
GUI Agents for Continual Game Generation
Source: arXiv:2605.28258 · Published 2026-05-27 · By Yixu Huang, Bo Li, Na Li, Zhe Wang, Kaijie Chen, Haonan Ge et al.
TL;DR
This paper addresses the gap between AI-generated game code and fully playable games by positioning graphical user interface (GUI) agents as critical playtesters. Unlike prior approaches that treat game generation as a one-shot code synthesis problem, this work emphasizes that quality in games resides in the interactive experience—requiring evaluation through actual play. The authors introduce PlaytestArena, a benchmark of 200 browser-based game generation tasks spanning eight genres, each paired with a rubric describing expected in-play behaviors. A GUI agent loads each game build, plays it via mouse and keyboard emulation, and adjudicates rubric satisfaction by observing gameplay. This setup enables objective evaluation grounded in play, not just static code correctness.
Building on this, the authors propose Play2Code, a novel loop coupling a game agent that generates or patches game code with a GUI agent that plays and tests the build, providing detailed summaries and actionable fix lists via shared memory. This iterative dialogue of coding and playing enables continual refinement of the game, drastically improving rubric pass rates. Experiments show Play2Code achieves a 66.8% average rubric pass rate across three LLM backbones, outperforming single pass and non-playtesting agentic baselines by 37.1 and 14.6 points respectively. The study also analyzes the nature of GUI agent feedback, finding it to be more traceable but idiosyncratic compared to human playtester reports, indicating GUI playtesting as a promising, scalable proxy for human testing in interactive code generation.
Key findings
- Play2Code achieves a 66.8% rubric pass rate, improving over single-pass (29.7%) and agentic-coding baselines (52.2%) by 37.1 and 14.6 percentage points respectively across three backbones (GPT-5.4, Sonnet 4.6, Kimi K2.5).
- The PlaytestArena benchmark consists of 200 browser-based games across eight genres with an average of 7.7 rubric criteria per game (total 1,548 criteria).
- GUI agents match human playtester judgments on rubric criteria with 84.2% raw agreement and Cohen’s kappa of 0.64 versus human–human agreement (0.66), indicating strong evaluator reliability.
- GUI agent-driven playtesting feedback enables monotonic improvement in rubric scores across iterative rounds, with most gains realized within 3–5 rounds for low and moderate complexity games.
- GUI agents differ in feedback focus: GPT-5.4 centers on functionality and control bugs, Sonnet 4.6 on pacing and game feel, and Kimi K2.5 on visual and aesthetic aspects, reflecting diversity akin to human testers.
- High-complexity games show limited gains under Play2Code due to GUI agents' difficulty reliably triggering complex mechanics, indicating GUI agent capability as a bottleneck.
- PlaytestArena rubric scores are strongly correlated between GUI agent and humans (Spearman’s ρ = 0.87, Pearson’s r = 0.88) on a stratified 32-game sample.
- All three GUI agent backbones achieve majority pass rates on a 120-level testbed of 20 diverse games, with GPT-5.4 approaching human performance (pass@20=0.82 vs human 0.92).
Threat model
Not a security-focused paper. The 'threat' addressed is incomplete or buggy game generation by large language models that lack interactive playtesting feedback. The adversary is thus the generation approach prone to producing unplayable games. GUI agents act as defenders by providing evaluation and refinement signals, but no adversarial attacks or malicious manipulations are assumed.
Methodology — deep read
Threat Model & Assumptions: The adversary here is an automated game generation system producing candidate games from natural language prompts. The challenge is that playable quality depends on dynamic interaction, which static code inspection cannot reveal. No direct adversarial attacks are studied—the focus is on evaluation and generation improvement via automated GUI playtesters.
Data: The authors curated PlaytestArena, comprising 200 HTML/JS browser-based games spanning eight genres (puzzle, strategy, card, platformer, action, management, shooter, others). Each game is paired with a natural language prompt (~131 tokens avg.) describing intended gameplay, and an expert-curated rubric with an average of 7.7 testable criteria per game (total 1,548 criteria). The rubrics define observable expected behaviors in gameplay (state changes, controls, progression, visual feedback). A separate smaller set of 20 games with 120 levels was used to evaluate GUI agents and humans for baseline playtesting performance.
Architecture / Algorithms:
- GUI Agents serve two roles: Evaluator (loads generated games in a browser, perceives rendered UI, reasons about state, acts via clicks/keys to play, and adjudicates rubric pass/fail per criterion). Three large model backbones (GPT-5.4, Anthropic's Claude Sonnet 4.6, Moonshot AI Kimi K2.5) were integrated.
- Play2Code system: a longer-running loop couples two agents—Game Agent (writes, debugs, patches HTML game code) and GUI Agent (plays the built game, generates structured play summaries and actionable fix lists mapped to code-level changes). These agents share a layered memory system: Episode Memory (in-task round history), Skill Memory (task-isolated agent knowledge), and World Memory (common game knowledge). This enables knowledge accumulation and iterative refinement.
Training / Execution Regime: No classic ML training; instead three pretrained LLM backbones are used as game and GUI agents. Each game generation unfolds in multiple rounds of generate/play cycles. Play2Code runs up to 5 rounds per game or until rubric satisfaction is met. Baseline comparators include Direct LLM generation (single pass) and OpenGame (agentic coding that iteratively builds and inspects code but does not play).
Evaluation Protocol:
- Metrics: rubric pass rate (% of rubric criteria passed).
- Baselines: Direct LLM generation and OpenGame pipeline.
- Human evaluation: Three humans played matched levels for comparison.
- Validation: Agreement between human annotation and GUI adjudication on rubric criteria (32-game stratified set), analyzed with Cohen's kappa, Spearman/Pearson correlations.
- Ablations: Appendix details confirm necessity of both GUI agent and memory system.
- Complexity stratification: Games partitioned by difficulty to study refinement trajectories.
- Reproducibility: Codebases not explicitly stated as released; dataset (PlaytestArena) partially curated from public sources but mainly constructed by authors. Backbones are known LLM APIs/models. Appendices provide detailed workflows and memory schema. Overall, some implementation details and artifacts appear closed or unpublished at time of writing.
Concrete example (Snake game): The GUI agent observes game screen, tracks snake and apple locations, reasons step-by-step the next moves using keys (ArrowLeft, ArrowUp, etc.), acts to control snake to eat apple, updates plans dynamically after each state change. This interaction loop demonstrates genuine gameplay testing capturing dynamics no static code check could see.
Technical innovations
- Introduction of PlaytestArena: A large, rubric-annotated benchmark of 200 multi-genre browser-based games with executable playtesting evaluation via GUI agents.
- Positioning GUI agents as surrogate human playtesters that interact through visual perception and input emulation, enabling objective, interaction-level evaluation beyond static code correctness.
- Development of Play2Code: a continual game generation framework coupling a game code-producing agent and a GUI agent playtester in a bidirectional loop mediated by a layered shared memory system for accumulating knowledge across rounds and tasks.
- Demonstration that GUI agent-driven playtesting provides actionable, traceable feedback that improves game quality iteratively, outperforming single-pass code generation and non-playtesting agentic baselines by large margins.
Datasets
- PlaytestArena — 200 games — curated browser-based HTML/JS games across 8 genres with expert-annotated rubrics
- 20-game testbed with ~120 levels — curated mix of LLM-generated and public web games — used for GUI agent and human playtesting baseline
Baselines vs proposed
- Direct LLM generation: average rubric pass rate = 29.7% vs Play2Code: 66.8%
- OpenGame agentic-coding (non-playtesting iteration): 52.2% vs Play2Code: 66.8%
- GUI agent pass@20 on 120-level testbed: GPT-5.4 = 82% vs human reference = 92%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28258.
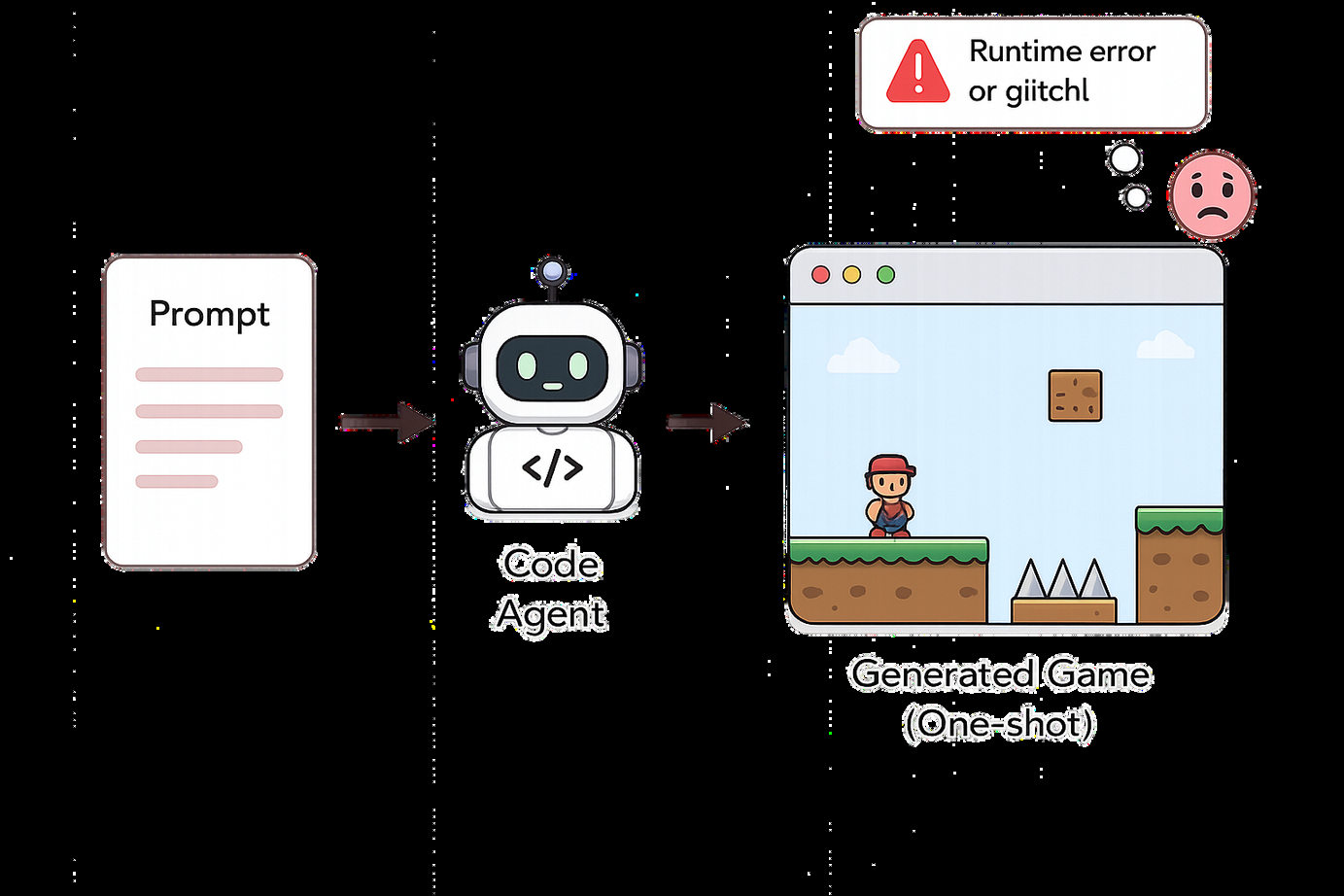
Fig 1: Three paradigms for AI-driven game generation. Unlike prior one-shot or runtime-probing pipelines,
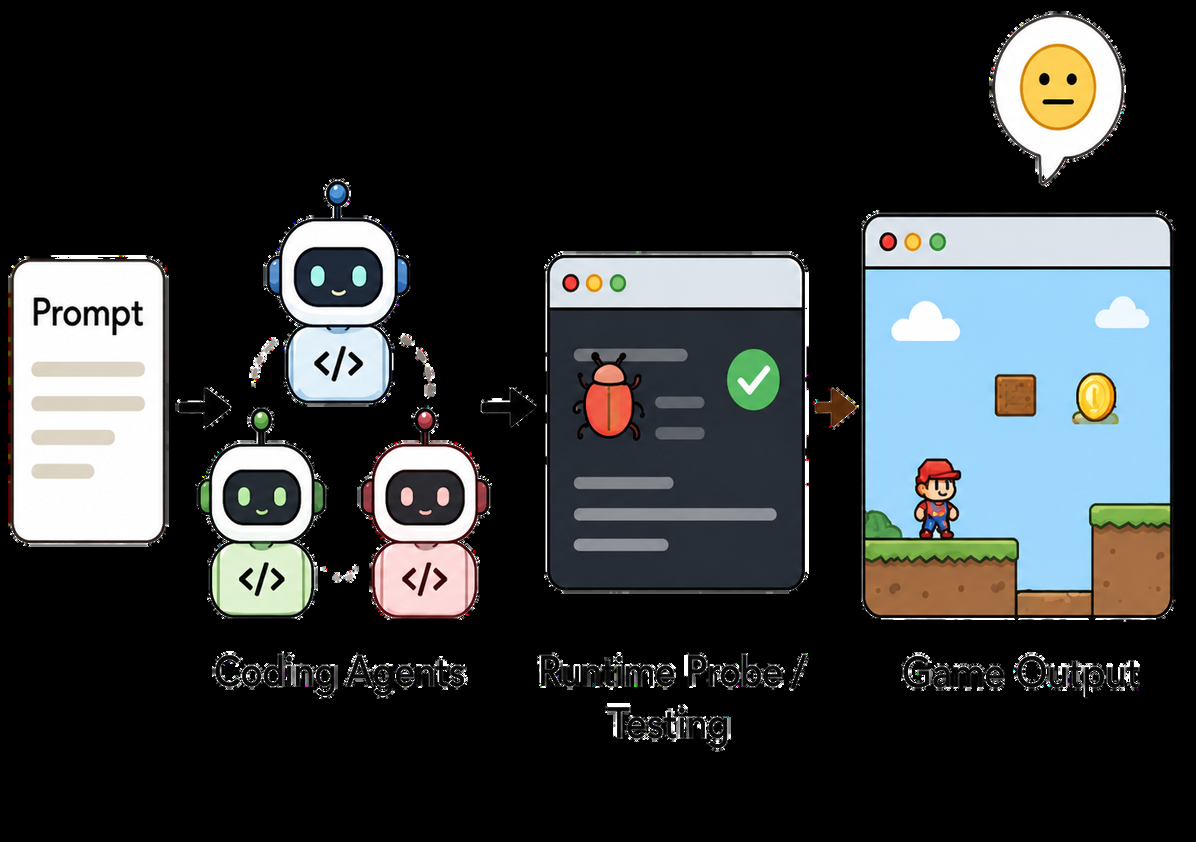
Fig 2: An example GUI agent session playing Snake. At each grid step, the agent observes the current screen,
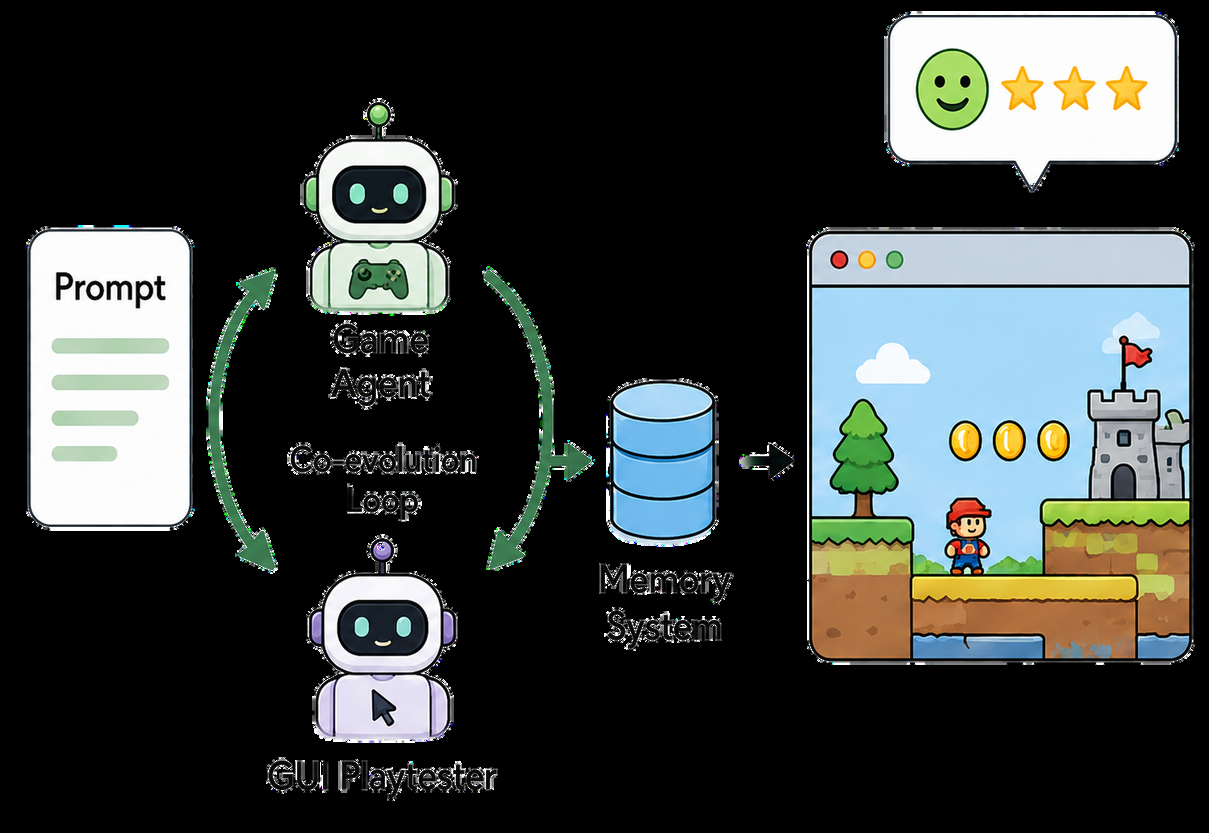
Fig 3: Statistics of PlaytestArena: (a) distribution of
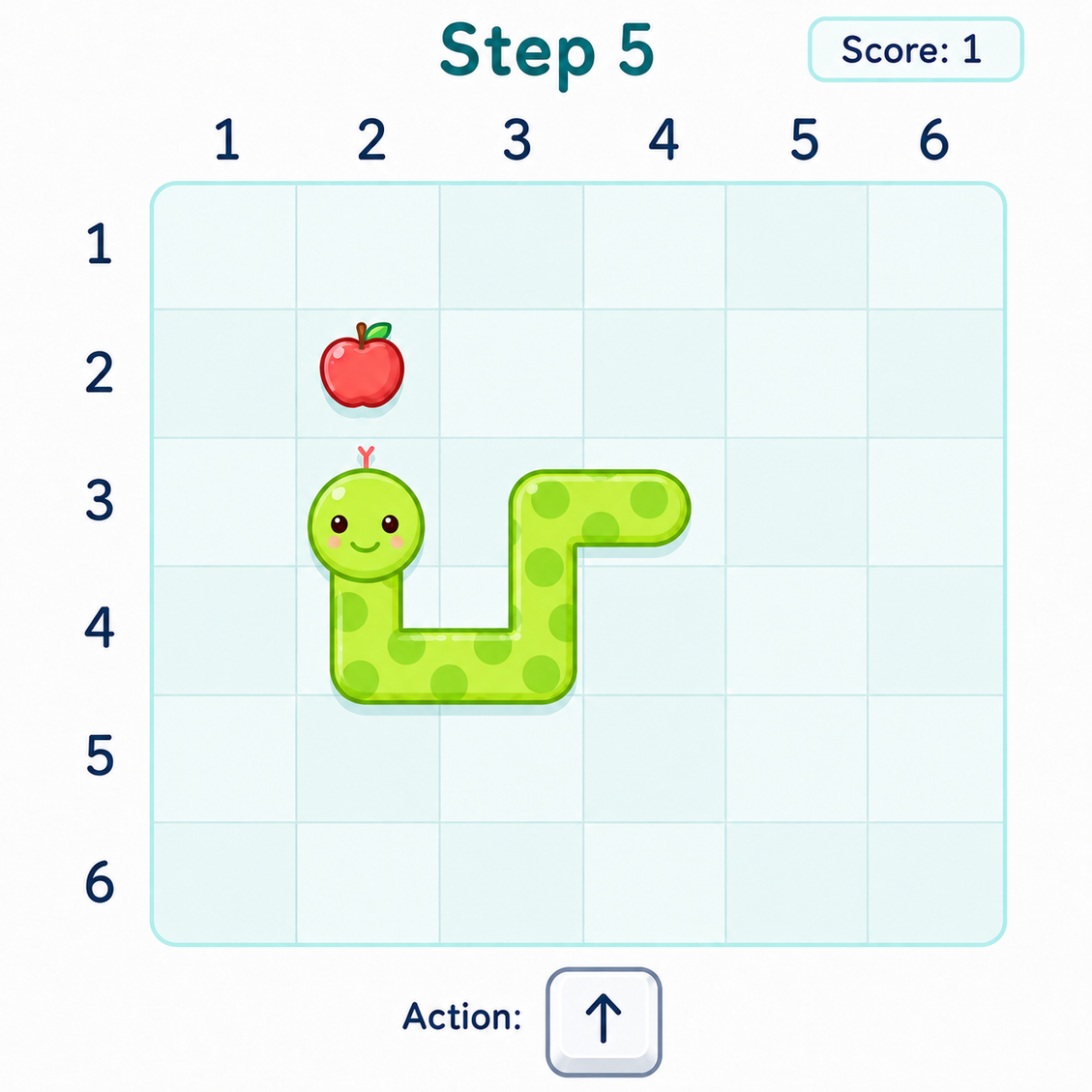
Fig 4: Overview of Play2Code. A game agent and GUI agent operate in a loop: the game agent generates or
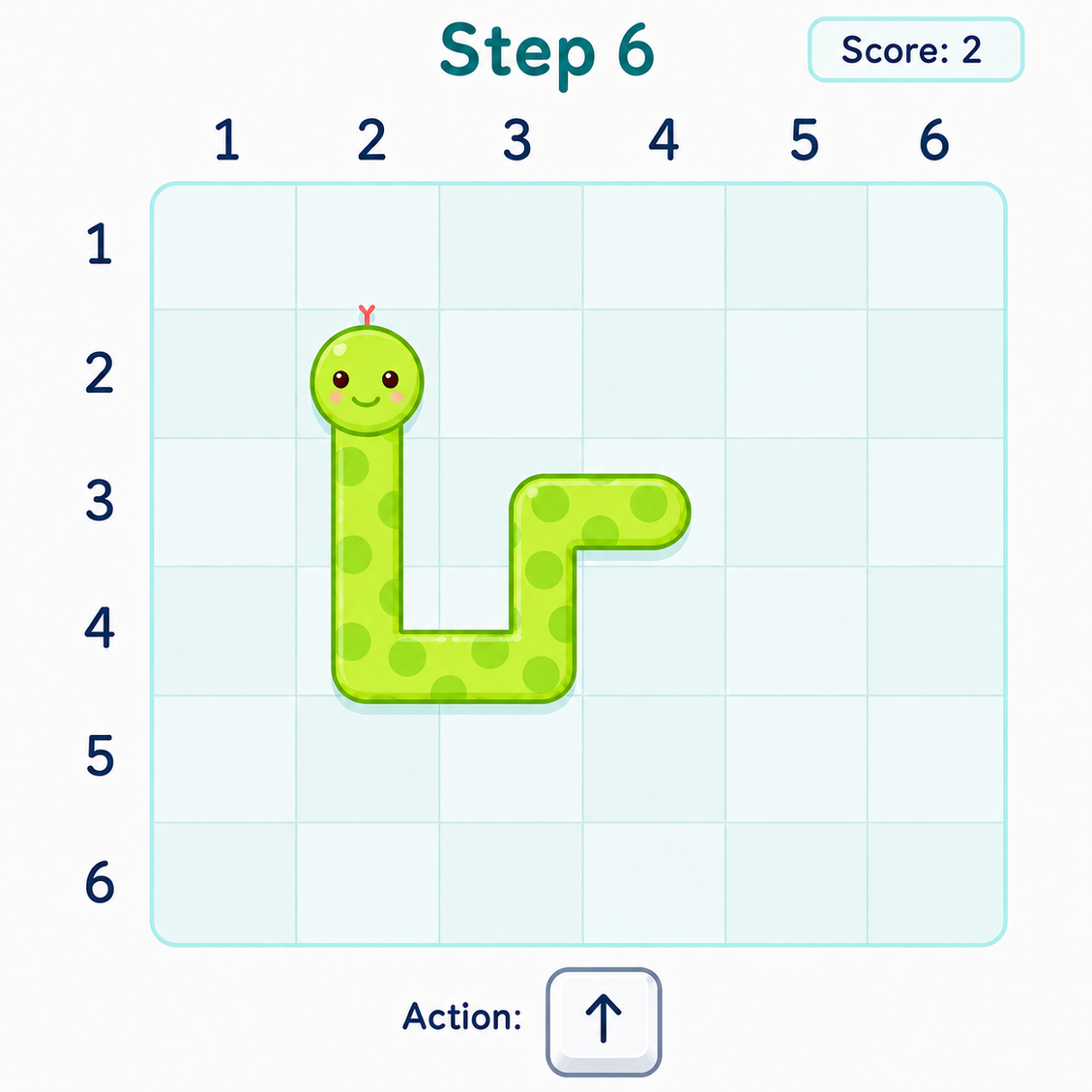
Fig 5 (page 3).
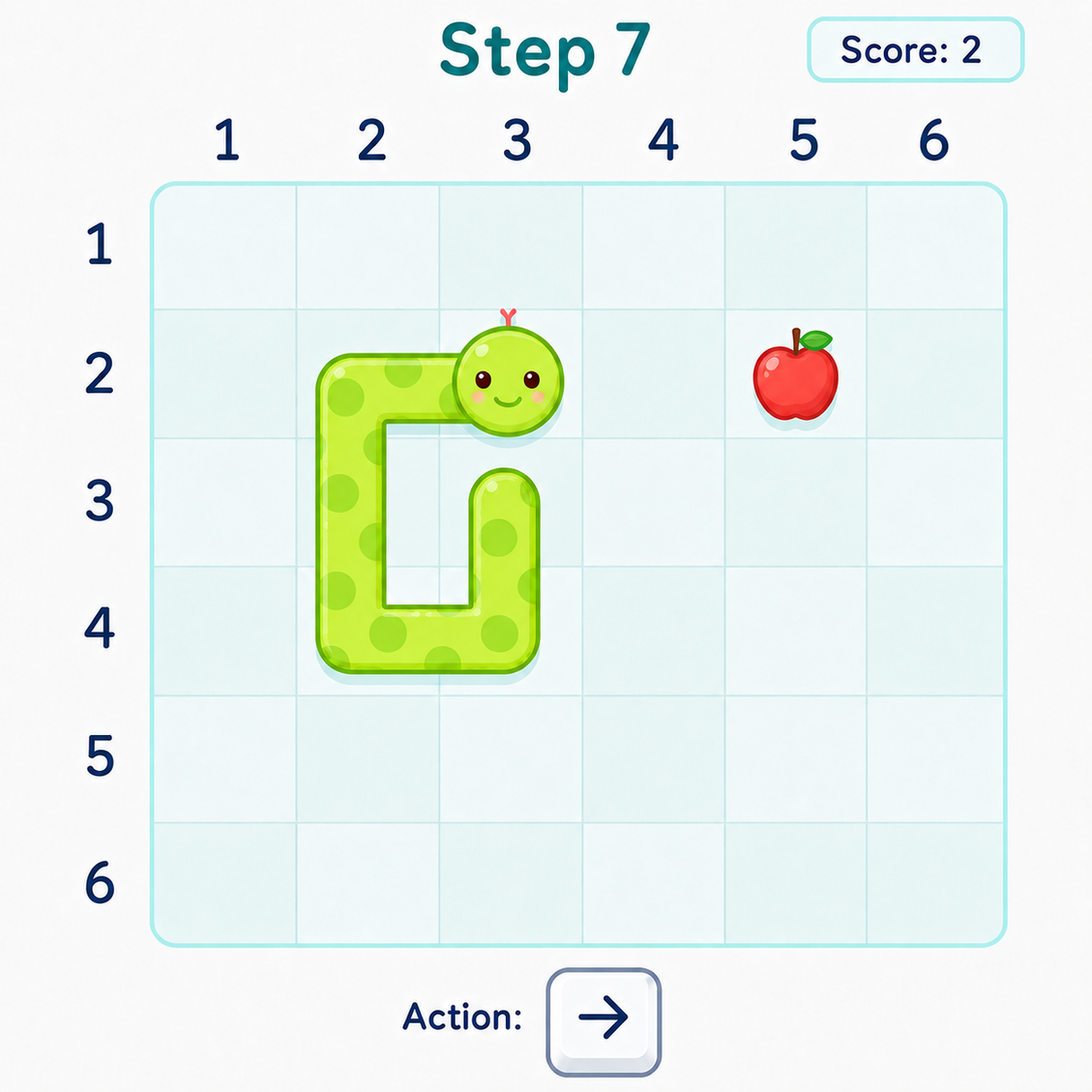
Fig 6 (page 3).

Fig 7 (page 3).

Fig 8 (page 3).
Limitations
- Current implementation and benchmark focus exclusively on browser-based HTML/JS games; extension to native, 3D, or more complex engines remains future work.
- PlaytestArena's curated game set controls quality but does not cover full diversity or complexity of real-world games, limiting ecological validity.
- The memory system is global and shared across all games; finer grain, genre-aware, or game-specific memory schemas might further enhance learning and adaptation.
- GUI agent capabilities constrain effectiveness on high-complexity games, where complex mechanics are hard to reliably trigger and test.
- No extensive adversarial or distribution-shift robustness evaluation of GUI agents or generated games is conducted.
- Human aspects such as subjective judgments of difficulty, fun, or aesthetics remain beyond current automated agents' scope.
Open questions / follow-ons
- How to extend GUI agent playtesting to more complex game modalities beyond browser HTML/JS, such as 3D engines or native platforms?
- What architectural or training improvements could enhance GUI agent capability to reliably trigger and test complex game mechanics, enabling better refinement on high-complexity games?
- Can game- or genre-specific memory structures improve knowledge reuse and accelerate continual learning beyond the global memory system used?
- How to integrate or approximate subjective human feedback dimensions (fun, difficulty, engagement) into automated GUI agent playtesting?
Why it matters for bot defense
This paper provides a compelling case for embedding GUI agents as interactive testers to close the gap between code correctness and functional, user-facing quality in generated artifacts. For bot defense and CAPTCHA practitioners, the notion of GUI agents operating over visual interfaces with action-feedback loops parallels challenges in automated test and validation of interactive systems, including CAPTCHA designs that rely on dynamic, behavioral criteria. The layered memory and feedback loop design in Play2Code offers a framework for continual refinement through observation and actuation, relevant to evolving bot-detection systems that must adapt to sophisticated attackers. Moreover, the traceability and structure of GUI-driven feedback overcomes brittleness in single-step artifact assessment, an insight broadly applicable for designing scalable, interpretable automated evaluation frameworks in bot defense. While the domain is games, the principles of interactive, perceptual evaluation driving iterative refinement inform CAPTCHA lifecycle management and adaptive test design.
Cite
@article{arxiv2605_28258,
title={ GUI Agents for Continual Game Generation },
author={ Yixu Huang and Bo Li and Na Li and Zhe Wang and Kaijie Chen and Haonan Ge and Qingyi Si and Yuanzhe Shen and Ruihan Yang and Guangjing Wang and Hongcheng Guo },
journal={arXiv preprint arXiv:2605.28258},
year={ 2026 },
url={https://arxiv.org/abs/2605.28258}
}