
Can Large Language Models Handle Discourse Particles? A Case Study of Colloquial Malay
Source: arXiv:2605.28782 · Published 2026-05-27 · By Mariah Al Giptiah Binte Yusoff, Jakin Tan, Bocheng Chen, Guangliang Liu, Xi Chen
TL;DR
This paper addresses the challenge of modeling discourse particles—short morphemes that convey pragmatic and interpersonal meaning—in large language models (LLMs), focusing specifically on Malay, a low-resource Southeast Asian language. The authors introduce MALAYPRAG, a novel benchmark dataset of colloquial Malay utterances containing two discourse particles (kan and ke), rigorously annotated by native speakers with a grounded five-attribute schema capturing epistemic stance, listener agreement, emotion, question type, and particle position. The study systematically evaluates ten off-the-shelf LLMs, including global and Southeast Asia–focused models, on three prediction tasks: attribute prediction, pragmatic function prediction, and particle prediction. Results demonstrate that current state-of-the-art LLMs struggle to correctly interpret and generate contextually appropriate discourse particles in Malay, performing near chance without structured guidance. However, providing models with the linguistically motivated attributes significantly improves their accuracy across all tasks, outperforming zero-shot baselines and chain-of-thought prompting. Moreover, smaller regional SEA-LION models benefit disproportionately from explicit attribute input, indicating latent pragmatic knowledge can be scaffolded effectively. The paper contributes a linguistically grounded framework, a new low-resource pragmatic benchmark, and thorough empirical insights into LLMs’ pragmatic competence deficits and potential paths forward in Southeast Asian contexts.
Key findings
- LLMs achieve only around 27.9% accuracy on Malay pragmatic function prediction without attribute guidance, barely above the 14.3% random chance baseline (Table 3).
- Providing the proposed five pragmatic attributes boosts function prediction accuracy by 24.5% absolute on average, reaching 52.5% (Table 3).
- Explicit attributes outperform chain-of-thought prompting (32.4% accuracy) by a margin of approximately 20% in pragmatic function prediction (Table 4).
- Discourse particle prediction from raw utterances yields 43% average accuracy; adding attributes increases this to 61.5%, and combining attributes plus pragmatic functions raises it to 69.1% (Table 5).
- Particle position, a syntactic attribute, is predicted most accurately (~85%), while listener agreement, a contextual attribute, is the hardest (~47%) (Table 2).
- English prompting slightly outperforms Malay prompting for attribute prediction, suggesting pragmatic concepts are learned predominantly in English training data (Table 2).
- Regional SEA-LION models show inconsistent performance but the greatest pragmatic-function prediction improvements when attribute inputs are provided (+35.8% in Gemma-SEA-LION-27B, Table 3).
- Overall, LLMs struggle with Malay discourse particles despite being state-of-the-art; structured, linguistically grounded scaffolding is necessary for improved pragmatic competence.
Threat model
Not applicable; the paper focuses on evaluating linguistic and pragmatic competence of LLMs in handling Malay discourse particles, not adversarial or security threat scenarios.
Methodology — deep read
The paper studies large language models' (LLMs) pragmatic competence in handling discourse particles in colloquial Malay, focusing on two particles: kan and ke. The methodology unfolds in multiple stages:
Threat Model & Assumptions: The study assumes zero-shot LLM usage without fine-tuning, testing models' out-of-the-box pragmatic understanding of Malay discourse particles. Adversaries or malicious actors are not considered, as the focus is on linguistic competency rather than security.
Data Collection: The MALAYPRAG dataset contains 1,137 utterances from Malay social media (Reddit, Twitter/X) containing discourse particles kan and ke. Additional neutral and substituted utterances were synthesized and validated by native speakers. Manual filtering excluded Indonesian borrowings and homograph interference. Two splits were created: a small GOLD set (N=187) with triple annotation and adjudication for evaluation, and a larger SILVER set (N=950) single-annotated for pragmatic function extraction.
Annotation Schema: The authors developed a five-attribute pragmatic annotation grounded in linguistic theory, covering Epistemic Stance (Certain, Uncertain, Neutral), Listener Agreement (Assumed Agreement, Confirmation Seeking), Emotion (Positive, Negative, Neutral), Question Type (Interrogative, Rhetorical, etc.), and Particle Position (Front, Mid/End, N/A). These attributes allow structured, interpretable metadata capturing speaker intentions.
Pragmatic Function Extraction: Using k-means clustering on the combined GOLD and SILVER attribute data (k=16), utterances were grouped by attribute similarity. Linguists qualitatively labeled the clusters with overarching pragmatic functions (e.g., Information-seeking verification, Negative rhetorical challenge). This decomposes complex pragmatic functions into discrete attribute combinations.
Experimental Tasks: LLMs are evaluated in zero-shot settings on three tasks:
- Task 1: Attribute Prediction: Given raw utterance (prompted in English or Malay), predict each of the five attributes.
- Task 2: Pragmatic Function Prediction: Predict the pragmatic function from raw utterance, from utterance+chain-of-thought (CoT), or from utterance+attributes.
- Task 3: Discourse Particle Prediction: Choose the appropriate particle (kan, ke, neutral) for a masked utterance under various prompt conditions (raw, with attributes, with functions, or both).
Models & Prompting: Ten LLMs were tested including GPT-5 variants, Anthropic Claude variants, Google Gemini, DeepSeek, and smaller SEA-LION regional models. Temperature=0 was used for deterministic outputs with closed-set labels required.
Metrics & Evaluation: Accuracy was measured at attribute, function (7 classes), and particle (3 classes) levels against the GOLD annotation set. Comparisons include direct raw prompting, CoT prompting, attribute-augmented prompting, and their combinations.
Reproducibility: The MALAYPRAG dataset and prompting templates are publicly released. Model checkpoints are off-the-shelf.
Concrete Example End-to-End: For instance, in Task 2c, an utterance containing "Dia dah makan, kan?" (He already ate, right?) is input to GPT-5 along with its known attributes (e.g., certain epistemic stance, assumed agreement) to predict its pragmatic function as a request for listener agreement. This scaffolding notably increases prediction accuracy over raw input or CoT prompting alone.
Overall, the methodology tightly integrates linguistic theory with data curation, structured annotation, clustering to derive pragmatic functions, and systematic zero-shot evaluation of powerful LLMs with controlled prompting strategies to reveal gaps and gains in pragmatic understanding.
Technical innovations
- Development of a linguistically grounded five-attribute schema (Epistemic Stance, Listener Agreement, Emotion, Question Type, Particle Position) to computationally represent Malay discourse particle pragmatic functions.
- Introduction of MALAYPRAG, a novel low-resource dataset for evaluating pragmatic competence in a Southeast Asian language with rigorously validated annotations.
- Use of k-means clustering of attribute annotations combined with expert linguistic review to induce a data-driven taxonomy of pragmatic functions rather than directly predicting them.
- Demonstration that providing explicit attribute-level scaffolding to LLM prompts significantly outperforms raw or chain-of-thought prompting for pragmatic function and particle prediction tasks.
Datasets
- MALAYPRAG — 1,137 utterances (187 GOLD, 950 SILVER) — collected from Reddit and Twitter/X Malay posts and synthesized neutral/substituted sentences.
- GOLD subset — 187 utterances annotated by three native linguists with adjudication, publicly released.
Baselines vs proposed
- Attribute Prediction (Overall accuracy): raw input in English prompts = 69.3% vs Malay prompts = 65.2%
- Pragmatic Function Prediction (accuracy): direct prompting = 28.0% vs attributes-provided prompting = 52.5%
- Pragmatic Function Prediction: chain-of-thought prompting = 32.4% vs attributes-provided = 52.5%
- Discourse Particle Prediction (accuracy): raw input = 43.0% vs attribute only = 61.5%, function only = 53.1%, attribute plus function = 69.1%
- SEA-LION Gemma-27B pragmatic function prediction improves from 23% to 59% (+35.8%) with attributes
- Chain-of-thought plus function particle prediction (68.9%) vs Attribute plus function (69.1%) performs similarly
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.28782.
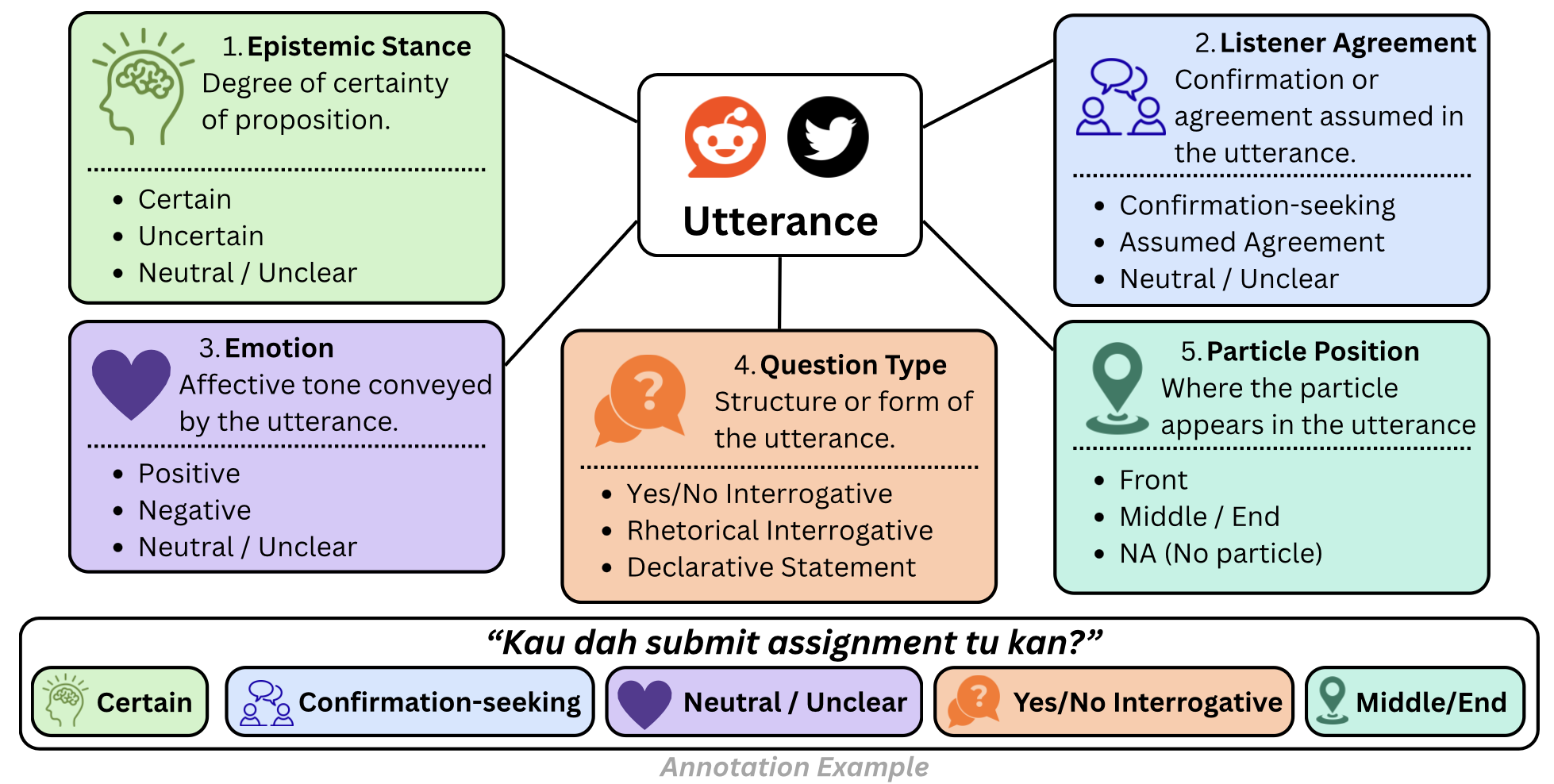
Fig 1: Five-dimensional annotation schema for Malay discourse particle utterances. An utterance is evaluated by
Limitations
- Text-only data excludes prosodic, intonational, and multi-turn conversational cues crucial for pragmatic interpretation, limiting annotation and model performance.
- Small size of the GOLD evaluation dataset (187 utterances) may constrain statistical power and generalizability.
- Only two Malay discourse particles (kan and ke) were studied; the approach needs extension to other particles and languages.
- Zero-shot prompting approach may not capture improvements possible via fine-tuning or continued post-training.
- Regional SEA-LION models lag primarily due to smaller scale and post-training deficits despite domain specialization.
- Annotations still subject to some human bias and disagreement, particularly for ambiguous attributes such as Listener Agreement.
Open questions / follow-ons
- How can multi-modal cues (prosody, intonation) and multi-turn conversational context be integrated to improve attribute annotation and LLM interpretation of discourse particles?
- Would fine-tuning or post-training LLMs on attribute-annotated data further enhance their pragmatic competence beyond zero-shot prompting?
- Can the five-attribute schema be generalized to other Southeast Asian languages with similarly rich discourse particle systems?
- How do different LLM architectures and training paradigms influence sensitivity to pragmatic cues, especially in low-resource languages?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper illustrates the challenges large language models face in understanding pragmatic nuances inherent in low-resource languages such as Malay. Discourse particles encode subtle social, emotional, and pragmatic meanings that current LLMs often miss without explicit scaffolding. This insight is valuable when designing language-based human-bot interaction tests or dialogue systems that need to robustly detect or generate human-like pragmatic signals. The attribute-based framework proposed provides a promising structured approach to improve LLMs’ pragmatic competencies, which in turn can help create more sophisticated CAPTCHAs or bot detection methods that exploit pragmatic subtlety rather than surface form alone.
Moreover, the demonstrated divergence between global and regionally specialized models suggests that careful consideration of language coverage, regional adaptations, and pragmatic scaffolding will be crucial in deploying bot-defense tools in multilingual, low-resource contexts. Practitioners might consider incorporating multi-dimensional pragmatic features or explicit attribute prompts to improve model interpretability and discrimination in human-likeness detection tasks across diverse languages.
Cite
@article{arxiv2605_28782,
title={ Can Large Language Models Handle Discourse Particles? A Case Study of Colloquial Malay },
author={ Mariah Al Giptiah Binte Yusoff and Jakin Tan and Bocheng Chen and Guangliang Liu and Xi Chen },
journal={arXiv preprint arXiv:2605.28782},
year={ 2026 },
url={https://arxiv.org/abs/2605.28782}
}