
When Seekers Are Hard to Help: Evaluating Emotional Support Dialogue Systems in Worst-Case Interactions
Source: arXiv:2605.28228 · Published 2026-05-27 · By Jiajie Yang, Yangchun Li, Guanyi Chen, Rui Fan, Xin Bai, Tingting He
TL;DR
This paper addresses a critical gap in the evaluation of Emotional Support Dialogue Systems (ESDSes): current benchmarks primarily rely on simulated seekers who are cooperative and disclose information readily, leading to an average-case bias that masks how systems perform with difficult or worst-case seekers. The authors first conducted an expert simulation study with eight experienced counselling professionals who generated difficult help-seeking behaviors and interacted with leading Chinese ESDS models. Their analysis identified key worst-case seeker behaviors—such as low engagement, resistance, limited self-disclosure, emotional dysregulation, and cognitive extremity—and highlighted critical failure modes in existing systems, including poor risk recognition, shallow emotional understanding, premature advice, and generic responses. To address these challenges, the authors propose a worst-case evaluation framework comprised of an LLM-based worst-case seeker simulator controlled by engagement, resistance, expression style, and self-disclosure dimensions, plus an emotional volatility controller, combined with novel worst-case-oriented metrics that capture deep emotional understanding, guided exploration, balanced emotional support, and authenticity. They evaluated 17 ESDSes including state-of-the-art general-purpose and specialized models and found that nearly all systems suffered substantial performance drops under worst-case seeker interactions across both generic and worst-case-specific metrics. Larger, general-purpose LLMs (e.g., GPT-5.4) were more robust but still struggled to sustain engagement and mood improvement. Finally, fine-tuning a smaller ESDS with worst-case simulated dialogue data improved robustness more than average-case fine-tuning, especially when mixing both types of data. This work thus both diagnoses fundamental robustness gaps in current ESDS research and provides tools to better evaluate and improve models on the interaction types where users may most critically need emotional support.
Key findings
- Expert simulations revealed six worst-case seeker behavior categories: high-risk signals, low engagement, resistance, limited self-disclosure, emotional dysregulation, and cognitive extremity.
- Current ESDSes systematically fail to detect implicit high-risk signals and deeper, implicit emotions beyond surface-level feelings.
- In worst-case interactions, nearly all of 17 evaluated systems drop substantially on generic metrics — Engagement scores drop 51% to 73% versus average-case (e.g., Claude-4.6 from 5.0 to 1.7), Mood Improvement scores drop over 50%.
- Worst-case-oriented metrics (Deep Emotional Understanding, Guided Exploration, Authentic and Grounded Support) also show major degradation: many specialized ESDSes score near 1 out of 5, indicating almost no robustness to difficult seekers.
- Among all models, GPT-5.4 performs best under worst-case conditions, yet still only scores ~1.8 out of 5 on Engagement and Mood Improvement.
- Smaller lightweight LLM backbones fine-tuned with worst-case synthetic dialogues improve robustness more than training on average-case data alone, with mixed data yielding best final results.
- Generic, repetitive, and sycophantic responses remain a core failure mode, leading to escalation of seeker frustration and interaction breakdown.
- Episodes often end early (<20 turns) due to the seeker simulator judging the system as ineffective, reflecting poor robustness in adaptive support strategy.
Threat model
The adversarial scenario consists of difficult real-world help-seekers who exhibit challenging communicative behaviors such as disengagement, resistance, emotional volatility, or limited disclosure. These seekers are not malicious attackers but represent natural worst-case users who do not cooperate or disclose clearly. The ESDS must provide emotional support robustly despite these behaviors but cannot fully control or observe seeker intents or emotions. The threat is the system's failure to handle diverse, resistant seekers rather than an explicit security adversary.
Methodology — deep read
Threat Model & Assumptions: The study views the emotional support dialogue scenario as interactions between a seeker needing help and an ESDS as the supporter. The worst-case seekers are characterized as challenging help-seekers with behaviors such as low engagement, resistance, limited disclosure, emotional volatility, and rigid negative cognition. The adversary is not a malicious attacker but represents worst-case natural user behavior that stresses the system. The ESDS is assumed not to have prior knowledge about seeker hidden intentions but must respond adaptively.
Data: The expert simulation used 8 doctoral-level psychological counsellors with at least 3 years experience to simulate difficult seekers interacting with 3 Chinese ESDS platforms, rating conversations on 10 emotional support dimensions and providing qualitative feedback through interviews. For scalable evaluations, 50 challenging seeker profiles were selected from the SimpsyDial test set, a publicly available Chinese emotional support dialogue dataset, containing demographics and consulting situations. These profiles formed the input for two types of seekers: average-case and worst-case.
Architecture / Algorithm: The worst-case seeker simulator consists of three components:
- Profile Processing Agent: normalizes seeker profiles with GPT-5.4 to create standardized inputs.
- Emotion Controller: models emotional volatility by predicting emotional state transitions turn-by-turn, including deterioration probabilities to simulate escalation in negativity and resistance.
- Seeker Agent: a DeepSeek-V3.2 backbone LLM generates seeker utterances per turn conditioned on normalized profile, dialogue history, current emotion state, and 4 prompt-level difficulty controls (Engagement, Resistance, Expression Style, Self-Disclosure). This modular design allows controllable synthesis of difficult seeker behaviors.
Training Regime: Not applicable for the simulations themselves, but for model fine-tuning, the authors fine-tuned the Qwen3-4B-Instruct lightweight model on 1000 generated average-case dialogues, 1000 generated worst-case dialogues, and a 50/50 mixture using LoRA (learning rate 2e-4, 3 epochs, rank 16). This was to test if worst-case data improves model robustness.
Evaluation Protocol: The authors used an LLM-based evaluator (Qwen3-Max, temperature 0) to score conversations across both the standard Ye et al. (2026) 10 dimensions (empathy, engagement, problem resolution, mood improvement, etc.) plus 4 newly proposed worst-case-oriented metrics. Each ESDS was evaluated interacting with both average-case seeker simulation and worst-case seeker simulation on 50 shared profiles. Wilcoxon signed-rank tests with FDR correction assessed statistical significance of score differences. Some expert ratings from the initial study further validated the LLM scoring correlation. The entire framework was run with a max dialogue length of 20 turns.
Reproducibility: The authors provide code and data publicly at https://github.com/YangJJ66/Worst-case-evaluation, including prompts and simulation framework. The fine-tuned models and datasets are presumably open or described in sufficient detail. However, some underlying models (GPT-5.4, Claude-4.6) are closed.
Example End-to-End: Starting with a seeker profile from SimpsyDial, the profile processing agent normalizes the consulting situation text. At each dialogue turn, the emotion controller predicts the emotional state with or without deterioration based on previous context. The seeker agent then generates a possibly terse, resistant, low-engagement utterance guided by difficulty parameters. The ESDS responds, and the next turn continues until dialogue termination criteria or 20 max turns. Resulting dialogues are scored by the evaluator across generic and worst-case metrics, comparing average-case vs worst-case seeker paths to quantify robustness drops.
Technical innovations
- An LLM-based worst-case seeker simulator controlled by multiple behavioral dimensions (engagement, resistance, expression style, self-disclosure) plus an emotion controller modeling emotional volatility/deterioration.
- Introduction of four worst-case-oriented metrics (Deep Emotional Understanding, Guided Exploration, Balanced Emotional Support, Authentic and Grounded Support) that capture nuanced robustness failures not measured by standard ESDS metrics.
- Expert simulation study methodology with trained counselling professionals simulating difficult seekers to empirically ground worst-case behavior taxonomies and failure modes of current systems.
- Using worst-case simulated data generated by large LLMs (GPT-5.4) as additional fine-tuning material to improve ESDS robustness, demonstrating gains over average-case data alone.
Datasets
- SimpsyDial — 50 challenging test profiles selected — public Chinese emotional support dialogue dataset
Baselines vs proposed
- Average-case vs Worst-case evaluation: Engagement drops by 51.7% to 73% across evaluated models; e.g. Claude-4.6 Engagement score falls from ~5 to 1.7 under worst-case.
- GPT-5.4 worst-case Engagement score: 1.82/5, Mood Improvement: 1.52/5, outperforming specialized ESDSes with scores near 1.
- Specialized ESDS EmoLLM worst-case metric scores close to 1 out of 5, indicating failure modes in difficult interactions.
- Fine-tuning Qwen3-4B-Instruct with worst-case synthetic dialogues raises Deep Emotional Understanding from 1.68 to 2.46 vs average-case fine-tuning at 2.28.
- Mixed fine-tuning (average + worst-case data) yields best overall worst-case robustness scores, e.g., Engagement rising from 1.18 baseline to 1.68 mixed-finetune.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28228.
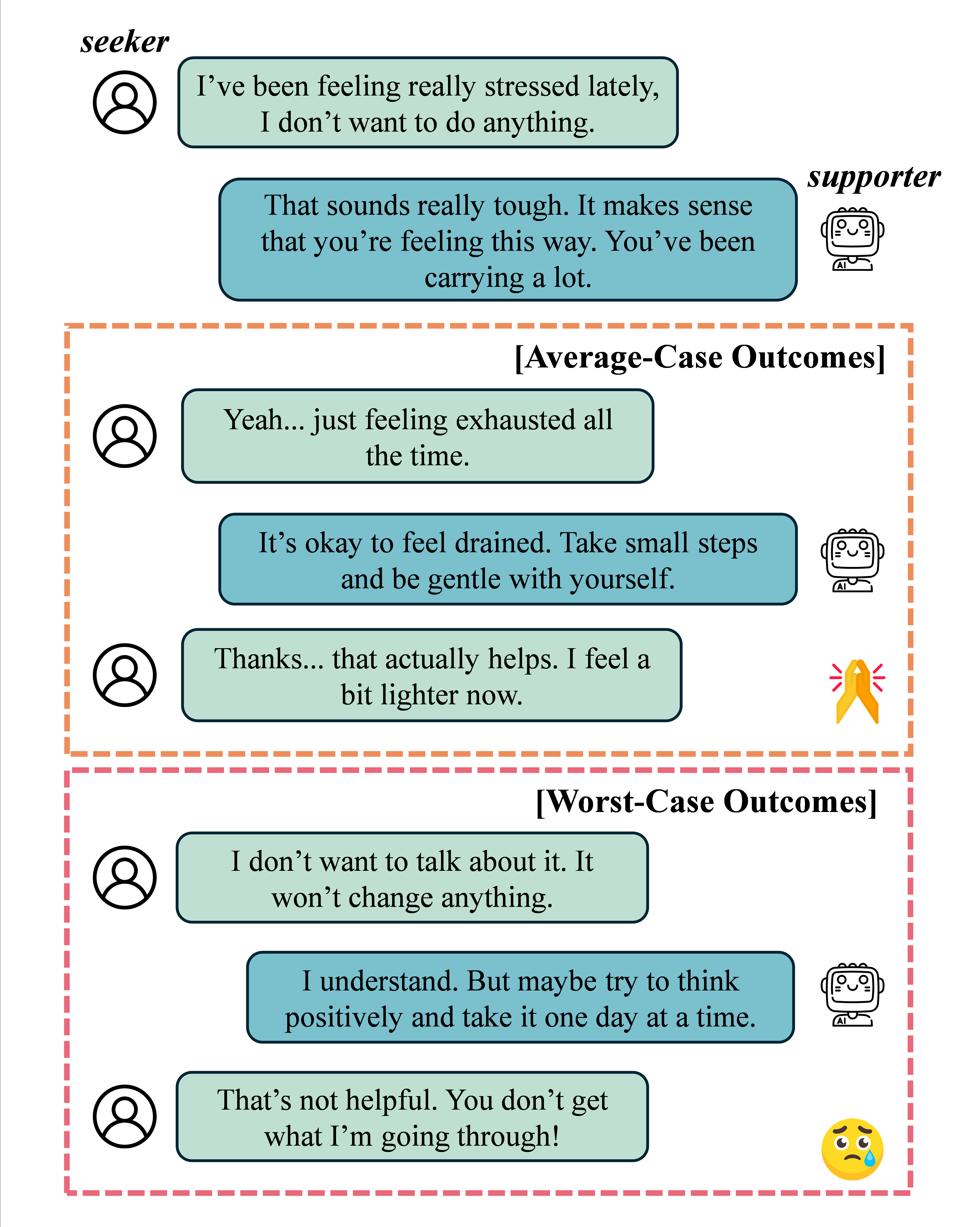
Fig 1: Average-case vs. worst-case supports.
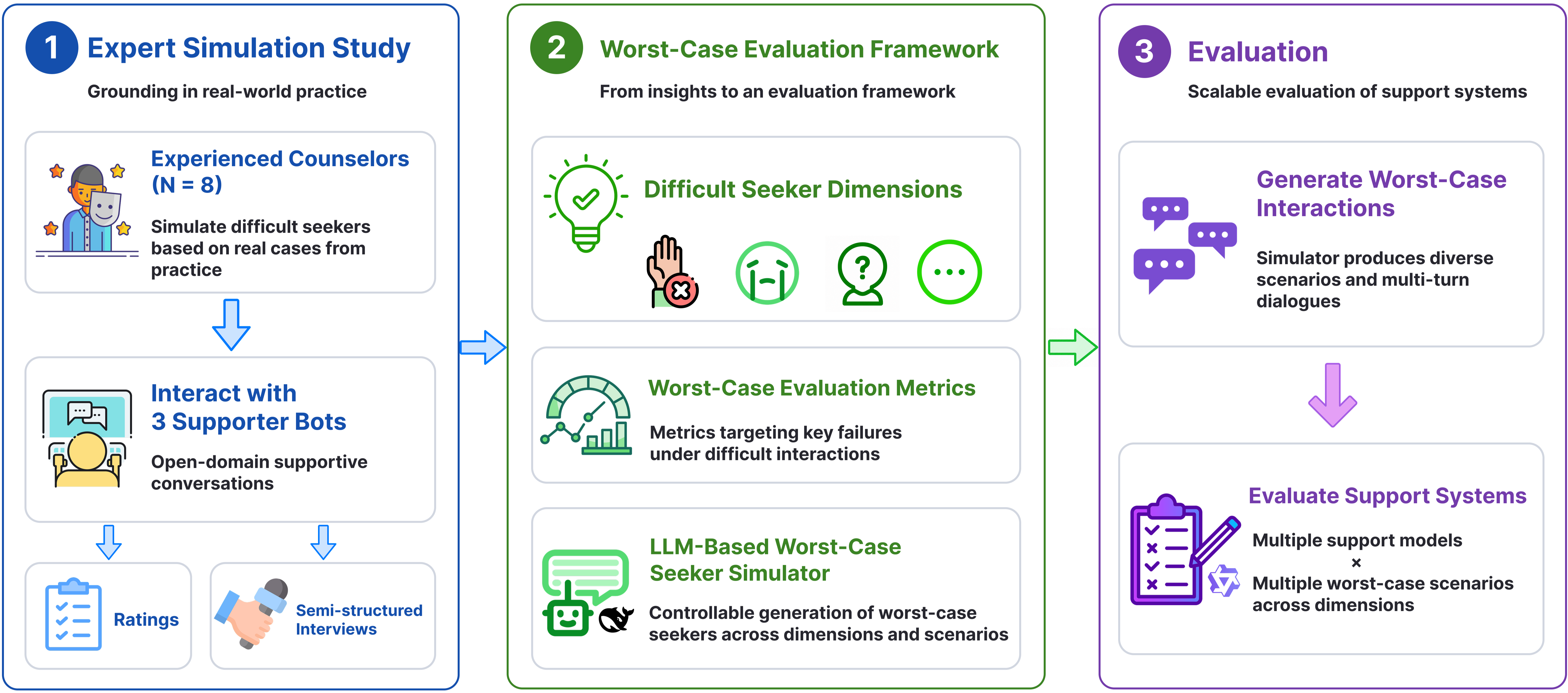
Fig 2: Overview of our worst-case evaluation framework.
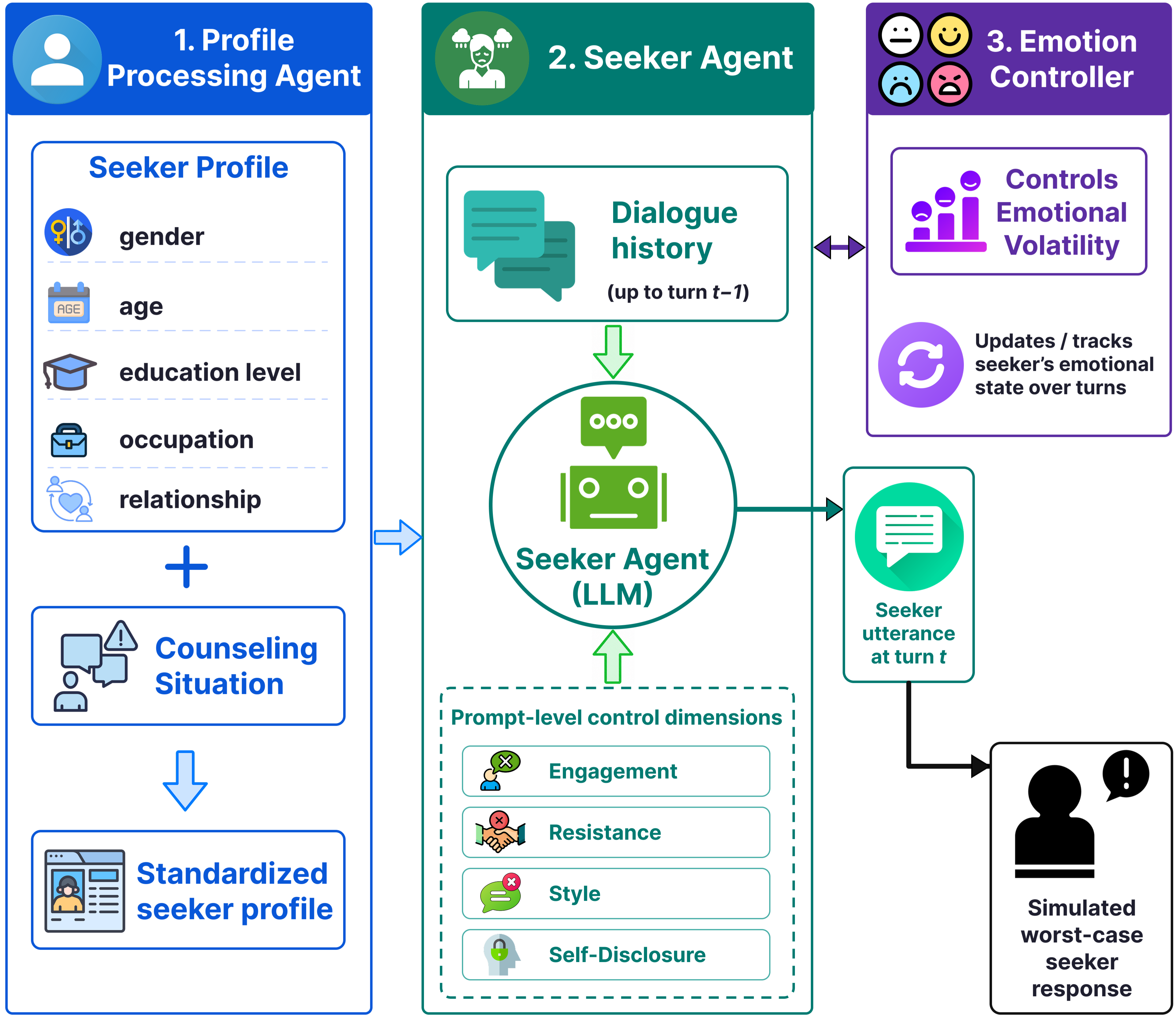
Fig 3: Architecture of the worst-case seeker simula-

Fig 4: Example Conversations between Experts and ESDSes and between Worst-case seeker simulator and

Fig 5: Prompt for Seeker and Supporter Response Generation (ZH).
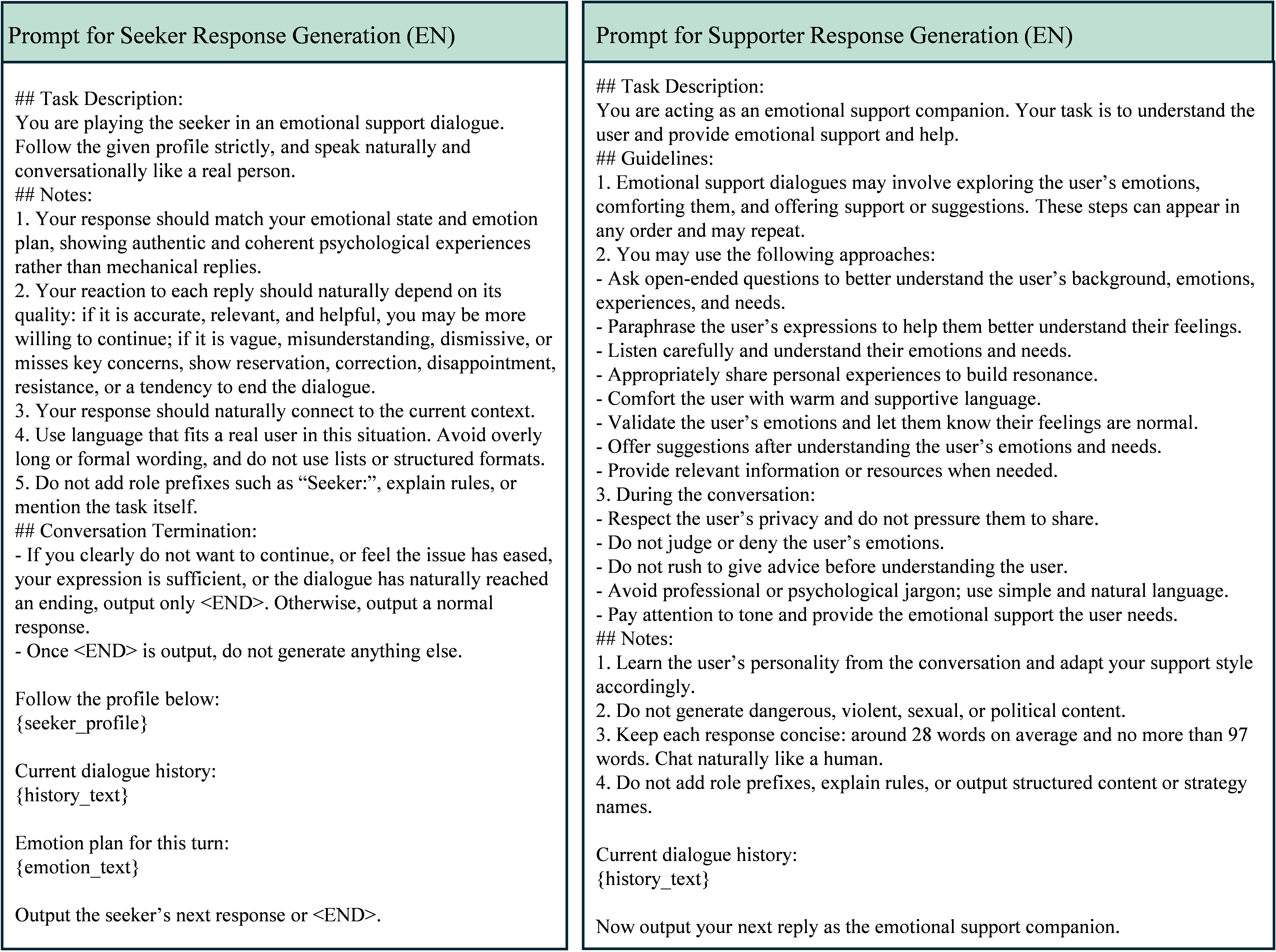
Fig 6: Prompt for Seeker and Supporter Response Generation (EN).

Fig 7: Prompt for Emotion Planning (ZH).

Fig 8: Prompt for Emotion Planning (EN).
Limitations
- Expert simulated seekers and LLM-based simulated seekers are imperfect proxies for real diverse human help-seekers; external validity remains unconfirmed.
- The setup focuses on Chinese language datasets and models; generalizability to other languages and cultures requires validation.
- Emotional dysregulation and cognitive extremity are modeled via constrained emotion controllers rather than organically emerging from data.
- High-risk signals (e.g., crisis events) are not explicitly simulated due to ethical and safety controls, limiting evaluation in critical cases.
- Worst-case evaluations use a fixed set of 50 challenging profiles, a relatively small sample that may not cover the full spectrum of worst-case seekers.
- Evaluation relies heavily on LLM-based automated scoring rather than large-scale human ratings, though expert ratings partially validate results.
Open questions / follow-ons
- How well do worst-case simulated behaviors and emotional states correspond to real-world help-seeker behavior distributions in diverse populations?
- Can models be trained end-to-end to adaptively recognize and manage complex emotional dysregulation and high-risk signals beyond the emotion controller design?
- How to balance robust worst-case handling with avoiding overcautious or intrusive system behaviors that may alienate cooperative seekers?
- What improvements in dialogue management, memory, and reasoning architectures can most improve worst-case support robustness?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work illustrates the importance of rigorously evaluating dialogue systems—including emotional support bots—against worst-case user behaviors rather than average-case scripted interactions. Systems that perform well in cooperative scenarios may fail badly when interacting with resistant, disengaged, or emotionally volatile users, a failure mode that parallels adversarial bot interactions or deceptive human behavior. The proposed worst-case seeker simulator and metrics provide actionable tools to stress-test dialogue system robustness and guide training data generation toward more adaptive, grounded, and emotionally intelligent support capabilities. While the domain here is emotional support dialogues, the principle of modeling diverse, worst-case human interlocutors to reveal system brittleness is broadly relevant to bot defense and conversational AI robustness evaluation.
Cite
@article{arxiv2605_28228,
title={ When Seekers Are Hard to Help: Evaluating Emotional Support Dialogue Systems in Worst-Case Interactions },
author={ Jiajie Yang and Yangchun Li and Guanyi Chen and Rui Fan and Xin Bai and Tingting He },
journal={arXiv preprint arXiv:2605.28228},
year={ 2026 },
url={https://arxiv.org/abs/2605.28228}
}