
Do Agents Need Semantic Metadata? A Comparative Study in Agentic Data Retrieval
Source: arXiv:2605.28787 · Published 2026-05-27 · By Shiyu Chen, Tarfah Alrashed, Alon Halevy, Natasha Noy
TL;DR
This paper investigates whether semantic metadata remains necessary for autonomous agents performing data retrieval, given the rise of large language models (LLMs) capable of navigating the unstructured web. The authors compare two agentic data retrieval systems: a Baseline Agent that searches billions of unstructured web documents via conventional web search, and a Semantic Agent that queries a curated corpus of 90 million datasets enriched with schema.org semantic metadata (Google Dataset Search). They evaluate the retrievals through an innovative multi-dimensional "LLM-as-a-judge" pipeline mapped directly to FAIR principles (Findable, Accessible, Interoperable, Reusable), measuring dataset relevance, accessibility, and computational utility. Results reveal a trade-off: the Baseline Agent achieves broader coverage (answering 40% more queries) but much lower precision and actionability, frequently retrieving prose-heavy or portal pages. The Semantic Agent achieves significantly higher precision (65.7% higher overall precision of FAIR-compliant datasets), with 44.9% more metadata-rich registries and 46.6% more machine-readable downloads among its results. The authors conclude that unstructured retrieval aids exploratory data discovery, but the semantic metadata ecosystem is indispensable for reliable, execution-oriented autonomous workflows.
Key findings
- Semantic Agent achieves 44.9% higher precision for metadata-rich dataset registries compared to Baseline Agent.
- Semantic Agent achieves 46.6% higher precision for datasets with machine-readable downloads versus Baseline Agent.
- Baseline Agent suffers 'Last-Mile Utility' failures: 20.1% of its results are prose-heavy pages, 8.5% are portal landing pages instead of actual data pages.
- Baseline Agent answers 40% more queries than Semantic Agent due to broader web coverage.
- Semantic Agent attains 65.7% higher overall precision in retrieving datasets that meet strict FAIR criteria (high relevance, machine-readable, data registry page type).
- On dataset page types, Semantic Agent returns 88.4% DATA_REGISTRY pages vs 61.0% for Baseline Agent, a 44.9% relative increase.
- Semantic Agent reduces Narrative/Unstructured data pages by 46.6%, Presentation-Bounded pages by 62.9%, and Non-Data pages by 76.3% relative to Baseline Agent.
- Dataset-level precision: Baseline Agent 28.0%, Semantic Agent 46.4% (p < 0.01)
Threat model
The adversary in this work is an autonomous data retrieval agent operating either over the unstructured web or a semantic metadata corpus, tasked with finding machine-actionable datasets. The model assumes that agents cannot easily manipulate or forge metadata at scale, and the semantic metadata corpus is filtered for quality to exclude invalid annotations. Adversaries cannot bypass authentication or paywalls during autonomous retrieval; instead, human intervention is expected in these cases. The agent faces noisy, unstructured web content and must avoid false positives that could cause downstream execution failures.
Methodology — deep read
Threat Model & Assumptions: The study assumes autonomous agents as adversary-contexts requiring machine-actionable datasets to perform workflows reliably. The adversary here is an agent-driven retrieval system trying to find and act on datasets. The agents operate under fixed tool execution conditions and query operators do not deliberately manipulate metadata or responses. The Semantic Agent cannot access unstructured web content beyond metadata-enriched dataset pages, while the Baseline Agent explores the entire structured and unstructured web except filtered by query expansion.
Data: The main datasets consist of the live Google Search index (billions of documents) accessed by the Baseline Agent and the Google Dataset Search index (90 million schema.org/Dataset metadata entries) accessed by the Semantic Agent. Queries come from the NTCIR-16 English keyword-based ad-hoc data search benchmark (N=58 queries) representing authentic real-world data discovery intents across domains such as economics and public health. Data was split naturally by query; both agents processed identical queries independently.
Architectures: Both agents use identical base architectures: the Agent Development Kit (ADK) powered by Gemini 2.5 Pro LLM, with temperature 0 to maximize reproducibility, returning a max of 3 datasets per query. The Baseline Agent queries the entire Google Search index with intentional query expansion appending "dataset" keywords to better target data. It retrieves URLs and synthesized snippets extracted from unstructured pages. The Semantic Agent queries only the Google Dataset Search index filtering with schema.org metadata, requiring no query expansion. It retrieves URLs paired with rich semantic metadata describing each dataset.
Training Regime: The underlying LLM (Gemini 2.5 Pro) is externally pre-trained by Google; the study does not involve retraining but adapts prompt engineering and tool integration within ADK. Both agents are prompted symmetrically with queries and structured task instructions emphasizing dataset retrieval relevance and FAIR principles. Prompt details and chains-of-thought are publicly disclosed for reproducibility.
Evaluation Protocol: Evaluation uses a novel, multi-dimensional LLM-as-a-judge framework, also running on Gemini 2.5 Pro. The LLM evaluates live snapshots of retrieved pages, extracting evidence and scoring on three FAIR-aligned dimensions: relevance to query (scored -1 to 2), data accessibility (6-level rubric from unreachable to machine-readable), and dataset page type (registry, raw data, narrative, etc.). Cohen’s kappa inter-rater reliability with human gold standards ranges 0.7-0.95, confirming reliability. Approximately 31% of pages required human evaluation due to scraping or complexity issues to avoid bias. Statistical significance testing was applied (p-values reported).
Reproducibility: The authors publish exact prompts, rubrics, and details about the LLM-based autoraters to enable replication. Data sources (Google indexes) are proprietary. The use of live web-scale corpora rather than static collections enhances ecological validity but limits reproducibility to some extent. The code for the ADK agents and autoraters is publicly referenced.
Technical innovations
- Introduction of a multi-dimensional LLM-as-a-judge evaluation pipeline explicitly mapped to FAIR data principles (Findable, Accessible, Interoperable, Reusable), extending beyond traditional relevance metrics.
- Comparative analysis framework isolating the effect of semantic metadata (schema.org) by evaluating near-identical autonomous agent architectures over fundamentally different corpora (unstructured open web vs. structured metadata corpus).
- Demonstration that schema.org-enabled dataset corpus acts as a filter that fundamentally shapes retrieval scale, search behavior, and agent performance, objectively quantifying "last-mile" utility failures of unstructured web retrieval.
- Empirical quantification of trade-offs between broad exploratory recall and high precision machine-actionability in autonomous data retrieval, informing hybrid agent design balancing breadth and precision.
Datasets
- NTCIR-16 Data Search English keyword queries — 58 queries — public benchmark
- Google Search Index — billions of web pages — proprietary live web crawl
- Google Dataset Search Index — 90 million dataset metadata records with schema.org markup — proprietary curated corpus
Baselines vs proposed
- Baseline Agent: dataset-level FAIR-compliant precision = 28.0% vs Semantic Agent: 46.4% (65.7% relative improvement, p < 0.01)
- Baseline Agent: 60.4% datasets scored 'Highly Relevant' vs Semantic Agent: 60.7%
- Baseline Agent: 48.7% machine-readable data vs Semantic Agent: 71.4% (46.6% relative increase)
- Baseline Agent: 61.0% DATA_REGISTRY page type vs Semantic Agent: 88.4% (44.9% relative increase)
- Baseline Agent: 20.1% prose-heavy pages (DATA_NARRATIVE) vs Semantic Agent: 13.4% (46.6% reduction)
- Baseline Agent answered 56 queries vs Semantic Agent 40 queries (40% fewer)
- Query-level FAIR dataset density: Baseline Agent 0.82 vs Semantic Agent 1.30 (difference not statistically significant)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28787.
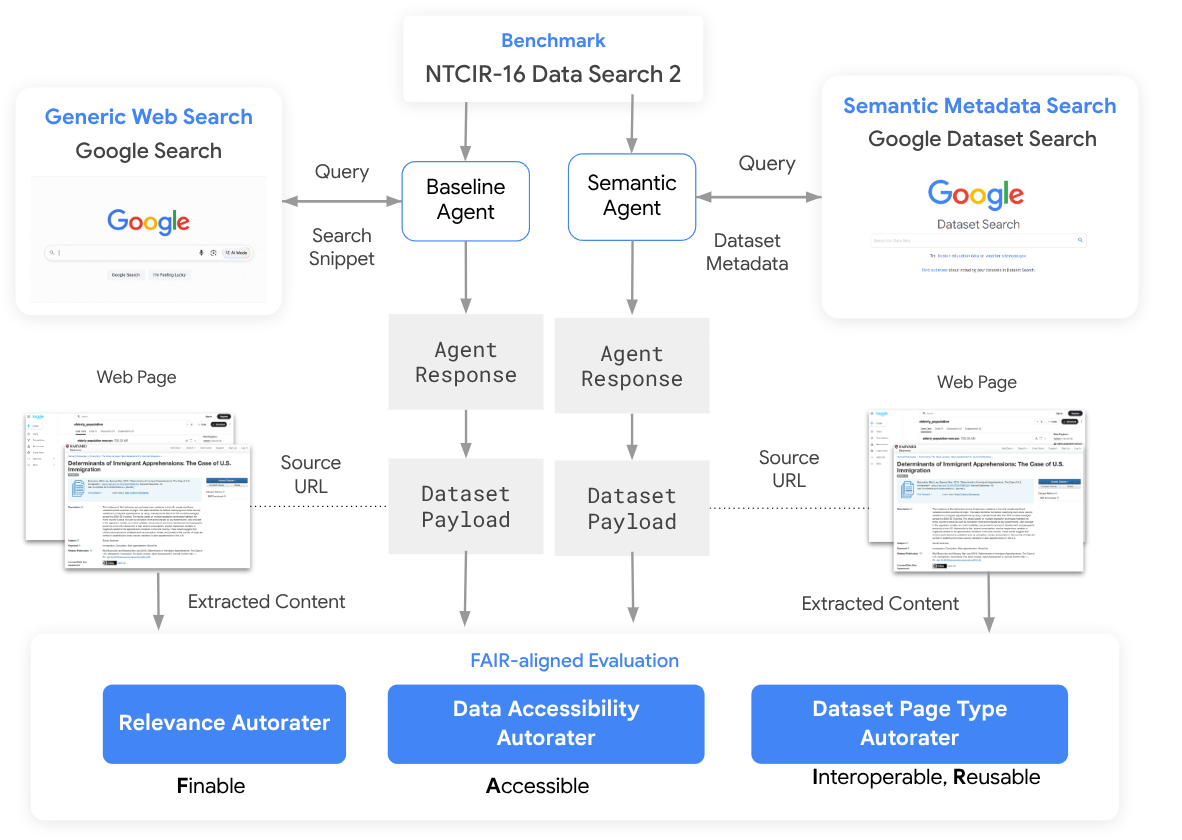
Fig 1: Comparative System Architecture. Similar agent logic is evaluated across un-
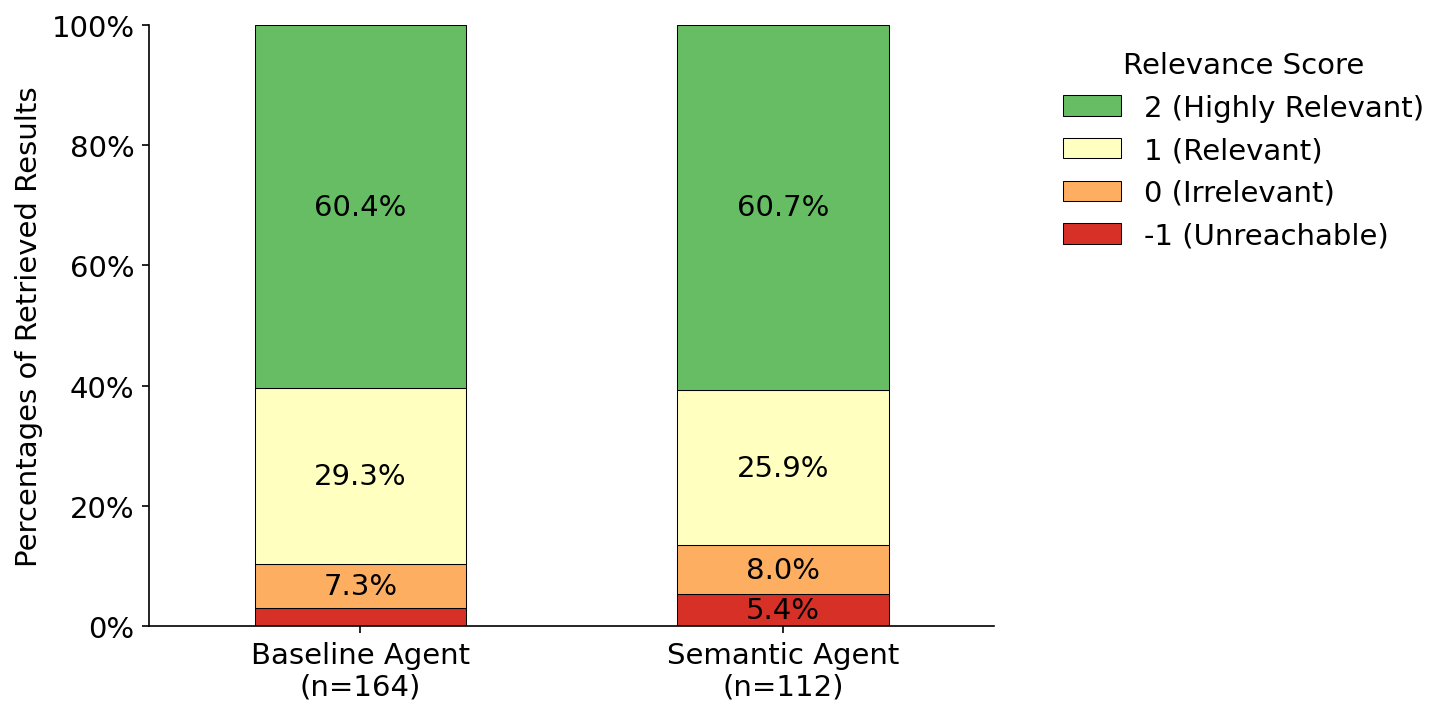
Fig 2: Comparison of the agent results by relevance scores.
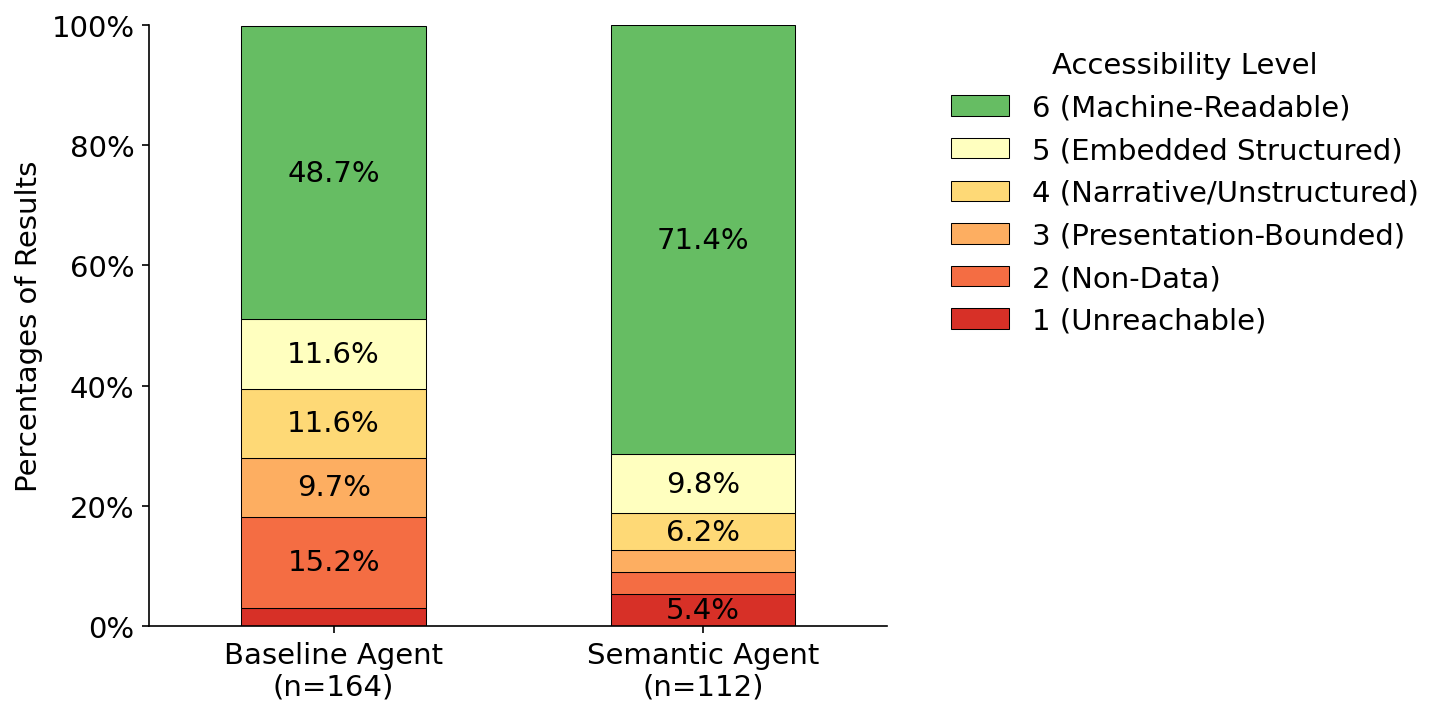
Fig 3: Comparison of the agent results by data accessibility levels
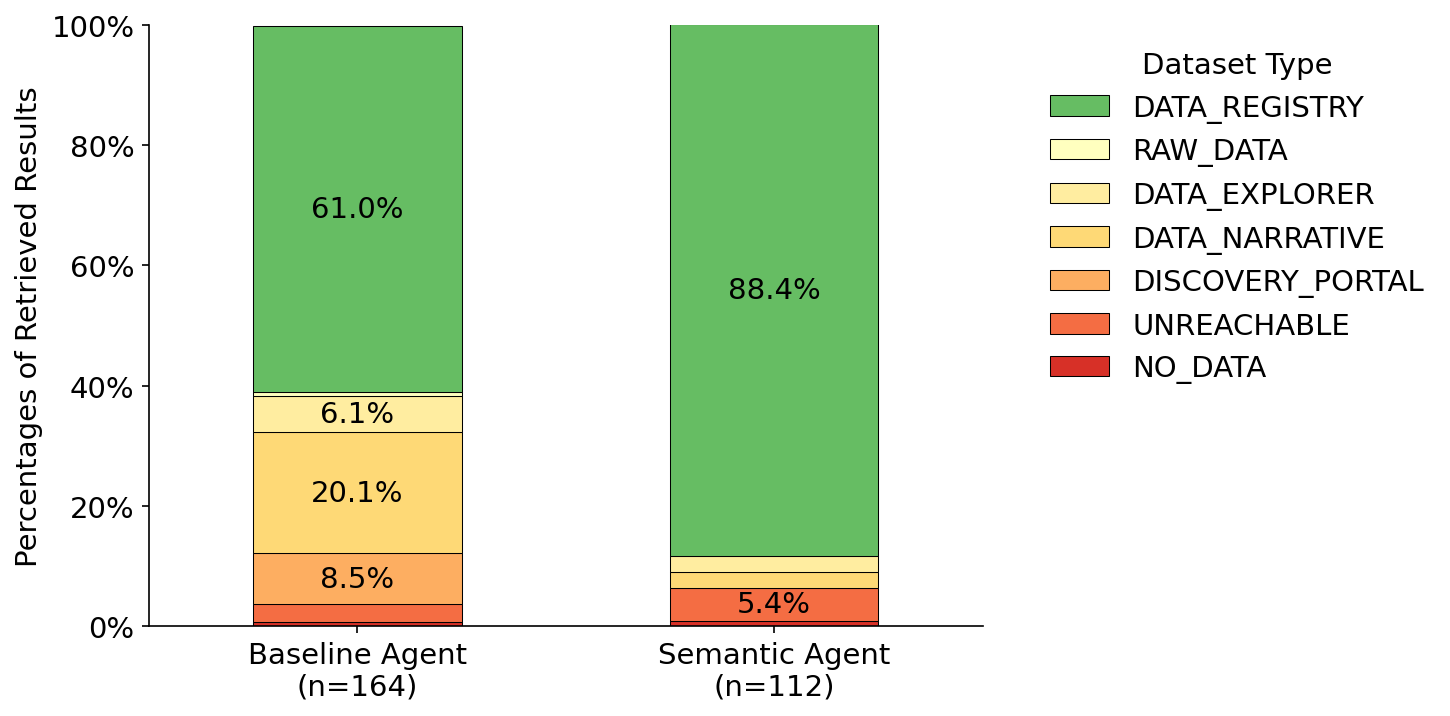
Fig 4: Comparison of the agent results by dataset page type
Limitations
- Coverage of Semantic Corpus limited to datasets annotated with schema.org/Dataset and DCAT on Google Dataset Search, excluding alternative schemas and datasets without metadata.
- Proprietary and undisclosed internal ranking mechanisms of Google Search and Dataset Search may confound comparisons and limit interpretability.
- Approximately 31% of retrieved pages could not be evaluated automatically due to scraping errors or complex layouts, requiring human evaluation to mitigate bias.
- Dataset retrieval evaluation is limited to keyword-based queries (N=58) from NTCIR-16, which may not generalize to richer natural language or multi-faceted queries.
- Use of live web indexes causes potential reproducibility challenges due to index volatility and link rot despite content freezing attempts.
- No explicit adversarial evaluation assessing agent robustness to manipulated metadata or adversarial content.
Open questions / follow-ons
- How do agents perform with complex, multi-faceted natural language queries involving explicit semantic constraints rather than keyword-based queries?
- Can hybrid architectures combining semantic metadata querying with fallback to unstructured web searching optimally balance breadth and precision for different autonomous workflows?
- What are the impacts of adversarial or low-quality metadata annotations on agentic data retrieval reliability in semantic ecosystems?
- How can agent autonomy be improved in gated or paywalled data scenarios, including seamless human-in-the-loop handoff strategies?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper highlights the critical role of semantic metadata in enabling autonomous agents to reliably discover and interact with machine-actionable datasets. Unstructured web retrieval, even when augmented with powerful LLMs, remains noisy and frequently fails at the last-mile extraction of usable data, landing instead on prose or portals. This implies that security systems relying on autonomous agent interactions should carefully consider the underlying data sources and metadata quality to prevent failures or exploitation. Moreover, systems designed to detect or challenge bot interactions may leverage the observed behavioral differences in how semantic metadata enhances agent precision and execution confidence. The paper's evaluation framework emphasizing retrieval precision, accessibility, and operational utility offers a rigorous approach for vetting autonomous workflows beyond simple content relevance, valuable for designing robust bot and risk detection methods.
Cite
@article{arxiv2605_28787,
title={ Do Agents Need Semantic Metadata? A Comparative Study in Agentic Data Retrieval },
author={ Shiyu Chen and Tarfah Alrashed and Alon Halevy and Natasha Noy },
journal={arXiv preprint arXiv:2605.28787},
year={ 2026 },
url={https://arxiv.org/abs/2605.28787}
}