
Fewer simulations, sharper covariances: Reducing mock covariance noise with Zeldovich approximation control variates
Source: arXiv:2605.28817 · Published 2026-05-27 · By Boryana Hadzhiyska, Martin White
TL;DR
This paper addresses the computational challenge of estimating accurate covariance matrices for large-scale structure (LSS) power spectrum measurements, which are critical inputs to cosmological parameter inference in current and upcoming surveys like DESI, Euclid, and LSST. Traditional sample covariance estimation from simulations requires thousands to tens of thousands of mock catalogs to achieve percent-level precision, owing to slow convergence rates. The authors leverage a control variate (CV) technique using computationally cheap Zeldovich approximation realizations paired with each target mock to remove correlated sample variance and accelerate covariance estimation convergence. They derive fully analytic expressions for the optimal CV weight β and correlation coefficient ρ between the target and control covariance estimators under a Gaussian disconnected covariance approximation.
Empirically, applying this method to realistic masked redshift-space lognormal mocks that resemble DESI LRG samples shows the CV estimator reduces covariance variance by roughly an order of magnitude on very large scales (k ≲ 0.05 h/Mpc), where traditional covariance estimation is most challenging. At smaller scales, convergence accelerates by a factor of 2–3, substantially lowering the necessary simulation budget. The analytic CV weights closely match brute-force estimates from 10,000 simulations, confirming the approach’s accuracy and robustness even in the presence of survey masking-induced mode coupling. The method’s simplicity and effectiveness make it immediately applicable for improving covariance estimation efficiency in existing and future LSS surveys.
Key findings
- Control variate estimator reduces covariance matrix variance by ~10× at large scales (k ≲ 0.05 h/Mpc) for masked redshift-space lognormal mocks.
- Variance reduction enables ~1,000 paired simulations to achieve precision equivalent to ~10,000 standard independent simulations, accelerating convergence by an order of magnitude on large scales.
- At smaller scales (k ≳ 0.1–0.2 h/Mpc), variance reduction gains diminish, but convergence still improves by a factor of ~2–3.
- Analytic expressions for optimal CV weights β(k, ℓ; k', ℓ') and correlation ρ(k, ℓ; k', ℓ') derived under Gaussian approximation track brute-force estimates from 10,000 simulations very well (Figs 2–4).
- Cross-correlation coefficient r(k) between target lognormal and control Zeldovich fields governs CV efficacy; ρ(k,k') = r²(k)r²(k') for monopole case.
- Survey mask breaks translation invariance and induces off-diagonal covariance, but the CV method remains effective using masked power spectra and FKP weighting.
- Reusing monopole-based analytic CV weights for higher multipoles (quadrupole) yields unbiased estimates with stable variance reduction.
- Lognormal mocks reproduce the key decorrelation behavior of realistic DESI LRG mocks, validating lognormal tests as a proxy for real tracer fields.
Methodology — deep read
Threat model & assumptions: The adversary here is the inherent statistical noise in sample covariance estimation of the galaxy power spectrum from finite mock catalogs under realistic survey conditions, including redshift-space distortions and masking. There is no malicious adversary - the problem is variance reduction of covariance estimators. The method assumes Gaussian disconnected covariance (independent Fourier modes) to derive analytic control variate weights.
Data: The study uses paired simulations consisting of computationally expensive target mocks—lognormal realizations approximating LRG galaxy fields at z=0.5 with bias b=2.2 and number density n=10⁻³ (h⁻¹ Mpc)⁻³—alongside cheap control mocks generated via the Zeldovich approximation sharing the same initial Gaussian random phases. Each simulation is performed in a 2000 Mpc/h box with 3D cubic grids, applying a DESI South Galactic Cap-like survey mask to induce realistic mode coupling and break periodicity.
Architecture / algorithm: The core idea is a control variate estimator for covariance matrix elements. For each covariance matrix element indexed by (k, ℓ; k', ℓ'), the control variate estimator subtracts a weighted difference between the sample covariance of the control field (Zeldovich mocks) and its known expectation:
Y_ij = X_ij - β_ij (C_ij - μ_ij)
where X_ij is the sample covariance element from target mocks, C_ij that from control mocks, and μ_ij the (high-precision) expected control covariance estimated from 10,000 control-only realizations. β_ij is the optimal weight minimizing the variance of Y, given analytically under Gaussian assumptions by
β_ij = Cov[X_ij, C_ij] / Var[C_ij]
and the maximal variance reduction factor depends on the correlation ρ_ij between X_ij and C_ij.
Training regime: They run 10,000 Zeldovich mocks (control-only) to estimate μ and variance terms with high precision. They generate N_sim=1000 paired lognormal + Zeldovich mocks to compute sample covariances X and C and validate the analytic β and ρ against brute-force estimates from splitting mocks into batches.
Evaluation protocol: The method is evaluated by comparing variance reduction obtained applying the CV estimator Y relative to standard sample covariance X on covariance matrix diagonal and off-diagonal blocks for monopole (ℓ=0) and quadrupole (ℓ=2) power spectrum multipoles in redshift space with survey mask. Analytic β and ρ matrices derived from power spectra ratios are checked against brute-force estimates. Variance ratios Var[X]/Var[Y] quantify acceleration equivalence in number of mocks needed. Correlation values near unity at large scales correspond to large gains.
Reproducibility: The study uses open source codes such as CLASS for linear power spectrum, nbodykit for lognormal mocks, and abacusutils for power spectrum estimation. While the exact sets of simulated mocks (e.g. DESI-like mask) are not explicitly public, the methods are straightforward to implement given the analytic formulas. No frozen weights are involved since this is a simulation-statistics methodology rather than a learned model.
Concrete example: For a given k-bin at low k ~ 0.02 h/Mpc and ℓ=0, from 1000 paired mocks the sample covariance X_ij is noisy with fractional errors ~sqrt(2/N_sim). Using the analytic expressions for power spectra, β_ij weights are computed elementwise as ratios of squared cross-power to auto-power spectra, reflecting strong correlation (r ~ 0.95). Subtracting the CV term using 10,000 control mocks reduces covariance variance by ~10× on these large scales, effectively amplifying the statistical power as if having 10,000 mocks without actually generating them. This is confirmed by splitting simulations into batches and comparing analytic β to brute-force estimates (Fig 3).
Technical innovations
- Pairing expensive target mocks with cheap Zeldovich-approximation mocks sharing the same initial conditions as control variates to reduce covariance noise.
- Derivation of fully analytic, closed-form expressions for optimal CV weights β(k, ℓ; k', ℓ') and correlation coefficients ρ(k, ℓ; k', ℓ') under a Gaussian disconnected covariance approximation.
- Extension of the CV framework to redshift-space multipoles with complex survey masks, handling mode coupling approximately via reuse of monopole-based weights.
- Demonstration that the CV variance reduction factor depends primarily on the squared cross-correlation coefficient between target and control fields, ρ(k,k')=r²(k)r²(k'), enabling predictive analytic estimates.
Datasets
- Lognormal mock catalogs resembling DESI Luminous Red Galaxies — 1000 paired realizations used for target and control covariance estimation — synthetic/mock
- Zeldovich approximation simulations used as control covariate — 10,000 realizations for precise mean covariance estimation — synthetic/mock
Baselines vs proposed
- Standard sample covariance estimator from 10,000 mocks: covariance variance baseline = 1; CV estimator from 1,000 paired mocks achieves equivalent variance reduction (factor ~10 improvement) on large scales k ≲0.05 h Mpc⁻¹.
- Variances on covariance matrix elements at k ~0.1 h/Mpc: CV method accelerates convergence by factor 2–3 relative to standard estimator.
- Analytic control variate weights β closely match brute-force estimates from 10,000 simulations across multipole blocks, validating Gaussian approximation and monopole reuse for quadrupole.
- Correlation coefficient ρ between target and control covariance matrices approaches unity on large scales and drops near zero at k ≈0.2 h/Mpc, explaining scale dependence of variance reduction.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28817.
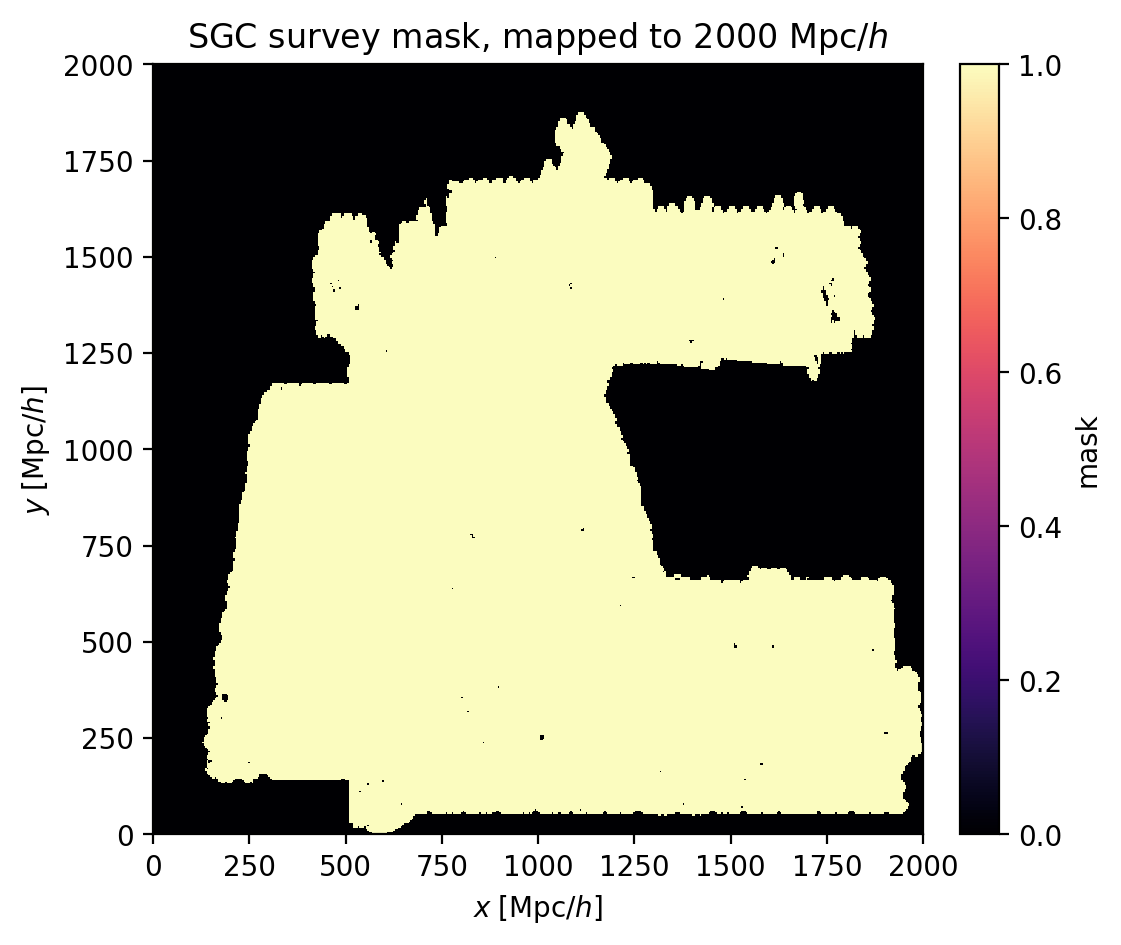
Fig 1: DESI South Galactic Cap (SGC) survey mask applied
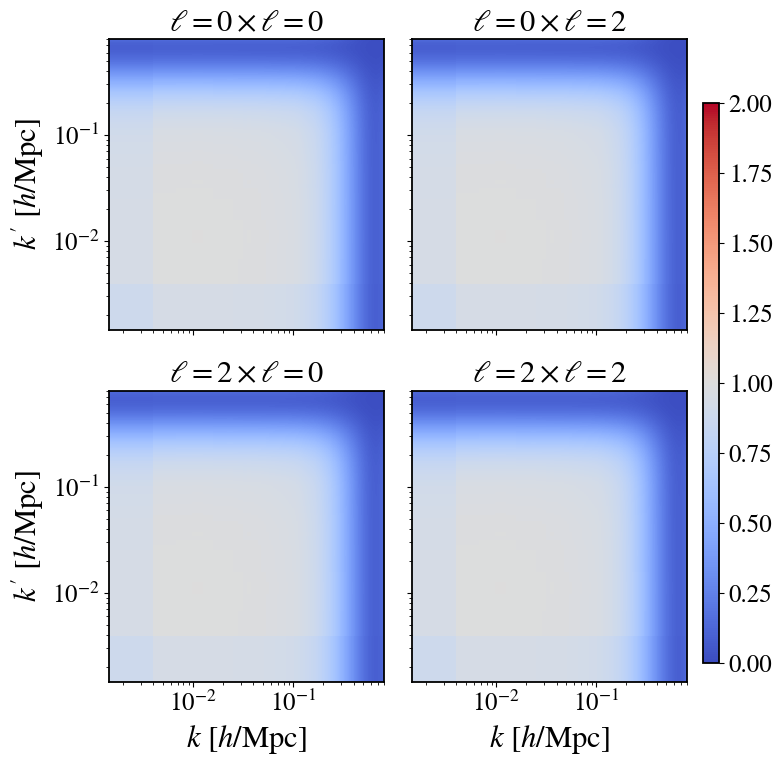
Fig 2: Comparison of the CV weight matrix β(k, ℓ; k′, ℓ′) in redshift space with a DESI-like survey mask. Left: analytic β.
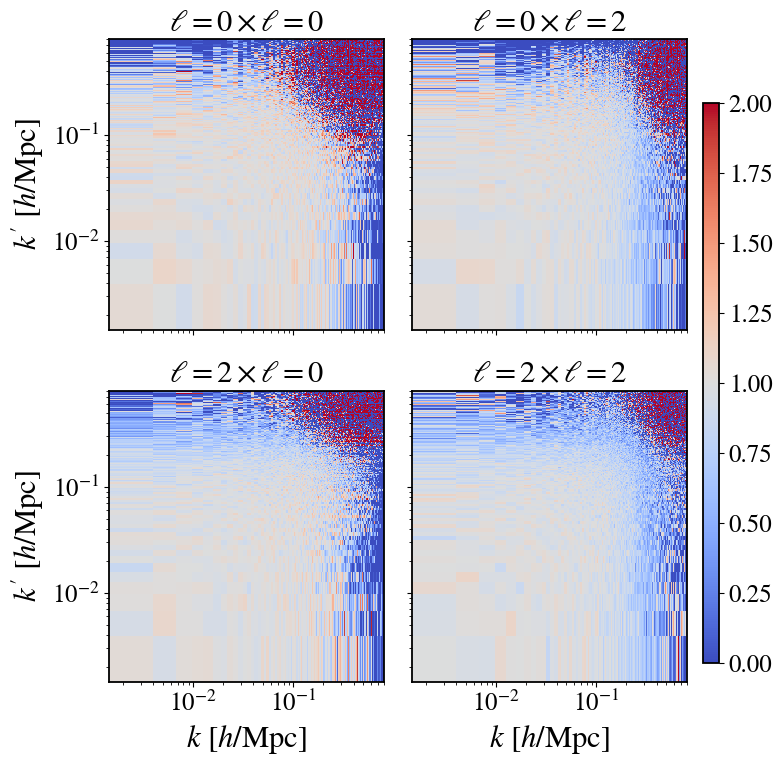
Fig 3: Diagonal comparison of the CV weight β between analytic and brute-force constructions in redshift space with mask.
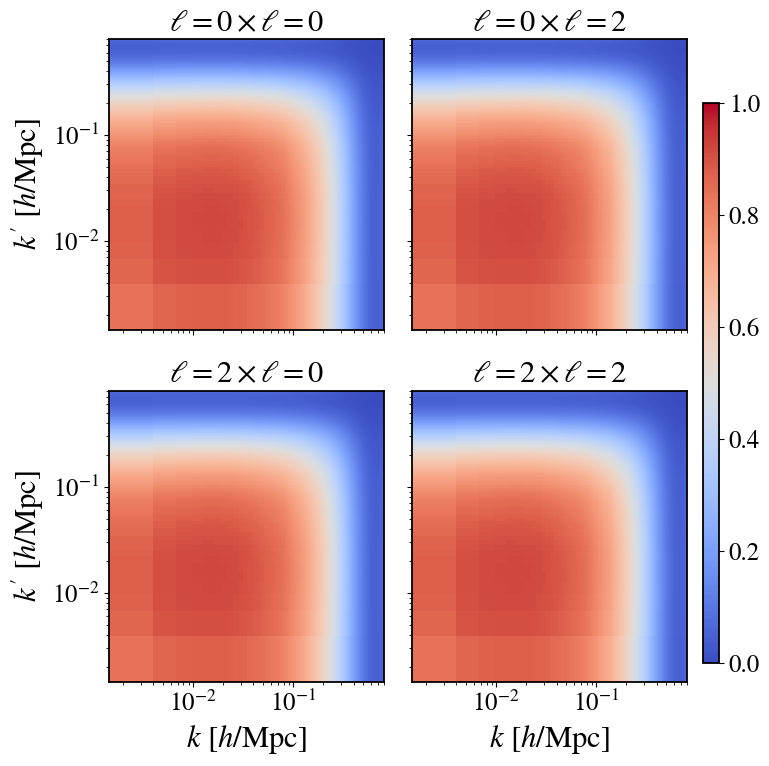
Fig 4: Comparison of the CV correlation coefficient ρ(k, ℓ; k′, ℓ′) in redshift space with survey mask.
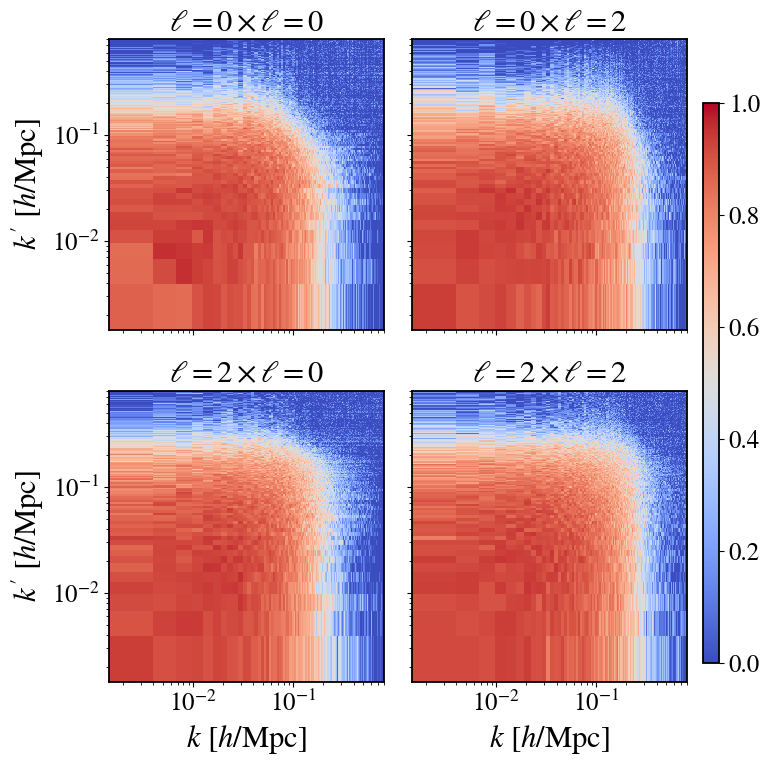
Fig 5: Effect of control variates on redshift-space covariance estimates for the realistic (masked) survey.
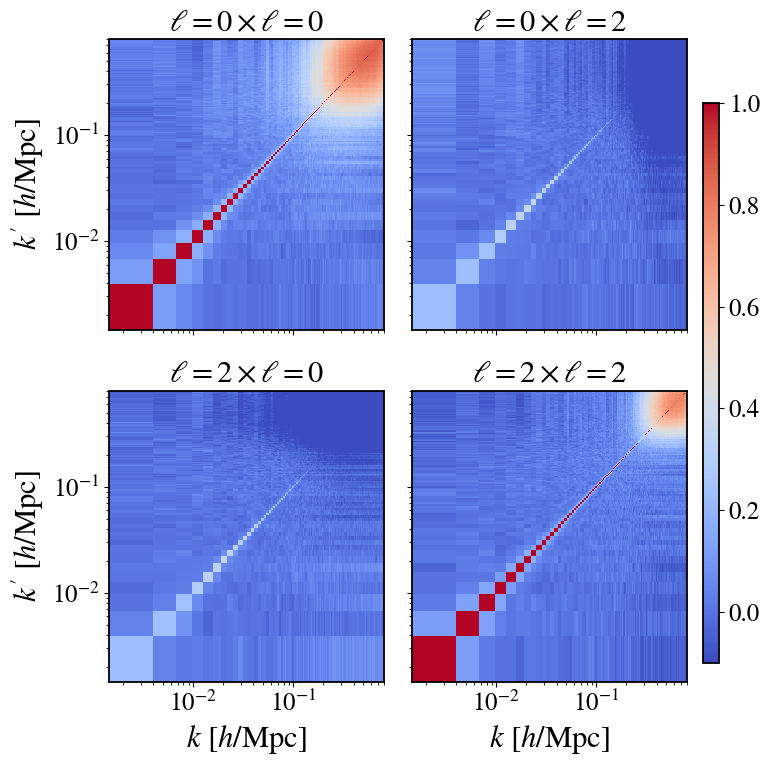
Fig 6: Diagonal comparison between the original covariance estimate X and the CV-corrected covariance estimate Y in
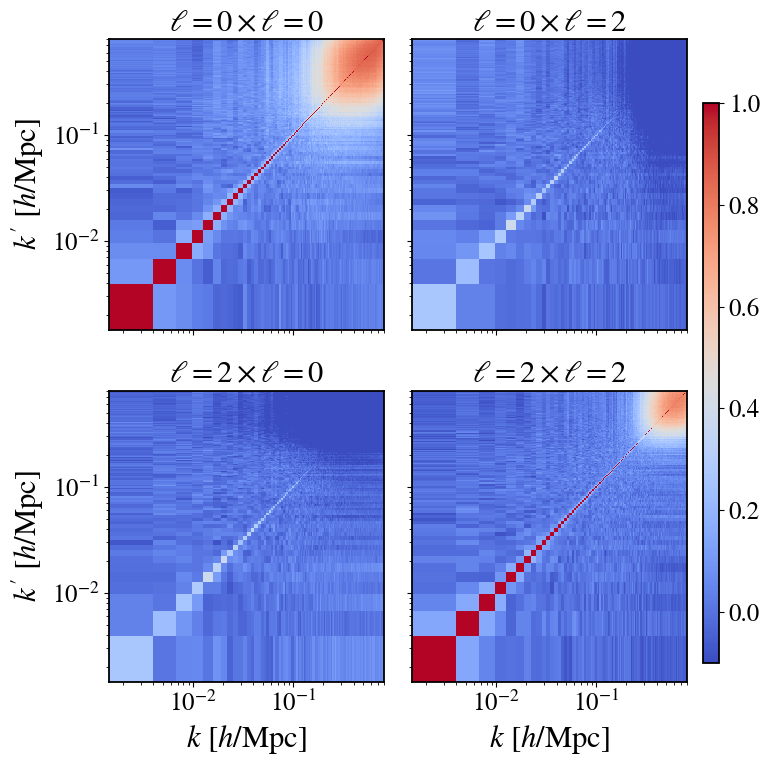
Fig 7: shows two maps side by side: (i) the analytic pre-
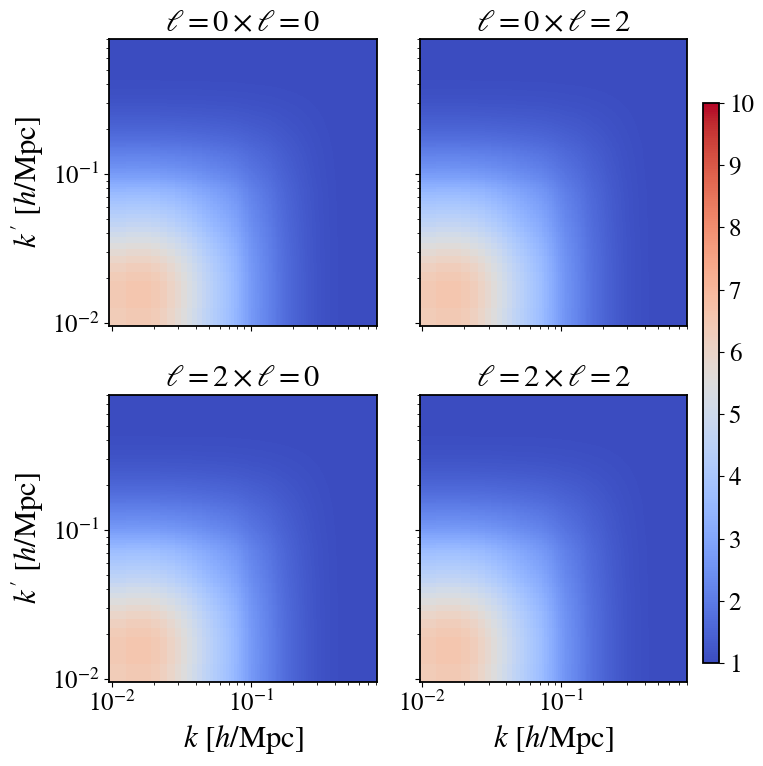
Fig 8: Variance ratio Var[X]/Var[Y ] on diagonal slices for the realistic redshift-space, masked survey.
Limitations
- Gaussian disconnected covariance approximation underpins derivations; non-Gaussian connected terms and exact mode coupling from survey masks may degrade CV optimality.
- Control variate efficacy decreases at smaller scales (higher k) where the correlation between target and Zeldovich fields drops sharply.
- Lognormal mocks serve as a proxy for realistic galaxy fields but do not capture full nonlinear structure formation and may misrepresent small-scale clustering.
- Reusing monopole-based analytic weights for higher multipoles is an approximation whose accuracy may vary with tracer bias and redshift-space distortions.
- The approach requires generating paired mocks with identical initial conditions, which may complicate workflows in some simulation pipelines.
- Performance depends on accurate, low-noise estimation of the control field mean covariance μ from large ensembles of control-only simulations.
Open questions / follow-ons
- How does the presence of non-Gaussian connected covariance terms and non-linear clustering affect the control variate estimator’s optimality and bias?
- Can the analytic control variate weights be extended beyond the Gaussian disconnected approximation to handle realistic survey window-induced mode coupling and multipole correlations more exactly?
- What is the impact of varying tracer bias, redshift, and number density on the cross-correlation between target and control fields and consequently on CV performance?
- How can the approach be integrated with other covariance noise reduction methods (e.g., shrinkage estimators or emulators) for further gains?
Why it matters for bot defense
While this work is fundamentally about variance reduction in astrophysical covariance matrix estimation, the core principle of using control variates to remove correlated noise could be inspirational for bot-defense or CAPTCHA analysis where high-variance estimators impede robust decisioning. For practitioners of covariance estimation in security telemetry or web traffic metrics, pairing expensive measurements with cheaper approximations that share underlying random seeds or structure, then employing analytic weights to optimally combine could accelerate convergence and reduce false positive rates in behavioral classifiers. The key insight that strong correlation of the control approximation with the target allows large variance reductions with minimal bias suggests exploring analogous cheap surrogate models in bot detection pipelines. Although the cosmological context and data differ, the statistical technique and analytic formulation provide a framework for variance reduction in complex, high-dimensional estimators common to CAPTCHAs and bot-defense systems.
Cite
@article{arxiv2605_28817,
title={ Fewer simulations, sharper covariances: Reducing mock covariance noise with Zeldovich approximation control variates },
author={ Boryana Hadzhiyska and Martin White },
journal={arXiv preprint arXiv:2605.28817},
year={ 2026 },
url={https://arxiv.org/abs/2605.28817}
}