
When Eyes Betray AI: Social Gaze Consistency as a Semantic Cue for AI-Generated Image Detection
Source: arXiv:2605.27348 · Published 2026-05-26 · By Kim Jihyeon, Sohee Kim, Soosan Lee, Souhwan Jung, James Matthew Rehg, Hyesong Choi
TL;DR
This paper addresses the detection of AI-generated images (AIGC), focusing on person-centric and multi-person interaction scenarios where conventional low-level artifact cues (pixel fingerprints, frequency anomalies, upsampling traces) have largely been mitigated by recent generative models. The authors introduce Social Gaze Consistency, a new high-level semantic cue that captures mutual coherence in gaze direction, head-eye alignment, and pupil placement between interacting individuals in images. This semantic cue is orthogonal to traditional low-level forensic features and thus provides an additional detection axis especially valuable in partial-edit attacks where only localized eye regions are manipulated.
To operationalize this cue, the authors build a Custom Gaze diagnostic dataset with strict pair-level identity preservation, eliminating generator memorization shortcuts. They propose a novel Block-Compositional Caption Supervision scheme that enforces a fixed 5-block reasoning skeleton in the caption outputs, decoupling reasoning consistency from surface lexical diversity. The resulting supervision improves detection performance significantly across multiple datasets, including +3.7 percentage points balanced accuracy on the COCOAI Interaction subset and +1.3 points on the person-centric COCOAI Person subset when fine-tuning a vision-language model (FakeVLM). Gains also transfer to a vision-only backbone (Effort), confirming the cue's architecture-agnostic nature. The method recovers fake-class recall without sacrificing real-class accuracy, ruling out trivial calibration shifts. A mechanistic four-step account is offered to explain the observed cross-generator and cross-architecture transfer.
Overall, this work advances AIGC detection by highlighting a semantic, social-consistency signal that supplements eroding low-level fingerprints, enabling better detection of nuanced human-face manipulations in complex social image contexts.
Key findings
- Custom Gaze dataset contains 46,830 paired real/fake images with localized partial eye-region edits, preserving base identity and forbidding generator-fingerprint memorization.
- Block-Compositional Caption Supervision constructs 1,250 unique captions using an invariant 5-block reasoning template, ensuring reasoning consistency during training.
- On the COCOAI Interaction benchmark, fine-tuning FakeVLM with gaze supervision improves balanced accuracy from 67.8% to 71.5%, a +3.7 pp gain.
- On the COCOAI Person benchmark, the same method improves balanced accuracy from 83.0% to 84.3%, a +1.3 pp gain.
- On the in-distribution Custom Gaze test set, balanced accuracy saturates near 99.9%, a +13.5 pp gain vs FakeVLM origin.
- Cross-architecture transfer to a vision-only Effort backbone yields +2.4 pp balanced accuracy on COCOAI Interaction (59.0% to 62.4%) and saturates Custom Gaze at 99.9%, confirming backbone-agnosticism.
- Confusion matrix analysis on COCOAI Interaction shows +17 true fake recoveries with near-zero (−1) true real losses, refuting predict-all-fake bias.
- Ablation comparing full 5-block caption supervision vs single-sentence decision-only supervision shows +2.9 pp gain on multi-person interaction fakes but tradeoffs on single-person fakes, indicating domain-targeted reasoning depth effect.
Threat model
The adversary is assumed to be a generative model (fully synthetic or partial-edit inpainting) producing person-centric images that may violate social gaze consistency. The attacker does not enforce consistent mutual gaze or head-eye alignment between interacting individuals, nor does it explicitly optimize semantic gaze coherence. The defense assumes attackers cannot perfectly replicate these nuanced relational semantics, and thus detection exploits this semantic inconsistency. Attacker cannot avoid localized eye-region editing cues or generate globally convincing gaze geometry under this regime.
Methodology — deep read
Threat Model & Assumptions: The adversary is a generative model producing synthetic or partially edited person-centric images, specifically targeting regions around the eyes. The detector assumes the adversary does not enforce social gaze consistency semantics, i.e., gaze directions and head-eye alignment may be inconsistent or biologically implausible. The attacker cannot perfectly replicate mutual gaze coherence between multiple interacting individuals. The defense targets both fully synthesized and localized inpainting manipulations (partial edits), known to evade low-level artifact detectors.
Data: The key dataset is Custom Gaze, constructed from the OI Mutual Gaze dataset, containing 23,415 mutual-gaze positive pairs totaling 46,830 images. Each pair shares identity, scene, composition, and lighting, differing only by replacing the eye region in one image using FLUX.1-Fill inpainting. Eye region masks cover vertical bands isolating eyes in the face bounding box, blurred softly. This paired-edit design blocks generator fingerprint memorization. The data is split 8:1:1 for train, validation, test with pair-level grouping to prevent leakage.
Architecture / Algorithm: The primary model is FakeVLM, a vision-language multimodal model built upon LLaVA-v1.5 (LLM Vicuna-7B) plus CLIP ViT-L/14. Parameter-efficient LoRA adapters are used on vision encoder and LLM attention and MLP layers; the projector (cross-modal bottleneck) is fully fine-tuned. The supervision involves generating natural-language captions with fixed 5-block reasoning skeleton (Decision, Scene, Method, Evidence, Conclusion), sampled combinatorially from 20 macro-pool caption segments to yield 1,250 unique captions. Training optimizes cross-entropy over these tokens rather than simple binary classification.
Training Regime: Mixed fine-tuning on combined dataset of Custom Gaze (≈31%) and FakeClue (soft texture-based captions, ≈69%). AdamW optimizer with learning rate 2e-5, cosine schedule with warmup 3%, batch size effectively 32 (8 GPUs x gradient accumulation 4) in bfloat16 precision. Training runs 2 epochs (~7,558 steps) on RTX A6000 hardware. Balanced accuracy checkpoint selection is used rather than minimum loss - peak BA obtained at step 1,650 (where token loss minimum is at 2,850), preventing reasoning collapse.
Evaluation Protocol: Evaluated on three benchmarks: in-distribution Custom Gaze test (partial-edit localized fakes), COCOAI Person (single-person multi-generator fakes, 13,100 fakes), COCOAI Interaction (multi-person interaction fakes, 165 fakes). Metrics: Balanced Accuracy (BA), macro-F1, Matthews Correlation Coefficient (MCC). Baselines: low-level detectors (AIDE, SAFE, NPR, UnivFD, Effort origin), large LMM detector (SIDA-13B 13B params), and FakeVLM origin. Also cross-architecture transfer to Effort backbone tested with label-only supervision on Custom Gaze. Statistical results averaged over 3 seeds.
Reproducibility: Code release planned upon acceptance. Dataset is constructed from public OI Mutual Gaze but includes novel paired inpainted images (Custom Gaze). Model weights and full training details provided, including LoRA configs and random seeds. Synthetic captions procedurally generated from 20 macro-pool segments.
Example end-to-end: A paired sample from Custom Gaze shares base identity and scene - the real image and its fake counterpart differ only in the eye region replaced by FLUX.1-Fill inpainting. The model receives the image and must generate a 5-block caption containing a reasoning skeleton asserting real or fake label based on gaze consistency. The paired-edit data structure and caption supervision induce learning of high-level semantic gaze coherence features, avoiding learning low-level generator artifacts. Evaluation on the COCOAI Interaction subset shows the model recovers +17 more fake images correctly with no substantial loss on real images, confirming acquisition of genuine semantic cues rather than shortcut artifacts.
Technical innovations
- Introduction of Social Gaze Consistency as a high-level semantic detection cue capturing mutual gaze, head-eye alignment, and pupil placement across interacting persons, orthogonal to low-level forensic features.
- Creation of a Custom Gaze paired-edit dataset with strict pair-level identity preservation isolating gaze-cue perturbations from generator fingerprint artifacts, enabling shortcut-proof training.
- Design of Block-Compositional Caption Supervision enforcing an invariant 5-block reasoning skeleton across 1,250 unique captions, decoupling reasoning consistency from lexical diversity to improve supervision quality.
- Cross-architecture demonstration of cue generality, showing that training on FakeVLM and label-level fine-tuning of Effort backbone both achieve saturation on gaze-consistency cues, supporting backbone-agnosticism.
Datasets
- Custom Gaze — 46,830 paired real/fake images — derived from OI Mutual Gaze with FLUX.1-Fill inpainting
- FakeClue — approx. 104,343 AI-generated images with free-form captions — public
- COCOAI Person subset — 15,720 images (13,100 fake) — person-centric multi-generator
- COCOAI Interaction subset — 198 images (165 fake) — multi-person interaction-centric
Baselines vs proposed
- FakeVLM origin on COCOAI Interaction: BA = 67.8% vs Ours: 71.5% (+3.7 pp)
- FakeVLM origin on COCOAI Person: BA = 83.0% vs Ours: 84.3% (+1.3 pp)
- FakeVLM origin on Custom Gaze test: BA = 86.4% vs Ours: 99.9% (+13.5 pp)
- Effort origin on COCOAI Interaction: BA = 59.0% vs Ours (Effort FT): 62.4% (+3.4 pp)
- SIDA-13B (13B LMM) mean BA: 70.8% vs Ours (7B) mean BA: 85.2% (+14.4 pp)
- Low-level baselines (AIDE, SAFE, NPR, UnivFD) collapse to BA ≤59% on Interaction, ≤71% on Person
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.27348.

Fig 1: Custom Gaze construction and Block-Compositional Caption Supervision. Only the
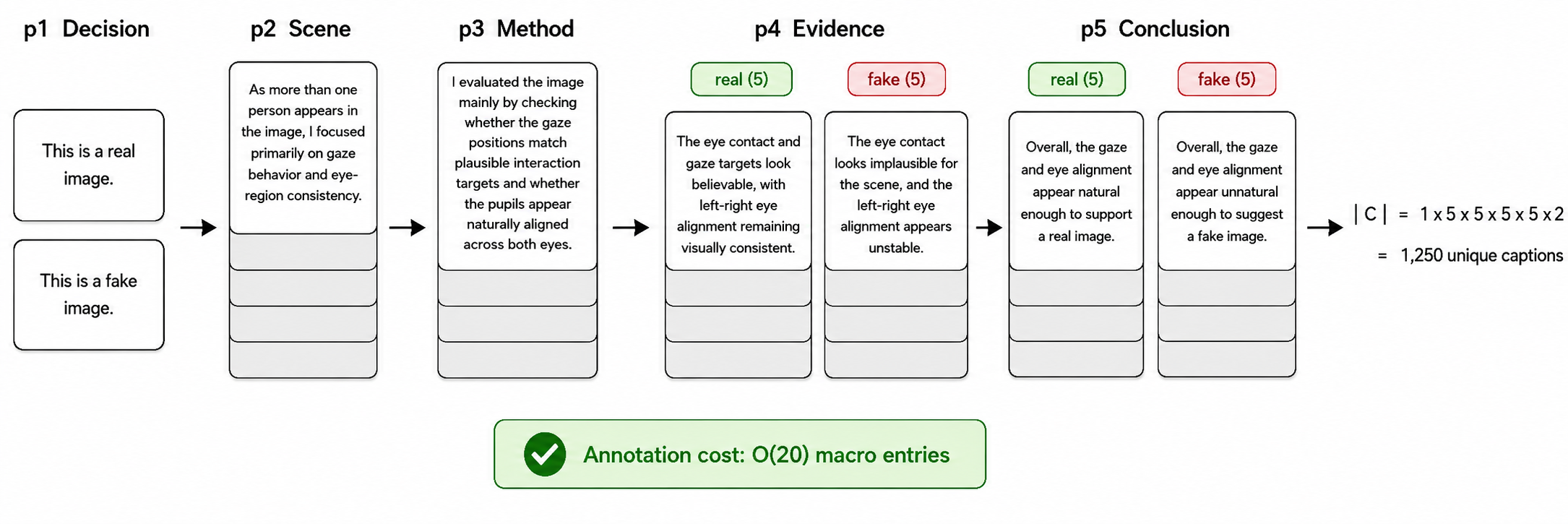
Fig 2: Block-Compositional Caption schema.
Limitations
- Domain specialization: cue designed specifically for person-centric and multi-person social gaze context, limiting generality to non-human or single-object images (L1).
- Potential over-trust in gaze-based heuristics (card over-trust) may cause errors when genuine social gaze is ambiguous or absent (L2).
- Dataset constructed using a single inpainting model (FLUX.1-Fill), raising concerns about robustness to other generators or unseen manipulations (L3).
- Dependency on accurate face detection and bounding boxes during training, which may affect generalization under occlusions or failure cases in the wild (L4).
- Evaluation limited primarily to static images; video temporal consistency and dynamics of gaze cues remain unexplored.
- Model tested on curated benchmarks but broader adversarial testing against adaptive attacks is not performed.
Open questions / follow-ons
- How robust is the Social Gaze Consistency cue against adversarial generation explicitly optimizing for gaze alignment or semantic consistency?
- Can the semantic-consistency axis be extended beyond gaze to other social signals such as body pose, gesture, or multi-modal audio-visual cues for cross-domain detection?
- What is the potential for leveraging temporal coherence of gaze and social interactions in videos to improve detection beyond single images?
- How does the cue generalize when applied to non-human subjects or synthetic scenes without clear gaze targets?
Why it matters for bot defense
Bot-defense engineers working on human verification or synthetic media detection can consider supplementing traditional low-level artifact detectors with higher-level semantic-consistency checks based on social gaze coherence, particularly in scenarios with multiple interacting individuals. This approach targets a detection axis that contemporary generators may struggle to convincingly replicate, especially in partial edits localized around eyes, which are common manipulation targets for identity or social context alteration.
Incorporating structured reasoning supervision (Block-Compositional Caption Supervision) enforces consistent semantics in detector outputs, which could inspire bot-detection models that require explainability or interpretability. The demonstrated cross-architecture transfer indicates that this semantic cue is not model-architecture-dependent, facilitating adoption in diverse detection pipelines. This work encourages designers to think beyond pixel-level or frequency-based artifacts and incorporate higher-level scene and interpersonal consistency checks as generative models continue improving low-level realism.
Cite
@article{arxiv2605_27348,
title={ When Eyes Betray AI: Social Gaze Consistency as a Semantic Cue for AI-Generated Image Detection },
author={ Kim Jihyeon and Sohee Kim and Soosan Lee and Souhwan Jung and James Matthew Rehg and Hyesong Choi },
journal={arXiv preprint arXiv:2605.27348},
year={ 2026 },
url={https://arxiv.org/abs/2605.27348}
}