Unitex system to automatically map diverse non-standard tokens to standard counterparts.
- Demonstration that LGGs effectively handle phenomena such as missing spaces, abbreviations, deviant spellings, transliteration variants, and emoticons.
Datasets
- Corpus A (news articles): 10,488 tokens, 3,967 types — collected from Korean online social issue news sections (public).
- Corpus B (customer reviews): 10,608 tokens, 3,792 types — collected from web blogs reviewing cosmetic products (public).
Baselines vs proposed
- Standard Korean lexical analyzer (Geuljabi) non-analyzable rate for formal news corpus: 3.8% of word types vs informal web corpus: 27% of word types.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.29638.
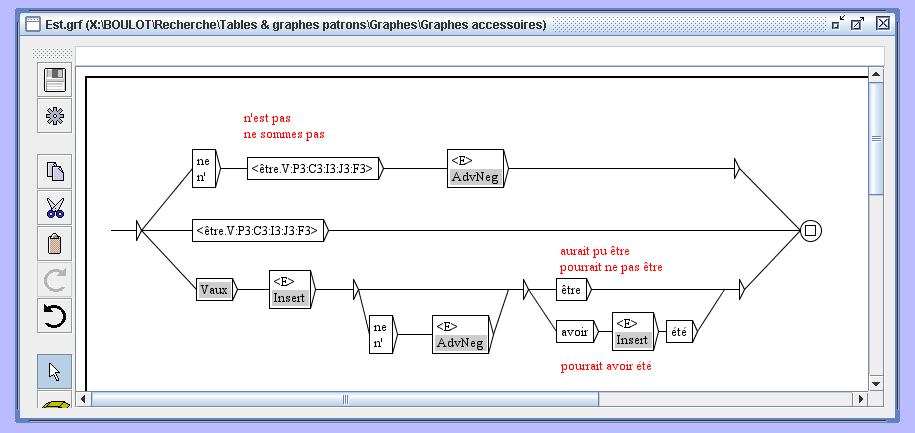
Fig 1 (page 5).
Fig 2 (page 6).
Fig 3 (page 6).
Fig 4 (page 6).
Fig 5 (page 6).
Fig 6 (page 6).
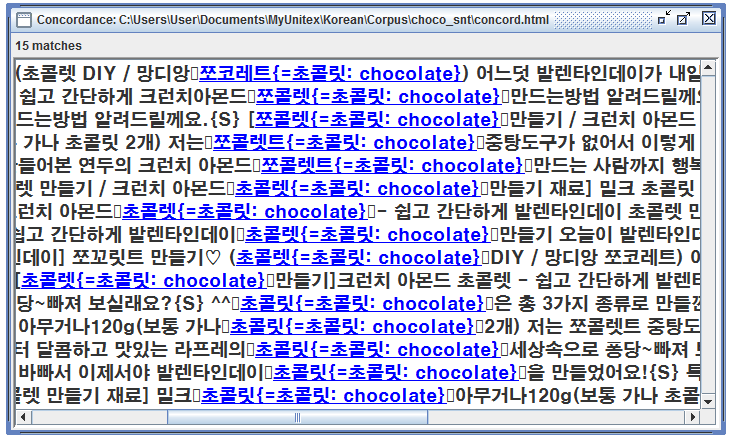
Fig 7 (page 7).
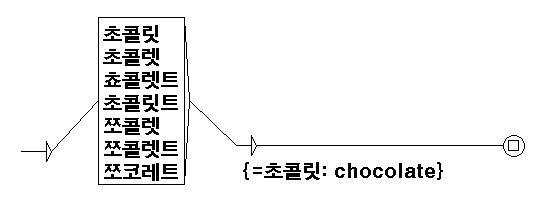
Fig 8 (page 7).
Limitations
- No formal evaluation metrics (e.g., normalization accuracy, impact on learner comprehension) were reported.
- Datasets are relatively small and narrowly domain-focused (social news, cosmetic reviews), limiting generalization.
- Analysis relies on dictionary coverage of Geuljabi; unknown proper nouns and typos might inflate non-analyzable counts in formal corpus.
- No adversarial or robustness testing against unseen slang or emerging neologisms was conducted.
- Reproducibility is limited; no release of LGG construction details, code, or processed corpora.
- The LGG approach requires manual rule engineering, which may not scale easily across domains or evolving language use.
Open questions / follow-ons
- How effective are LGG-based normalizations quantitatively in improving language learner comprehension or downstream NLP tasks?
- Can LGGs be extended or combined with statistical/machine learning methods for better scalability and adaptation to emerging slang?
- How well do the proposed LGGs generalize beyond the cosmetic review and news domains to other informal Korean texts like social media posts or chat messages?
- What is the user experience impact of integrating LGG normalization in an interactive e-learning platform for Korean learners?
Why it matters for bot defense
For bot-defense or CAPTCHA practitioners, this work provides insight on how informal language phenomena—especially in a morphologically rich language like Korean—pose challenges for text understanding and normalization. The classification and LGG formalism offer a framework to detect and systematically handle informal lexical variations that could otherwise confound language-based challenges or assessments. CAPTCHA systems targeting human linguistic knowledge might use such normalization layers to accept diverse valid user inputs or to better filter bot-generated text that fails to replicate realistic linguistic variation. Additionally, knowledge of the frequency and forms of these non-standard expressions can inform the design of more nuanced linguistic tests that distinguish between human language fluency and automated scripts. While this paper is not directly about bot detection, the underlying approach to formalizing informal language variation is conceptually valuable for natural language understanding components of bot-defense mechanisms.
Cite
@article{arxiv2605_29638,
title={ Classification of non-analyzable word types in web documents to implement an effective Korean e-learning system },
author={ Sang-Taek Park and Ae-Lim Ahn and Eric Laporte and Jee-Sun Nam },
journal={arXiv preprint arXiv:2605.29638},
year={ 2026 },
url={https://arxiv.org/abs/2605.29638}
}