
Multi-Adapter Representation Interventions via Energy Calibration
Source: arXiv:2605.28722 · Published 2026-05-27 · By Manjiang Yu, Hongji Li, Junwei Chen, Xue Li, Priyanka Singh, Yang Cao et al.
TL;DR
This paper addresses the challenge of aligning large language models (LLMs) toward desired behaviors—such as truthfulness, bias mitigation, and safety—by intervening on their internal representations at inference without modifying model weights. Prior representation intervention methods apply a single fixed intervention uniformly, but the authors find that optimal intervention direction and strength vary widely across inputs. Indiscriminate fixed interventions can degrade model general capabilities on benign queries. To overcome this, they propose Multi-Adapter Representation Interventions via Energy Calibration (MARI), which employs a set of competitive low-rank adapters specialized through training to capture heterogeneous and nonlinear correction patterns for different inputs. Furthermore, an energy-based gating module detects when intervention is appropriate, selectively activating the intervention only for inputs that benefit from it while preserving performance on benign inputs. Extensive experiments on multiple benchmarks (TruthfulQA, BBQ, Sorry-bench, MMLU, ARC) demonstrate that MARI achieves state-of-the-art alignment improvements while maintaining or even improving general capabilities across diverse model families and scales from 7B to 32B parameters.
Key findings
- A single global linear intervention vector fails to capture heterogeneous and input-dependent correction directions and strengths, as shown by large variability on TruthfulQA samples (Fig 2).
- MARI’s multi-adapter strategy improves TruthfulQA MC1 accuracy from 50.46% (ReFT) to 64.35% on Llama-2-7B, a 14 percentage point gain.
- Energy-based gating reduces over-intervention, preserving or improving MMLU accuracy; e.g., MARI achieves 52.6% MMLU on Llama-2-7B versus 51.8% for ReFT.
- Removing energy gating increases alignment scores but causes significant general capability drops (e.g., MMLU drops from 66.6% to 57.5% on Llama-3-8B).
- Scaling to larger models yields stronger alignment gains; MARI improves TruthfulQA MC1 from 55.60% (ReFT) to 81.94% on Qwen2.5-32B (26.34 pp gain).
- Performance saturates at around 3-4 adapters; using more experts dilutes training signals and degrades performance (Fig 4).
- Energy gate threshold calibrated on small control set transfers robustly across domains including GSM8K data without recalibration, maintaining gains on TruthfulQA while preserving general tasks (Table 3).
- Statistical analysis bounds the risk impact of misrouting adapters and shows gating reduces low applicability energy on benign inputs, improving reliability.
Threat model
The threat model involves a deployed large language model that is fixed and immutable (weights frozen). The adversary or environment includes queries with a wide distribution, some requiring alignment interventions (e.g., to reduce hallucination) and others benign. The intervention mechanism must adaptively identify when and how to act on representations. Attackers cannot modify model weights or the intervention modules directly. The gating rejects inputs unlikely to benefit from intervention, avoiding unnecessary edits that might cause degradation.
Methodology — deep read
The paper tackles the problem of input-adaptive representation intervention to align LLM outputs with desired properties without changing base model weights. The threat model assumes a fixed frozen LLM, with interventions applied only at one layer-token position during inference; no direct model modifications or retraining of base parameters occur.
Data and Evaluation: The authors evaluate on multiple public benchmarks: alignment datasets TruthfulQA, BBQ (bias), Sorry-bench (safety/refusal), plus general benchmarks MMLU, ARC-Easy, ARC-Challenge for general capability assessment. Control and held-out datasets with applicable and non-applicable instances enable gating threshold calibration. Details on data splits and preprocessing are provided in Appendix A.
Architecture: MARI places multiple (K≥1) low-rank adapters at a single injection site in the frozen model. Each adapter learns a rank-r additive update function parameterized as Φψk(h) = h + γ sk ∆ψk(h), with ∆ψk(h) = Uk(Vk' h + bk), constraining the update within a learned subspace. Competitive training uses a "winner-take-gradient" approach: for each supervised example (x,y), only the adapter minimizing cross-entropy (or negative log-likelihood) loss receives gradients. This encourages complementary specialization. At inference, a parameter-free entropy-based routing mechanism selects the adapter with minimum predictive entropy, approximating the oracle selection used during training.
An energy-based gating module decides whether to apply the full intervention or fall back to the frozen base model. This calibration relies on injecting a small low-rank probe update gϕ(h) at the intervention site and measuring the median propagation response energy E(x;α) over deeper layers. The probe is trained separately with an off-subspace regularizer encouraging updates to lie within a PCA subspace fit from unlabeled data, improving energy-based separability between intervention-applicable and benign inputs. A threshold τE set on a small control set determines the gating: only inputs with energy above τE receive the full actuation strength αfull; others are passed through safely (αsafe=0).
Training: Each adapter and the probe are trained with standard cross-entropy or language modeling losses on labeled supervision. Competitive multi-adapter training uses hard routing per batch sample, with added balancing to prevent collapse. The probe model is trained in parallel without routing. The base model remains frozen.
Evaluation: Metrics include TruthfulQA MC1 and MC2 accuracy, BBQ accuracy, safety refusal rate via Sorry-bench, and general knowledge accuracy on MMLU and ARC. Multiple model families (Llama-2, Llama-3, Qwen2, Qwen2.5) and parameter scales (7B to 32B) are evaluated. Ablations examine the contribution of multi-adapters and energy gating. Sensitivity analyses sweep number of adapters K and rejection rate ρ.
Example Workflow: For a test input on TruthfulQA, the frozen LLM’s activations at the selected layer/token are extracted. The entropy router computes predictive entropy for each adapter’s output and selects the lowest-entropy adapter. The energy gate evaluates the propagation response from a probe update. If energy exceeds the threshold τE, the full adapter intervention update replaces the activation and the modified activation proceeds forward; else, the original frozen activation is used. The updated logits generate the aligned output.
Reproducibility: Code is publicly released at https://github.com/V1centNevwake/MARI. Detailed appendices provide formal definitions, training hyperparameters, PCA details, and dataset information. Models evaluated are open-weight and publicly available.
Uncertainties: Exact hyperparameter values for some components are in appendices. The method uses heuristics for gating thresholds, and scalability beyond the reported models is empirically suggested but not exhaustively analyzed.
Technical innovations
- Competitive multi-adapter mechanism trains multiple specialized low-rank adapters with hard routing to capture nonlinear, heterogeneous intervention requirements, overcoming limitations of fixed linear interventions.
- Energy-based gating module leverages propagation-response energy from a dedicated low-rank probe update to provide a label-free applicability signal that selectively triggers interventions only on inputs that benefit from correction.
- Entropy-based routing at inference selects among multiple adapters using the minimal predictive entropy criterion, enabling parameter-free, training-free adapter selection that approximates oracle routing.
- Off-subspace regularization on the energy calibrator probe constrains gating signals to a PCA subspace, improving separability between intervention-applicable and benign inputs.
Datasets
- TruthfulQA — size not specified in paper — public
- BBQ (Bias Benchmark for Question answering) — size not specified — public
- Sorry-bench (Safety refusal detection) — size not specified — public
- MMLU (Massive Multitask Language Understanding) — ~57 tasks, large benchmark — public
- ARC-Easy — public
- ARC-Challenge — public
- Control set for gating calibration — domain combinations of alignment and general capability tasks — constructed by authors, details in Appendix A
Baselines vs proposed
- ReFT: TruthfulQA MC1 (Llama-2-7B) = 50.46% vs MARI: 64.35%
- ReFT: BBQ accuracy (Llama-2-7B) = 0.540 vs MARI: 0.751
- ReFT: Refusal (Sorry-bench) (Llama-2-7B) = 0.845 vs MARI: 0.851
- ReFT: MMLU accuracy (Llama-2-7B) = 51.8% vs MARI: 52.6%
- ReFT: TruthfulQA MC1 (Qwen2.5-32B) = 55.60% vs MARI: 81.94%
- Removing energy gating increases TruthfulQA MC1 but degrades MMLU by ~9.1% on Llama-3-8B
- Single adapter (no multi-adapter) reduces alignment performance relative to MARI by up to ~20 percentage points on TruthfulQA.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28722.
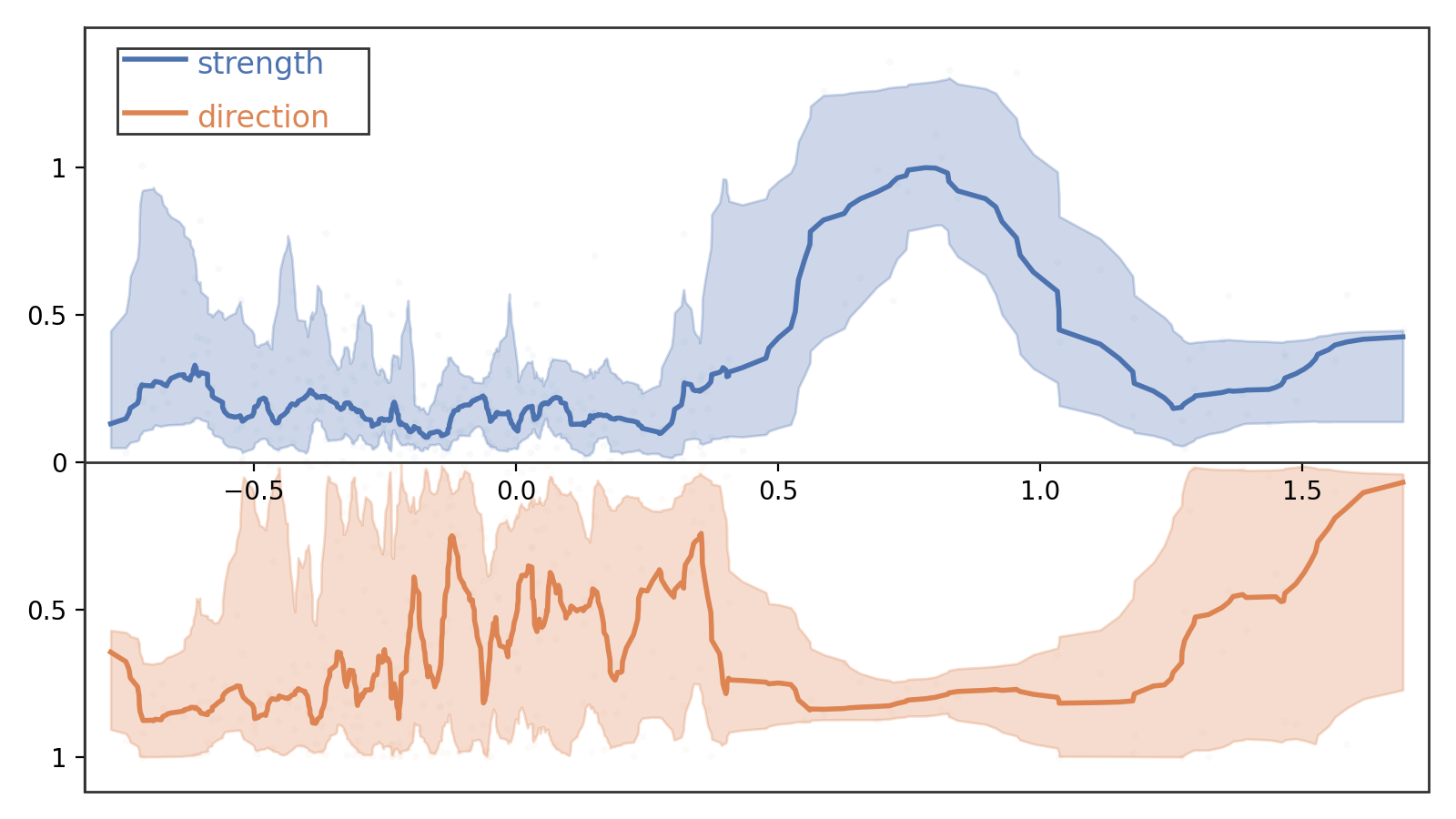
Fig 2: Variability of intervention needs. The visualization
Fig 3: Pipeline of MARI. MARI integrates an Energy-Based
Fig 3 (page 3).
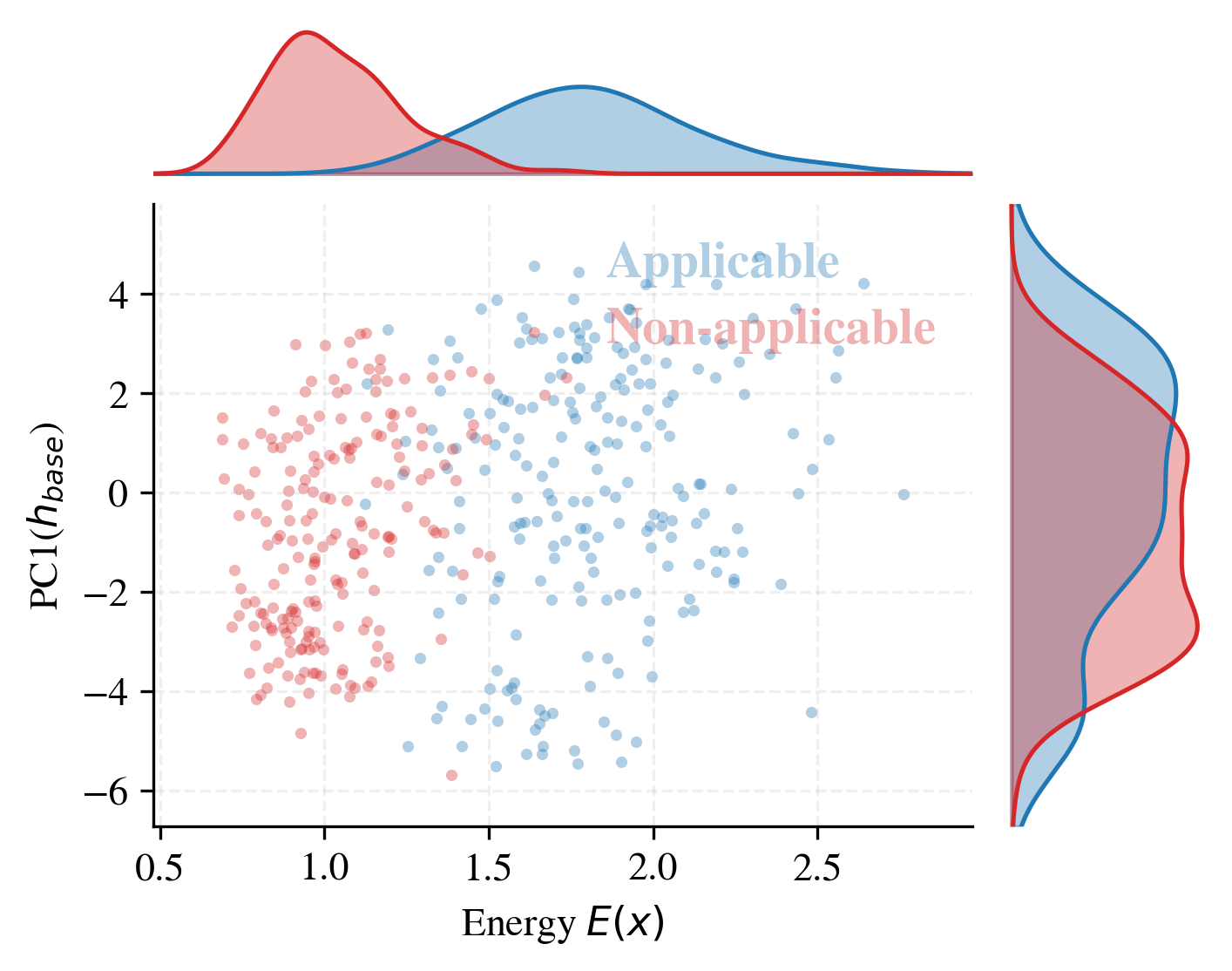
Fig 6: Energy-based gating diagnostics. (a) We project each
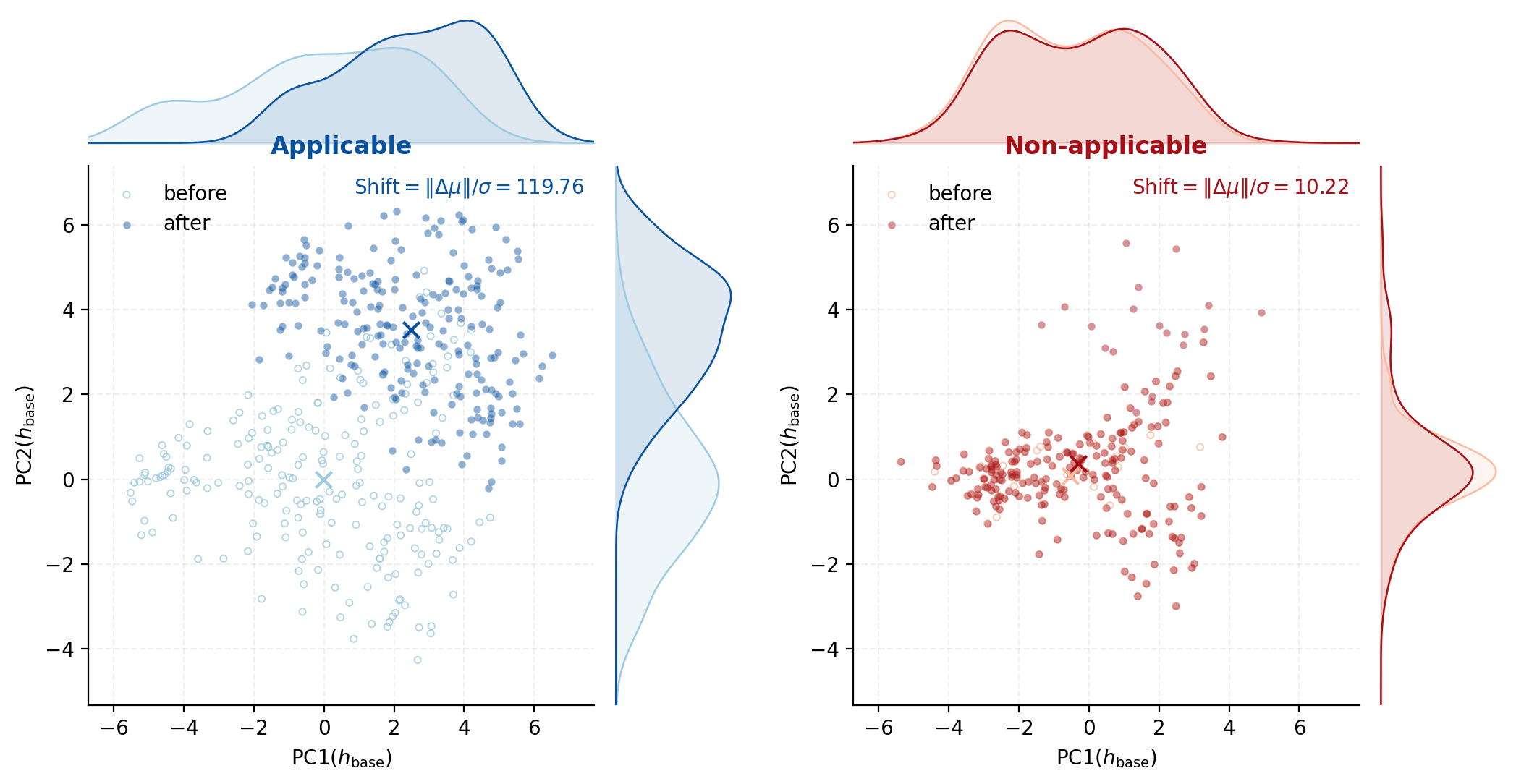
Fig 7: Representation shift under intervention. Applicable
Limitations
- Energy gating threshold τE requires calibration on a held-out control set mixing applicable and non-applicable inputs; robustness to severe out-of-distribution inputs unknown.
- While strong gains are demonstrated on select benchmarks, more diverse real-world deployment scenarios with adversarial inputs are not evaluated.
- Probe model for gating is separately trained, adding complexity and requiring extra compute resources.
- The approach intervenes at a single fixed layer and token position; potential benefits or risks of multiple injection sites unexamined.
- The method currently focuses on correcting fairly broad attributes (truthfulness, bias, refusal); applicability to fine-grained or task-specific alignments is unclear.
- Although tested across multiple model families and scales, transferability to newer architectures or non-transformer models is not assessed.
Open questions / follow-ons
- How robust is the energy-gating mechanism to strong adversarial or out-of-distribution inputs beyond those seen in the calibration/control set?
- Can multiple injection sites and multi-layer interventions further improve adaptive alignment while preserving capabilities?
- What are the trade-offs in extending the competitive adapter mechanism to larger numbers of adapters or hierarchical routing schemes?
- How well does MARI generalize to other downstream domains or fine-grained attribute alignments beyond truthfulness, bias, and safety?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, MARI offers valuable insights regarding the importance of input-adaptive, conditional interventions rather than uniform changes when controlling complex, large models. In settings where language models assist in security workflows—such as generating adaptive challenges or evaluating user input safety—indiscriminate application of steering or filtering risks degrading general utility and user experience. MARI’s competitive multi-adapter design and energy-based gating provide a flexible framework to calibrate interventions precisely, boosting alignment capabilities while preserving benign behavior. This trade-off is key in bot mitigation, where false positives and negatives can respectively lead to usability issues or security gaps. Understanding propagation energy as a label-free signal for gating decisions also suggests new directions for lightweight, dynamic intervention triggers in security-sensitive model deployments.
Cite
@article{arxiv2605_28722,
title={ Multi-Adapter Representation Interventions via Energy Calibration },
author={ Manjiang Yu and Hongji Li and Junwei Chen and Xue Li and Priyanka Singh and Yang Cao and Lijie Hu },
journal={arXiv preprint arXiv:2605.28722},
year={ 2026 },
url={https://arxiv.org/abs/2605.28722}
}