
CORE: Contrastive Reflection Enables Rapid Improvements in Reasoning
Source: arXiv:2605.28742 · Published 2026-05-27 · By Linas Nasvytis, Simon Jerome Han, Ben Prystawski, Satchel Grant, Noah D. Goodman, Judith E. Fan
TL;DR
This paper addresses the problem of improving reasoning capabilities of frozen language models via learning from verifiable rewards in a highly sample- and rollout-efficient manner. Existing parametric methods (e.g., reinforcement learning approaches like GRPO) require hundreds of thousands of rollouts and large datasets, while state-of-the-art non-parametric approaches (e.g., prompt optimization, retrieval of past rollouts) still demand large amounts of data and context tokens, making them computationally expensive and context-inefficient. The authors propose CORE (Contrastive Reflection), a novel, non-parametric learning algorithm that enables rapid improvement by generating and accumulating compact, interpretable natural-language insights—short descriptions of reasoning strategies extracted by contrasting successful and failed attempts. These insights are stored with utility estimates and selectively retrieved for future problem-solving based on semantic similarity and observed effectiveness.
The authors empirically show that CORE outperforms both parametric (GRPO) and non-parametric baselines (GEPA, Episodic RAG, MemRL) across four distinct reasoning tasks involving logic, arithmetic word problems, symbolic puzzles, and planning. CORE achieves significantly faster learning curves and better final accuracy with as few as five training examples and a fraction of the rollouts used by alternatives. It is also substantially more context-efficient at evaluation time, requiring 35–36× fewer prompt tokens than retrieval-based methods. Ablation studies demonstrate the importance of the contrastive reflection method and utility-aware retrieval mechanisms. Overall, the results suggest that storing distilled, contrastive insights rather than raw reasoning trajectories or model weight updates offers a more effective and interpretable path for language model self-improvement on reasoning tasks.
Key findings
- CORE increases held-out accuracy by 59.9% (0.445 to 0.712) from rollout 0 to rollout 350 averaged across four tasks, surpassing all baselines despite using fewer rollouts (2100 vs 4000 baseline rollouts).
- CORE achieves highest mean accuracy in 9 of 12 task-by-training-size settings (5, 10, 100 samples), e.g. 0.907 accuracy on matchstick arithmetic with 10 training samples vs best baseline GEPA at 0.693.
- CORE requires on average 0.92k context tokens per evaluation item, compared to 33.6k for Episodic RAG and 32.7k for MemRL, representing a 35–36× reduction in evaluation-time context usage.
- Ablation removing contrastive reflection (using only last failure or only success traces) reduces final accuracy on matchstick arithmetic from 0.907 to 0.617 (last trace) and 0.830 (correct trace), showing contrastive insight generation is critical.
- Removing utility-awareness from insight retrieval reduces accuracy from 0.907 to 0.780, indicating benefit of tracking empirical insight performance rather than relying only on semantic similarity.
- CORE admits between 65 and 143 insights per task after 2000 rollouts; most admitted insights have non-negative empirical utility (>91%), with a small subset accounting for largest performance gains.
- Insight types fall into three functional classes: search space structuring heuristics, intermediate state tracking, and verification/validation constraints; these are procedural abstractions rather than just trajectory summaries.
Threat model
n/a – this work does not consider adversarial threat models but focuses on interactive frozen language model self-improvement via verifiable reward signals. The 'adversary' in experimental setup is not a malicious entity but the difficulty imposed by unsolved problems and failed attempts.
Methodology — deep read
Threat Model & Assumptions: The adversary context is not the focus here; instead, the problem setting is a frozen language model (GPT-OSS-120B) solving a verifiable reasoning task with binary feedback (reward). No weight updates occur. The key assumption is access to a verifier function providing correctness labels for candidate answers. The model’s baseline success rates for problems are estimated from independent rollouts before learning begins.
Data: Four distinct reasoning domains are used: Matchstick Arithmetic puzzles, MathGAP arithmetic word problems, Tower of Hanoi planning puzzles, and ZebraLogic logical grid puzzles. The datasets are procedurally generated with associated verifiers to produce binary success/failure for candidate solutions. Training sets vary in size (5, 10, 100 problems), with held-out evaluation sets fixed at 100 problems per task. Inputs are encoded with embeddings (jina-embeddings-v2-base-en for CORE and Episodic RAG; text-embedding-3-large for MemRL).
Algorithm: CORE maintains two external memory stores:
- Rollout memory stores past successful rollouts indexed by problem embedding.
- Insight memory stores short natural-language insights with empirical utility estimates per problem.
During training, problems are sampled with failure bias to focus learning on challenging problems. For each training query,
- The top-K insights are retrieved by combining semantic similarity and learned utility scores and appended to the model prompt.
- The model generates a reasoning trace and answer.
- Verifier feedback is used to estimate baseline-relative utility for retrieved insights.
When a failure occurs, contrastive reflection is triggered:
- The model compares a failed rollout with a semantically similar successful rollout.
- This contrastive prompt generates candidate insights describing strategies or constraints differentiating success from failure.
- Candidates are deduplicated, tested individually via admission trials (single rollout with insight included), and admitted only if accuracy improves.
- Admitted insights are added to insight memory with initial utility scores.
Insight retrieval scores combine observed average baseline-relative utility over semantically similar problems plus an exploration bonus decaying with retrieval frequency. This guides selective reuse of effective insights in context.
Training Regime: Training uses GPT-OSS-120B frozen with temperature 0.6, reasoning effort set high, and max output length 32k tokens. Rollouts count both baseline estimation and training attempts; CORE runs 2000 actual training rollouts per dataset. Three independent runs are averaged. Baselines use recommended hyperparameters and comparable infrastructure.
Evaluation Protocol: Held-out test performance is measured by verifier accuracy on 100 unseen problems per task. Metrics include accuracy, rollout efficiency (accuracy vs rollouts), sample efficiency (accuracy vs number of training problems), and context efficiency (prompt token count). Ablations isolate the impact of contrastive reflection and utility-aware retrieval. Performance is compared against GRPO (parametric RL approach), GEPA (prompt optimization), Episodic RAG (retrieving past rollouts), and MemRL (value-aware retrieval summaries).
Reproducibility: Code and data for matchstick arithmetic are released at the authors’ GitHub. GPT-OSS-120B is an open-source 120B parameter language model. Embedding models and implementation details like retrieval parameters are documented. Some task datasets (e.g., MathGAP, ZebraLogic) are public or procedurally generated.
Example end-to-end for a failed problem: On encountering a problem q that the model fails at, CORE retrieves the most similar successful rollout τ+ for the same or similar problem. Using q, τ+ and the failed attempt τ-, the model is prompted to generate candidate insights highlighting contrasts between the two attempts. Each candidate insight is then tested individually via admission trials: the model solves q with only that insight provided in context. Insights that improve performance over baseline accuracy are admitted. During future solves of semantically similar problems, high-utility insights are retrieved and prepended to the prompt, improving the probability of successful solve.
Technical innovations
- Introduction of contrastive reflection to generate insights by explicitly contrasting successful and failed reasoning trajectories instead of summarizing individual traces.
- Storing learning artifacts as short natural-language insights with empirical utility estimates rather than raw reasoning rollouts or weight updates.
- Utility-aware retrieval that balances semantic similarity with measured empirical effectiveness of insights for selective reuse.
- Failure-biased problem sampling combined with admission testing of candidate insights to admit only useful learning artifacts, reducing memory bloat and spurious knowledge.
- A non-parametric learning paradigm for frozen language models that enables rapid self-improvement with minimal rollouts and low evaluation-time context.
Datasets
- Matchstick Arithmetic — 5, 10, 100 training items and 100 held-out evaluation items — Procedurally generated, code released
- MathGAP — 5, 10, 100 training items and 100 evaluation items — Public benchmark dataset for arithmetic word problems [21]
- Tower of Hanoi — 5, 10, 100 training items and 100 evaluation items — Procedurally generated classic planning puzzles [28]
- ZebraLogic — 5, 10, 100 training items and 100 evaluation items — Constraint satisfaction logic puzzles [15]
Baselines vs proposed
- GRPO: final held-out accuracy on Matchstick Arithmetic with 10 samples = 0.637 vs CORE = 0.907
- GEPA: final held-out accuracy on MathGAP with 100 samples = 0.777 vs CORE = 0.843
- Episodic RAG: final held-out accuracy on Tower of Hanoi with 100 samples = 0.303 vs CORE = 0.427
- MemRL: final held-out accuracy on ZebraLogic with 5 samples = 0.683 vs CORE = 0.700
- CORE rollout efficiency (averaged across tasks): accuracy improves 59.9% from rollout 0 to 350 vs best baseline plateauing earlier
- CORE context tokens per evaluation item: average 0.92k vs Episodic RAG 33.6k and MemRL 32.7k (35–36× reduction)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28742.
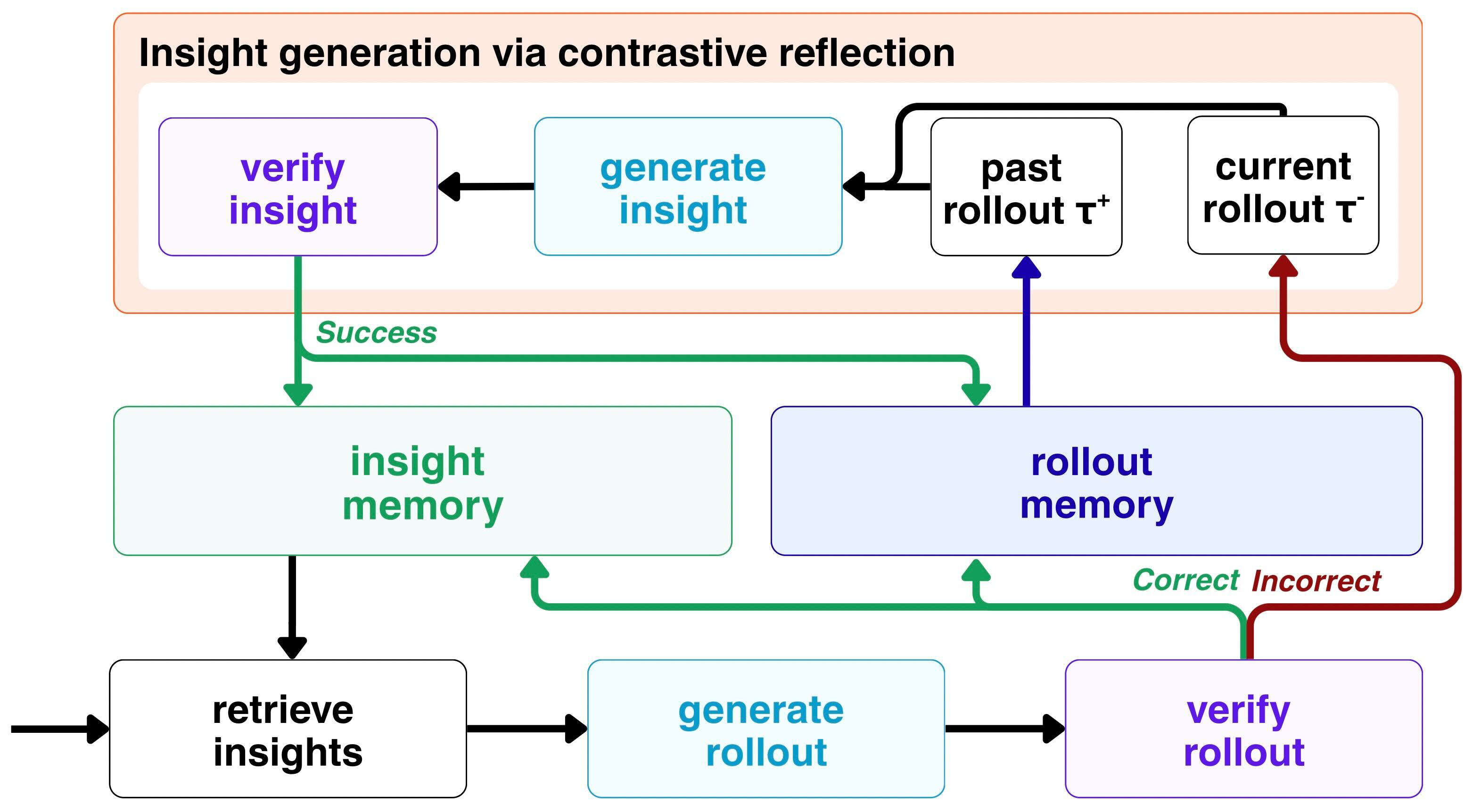
Fig 1: Illustration of the CORE algorithm: A model retrieves relevant insights, then generates a
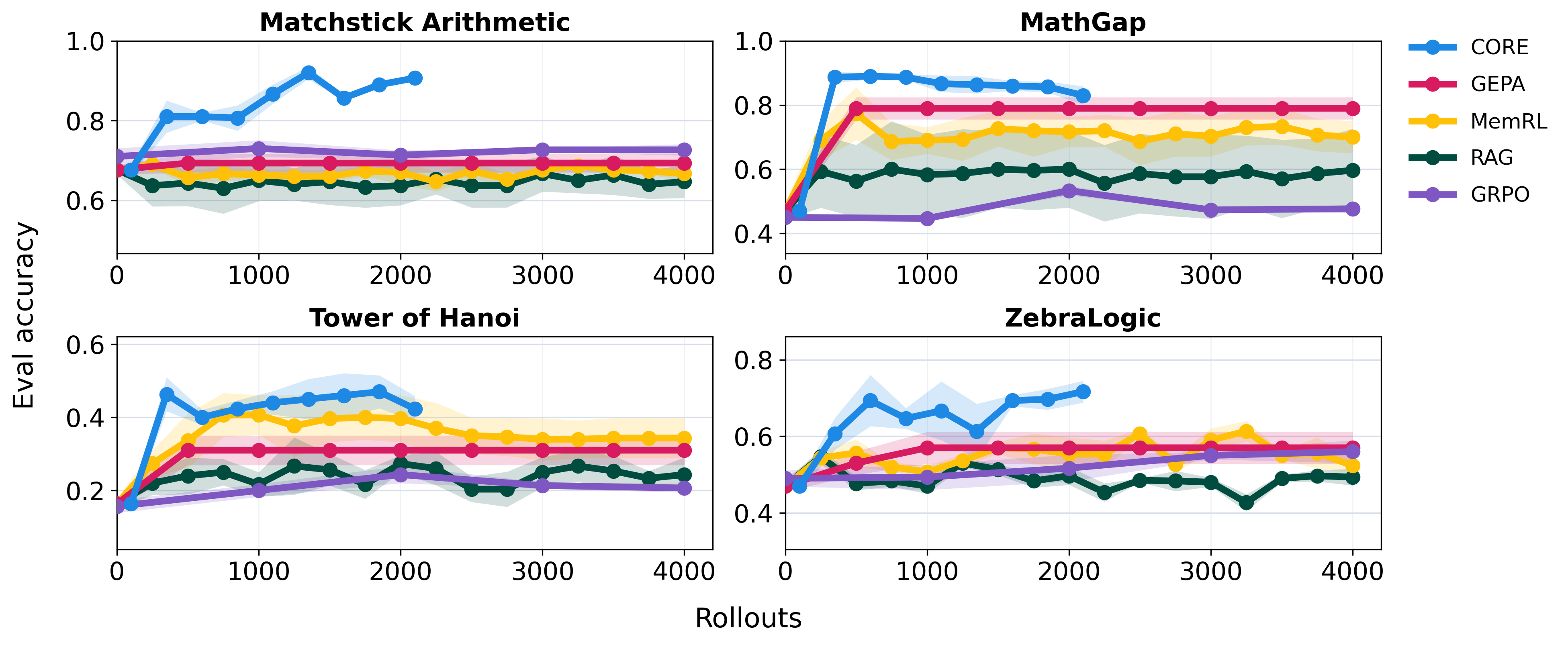
Fig 2: CORE improves rollout efficiency. Held-out evaluation performance as a function of total
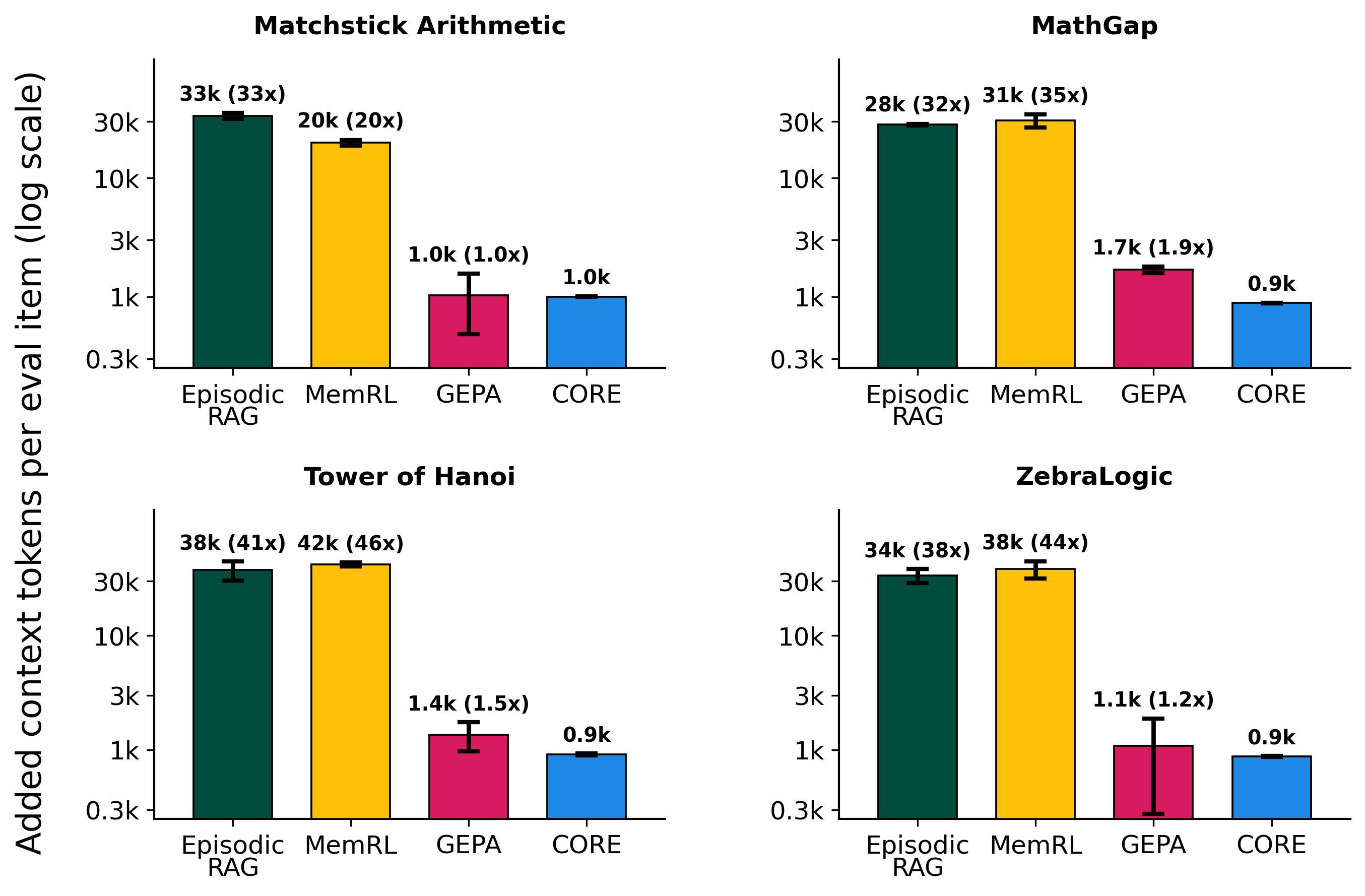
Fig 3: CORE improves context efficiency. Added task-external context tokens per evaluation
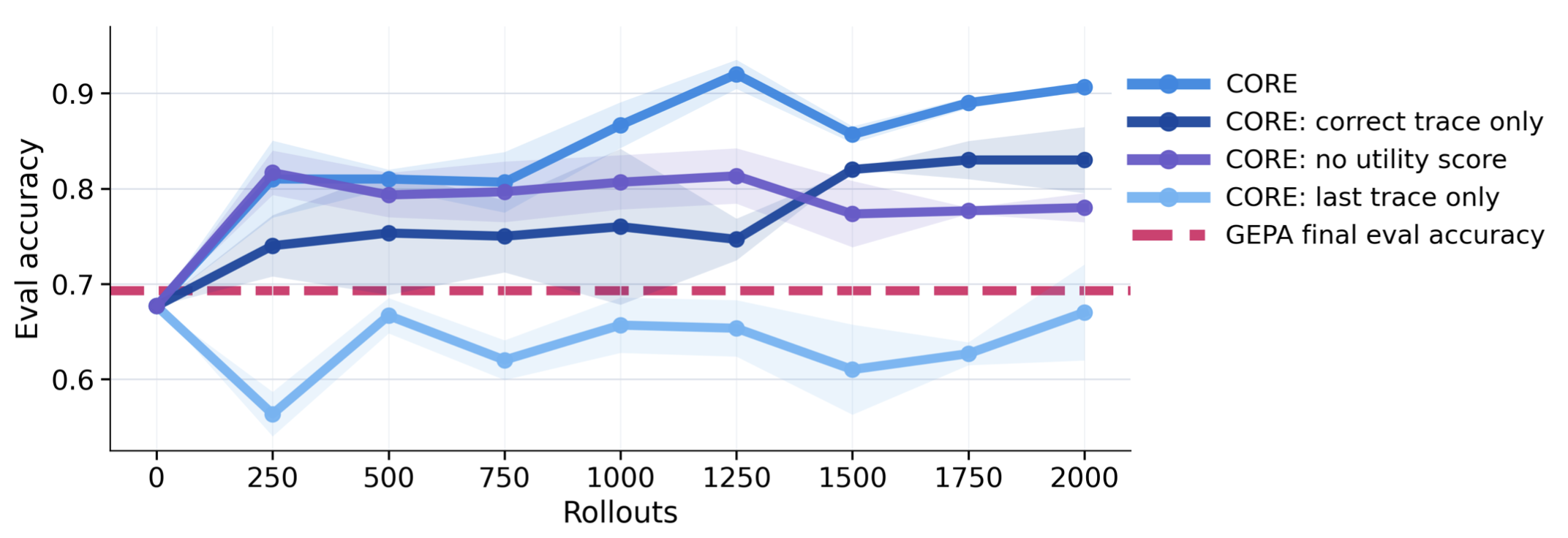
Fig 4: Ablations on the Matchstick Arithmetic task with 10 training examples. We compare CORE
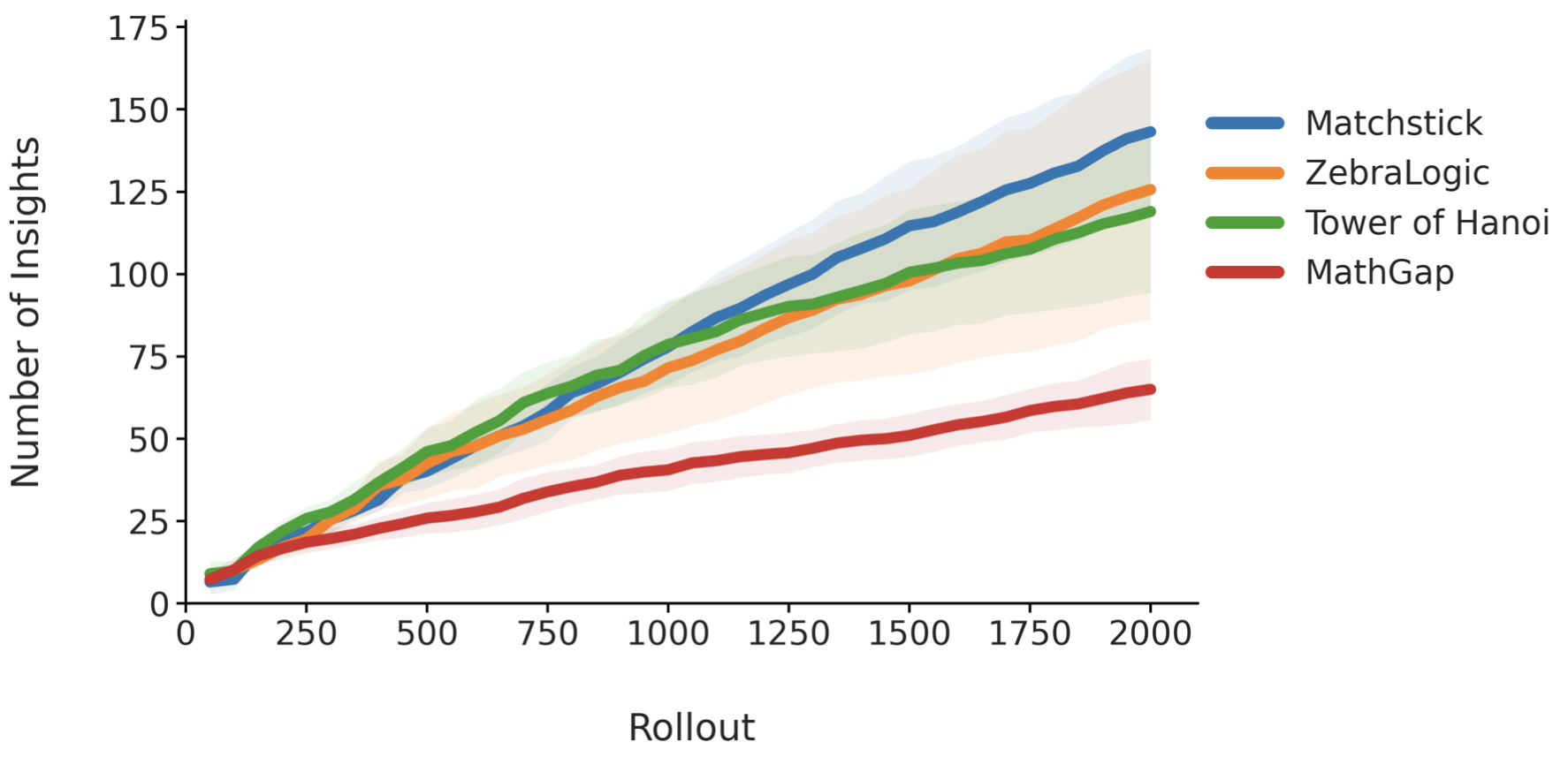
Fig 5: Growth of the insight memory across rollouts for each task. Lines show the number of
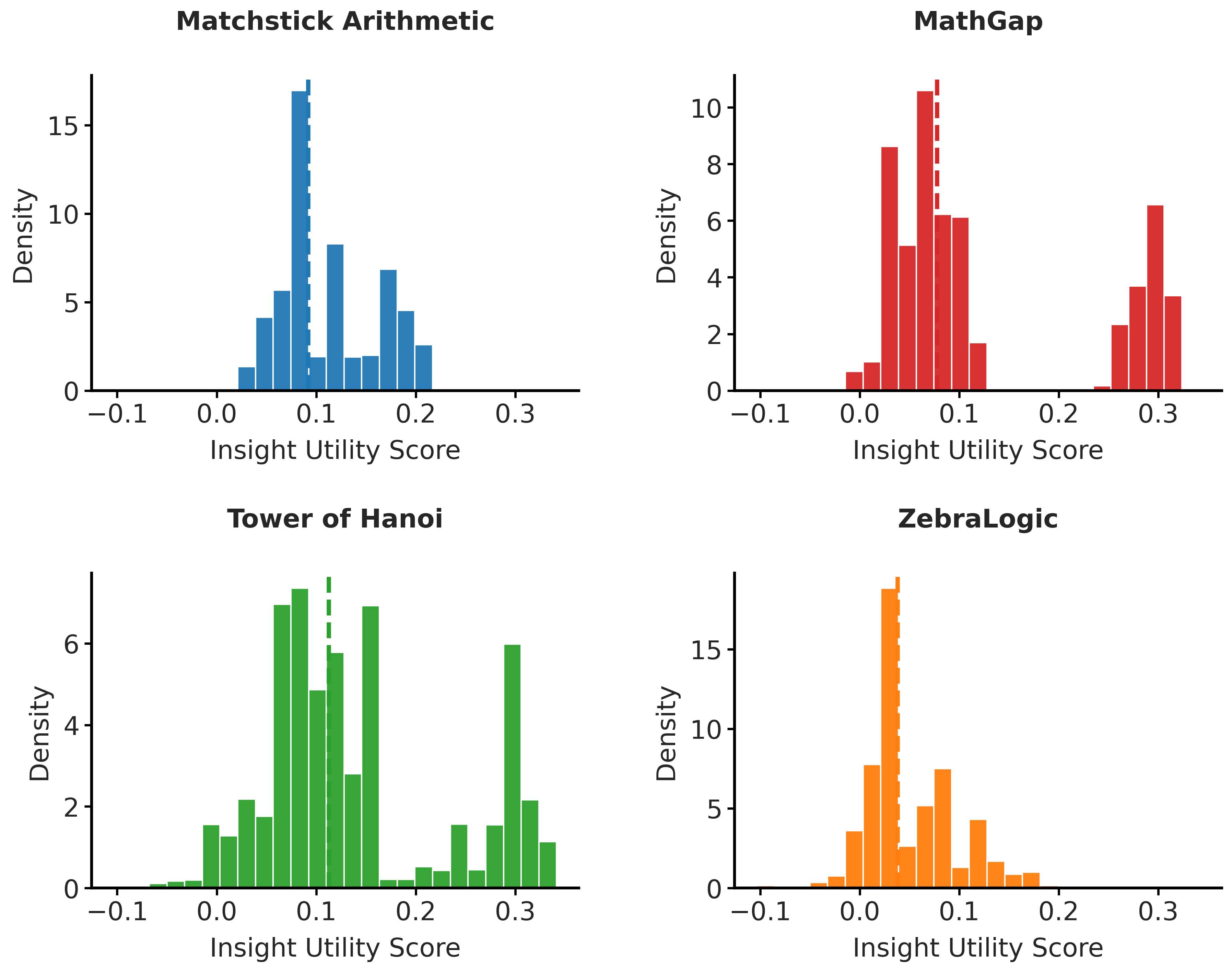
Fig 6: Distributions of insight utilities across the four tasks.
Limitations
- Uses only frozen language models; does not combine parametric weight updates and non-parametric reflection simultaneously, though suggested as future work.
- Empirical utility scores assign credit to all retrieved insights equally per rollout, limiting fine-grained credit assignment between insights retrieved together.
- Evaluation mainly on synthetic, procedurally generated reasoning tasks; real-world or downstream application scenarios remain unexplored.
- Admission testing uses a single rollout (nadm=1) with no admission margin (δ=0), which may admit some low-confidence insights or miss others.
- Computational and memory overhead of contrastive insight generation and maintenance of two memory stores might scale with dataset and insight size; scalability beyond tasks and sizes tested is unclear.
- Lack of explicit adversarial or distribution-shift robustness evaluation for insight reuse under domain drift or adversarial manipulation.
Open questions / follow-ons
- How to effectively integrate CORE’s non-parametric reflection and insight reuse with parametric fine-tuning or RL updates to combine benefits of both approaches?
- Can CORE-scale contrastive reflection and insight generation efficiently to larger and more diverse, real-world problem distributions beyond synthetic reasoning benchmarks?
- What methods can improve credit assignment among sets of co-retrieved insights, beyond group-level utility updates, to better attribute gains to individual insights?
- How robust are CORE-generated insights and retrieval policies to adversarial failures, distribution shifts, or noisy reward signals?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, CORE’s approach of distilling compact, interpretable reasoning insights from contrasting past successes and failures could inspire efficient, sample-frugal learning mechanisms for challenging verification tasks. Rather than relying on opaque weight updates or maintaining large caches of prior full interactions, systems could store and selectively retrieve abstracted natural-language heuristics guiding human-like reasoning and anomaly detection. CORE’s demonstrated rollout and context efficiency also suggest potential benefits for constrained computational setups commonly found in CAPTCHA evaluation pipelines. Importantly, the transparency of learned artifacts contrasts with black-box model updates, a potential advantage for safety and auditability when deploying adaptive bot-defense mechanisms. However, further research would be needed to test CORE’s ideas under adversarial conditions typical in bot detection and to design mechanisms for scalable online insight consolidation in security-critical environments.
Cite
@article{arxiv2605_28742,
title={ CORE: Contrastive Reflection Enables Rapid Improvements in Reasoning },
author={ Linas Nasvytis and Simon Jerome Han and Ben Prystawski and Satchel Grant and Noah D. Goodman and Judith E. Fan },
journal={arXiv preprint arXiv:2605.28742},
year={ 2026 },
url={https://arxiv.org/abs/2605.28742}
}