
I Hear, Therefore I Trust: A Socio-Technical Investigation of Humans as Synthetic Speech Detectors
Source: arXiv:2605.28064 · Published 2026-05-27 · By Lelia Erscoi, Tomi Kinnunen
TL;DR
This paper addresses the problem of human detection of synthetic speech (voice deepfakes) as a socio-technical phenomenon, emphasizing that human listeners must operate within environmental trust contexts rather than in isolated lab settings. Prior studies showed limited human ability to detect synthetic speech, often relying on outdated cues. The authors designed an experiment where 47 native English speakers annotated suspected synthetic segments within fully authentic, fully synthetic, and partially synthetic utterances under manipulated trust cues: instructional framing, affective priming, and provenance labeling. The dataset contained speech from known TTS models spliced with authentic segments, masked with ecological noise.
Key findings reveal that utterance type dictated detection accuracy and subjective perceptual quality, while manipulated trust cues did not significantly impact outcome metrics but modulated behavior patterns like annotation duration and revision rates. Participants systematically failed to detect fully synthetic speech, often misclassifying it as partially synthetic, and were overconfident in their judgments. Quality ratings (mechanicalness, expressiveness, intelligibility, clarity, calmness) correlated with utterance authenticity, indicating implicit sensitivity. The authors interpret these results as showing humans’ inability to reliably identify deepfakes without acoustic anchors (authentic segments), and that contextual trust manipulations alone do not improve human detection performance. This work highlights the socio-technical limitations of humans as synthetic speech detectors and the need to consider trust framing in mitigation strategies.
Key findings
- Fully synthetic speech was detected at below-chance levels; none of the 5 fully synthetic trials were correctly classified (0% accuracy) while authentic and partially synthetic were detected with 80% accuracy each.
- Average overall window-level detection accuracy across utterance types was 55.8%, with true positive rate (TPR) 19.4% and false positive rate (FPR) 7.1%.
- Linear mixed-effects models showed strong effects of utterance type on detection accuracy (H1) and quality ratings (H2), both statistically significant (p < 0.001) with large effect sizes (Cohen’s d > 1.5).
- Trust cues (instructional framing, affective priming, provenance labeling) produced no significant main effects on detection accuracy or perceptual quality scores (H1a and H2a not supported).
- Participants showed overconfidence: self-reported confidence averaged 71.5% despite poor detection performance, especially on fully synthetic speech.
- Participants annotated suspicious segments with longer trial durations and more actions on synthetic trials than authentic ones, with trust cues modulating these behavioral patterns (e.g., positive instruction framing increased trial duration by +22 s).
- Majority vote classification misassigned fully synthetic speech as partially synthetic consistently, indicating detection of manipulation presence but failure to estimate extent.
- Subjective quality ratings (mechanicalness, expressiveness, intelligibility, clarity, calmness) closely tracked ground truth authenticity, suggesting implicit discrimination even when explicit detection failed.
Threat model
The adversary is an entity able to generate fully or partially synthetic speech segments using state-of-the-art text-to-speech technologies, aiming to deceive human listeners who receive speech within a noisy, realistic context. Listeners do not have prior knowledge of utterance authenticity and rely solely on auditory cues and contextual trust manipulations. The adversary cannot manipulate the environmental trust cues in the experimental setting but may exploit human susceptibility to cognitive biases and limited vigilance. The model assumes the adversary cannot manipulate other multimodal or metadata channels beyond the audio.
Methodology — deep read
Threat Model & Assumptions: The adversary in this study is an entity producing synthetic speech (deepfakes) that may be fully or partially manipulated to deceive human listeners. Listeners do not have prior knowledge of utterance authenticity and must detect manipulated speech segments in naturalistic, noisy conditions. Attackers leverage realistic TTS models and partial segment splicing to evade detection. The study assumes humans are naive detectors acting under different environmental trust contexts.
Data: The study uses the LlamaPartialSpoof dataset generated from 40 English speakers in LibriTTS with utterances fully authentic, fully synthetic, or partially synthetic (mixed genuine and fake segments). Five open-source TTS models plus one commercial system generated synthetics. 20 utterances (balanced 1:1:2 ratio authentic:synthetic:partial) over 10 seconds long were sampled. Environmental noise from the International Soundscape Database was added at 25 dBSNR to simulate real-world acoustic conditions.
Architecture/Algorithm: No machine learning model was trained; the experiment centers on human perceptual detection. Participants annotate suspected synthetic speech segments via a GUI with two marker types (point flags or intervals). Annotations are evaluated against ground truth using 0.2 s sliding windows with ±200 ms tolerance. Aggregation metrics (accuracy, true/false positive rates) are computed window-wise and trial-wise with majority vote.
Training Regime: Not applicable for humans; 47 native English listeners recruited and randomized into two instruction frames (positive or negative trust), two affective valence priming groups (positive or negative images), and on each trial with 50% provenance labeling (trusted source label or none). Participants listened to utterances in random order and annotated suspicious segments, followed by subjective ratings on 6 perceptual qualities. Attention checks ensured task engagement.
Evaluation Protocol: Tasks measured window-level detection accuracy, sensitivity, and specificity, plus trial-level majority vote accuracy. Mixed-effects regression models tested utterance authenticity and trust cue effects on detection and ratings across 940 trials. Behavioral data (trial duration, action/revision rates) were analyzed for trust modulation. Confidence calibration curves assessed overconfidence. Comparisons were made across utterance types and trust cue conditions.
Reproducibility: The experiment software runs on the Prolific platform with a custom Python Streamlit GUI replicating social media scenarios. The study provides detailed descriptions of stimuli, trust cue manipulations, evaluation metrics, and participant demographics. The LlamaPartialSpoof dataset is publicly referenced. Code release status is not specified, and no frozen models apply as human subjects conducted detection.
Concrete Example: A participant listens to a 15-second utterance partially synthetic with 2 synthetic segments spliced in. The participant annotates suspected synthetic timestamps with segments and flags, spending 90 seconds on the trial. Their annotations are automatically aligned to ground truth with ±200 ms margin to compute true/false positives each 0.2 s window. The aggregated metrics show if the participant correctly identified the synthetic portions. After marking, the participant rates the audio on mechanicalness, expressiveness, intelligibility, clarity, calmness, and confidence. This process repeats for 20 trials with assigned trust cue conditions. The final dataset of annotations and ratings is analyzed across all participants for significance testing.
Technical innovations
- Introduction of a synthetic speech localization task allowing fine-grained segment-level annotations rather than binary utterance classification.
- Systematic manipulation of trust cues (instructional framing, affective valence priming, provenance labeling) integrated into human detection experiments to model socio-technical environmental factors.
- Combination of perceptual quality ratings with detection behavior to reveal implicit discrimination of synthetic speech despite poor overt detection.
- Use of partially synthetic utterances generated by splicing authentic and synthetic speech segments to simulate realistic targeted manipulation attacks.
Datasets
- LlamaPartialSpoof — 20 utterances sampled from a larger dataset of 40 LibriTTS speakers with synthetic samples from 5 open-source and 1 commercial TTS systems — Publicly referenced
- LibriTTS — Source corpus for voices — Public
- International Soundscape Database noise samples — Public
- Open Affective Standardized Image Set (OASIS) — For affective priming images — Public
Baselines vs proposed
- Authentic speech: majority vote accuracy = 80% (4/5 correct)
- Partially synthetic speech: majority vote accuracy = 80% (8/10 correct)
- Fully synthetic speech: majority vote accuracy = 0% (0/5 correct)
- Overall window-level accuracy: 55.8% (TPR 19.4%, FPR 7.1%)
- Trust cue conditions (instruction framing, valence priming, provenance labeling) produced no statistically significant improvements vs baseline detection scores (p > 0.05)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28064.
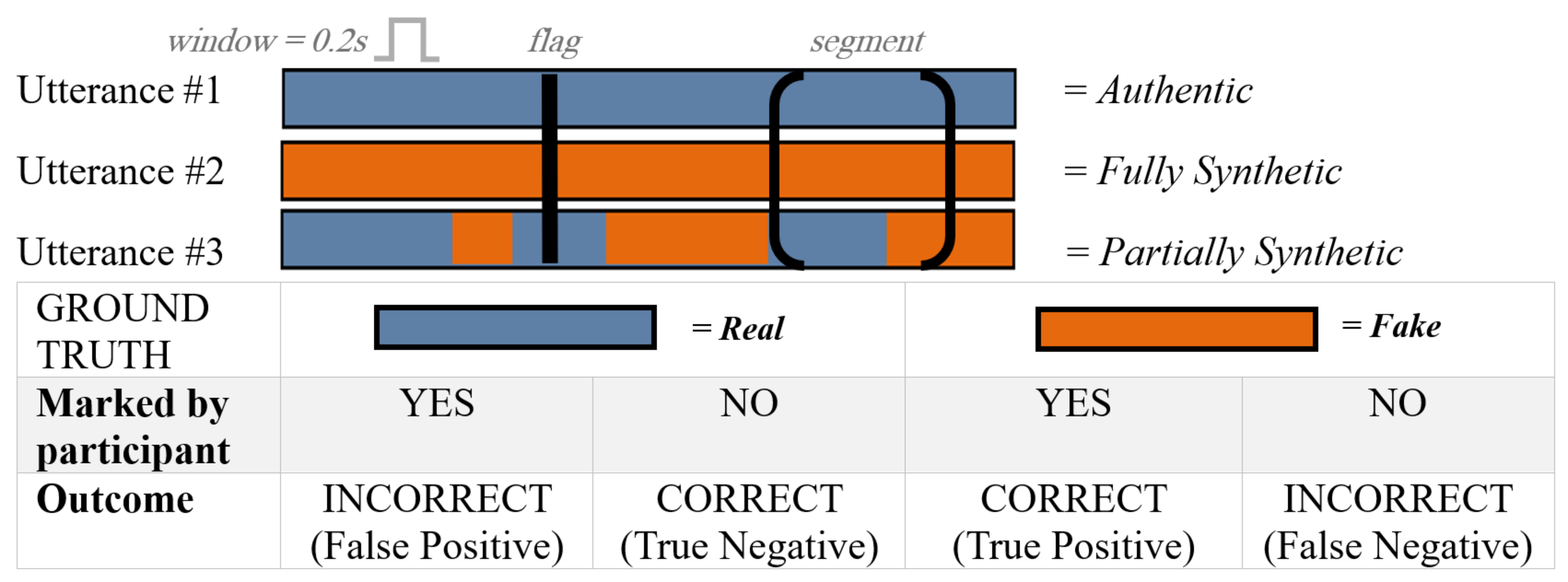
Fig 1: How user markers translate to evaluation metrics.
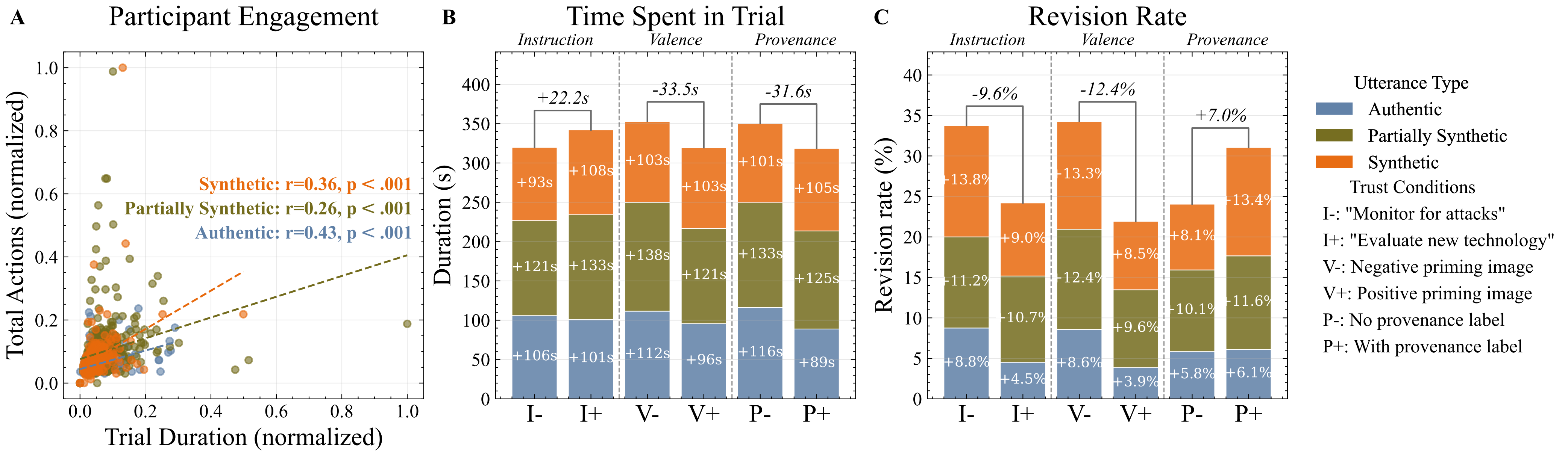
Fig 2: Decision-making patterns across conditions. (A) Positive correlation between action count and trial duration across all
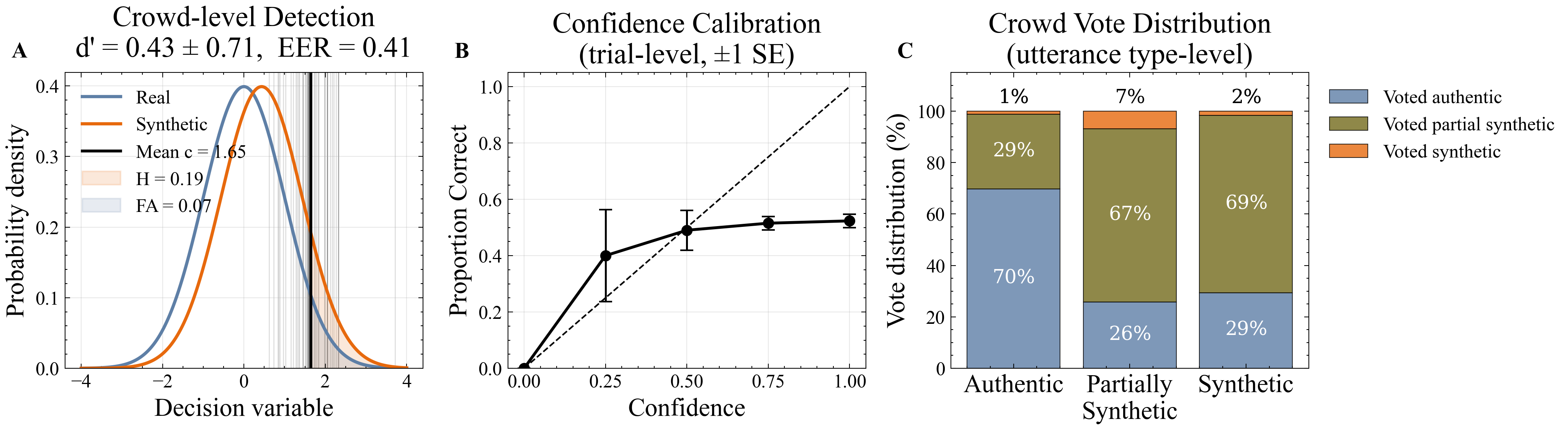
Fig 3: Crowd-level detection performance. (A) Raw discriminability. Distributions show the internal decision variable for real and
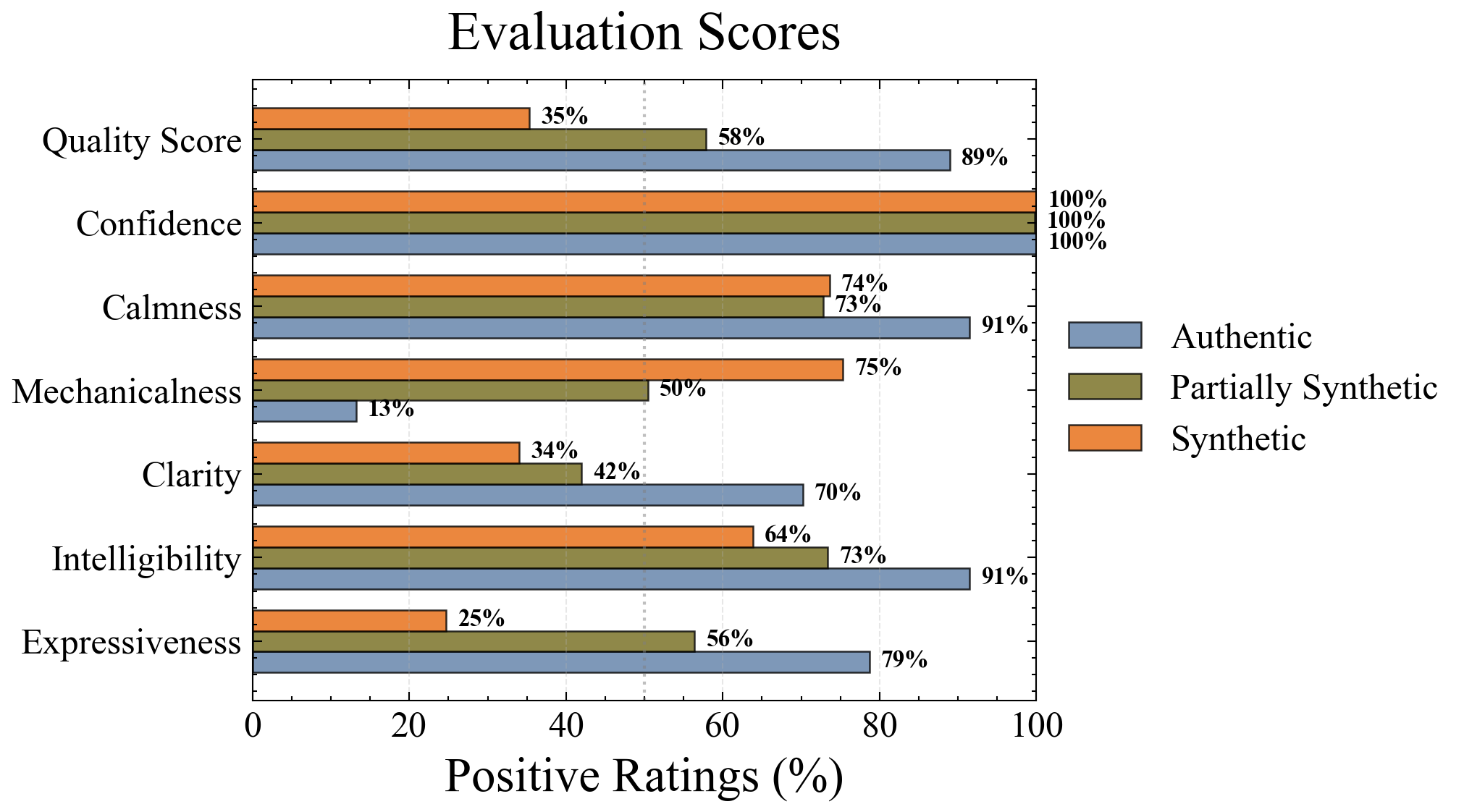
Fig 4: Percentage of positive ratings (”Agree”, ”Strongly
Limitations
- Small stimulus set of 20 utterances limits the generalizability across different synthesis systems and speaker voices.
- Explicit task framing likely primed participants for suspicion, possibly attenuating natural trust cue effects and ecological validity.
- Crowdsourced participants aware of synthetic speech detection task, not naive listeners encountering deepfakes in the wild.
- Lack of adversarial or evolving synthetic systems evaluation; results pertain to specific TTS models available at study time.
- Use of ecological noise aids realism but noisy environments may confound detection performance measurements.
- No longitudinal or repeated exposure assessment to test trust development or degradation over time.
Open questions / follow-ons
- How would human detection performance vary in truly naturalistic, unaware listening contexts without explicit suspicion priming?
- Can repeated exposure and training improve listeners’ ability to detect synthetic speech or is detection fundamentally limited?
- What is the effectiveness of combining human judgments with automatic detection tools in real-world, socio-technical trust settings?
- How do differences in speaker identity and synthesized voice trustworthiness affect user susceptibility to deepfakes?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this study highlights that human capability to detect synthetic speech—akin to audio-based CAPTCHA challenges—is fundamentally limited especially when confronted with fully synthetic or partially manipulated speech. The findings caution against relying solely on naive human evaluation as a security measure for synthetic media detection. Contextual trust cues and framing manipulations, common tactics to influence user vigilance and responsiveness, do not substantially improve human detection accuracy.
Implementers should be aware that detection tasks demanding users to flag manipulated audio segments in naturalistic noise and streaming conditions may result in below-chance performance and overconfidence, potentially allowing sophisticated voice deepfake attacks to bypass human scrutiny unnoticed. This underscores the importance of combining human factors understanding with robust automatic detection systems, and designing socio-technical workflows where trust cues do not serve as naive band-aids but are integrated with effective technical signals.
Cite
@article{arxiv2605_28064,
title={ I Hear, Therefore I Trust: A Socio-Technical Investigation of Humans as Synthetic Speech Detectors },
author={ Lelia Erscoi and Tomi Kinnunen },
journal={arXiv preprint arXiv:2605.28064},
year={ 2026 },
url={https://arxiv.org/abs/2605.28064}
}