
JECA^2: Judgment-Explanation Consistent Adversarial Attack against Forensic Vision-Language Models
Source: arXiv:2605.28609 · Published 2026-05-27 · By Jiachen Qian
TL;DR
This paper investigates the adversarial robustness of forensic vision-language models (VLMs) that jointly detect image manipulations and generate natural language explanations justifying their judgments. Standard adversarial attacks often focus on flipping the binary authenticity decision but overlook whether the model's explanation remains consistent with the flipped judgment, creating a potential audit vulnerability. To address this, the authors propose JECA2, a Judgment-Explanation Consistent Adversarial Attack technique that crafts perturbations to both the visual input and the prompt embeddings to cause the forensic VLM to output an incorrect determination (e.g., labeling a forged image as real) along with a matching explanation that supports this incorrect output. On the visual side, JECA2 uses a Grad-CAM-guided attention diversion that suppresses model focus on tampered regions in favor of benign background areas. On the textual side, the method optimizes prompt embeddings towards semantic embeddings consistent with the target false judgment, constrained to remain close to valid token embeddings to preserve plausibility. Through extensive white-box evaluations primarily on the SID-Set dataset with the SIDA forensic VLM, JECA2 achieves a high attack success rate (ASR 87.2%) and substantially higher judgment-explanation consistency scores (JEC 4.15/5) compared to prior image-only or cross-modal attacks, which struggle to align explanation with the incorrect judgment. Transfer experiments to other forensic datasets and black-box closed-source VLMs show measurable but limited attack transferability. The work reveals a latent failure mode in explanation-based forensic VLMs, where explanations can inadvertently aid in detecting adversarial manipulations if inconsistent with the model’s judgment, emphasizing the need for robustness evaluations incorporating both output modalities.
Key findings
- JECA2 improves attack success rate to 87.2% (±2.4%) on SID-Set/SIDA under white-box conditions, surpassing strongest baseline CMI at 79.5%.
- Judgment-Explanation Consistency (JEC) evaluated by GPT-4 on successful attacks is 4.15/5 for JECA2 vs ≤3.12 for cross-modal attacks and ≤2.31 for image-only attacks.
- Visual module alone achieves 80.3% ASR, while textual prompt embedding optimization adds +6.9% ASR.
- JECA2 reduces tampering localization IoU from 0.44 (clean) down to 0.13 (attack), indicating effective attention diversion.
- Attention Diversion Score (ADS) increases from 0.12 (clean) to ≥0.7 (JECA2), showing substantial attribution shift to benign background regions.
- Transfer to OpenForensics/FakeShield datasets yields 77.8% ASR on average with J-ASR (joint classification + localization flip) at 71.2%.
- Black-box transfer on closed-source VLMs (e.g., GPT-4V, Claude-3 Opus) achieves 11.9–18.2% ASR, notably above random noise baseline of 2.7%.
- Ensemble surrogate training improves transfer ASR to 45.2% vs single-source 38.5%, indicating shared vulnerabilities across forensic VLM architectures.
Threat model
The adversary is a white-box attacker capable of perturbing the input image and, under stronger Level II threat, the prompt embeddings feeding into the forensic vision-language model. Their goal is to induce a forensic VLM to misclassify a forged image as real while simultaneously generating a natural-language explanation that supports this incorrect judgment. The attacker has knowledge of the model architecture, weights, and tampering mask regions (oracle or predicted). The attacker cannot modify model parameters or internals beyond input and embedding interference, and the attack is designed for digital image inputs rather than physical or sensor-level manipulation.
Methodology — deep read
Threat Model & Assumptions: The adversary aims to simultaneously cause a forensic VLM to make an incorrect binary authenticity judgment (e.g., forged image labeled 'Real') and to generate a supporting natural-language explanation consistent with the false judgment. Two threat levels are considered: Level I where only the input image is perturbed (image-only adversary), and Level II where both image and prompt embeddings are modified (stronger insider or compromised system access). The adversary is assumed to have white-box access to the model including gradients, and mask annotations indicating tampered regions are used for targeted attacks.
Data: The primary evaluation benchmark is the SID-Set dataset, containing 300K images with 100K each of real, fully synthetic, and tampered images (object replacement, partial editing). The test set includes 3,000 tampered images sampled with manipulation metadata. Transfer evaluation uses OpenForensics (∼115K images) and FakeShield datasets. Ground-truth tampering masks are used for oracle attack evaluations; a predicted-mask variant using DINO saliency maps tests mask-free scenarios.
Architecture/Algorithm: JECA2’s attack consists of three modules—(a) Visual Attention Diversion uses Grad-CAM maps to compute attention on tampered (Rtamper) and background (Rbg) regions. Perturbations δ are optimized via PGD to reduce tampered-region attribution and amplify Gaussian pseudo-hotspots added in Rbg, including a total variation smoothing loss around tampering boundaries. (b) Textual Explanation Alignment optimizes prompt embeddings E via gradient descent under classification loss encouraging the 'Real' label and a coherence penalty to keep embeddings close to valid token vectors in a vocabulary anchor set, thereby steering the textual justification to support the adversarial judgment. (c) Joint optimization alternates updates to δ (visual) and E (textual) using stepwise loss minimization for 100 iterations.
Training Regime: Perturbation bound ε=8/255, learning rates ηv=1/255 for visual PGD and ηe=0.01 for embedding steps, attention loss weight λ1=1.0, regularization λ2=0.01, total variation suppression λs=1.0, Gaussian spread σ=15 pixels, balance α=0.7 between mislead and conceal loss components. The optimization converges typically after ~60 iterations.
Evaluation Protocol: Metrics include Attack Success Rate (ASR) quantifying fraction of originally detected forged images flipped to 'Real', Joint ASR (J-ASR) requiring classification flip and localization IoU<0.2 to confirm spatial disruption, localization IoU measuring overlap of predicted vs ground-truth tampering mask, and perceptual quality metrics (PSNR, SSIM, LPIPS) to assess perturbation stealth. Baselines include classical image-only attacks (FGSM, PGD, C&W), recent prompt- or cross-modal attacks (CroPA, CMI), and task-specific black-box like RLGC. Automated judgment-explanation consistency (JEC) is rated 1–5 by GPT-4 on attacked samples' explanations. Transfer tests involve distinct datasets, models (FakeShield), and black-box closed-source VLM APIs (GPT-4V, Claude-3 Opus).
Reproducibility: Code release not specifically mentioned, but detailed hyperparameters, datasets, and optimization protocols are described. Oracle masks used for diagnostic upper bound; predicted-mask variant for black-box mimicking.
Concrete Example End-to-End: Given a tampered image I and ground-truth mask Mmask, initialize perturbation δ=0 and prompt embeddings E from the clean prompt. Iteratively compute Grad-CAM attribution map M on I+δ, optimize δ to reduce tampered-region attention and amplify Gaussian hotspots on background by minimizing detection loss plus bidirectional attention loss and a perturbation norm penalty. Then freeze δ, optimize E to increase confidence in 'Real' judgment while keeping embeddings close to valid tokens. Repeat alternating updates for 100 iterations. Return the final Iadv=I+δ and Eadv embeddings. Evaluate ASR, localization IoU, and JEC on this altered input. Successful attacks produce predictions of 'Real' with explanations referencing benign features consistent with the decision, while attention maps show attribution shifted away from tampered areas.
Technical innovations
- Joint optimization of visual perturbations and prompt embeddings to induce judgment and explanation consistency in forensic VLMs.
- Visual attention diversion leveraging Grad-CAM to redirect attribution from tampered regions to benign background using Gaussian pseudo-hotspots combined with total variation smoothing.
- Token-proximity constrained optimization of prompt embeddings to steer natural language explanations towards the adversarial target judgment while maintaining semantic plausibility.
- Introduction of an automated judgment-explanation consistency metric (JEC) using GPT-4 proxy evaluation to quantify explanation alignment with adversarial predictions.
- Use of alternating optimization between visual and textual modules for stable attack convergence.
Datasets
- SID-Set — 300K images (100K real, 100K synthetic, 100K tampered) — public
- OpenForensics — ~115K images with pixel-level forgery masks — public
- FakeShield — dataset for explainable image forgery detection — public
Baselines vs proposed
- FGSM: ASR=66.2% vs JECA2: 87.2%
- PGD: ASR=72.8% vs JECA2: 87.2%
- C&W: ASR=73.5% vs JECA2: 87.2%
- AnyAttack: ASR=74.9% vs JECA2: 87.2%
- MAA: ASR=78.3% vs JECA2: 87.2%
- JMTFA: ASR=76.1% vs JECA2: 87.2%
- PNA: ASR=75.4% vs JECA2: 87.2%
- CroPA: ASR=78.6% vs JECA2: 87.2%
- CMI: ASR=79.5% vs JECA2: 87.2%
- RLGC (black-box): ASR=74.3% vs JECA2: 87.2%
- Visual module only: ASR=80.3% vs JECA2 full: 87.2%
- Textual module only: ASR=73.5% vs JECA2 full: 87.2%
- Transfer to OpenForensics: average ASR=77.8%, J-ASR=71.2%, IoU=0.18
- Black-box to GPT-4V: ASR=14.6% vs random noise: 2.7%
- Black-box to Claude-3 Opus: ASR=11.9%
- Black-box to Gemini Pro: ASR=18.2%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28609.
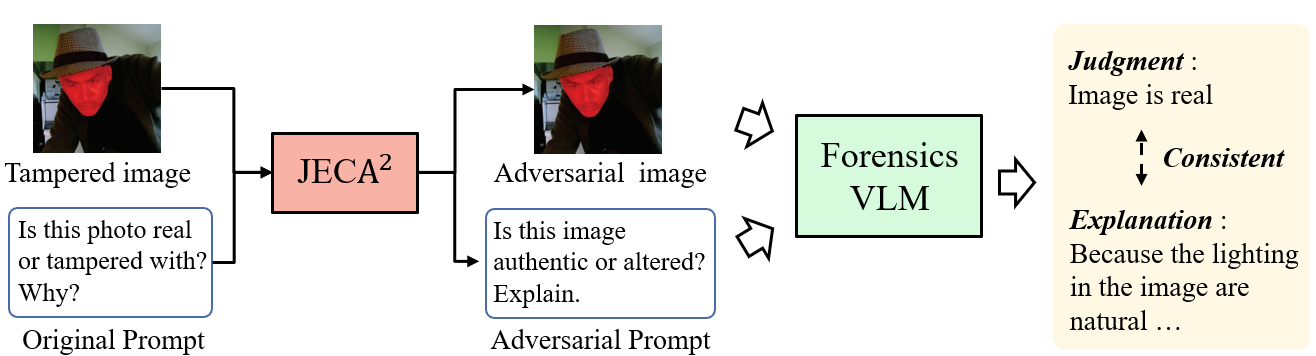
Fig 1: Schematic illustration of the proposed JECA2 against a forensic VLM. The
Fig 2: Complete workflow of the JECA2 framework. The visual attention diversion
Fig 3: Success and failure cases of JECA2. Top (Success): (a) Face-swap; (b) Inpaint-
Fig 4 (page 30).
Fig 5 (page 31).
Limitations
- Assumes white-box access and ground-truth tampering masks for strongest performance; predicted-mask variant reduces effectiveness slightly (78.6% ASR).
- Transferability to closed-source general VLMs remains limited and may not pose immediate practical black-box threat.
- Visual attention diversion relies on presence of sufficient benign background regions; fails on full-face high-coverage manipulations or multiple disjoint tampered regions.
- Grad-CAM is used as a proxy for attention but may not fully capture internal model reasoning.
- Automated JEC metric uses GPT-4 proxy evaluation only; human validation limited and may not fully capture forensic explanation faithfulness.
- Non-adaptive defense evaluations suggest possible arms race absent in current work.
Open questions / follow-ons
- How can defenses specifically target judgment-explanation consistency vulnerabilities in forensic VLMs without excessive efficiency loss?
- What alternative explanation alignment metrics or human-in-the-loop signals could better validate or detect adversarially consistent outputs?
- Can multi-region or full-face manipulations be attacked effectively with extended visual attention diversion schemes (e.g., multiple Gaussian decoys)?
- How would realistic black-box attack setups with limited model knowledge affect transferability and consistency of attacks?
Why it matters for bot defense
For CAPTCHA and bot-defense practitioners, this work highlights an emerging complexity in adversarial attacks on vision-language forensic models that simultaneously attack both prediction and accompanying explanations. Explanation-based defense and triage systems that rely on consistency between binary authenticity decisions and natural language justifications could be fooled by attacks like JECA2 that induce false-consistency. This means forensic human-review modules integrated in trust workflows might be blinded by adversarially crafted inputs that produce plausible, internally consistent but incorrect narratives. Practitioners should consider evaluation metrics beyond simple classification error and incorporate robust attention and explanation-consistency tests into their threat modeling and detection pipelines. Moreover, the dual-image-and-text prompt embedding attack vector suggests that defenses against tampered prompt embeddings may be needed if system architectures allow embedding-level access or modifications.
Cite
@article{arxiv2605_28609,
title={ JECA^2: Judgment-Explanation Consistent Adversarial Attack against Forensic Vision-Language Models },
author={ Jiachen Qian },
journal={arXiv preprint arXiv:2605.28609},
year={ 2026 },
url={https://arxiv.org/abs/2605.28609}
}