
Ω-QVLA: Robust Quantization for Vision-Language-Action Models via Composite Rotation and Per-step Scaling
Source: arXiv:2605.28803 · Published 2026-05-27 · By Xinyu Wang, Mingze Li, Sicheng Lyu, Dongxiu Liu, Kaicheng Yang, Ziyu Zhao et al.
TL;DR
This paper addresses the challenge of efficiently deploying Vision-Language-Action (VLA) models, which combine multi-billion-parameter language backbones and diffusion-based action heads. Prior work only partially compresses these models, usually leaving the diffusion transformer (DiT) action head at full precision or using mixed precision due to its sensitivity to quantization. The authors propose Ω-QVLA, a novel training-free post-training quantization (PTQ) framework that uniformly compresses both the language backbone and the entire DiT action head to 4-bit weights and activations (W4A4). This eliminates the need for mixed-precision allocation and significantly reduces memory usage without degrading task success.
Ω-QVLA introduces a composite rotation technique combining SVD and Hadamard transforms to equalize per-channel weight energy and diffuse activation outliers, making uniform quantization more stable. Additionally, per-step activation scaling is applied to absorb dynamic range shifts across the multi-step denoising process in the DiT action head. On the LIBERO benchmark with two VLA models (Pi 0.5 and GR00T N1.5), Ω-QVLA matches or exceeds FP16 full-precision performance while reducing memory footprint by ~71%. Real-world bimanual robot manipulation tasks further show smoother, more reliable control under W4A4 quantization compared to previous methods. These results overturn the prevailing belief that the DiT action head cannot be uniformly low-bit quantized.
Key findings
- Ω-QVLA compresses Pi 0.5 and GR00T N1.5 vision-language-action models to uniform W4A4 precision with task success rates of 98.0% and 87.8% respectively on LIBERO, matching or exceeding their FP16 references of 97.1% and 87.0%.
- Static memory footprint is reduced by 71.3% compared to FP16 baseline for GR00T N1.5 (from 1.99GB to 586MB) and by 72.0% for Pi 0.5 (from 4.27GB to 1.20GB).
- Standard post-training quantization methods fail on full VLA stack quantization, especially when including DiT attention layers, with some methods’ success rates dropping below 20%.
- Composite SVD·Hadamard rotation reduces per-channel weight norm variances from up to 26× to around 6× and activation norm ratios from 20× to approximately 1.6×, dramatically diffusing outliers.
- Per-step DiT activation scaling mitigates dynamic range drift across denoising steps, improving task success by 2 percentage points overall and preventing severe drops on long-horizon tasks (7-point drop without scaling).
- Real-world bimanual manipulation tasks show Ω-QVLA achieves an average progress score of 51.0 vs. 49.6 for FP16 baseline and only 25.0 for prior QuantVLA under uniform W4A4 quantization.
- Ablation studies confirm both the composite rotation and per-step scaling are critical, with combined SVD·Hadamard rotation improving average success by 8.5 points over SVD alone.
- Ω-QVLA’s block-wise rotation and zigzag channel permutation balance energy distribution without activation statistics, avoiding overfitting and maintaining robustness.
Threat model
The threat is quantization-induced perturbations that accumulate over iterative diffusion steps and closed-loop physical control in vision-language-action models, potentially causing degraded task success. The adversary is the quantization error itself; the method assumes no retraining and only limited calibration data are available. The approach does not consider malicious attacks but focuses on robustness to low-bit uniform quantization noise across both language and diffusion action modules.
Methodology — deep read
Threat Model and Assumptions: The adversary is implicitly the quantization process itself, which can cause errors that degrade VLA model performance, especially the diffusion-based action head. The authors assume no model retraining, only post-training quantization with limited unlabeled calibration data (10 trajectory samples). The goal is to maintain task performance for embodied control under uniform low-bit quantization. They do not consider adversarial attacks.
Data: Evaluation uses the LIBERO simulator benchmark which includes four tasks (Spatial, Object, Goal, Long) testing relational reasoning, grasping, task alignment, and temporal control. Two VLA policies are quantized and tested: Pi 0.5 (efficient inference, smaller backbone) and GR00T N1.5 (larger, richer action modeling). Real-world testing occurs on an ARX R5 dual-arm robot with bimanual manipulation tasks of increasing difficulty. No new labeled training data is introduced; instead, calibration uses 10 unlabeled trajectories.
Architecture and Algorithms: Ω-QVLA is a post-training quantization framework applying uniform 4-bit weights and activations (W4A4) to the entire VLA stack, including the language backbone (LLM) and the DiT action head. Key novelties:
- Composite two-level rotation: A block-wise SVD rotation derived from weight matrices is combined with a normalized Hadamard transform. SVD equalizes per-channel weight energy; Hadamard diffuses residual activation outliers that the SVD alone misses.
- Zigzag channel permutation before block partitioning distributes high-norm channels evenly across blocks to prevent outlier concentration.
- Per-step DiT activation scaling: Instead of single static activation quantization scales, a per-step, per-layer, per-channel scale table is precomputed offline to handle dynamic range drift across iterative diffusion denoising steps.
- Weight quantization uses GPTQ-style weight-only quantization on LLM with block size 128. Activation quantization uses round-to-nearest (RTN) with per-step scaling for the DiT action head activation).
Training Regime: There is no retraining or fine-tuning; this is a zero-shot post-training quantization method. Calibration uses 10 unlabeled trajectories to estimate activation ranges and scaling factors. All quantization parameters (rotation, scaling) are computed offline. Experiments run on NVIDIA A100 GPUs.
Evaluation Protocol: Metrics: Task success rates on LIBERO for 4 task suites and their average; progress scores for individual real robot tasks are averaged over 10 trials per task. Baselines include FP16 full precision, weight-only quantization like GPTQ and AWQ, PTQ baselines such as SmoothQuant, DuQuant, OmniQuant, and prior VLA quantization methods QuantVLA and QVLA. Ablations analyze rotation variants and per-step scaling effect. Sensitivity to DiT attention quantization is explicitly measured (removing DiT attention layers from quan). Memory footprint and parameter overhead are reported. No adversarial or distribution shift evaluation. Variance or statistical significance tests are not detailed.
Reproducibility: Code is released publicly at the project github repository. The dataset used is LIBERO (public). Model checkpoints are standard published VLA backbones referenced from prior work. Hardware and experimental details are provided. Some architectural and hyperparam details are in appendix.
Concrete Example: For the Pi 0.5 model, rotation matrices (block-wise SVD combined with Hadamard of size 64) are computed from full precision weights. Channels are permuted via zigzag ordering by column norms. Activations are quantized per-step with per-layer, per-channel scales derived from calibration trajectories over 8 denoising steps. The quantized weights and activations at W4A4 precision are then used for inference on LIBERO tasks, yielding a 98.0% average success rate, slightly exceeding full precision and consuming 72% less static memory.
Technical innovations
- Composite SVD·Hadamard rotation equalizes per-channel weight energy and diffuses residual activation outliers, enabling stable uniform 4-bit quantization of both weights and activations.
- Per-step DiT activation scaling that calibrates activation quantization scales per denoising step, layer, and channel to absorb dynamic range drift across diffusion timesteps.
- Zigzag channel permutation strategy prior to block-wise rotation to balance energy distribution across blocks and prevent outlier concentration without relying on activation statistics.
- Training-free post-training quantization framework that achieves full-stack uniform W4A4 quantization status on large vision-language-action models, including sensitive diffusion-based action heads.
Datasets
- LIBERO — size not explicitly stated — public vision-language robot manipulation benchmark with 4 task suites
- Unlabeled calibration buffer — 10 trajectories — used for per-step activation scaling calibration
Baselines vs proposed
- FP16 full precision: GR00T N1.5 average success = 87.0%, Pi 0.5 = 97.1% vs Ω-QVLA W4A4: 87.8% (GR00T), 98.0% (Pi 0.5)
- GPTQ W4A16 full quantization: GR00T average 56.3%, Pi 0.5 16.0% vs Ω-QVLA W4A4: 87.8%, 98.0%
- QuantVLA W4A4 full quantization: GR00T average 69.8%, Pi 0.5 82.0% vs Ω-QVLA W4A4: 87.8%, 98.0%
- SmoothQuant W4A8 full quantization: GR00T average 86.3%, Pi 0.5 96.8% vs Ω-QVLA W4A4: 87.8%, 98.0%
- Real-world manipulation (Pi 0.5, W4A4): QuantVLA progress score avg = 25.0 vs Ω-QVLA = 51.0 vs FP16 baseline = 49.6
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28803.
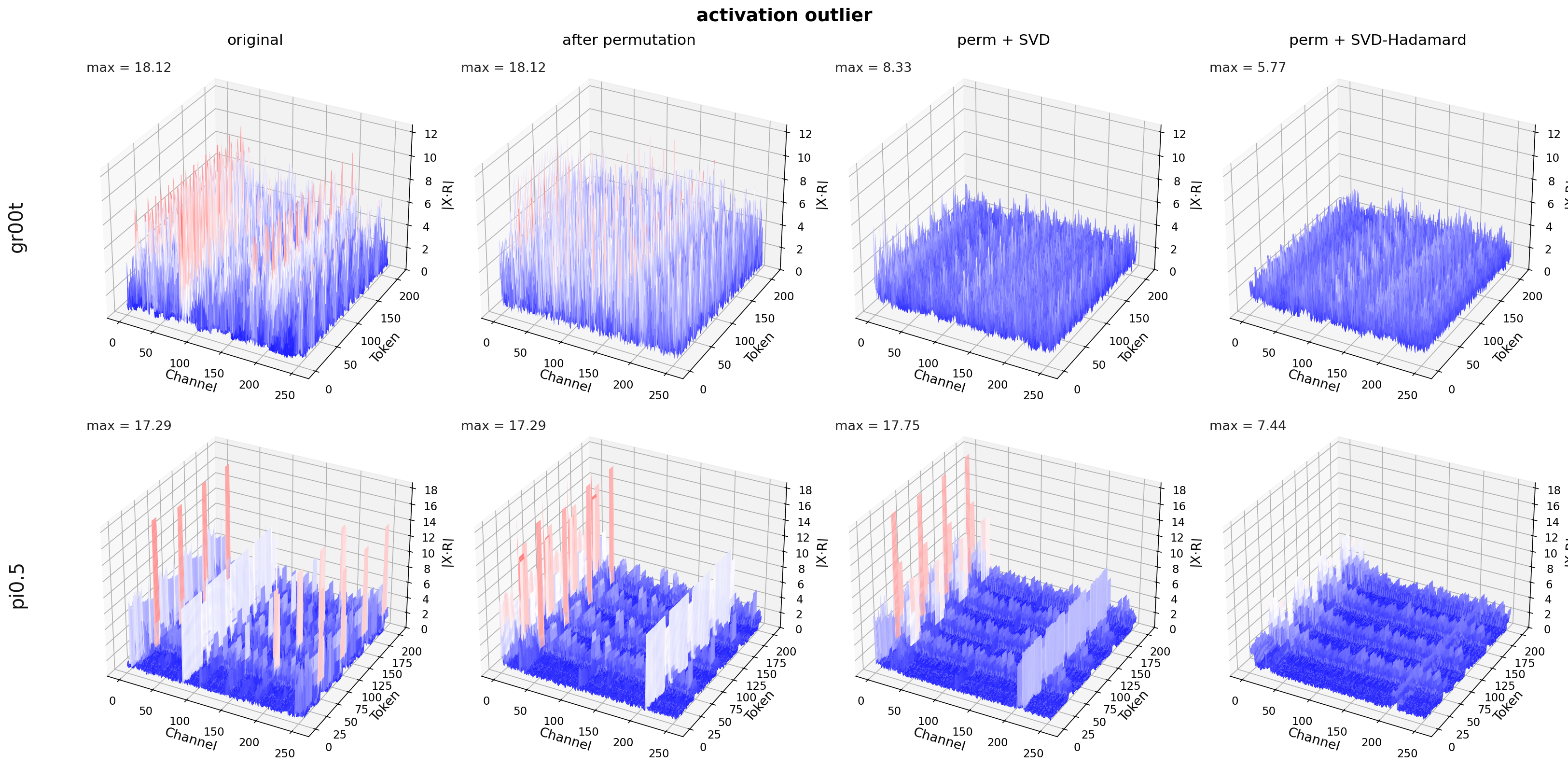
Fig 3: Activation outlier suppression of rotation with SVD (Zhang et al., 2026) versus our SVD-Hadamard.

Fig 4: Experimental setup of the real-world manipulation tasks. (a) Pick Cup: move the plate to the center and

Fig 7: (left) plots the 99.9-percentile activation

Fig 8: presents an open-loop comparison of

Fig 5: measures the layer-wise W4 weight-only

Fig 6: quantifies the gain from adding the
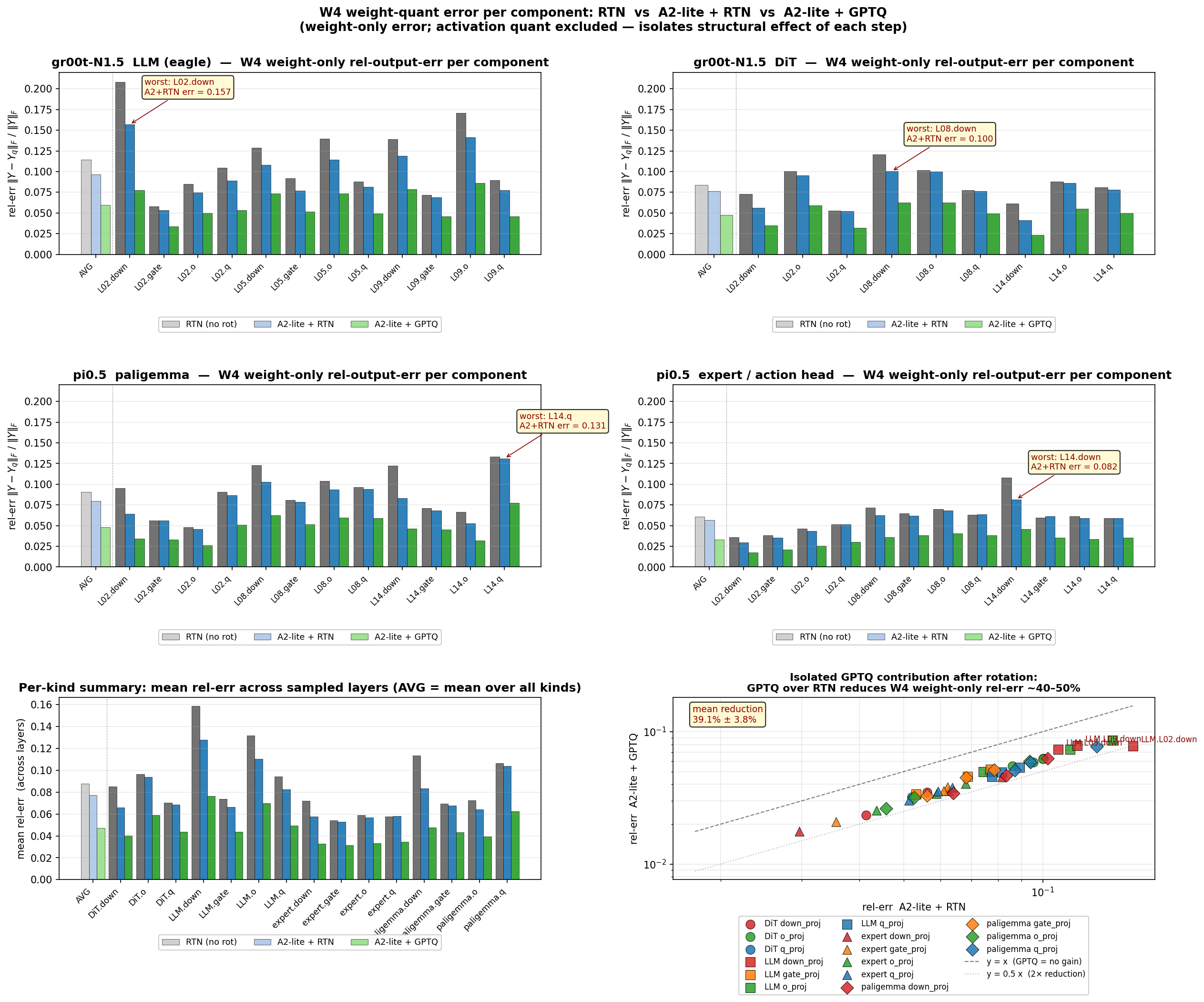
Fig 9: further compares the layer-wise quantiza-
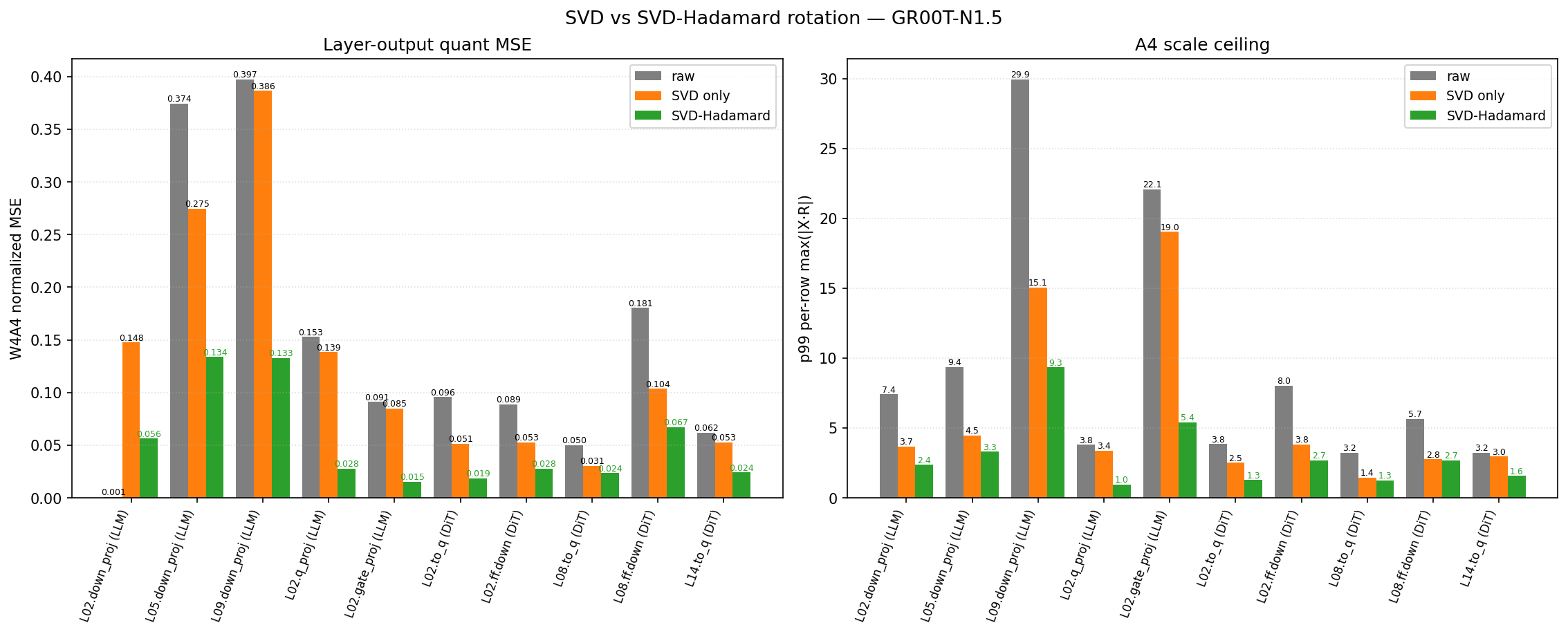
Fig 8 (page 15).
Limitations
- Evaluation limited to two DiT-based VLA backbones (Pi-0.5 and GR00T N1.5) and one benchmark suite (LIBERO) plus one physical robot platform.
- Vision encoder (ViT) remains at FP16 precision; composite rotation is not yet applied to this component.
- Real-world experiments average over only 10 rollouts per task, leaving non-trivial statistical variance.
- Wall-clock latency and throughput performance under W4A4 quantization are not reported due to hardware kernel support dependencies.
- Focus is on W4A4 regime; extending further to W3 or W2 precision may require additional techniques like low-rank residual branches or learned codebooks.
- No adversarial robustness or distributional shift evaluations included.
Open questions / follow-ons
- How does Ω-QVLA generalize to other action head architectures such as autoregressive or flow-matching models?
- What are the latency and throughput trade-offs of W4A4 quantization on different hardware with kernel-level support?
- Can the composite rotation and per-step scaling methods extend effectively to the vision encoder and multimodal fusion components?
- What complementary methods are needed for stable quantization beyond 4-bit precision (e.g., 3-bit or 2-bit)?
Why it matters for bot defense
While primarily focused on vision-language-action models for embodied control, the techniques developed here for robust, uniform low-bit post-training quantization of large multi-modal transformers are broadly relevant to bot-defense systems that rely on multimodal interaction models under resource constraints. The composite rotation approach effectively manages activation and weight outliers, a challenge shared with real-time CAPTCHA solvers that must operate reliably on-device. The ideas of per-step dynamic scaling could inform quantization strategies for generative models used in challenge-response systems. The demonstrated ability to uniformly quantize sensitive attention-heavy modules suggests promising directions for compressing complex detection and reasoning models in bot-defense pipelines without sacrificing accuracy.
Cite
@article{arxiv2605_28803,
title={ Ω-QVLA: Robust Quantization for Vision-Language-Action Models via Composite Rotation and Per-step Scaling },
author={ Xinyu Wang and Mingze Li and Sicheng Lyu and Dongxiu Liu and Kaicheng Yang and Ziyu Zhao and Yufei Cui and Xiao-Wen Chang and Peng Lu },
journal={arXiv preprint arXiv:2605.28803},
year={ 2026 },
url={https://arxiv.org/abs/2605.28803}
}