
VLMs May Not Globally Enhance Human Alignment over LLMs During Natural Reading
Source: arXiv:2605.28818 · Published 2026-05-27 · By Jinzhou Wu, Zhengwu Ma, Jixing Li, Baoping Tang, Zitong Lu
TL;DR
This paper investigates whether vision-language models (VLMs), pretrained on both visual and textual data, provide improved alignment with human neural and behavioral signals during natural reading, compared to large language models (LLMs) trained on text alone. The study directly compares three matched pairs of LLMs and VLMs processing identical text-only inputs to isolate the effect of multimodal training history from real-time visual processing or cross-modal fusion. Using a natural reading dataset containing synchronized whole-cortex fMRI and eye-tracking measurements from 52 human readers, the authors measure model alignment to brain activity and regressive eye movements.
The key finding is that multimodal pretraining does not confer a stable global advantage in neural alignment during natural reading, as measured by fMRI prediction accuracy. However, VLMs show selective gains in alignment with both brain responses and regressive eye movements during reading of sentences with higher "visual semantic strength." This content-dependent advantage was observed in two of the three matched model pairs. The study thus argues that the core neural computations during natural reading rely mainly on language-internal representations captured by LLMs, while visual grounding from multimodal training provides a selective, context-dependent enhancement for visually evocative language.
Key findings
- Both LLMs and VLMs reliably predicted fMRI BOLD responses in bilateral temporal-parietal language-related cortical regions (Fig 2).
- No consistent global fMRI alignment advantage was found for VLMs over matched LLMs across three model pairs; mean layer differences were small and non-significant.
- VLMs Qwen2-VL-7B and DeepSeek-VL-7B showed significant improvement over their LLM counterparts in predicting regressive saccades (p=0.0072, p=0.0020), whereas the Mistral/Idefics2 pair did not (p=0.1711).
- Visual semantic strength of sentences (based on Lancaster Sensorimotor Norms) modulated the VLM advantage: The VLM–LLM fMRI alignment difference was significantly larger for high-visual-strength sentences in the Qwen2 and DeepSeek pairs (p=0.0099, p=0.0139) but not Mistral/Idefics2.
- Selective VLM alignment gains localized to lateral temporal and inferior parietal cortex associated with semantic and multimodal integration (Fig 4).
- Attention features extracted from lower-triangular self-attention matrices of models better captured regressive fixation transitions than linear embedding features.
- Matched model comparison using strictly text-only inputs controlled for architectural and input differences, isolating multimodal pretraining effects.
- The Mistral/Idefics2 pair, less tightly matched architecturally, showed weaker or no VLM advantage, highlighting model-dependence of effects.
Methodology — deep read
Threat model & assumptions: The study does not target adversarial security threats but rather examines whether visual grounding during pretraining improves alignment with human brain and behavioral data. The key assumption is that any difference between tightly matched LLM/VLM pairs processing identical text-only inputs reflects the effect of multimodal pretraining history, independent of online visual input or fusion.
Data: They used the openly available Reading Brain dataset (OpenNeuro), comprising concurrent whole-cortex fMRI and eye-tracking recordings from 52 adult native English speakers reading 148 sentences from 5 STEM articles one sentence at a time in the MRI scanner.
Model architecture & algorithm: Three matched pairs of LLMs and VLMs were evaluated: Qwen2-7B vs Qwen2-VL-7B, DeepSeek-LLM-7B vs DeepSeek-VL-7B, and Mistral-7B-v0.1 vs Idefics2-8B-base. Qwen2 and DeepSeek pairs had the same language backbone and similar attention/layer configurations; Mistral/Idefics2 was a cross-architecture comparison. VLMs had multimodal pretraining with paired text-image data but were run in text-only mode for evaluation with no visual inputs.
For each text input sentence, they extracted word-level self-attention matrices from the language model's transformer layers by aggregating subword tokens to words, isolating the strict lower triangle that reflects attention from later to earlier words (capturing regressive dependencies).
Training regime: All models were pretrained independently before this evaluation; no instruction tuning or fine-tuning was applied for the experiment. Details of training datasets and optimization are from referenced sources and some Appendix material.
Evaluation protocol: Model-to-brain alignment was assessed by ridge regression predicting fMRI BOLD responses linked to regressive fixations, at 5-second hemodynamic lag, using leave-one-article-out cross-validation. Prediction accuracy was Pearson correlation (r) between predicted and observed signals, summarized over the cortex.
Model-to-behavior alignment was tested by predicting human regressive saccade counts from model attention features with participant-specific ridge regression. Normalized R2 (explained variance) was calculated relative to a noise ceiling.
Paired statistical tests (paired t-tests or permutation tests with FDR correction) compared each VLM to its matched LLM at the subject level for both fMRI and eye-tracking alignments. They conducted a key conditional analysis testing whether the VLM advantage depended on the visual semantic strength of sentences, computed from Lancaster Sensorimotor Norms lexicon scores.
- Reproducibility: The natural reading dataset is publicly available; model weights and code release are not stated explicitly but rely on publicly referenced LLM/VLM families. Implementation and preprocessing details are described in appendices but seem sufficient to reproduce given public resources.
Concrete example end-to-end: A participant reads a sentence inside an fMRI scanner with concurrent eye-tracking. The sentence is passed through matched LLM and VLM (in text-only mode), extracting word-level self-attention matrices per transformer layer. The strict lower-triangle attention vector per sentence is concatenated across stimuli. Ridge regression predicts that participant's BOLD response at each cortical vertex linked to regressive fixations. Separate ridge regression predicts participant's regressive saccade counts. These predicted mappings are correlated with observed data and normalized to noise ceilings. Finally, the performance of VLM and LLM are compared for significance and effect size, both overall and conditioned on sentence visual semantic strength.
Technical innovations
- Use of tightly matched LLM/VLM pairs evaluated in strictly text-only mode to isolate effects of multimodal pretraining from online visual stimuli or fusion.
- Extraction of lower-triangular self-attention matrices as word-pair features to model regressive eye-movements and fixation-linked fMRI BOLD responses.
- Visual semantic strength conditioning of model alignment analysis using Lancaster Sensorimotor Norm norms combined with calibrated LLM-based scoring for low-coverage texts.
- Use of leave-one-article-out cross-validation for both fMRI and eye-movement regression with paired statistical comparison across participant-level cortical maps.
Datasets
- Reading Brain dataset — 52 subjects, 148 sentences from 5 English STEM articles — OpenNeuro public natural reading fMRI and eye-tracking dataset
Baselines vs proposed
- Qwen2-7B (LLM): normalized regressive saccade R2 < Qwen2-VL-7B (VLM): significant improvement with p=0.0072
- DeepSeek-LLM-7B: normalized regressive saccade R2 < DeepSeek-VL-7B: significant improvement with p=0.0020
- Mistral-7B-v0.1: normalized regressive saccade R2 ≈ Idefics2-8B-base (VLM): no significant difference (p=0.1711)
- Global fMRI prediction correlation (r) for VLM vs LLM pairs showed small, non-significant differences; no stable global advantage for VLMs
- Visual-strength conditioned fMRI alignment difference (VLM minus LLM) significantly positive for Qwen2 and DeepSeek pairs (p=0.0099, p=0.0139), not for Mistral/Idefics2
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28818.
Fig 1: Overview of the matched LLM/VLM alignment pipeline. (a) Data acquisition. Participants read sentences
Fig 2: Global fMRI alignment of different LLM–VLM pairs. Significant brain clusters from the single-model-
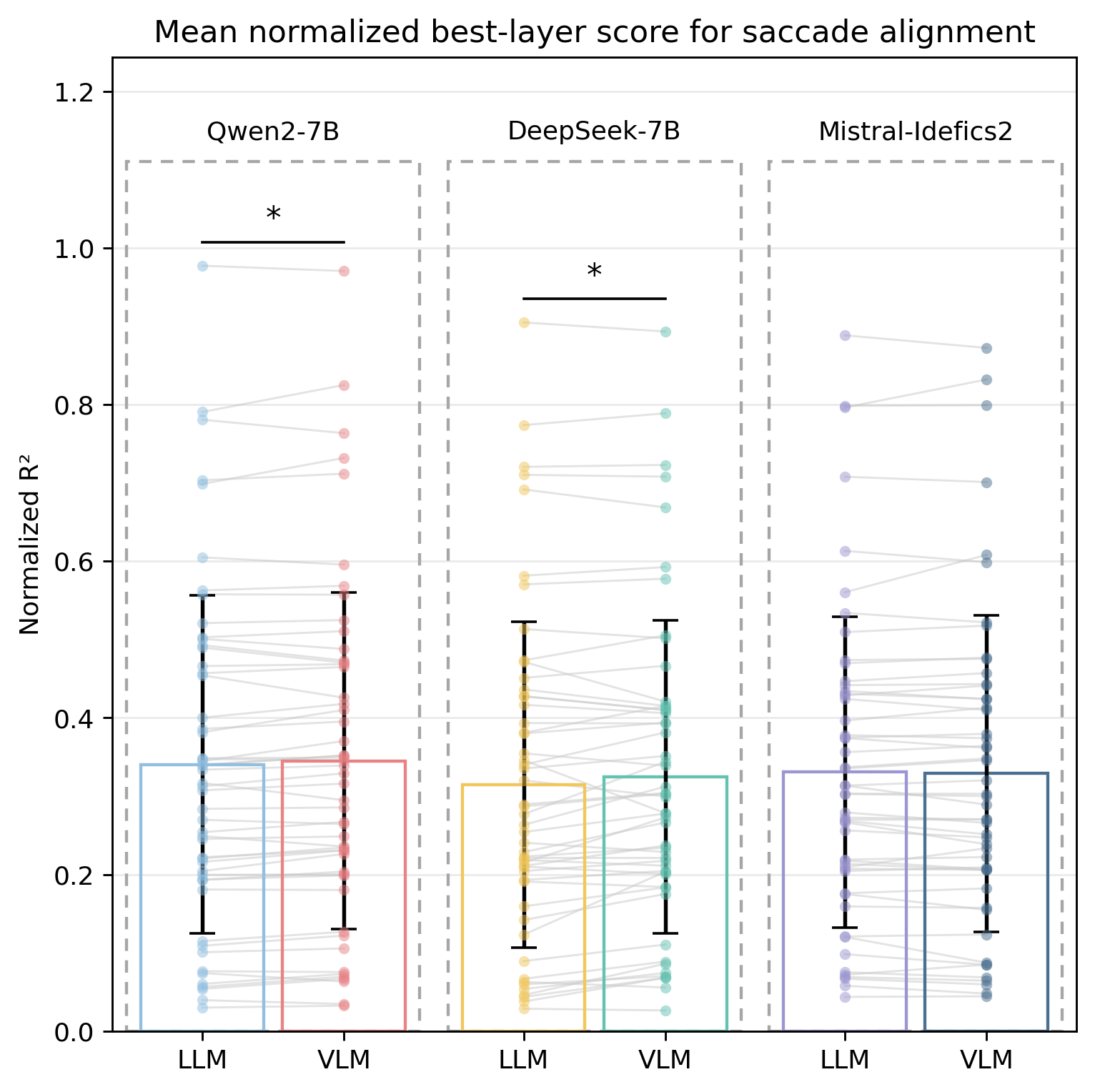
Fig 3: Eye-movement alignment for regressive sac-
Fig 4: Visual strength modulation of VLM–LLM alignment across matched model pairs. (a) Mean advantage in
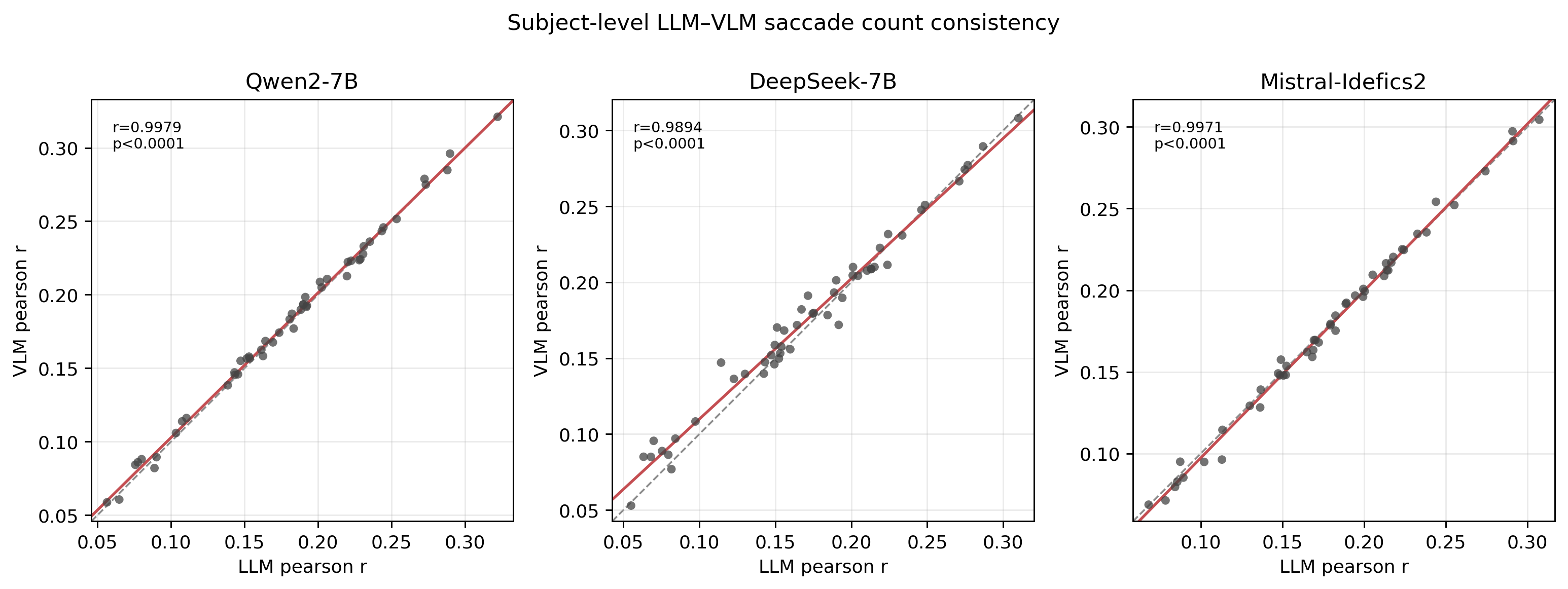
Fig 5: Subject-level LLM–VLM consistency for eye-movement alignment. Each point represents one participant;
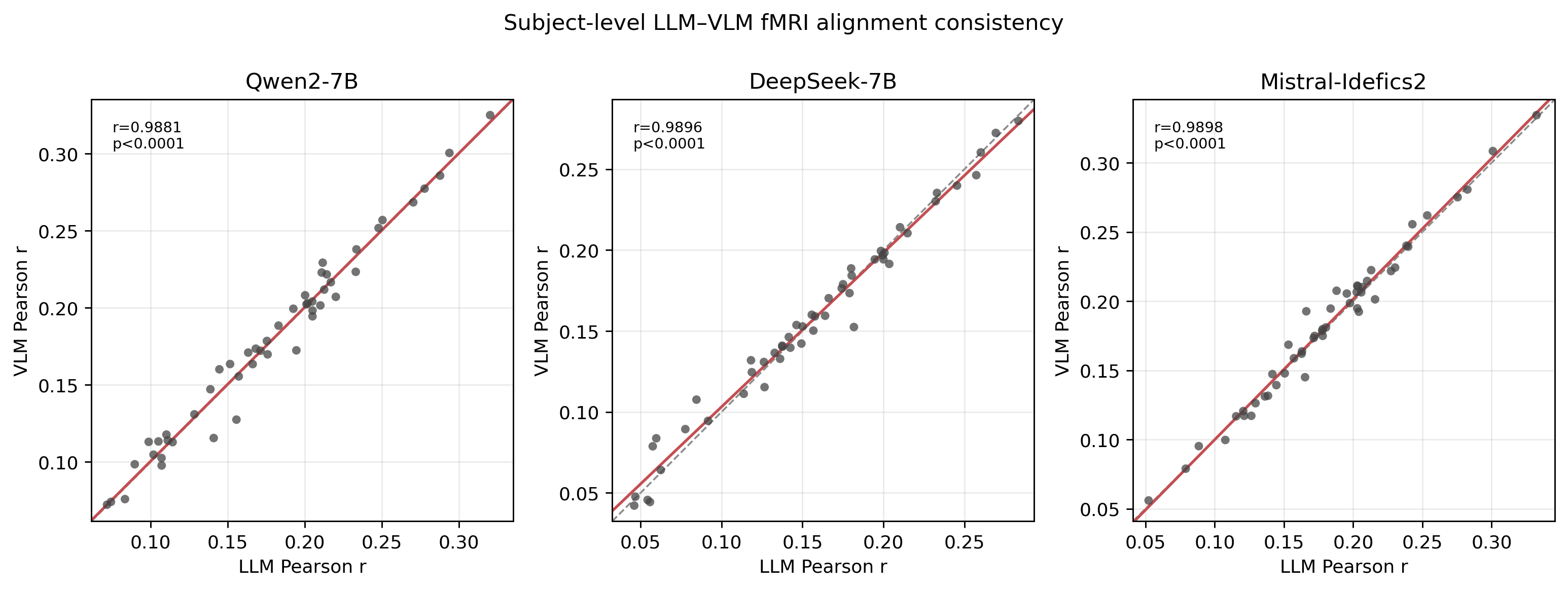
Fig 6: Subject-level LLM–VLM consistency for fMRI alignment. Format follows Figure 5.
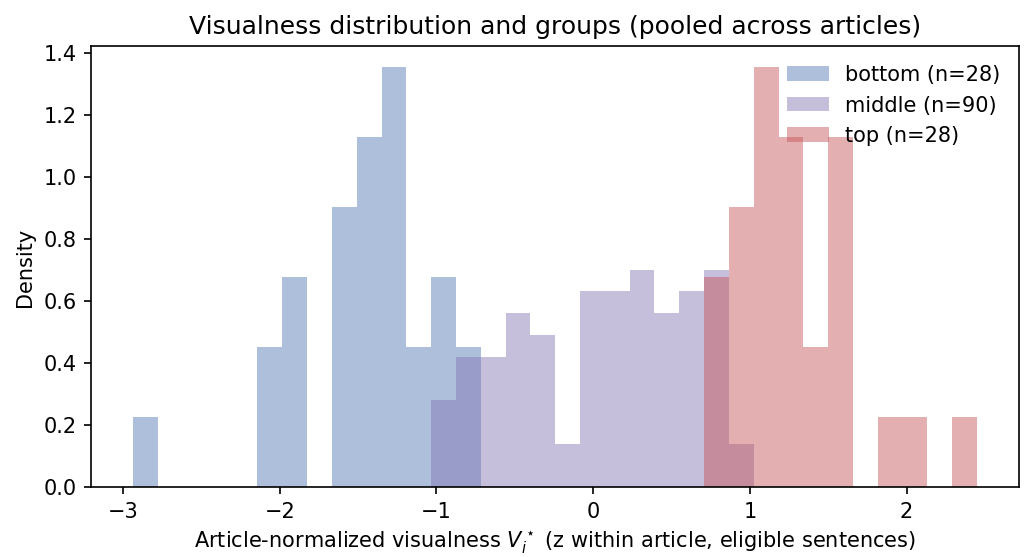
Fig 7: Distribution of sentence-level visual strength
Limitations
- Perfect causal isolation of multimodal pretraining is not possible as matched model pairs can still differ in training data scale, optimization, architecture details.
- Strictly text-only evaluation excludes real-time dynamic visual context that humans experience during natural language comprehension.
- Use of lower-triangular attention features limits the scope of neural/behavioral alignment analysis; other model representations or features might reveal different effects.
- Sentence-level visual semantic strength is approximated from lexicon-based norms and calibrated scores; may incompletely capture visual grounding complexity.
- Eye-movement alignment advantages were model-dependent and absent in one model pair, limiting generalizability.
- Absence of stable global VLM-fMRI advantage could be influenced by differences in model training or architecture unrelated to multimodality.
Open questions / follow-ons
- How do real-time dynamic multimodal interactions during natural language processing affect model-human alignment beyond text-only evaluations?
- Can alternative model features beyond lower-triangular self-attention better capture neural and behavioral correlates of natural reading and visual grounding?
- How do different types of multimodal pretraining (e.g., scale, modality balance, objective functions) influence selective improvements in human alignment?
- What are the neural mechanisms underlying selective lateral temporal and inferior parietal engagement during visually grounded language comprehension?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners interested in leveraging language models to understand or predict human reading and comprehension behavior, this study highlights important limitations and conditions under which multimodal pretrained models better approximate human processes. Specifically, VLMs do not universally outperform text-only LLMs in modeling brain responses during natural reading, but their advantage is context-dependent, emerging primarily when the language contains strong visual semantic content. This suggests caution in assuming that multimodal training confers broadly enhanced human-like language understanding or behavior prediction.
From an alignment perspective, understanding which semantic contexts induce selective VLM advantages may guide the design of behavioral or neural features that distinguish human-like natural language processing from automated or adversarial reading patterns. The methodology of matched text-only comparisons controlling for architectural confounds also informs evaluation frameworks for model interpretability and alignment relevant to CAPTCHA systems that need to differentiate humans from bots based on nuanced language understanding or eye-movement behaviors.
Cite
@article{arxiv2605_28818,
title={ VLMs May Not Globally Enhance Human Alignment over LLMs During Natural Reading },
author={ Jinzhou Wu and Zhengwu Ma and Jixing Li and Baoping Tang and Zitong Lu },
journal={arXiv preprint arXiv:2605.28818},
year={ 2026 },
url={https://arxiv.org/abs/2605.28818}
}