
Self-Prophetic Decoding to Unlock Visual Search in LVLMs
Source: arXiv:2605.28741 · Published 2026-05-27 · By Zhendong He, Qiyuan Dai, Guanbin Li, Liang Lin, Sibei Yang
TL;DR
This paper addresses critical challenges in enabling effective visual search within Large Vision-Language Models (LVLMs), which are integral to the multimodal thinking-with-images paradigm. The authors identify two key problems in current visual search LVLMs: incompatibility and deterioration of intrinsic single-step capabilities after specialized post-training, and interference that accumulates across long multi-step reasoning contexts, leading to degraded task performance. To overcome these, they propose a novel framework called Self-Prophetic Decoding (SeProD) that tightly couples a post-training LVLM (the search model) with its pre-training counterpart (the prophet model), leveraging the latter's intrinsic single-step capabilities to dynamically guide the reasoning in the former. Unlike naive prompting or external tool augmentation, their method uses a probability-based interface—prophetic sampling—that selectively accepts tokens from the pre-training model only if they align probabilistically with the search model’s native distribution. This enables a seamless, training-free, plug-and-play decoding process that preserves coherence over multiple reasoning steps without additional inference overhead.
Empirically, SeProD consistently improves visual search accuracy across all 12 splits of 4 high-resolution visual search benchmarks (VisualProbe, V* Bench, HR-Bench) and general VQA datasets, with gains ranging approximately from 1% to 5% absolute over three strong LVLM baselines, including Mini-o3 and DeepEyes. The improvements are especially significant on challenging, long-horizon reasoning tasks and fine-grained spatial perception scenarios, demonstrating SeProD’s ability to mitigate capacity degradation and multi-step interference effectively. Their parallel prefix acceptance mechanism maintains decoding speed and coherence, presenting a principled alternative to prior methods that either sacrifice intrinsic capabilities or induce reasoning fragmentations.
Key findings
- Visual-search post-training reduces intrinsic single-step capabilities, dropping grounding by 49.3%, OCR by 2.3%, spatial understanding by 10.9%, and counting by 3.0% (Fig. 2a).
- Interference accumulates in long multi-step reasoning, with masking irrelevant context recovering accuracy by +5.56% to +5.66% on VisualProbe test splits (Fig. 2b).
- SeProD’s probability-based prophetic decoding preserves output consistency with the original LVLM distribution, enabling coherent multi-step reasoning (Fig. 2c).
- Across VisualProbe test subsets, SeProD improves baseline accuracies by up to +3.5% (DeepEyes hard set) and +3.3% (Mini-o3 hard set) (Table 1).
- On V* Bench and HR-Bench (4K and 8K), SeProD improves accuracy by +1.0% to +4.4% over various baselines without external tools (Table 1).
- SeProD yields gains on several general VQA benchmarks (MME-RealWorld, ScienceQA, OCRBench, CVBench), verifying transfer beyond visual search (details in appendix).
- Self-prophetic decoding is training-free and uses a parallel token acceptance algorithm, adding no extra latency compared to baseline inference.
- SeProD’s interaction mechanism dynamically steers the prophet’s focus and uses a balancing factor α to weigh likelihoods from both models, preserving robustness to token rank.
Methodology — deep read
Threat Model & Assumptions: The adversary scenario is not explicitly defined as this is primarily a modeling and inference framework for LVLM visual search. Implicitly, the method assumes standard inference-time conditions without adversarial model attacks or malicious inputs. The focus is on improving multi-turn decoding robustness by leveraging pre- and post-training LVLM models.
Data: The approach is evaluated on multiple publicly known visual search and VQA benchmarks including VisualProbe test, V* Bench, HR-Bench (4K and 8K), MME-RealWorld, ScienceQA, OCRBench, and CVBench. These datasets vary in size and challenge but involve high-resolution images and complex multi-step reasoning tasks requiring fine-grained localization, OCR, counting, and spatial understanding. Specific splits and evaluation protocols match prior works cited. Data preprocessing is minimal since the method operates at the decoding level.
Architecture / Algorithm: Two LVLM instances form a pair: the post-training model (search model) equipped with visual search training, and its pre-training base version (prophet model) with intact single-step capabilities. The search model performs multi-turn reasoning generating sequences and intermediate cropped image regions per reasoning step (grounding mode) or answers (answering mode). At each step, the prophet model ingests the current cropped image and a task-dependent query (grounding verification or answering) and outputs a prophetic token prefix.
The core novelty is the probability-based prophetic sampling technique: The search model evaluates token-by-token if the prophet's suggestions are consistent with its own output probabilities. A composite score sj combines the search model’s and prophet’s token likelihoods via a balancing parameter α tied to the token’s rank. Tokens surpassing threshold τ are accepted as native search model tokens, else the search model samples from its own distribution. This maintains output distribution consistency and context coherence during multi-step decoding.
Training Regime: No additional training is involved—the framework is plug-and-play at inference time. The prophet is the pre-training LVLM snapshot before visual-search post-training. The search model is a post-training LVLM. Hyperparameters include τ=0.3 and α dynamically adjusted based on token rank. The process reduces overhead via parallel evaluation of candidate prophetic prefixes.
Evaluation Protocol: Metrics include accuracy or averaged accuracy per prior benchmark protocols (VisualProbe uses avg@32, Mini-o3 uses avg@32 and avg@8, etc.). Baselines are post-training LVLMs without SeProD (e.g., Pixel Reasoner, DeepEyes, Mini-o3). Gains with SeProD integration on all benchmarks are reported. Ablations investigate distribution consistency curves, single-step degradation after post-training, interference reduction by context masking, and the impact of probability threshold and α. No explicit adversarial or distribution-shift tests mentioned.
Reproducibility: The paper provides detailed architecture descriptions and hyperparameter settings. The prophet model defaults to Qwen2.5-VL-3B. Baselines use official code pipelines from cited works. Comprehensive evaluation over 12 splits of 4 benchmarks is reported. Source code and models are not mentioned as released, so reproducibility outside official codebases is unclear.
Concrete end-to-end example: At each reasoning turn, the search model generates a cropped zoom-in image and a textual output. That zoomed image and a grounding or answering query are fed to the prophet. The prophet outputs tokens representing verification or answer drafts. The search model simultaneously evaluates these tokens and probabilistically accepts prefixes maintaining output coherence. This process iterates through reasoning turns until the final answer is output, mitigating error accumulation and capability deterioration encountered in naive prompting or isolated step executions.
Technical innovations
- Introduction of self-regulation between pre- and post-training LVLMs to leverage intrinsic single-step capabilities for improved multi-step visual search reasoning.
- First application of probability-based prophetic sampling as a probabilistic decoding interface where the pre-training LVLM acts as a prophet and the post-training model selectively accepts tokens.
- Self-prophetic decoding framework (SeProD) that integrates pre-training model outputs as accepted prefixes during post-training LVLM inference, preserving output distribution consistency.
- Parallel evaluation of candidate prophetic prefixes with a token acceptance threshold allowing controlled and coherent multi-step propagation without adding computational overhead.
Datasets
- VisualProbe test — multiple splits (Easy, Medium, Hard) — public benchmark (Lai et al., 2025)
- V* Bench — high-resolution visual search dataset — public (Wu & Xie, 2023)
- HR-Bench (4K and 8K) — high-resolution visual reasoning — public (Wang et al., 2024b)
- MME-RealWorld — general VQA benchmark — public (Zhang et al., 2025c)
- ScienceQA — science domain VQA — public (Lu et al., 2022)
- OCRBench — OCR recognition VQA — public (Liu et al., 2024)
- CVBench — spatial understanding, counting — public (Tong et al., 2024)
Baselines vs proposed
- Pixel Reasoner: VisualProbe (Hard) accuracy = 28.7% vs SeProD-enhanced = 30.2% (+1.5%)
- DeepEyes: VisualProbe (Hard) accuracy = 38.4% vs SeProD = 41.9% (+3.5%)
- Mini-o3: VisualProbe (Hard) accuracy = 47.2% vs SeProD = 50.5% (+3.3%)
- Pixel Reasoner: V* Bench overall accuracy = 86.9% vs SeProD = 88.5% (+1.6%)
- DeepEyes: V* Bench overall accuracy = 89.0% vs SeProD = 91.1% (+2.1%)
- Mini-o3: HR-Bench 8K overall = 73.0% vs SeProD = 75.0% (+2.0%)
- Mini-o3 + SeProD (7B prophet): VisualProbe (Hard) accuracy = 51.5% (+4.3% over baseline 47.2%)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28741.

Fig 1: Overview of paradigms for enabling visual search in

Fig 2: (a) The degradation of intrinsic capabilities at a single step after visual-search post-training. Performance drops on
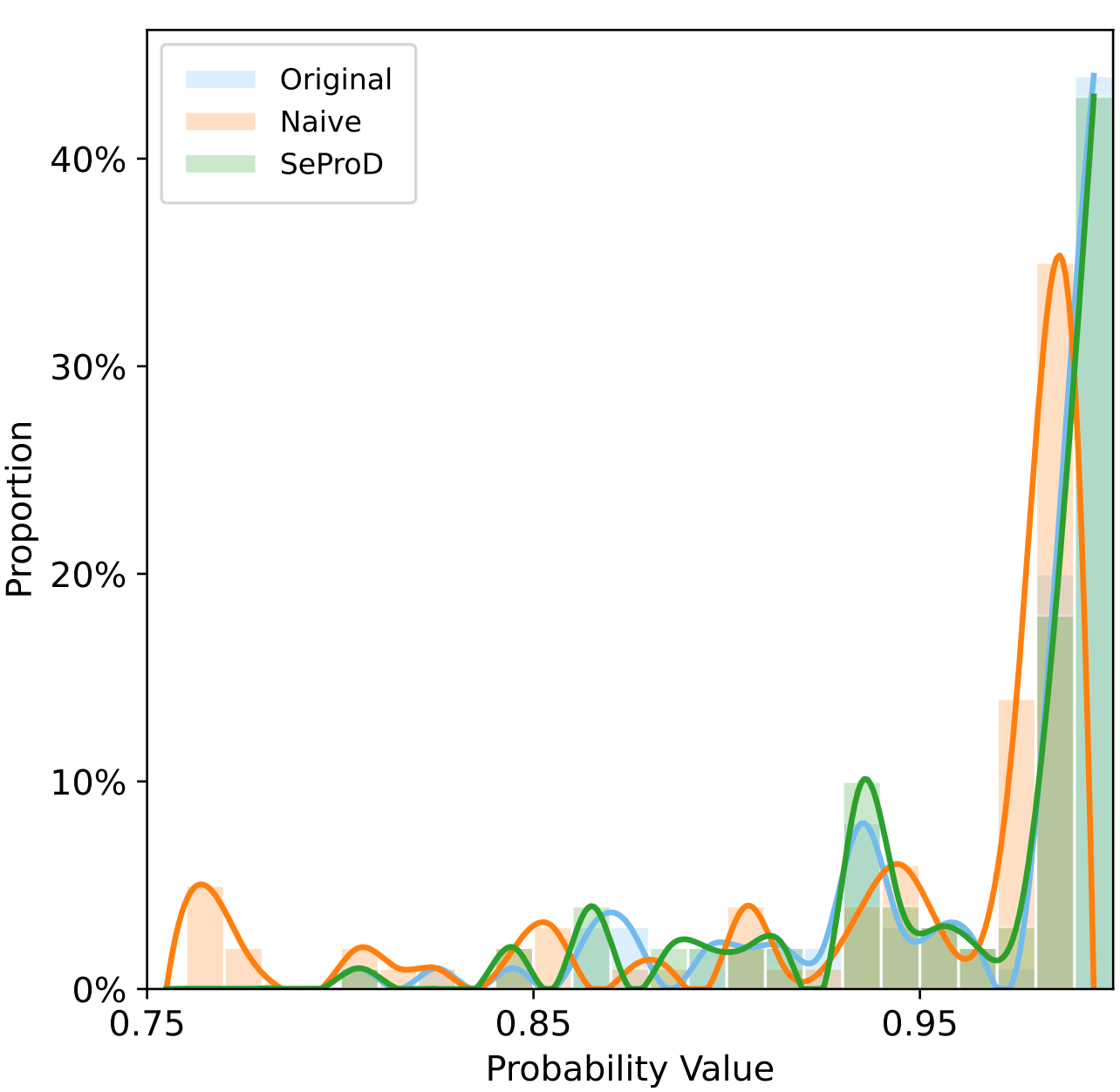
Fig 3: The overall framework of SeProD. (1) Pair of search model and prophet model. The post-training LVLM serves as the

Fig 4 (page 4).

Fig 4: An example of SeProD. At turn 0, the region localized by the search model through its grounding capability is provided as input,

Fig 5: An example of SeProD. At turns 0 and 5, the regions localized by the search model through its grounding capability are provided

Fig 6: A failure case of SeProD. At the final turn (turn 8), the search model ultimately localizes a misleading and incorrect region for

Fig 7: A failure case of SeProD. At the final turn (turn 3), the search model localizes the correct region. However, the target text in the
Limitations
- The method assumes availability of both pre-training and post-training checkpoints of the same LVLM; may not generalize if only one version is available.
- No adversarial robustness or distribution shift tests are reported; effects under unexpected inputs remain unclear.
- The probabilistic acceptance threshold τ and balancing factor α are hyperparameters requiring tuning; sensitivity to these is not fully explored.
- SeProD currently targets LVLM visual search post-training but may be less effective or untested on other multimodal reasoning tasks.
- Although parallel token acceptance reduces overhead, the use of two full LVLMs simultaneously may increase inference resource requirements in some settings.
- Failure cases exist where SeProD localizes incorrect regions or fails to fully correct search model errors, indicating incomplete elimination of reasoning interference.
Open questions / follow-ons
- How does SeProD perform under adversarial or distribution-shifted visual inputs, e.g., occlusions or novel domain images?
- Can the self-prophetic decoding framework be extended beyond visual search to other multimodal reasoning tasks requiring multi-step context integration?
- What is the impact of different prophet model sizes or architectures on acceptance rates and reasoning coherence?
- Can the acceptance threshold and α parameter be adaptively learned or optimized dynamically during inference?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, SeProD demonstrates a novel approach to maintaining intrinsic capabilities in LVLMs engaged in complex visual search and multi-step reasoning—a relevant insight given modern CAPTCHA systems increasingly use multimodal content. Its probabilistic interface to combine multiple intrinsic model states may inspire more robust methods to detect or bypass bots by testing coherence across multi-turn visual reasoning chains. The training-free, plug-and-play nature of SeProD suggests practical ways to enhance LVLM-based challenge-response systems without retraining, which could improve resilience against adaptive bots that exploit weaknesses in fragmented visual or textual reasoning. However, practitioners should also consider resource trade-offs of running dual models in real-time and carefully evaluate robustness under adversarial attempts to confuse multi-step visual reasoning.
Cite
@article{arxiv2605_28741,
title={ Self-Prophetic Decoding to Unlock Visual Search in LVLMs },
author={ Zhendong He and Qiyuan Dai and Guanbin Li and Liang Lin and Sibei Yang },
journal={arXiv preprint arXiv:2605.28741},
year={ 2026 },
url={https://arxiv.org/abs/2605.28741}
}