
Skill-Conditioned Gated Self-Distillation for LLM Reasoning
Source: arXiv:2605.28791 · Published 2026-05-27 · By Jiazhen Huang, Xiao Chen, Xiao Luo, Yong Dai, Senkang Hu, Yuzhi Zhao
TL;DR
This paper addresses the challenge of improving large language model (LLM) reasoning through on-policy self-distillation (SD) with weaker privileged information (PI). Existing SD methods rely on trusted PI such as reference answers or successful traces, but this work explores using experience-derived skill banks as PI. Skills are compact, reusable abstractions extracted from prior trajectories but may be partially relevant or even misleading for new problems. The authors propose Skill-Conditioned Gated Self-Distillation (SGSD), which treats skill-conditioned teachers as hypotheses validated by rollout outcomes rather than unconditional authorities to imitate. SGSD jointly considers multiple skill–mistake pairs as separate teacher contexts that score the same student rollout, infers the polarity of teacher support relative to verifier outcomes, and distills informative teacher-student disagreements via a gated, robust objective that suppresses uncertain or extreme signals.
Empirical results on multiple mathematical reasoning benchmarks (AIME24, AIME25, HMMT25) using Qwen3 models demonstrate that SGSD significantly improves over RLVR baseline GRPO and remains competitive with answer-conditioned OPSD that has stronger PI assumptions. For instance, on Qwen3-1.7B, SGSD raises average accuracy from 37.4% baseline to 43.7%, outperforming GRPO by 6.2% and OPSD by 1.7%. Ablations show the importance of teacher polarity, multi-teacher diversity, and robust support estimation components. SGSD stabilizes learning better than OPSD, which degrades mid-training. This work thus establishes skill-conditioned self-distillation as a viable approach to internalize reusable reasoning principles under weaker supervision from verifier feedback.
Key findings
- SGSD on Qwen3-1.7B improves average accuracy across AIME24, AIME25, and HMMT25 from 37.4% baseline to 43.7%, exceeding GRPO by 6.2% and OPSD by 1.7%.
- SGSD remains competitive with answer-conditioned OPSD despite assuming weaker privileged information (skills instead of full reference answers).
- Skill injection alone (Base+Skill, GRPO+Skill, OPSD+Skill) does not improve performance, demonstrating that naive exposure to skills is insufficient.
- Removing teacher polarity in SGSD causes late-stage training collapse and performance degradation below base model.
- Using a multi-teacher pool of diverse skill–mistake pairs outperforms a single teacher, highlighting the importance of diverse hypotheses.
- Robust support estimation components (token masking, log probability gap clipping, polarity thresholding) improve training stability and final accuracy; their removal reduces gains or causes collapse.
- Full-vocabulary distillation outperforms truncated Top-100 token support approaches for calculating gradients in SGSD, suggesting tail probabilities aid polarity calibration.
- Synchronizing the teacher policy with the student (live teacher) provides stronger and more stable training signals than frozen or EMA teacher variants.
Threat model
The adversary is not explicitly modeled as malicious but the core challenge is that the privileged information—retrieved skill–mistake pairs—is noisy, partially relevant, or potentially misleading for distillation. The system cannot assume that the skills are always trustworthy or perfectly aligned with the current problem instance. The verifier outcome is assumed to be reliable and authoritative to validate teacher hypotheses. The adversary cannot manipulate verifier outputs or training data.
Methodology — deep read
The threat model assumes an adversary that cannot interfere with training data or verifier outcomes; rather the main challenge is that retrieved skills may be partially relevant, irrelevant, or misleading as privileged information for distillation.
Data: Training uses the English subset of DAPO-Math-17K, with evaluations on out-of-domain competition math problem sets AIME24, AIME25, HMMT25. A cold-start skill bank is constructed by sampling 256 in-domain problems, generating solution traces, and extracting reusable general skills (positive principles) and common mistakes (negative patterns) summarized from successful and failed trajectories.
Architecture/algorithm: SGSD uses a single LLM policy π_θ playing dual roles as student and multiple skill-conditioned teachers. For each problem x, top-K skill–mistake pairs are semantically retrieved from the skill bank. Each teacher’s context is built by concatenating the skill, mistake, and problem prompt.
The student samples a rollout y under plain prompt p_S(·|x). A verifier assigns a binary outcome r ∈ {−1, 1} indicating solution correctness. Each teacher scores the fixed rollout generating token probabilities p_T^(k)(·|c_k(x), y_<t). The token-level log-probability gaps Δ_t^(k) = log p_T^(k)(y_t) - log p_S(y_t) measure teacher support or suppression.
Teacher polarity ρ_k is derived by validating support direction conditioned on rollout success: a teacher supporting success or suppressing failure is helpful (ρ_k = +1), otherwise misleading (ρ_k = -1). A robust support score e a_k is computed by masking out non-reasoning tokens and clipping Δ_t^(k) to remove outliers, with a threshold to ignore uncertain teachers.
The distillation loss is a weighted sum over teachers and tokens of a gated function ℓ_gate(Δ) that grows for moderate disagreement but saturates for extremes to remain stable. Weights combine semantic retrieval confidence, polarity ρ_k, and token masks.
Training uses 200 gradient steps, batch size unspecified but minibatched over problems. The teacher is a stop-gradient copy of the student synchronized online. The skill bank dynamically updates at intervals by merging newly extracted skills and mistakes from recent rollouts, pruning for compactness.
Evaluation is an average of accuracy over the three math benchmarks measured every 25 steps, reporting best checkpoint. Baselines include GRPO (RL with sparse environment rewards) and OPSD (on-policy self-distillation conditioned on ground-truth answers). Ablations test components such as polarity, multi-teacher pool, support estimation, and loss variants.
Reproducibility: code and model details are publicly released at https://github.com/walawalagoose/SGSD. Datasets are publicly available benchmarks. Exact training hyperparameters like batch size or seed are not detailed in the excerpt. The skill bank construction and update processes, along with prompt templates, are included in appendices.
Example: On one math problem x, student model samples a rollout y with only plain prompt. The verifier returns r=+1 for success. Retrieve top-K skill–mistake pairs {(g_k,e_k)} and form teacher contexts c_k = g_k ⊕ e_k ⊕ x. Each teacher scores the fixed y producing p_T^(k). Compute per-token gaps Δ_t^(k). Aggregate into robust support e a_k and infer polarity ρ_k = +1 if teacher supports success. Calculate gated loss ℓ_gate(Δ_t^(k)) weighted by polarity, assign gradients to student model parameters to reinforce helpful teacher signals and suppress misleading ones. Iterate this over minibatch and update parameters and skill bank online.
Technical innovations
- Formulating skill-conditioned self-distillation as a teacher hypothesis validation problem where multiple retrieved skill–mistake pairs produce competing, polarity-validated teacher signals instead of unconditional imitation.
- Designing a robust gated distillation loss that saturates on extreme teacher-student disagreements and ignores uncertain teacher polarity, stabilizing learning.
- Constructing a multi-teacher pool by pairing retrieved general skills with mistake patterns, enabling balanced positive and negative teacher guidance.
- Introducing an outcome-validated teacher polarity metric that reverses supervision direction when teacher support conflicts with verifier outcome.
- Dynamically maintaining and updating a structured skill bank online from recent successful and failed student rollouts.
Datasets
- DAPO-Math-17K English subset — size unspecified — public training data for mathematical reasoning
- AIME24 — size unspecified — public math competition benchmark
- AIME25 — size unspecified — public math competition benchmark
- HMMT25 — size unspecified — public math competition benchmark
Baselines vs proposed
- GRPO: avg@12 accuracy = 37.5% (Qwen3-1.7B) vs SGSD: 43.7%
- OPSD: avg@12 accuracy = 42.0% (Qwen3-1.7B) vs SGSD: 43.7%
- GRPO+Skill: 39.0% (Qwen3-1.7B) vs SGSD: 43.7%
- OPSD+Skill: 40.6% (Qwen3-1.7B) vs SGSD: 43.7%
- Base model: 37.4% (Qwen3-1.7B) vs SGSD: 43.7%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28791.

Fig 1: Overview of SGSD. The student samples a rollout from the plain problem, while retrieved skill–mistake

Fig 2 (page 3).

Fig 3 (page 3).

Fig 4 (page 3).

Fig 5 (page 3).

Fig 6 (page 3).

Fig 7 (page 3).
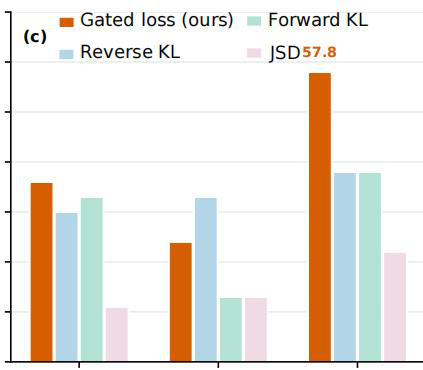
Fig 3: Further discussions on Qwen3-1.7B. (a) Full-vocabulary distillation consistently outperforms Top-100
Limitations
- Evaluation restricted primarily to mathematical reasoning tasks with automatic binary answer verification, limiting generalization to open-ended tasks.
- Skill bank construction relies on a cold-start extraction and static pairing; more adaptive retrieval and weighting strategies are not explored but may enhance performance.
- Experiments mainly report best checkpoints rather than full held-out validation or generalization over model seeds.
- Ablations and detailed analysis focus mostly on the smallest Qwen3-1.7B model; less is known about scaling behavior or hyperparameter sensitivity on larger models.
- The approach assumes a reliable verifier outcome signal, which may not be available or accurate in less structured reasoning domains.
- Potential reliance on quality and coverage of skill bank contents; stale or biased skill summaries could mislead training.
Open questions / follow-ons
- How to extend SGSD to open-ended generation tasks where verifier outcomes may be unavailable or less structured?
- Can more sophisticated retrieval, pairing, or weighting of skills improve multi-teacher pool quality and distillation effectiveness?
- What is the impact of skill bank size, diversity, and update frequency on training stability and final reasoning performance?
- How does SGSD scale with larger LLMs and more complex reasoning domains beyond mathematical benchmarks?
Why it matters for bot defense
For bot-defense or CAPTCHA engineering, SGSD presents an interesting paradigm for strengthening LLM reasoning robustness using weak privileged information derived from prior experience rather than relying on ground-truth labels. This insight could inspire systems that incorporate reusable, compact skill abstractions to validate or gate generated outputs based on partial recall, improving interpretability and adaptability under scarce supervision.
The teacher polarity and gated loss approach offers a mechanism to selectively learn from model internal feedback, potentially useful for bot behavior modeling or anomaly detection where noisy signals must be filtered adaptively. The multi-teacher hypothesis validation idea suggests architectures where multiple knowledge sources jointly endorse or contradict outputs, helping detect unreliable or adversarially generated reasoning traces. However, deployment would require reliable verifier signals, which might not be straightforward for CAPTCHA tasks with open-ended user inputs. Still, skill-conditioned self-distillation could provide more robust token-level supervision for LLM-based bot detection or challenge generation pipelines.
Cite
@article{arxiv2605_28791,
title={ Skill-Conditioned Gated Self-Distillation for LLM Reasoning },
author={ Jiazhen Huang and Xiao Chen and Xiao Luo and Yong Dai and Senkang Hu and Yuzhi Zhao },
journal={arXiv preprint arXiv:2605.28791},
year={ 2026 },
url={https://arxiv.org/abs/2605.28791}
}