
Towards Just-in-Time Adaptive Feedback: Enhancing Student Learning via Knowledge-Grounded LLM
Source: arXiv:2605.26405 · Published 2026-05-26 · By Younghun Lee, Amir Bralin, Nobel Sanjay Rebello, Dan Goldwasser
TL;DR
This paper addresses the challenge of providing Just-in-Time (JiT) adaptive feedback at scale in STEM education by grounding Large Language Models (LLMs) with domain-specific expert knowledge. The authors propose a feedback framework that analyzes students’ written strategy essays for common error types and delivers tailored, non-intrusive feedback aimed at promoting conceptual understanding rather than simply giving correct answers. Deployed in a large university physics course with over 1,000 students, the framework significantly improved student performance by more than 80% compared to previous semesters without LLM feedback. The iterative conversational interaction allowed students to refine their reasoning, shifting misconceptions to correct understandings.
Key novelty lies in combining human-expert annotated domain knowledge with few-shot prompting and Chain-of-Thought reasoning to classify error types from natural language strategy essays, enabling adaptive feedback generation. Analysis of conversational data showed increased essay correctness and that more extensive textual revisions correlate with better learning outcomes. Despite imperfect error classification accuracy, the expert-grounded feedback helped identify and clarify missing or incorrect concepts effectively, disrupting common formula-hunting heuristics in novice learners.
Key findings
- JiT adaptive feedback framework improved student quiz performance by over 80% compared to prior semesters without LLM feedback (Fig 5).
- LLM error type classification accuracy reached 60.61% and macro F1 of 54.24% using few-shot prompting with secondary label consideration, outperforming fine-tuned BERT baseline (accuracy 50%) (Table 1).
- About 20% of students engaged in iterative conversational feedback with LLM, resulting in increase of ‘correct’ classification of essays from 42.79% initially to 71.64% after conversations (Table 2).
- Students’ degree of revision (word count change between essay versions) positively correlated with essay correctness (Pearson r = 0.18, p < 0.001), whereas time spent between turns had negligible correlation (r = 0.06, p = 0.27) (Fig 9).
- Survey showed both novice and advanced students preferred feedback targeted to novices, indicating LLM struggles to generate effective advanced-level feedback (Fig 2).
- LLM-generated feedback effectively helped confirm correct concepts and clarifying missing or overlooked ideas according to qualitative student feedback clustering (Fig 6).
- Grounding LLM with human expert annotations enabled robust feedback despite imperfect error predictions, mitigating risks of incorrect/no intervention when essays were misclassified as ‘correct’.
- Iterative LLM feedback conversations led 91.43% of students (32/35) in a subset sample to solve the target quiz correctly via incremental essay improvements (Fig 8).
Threat model
n/a — The paper focuses on educational technology and does not define an adversarial threat model. The primary challenge is the non-trivial task of correctly classifying student reasoning errors from natural language essays to avoid misleading feedback.
Methodology — deep read
Threat Model & Assumptions: The threat model is framed as an educational setting rather than an adversarial security scenario. The main challenges addressed are the inherent difficulty in classifying complex student reasoning with incomplete information, and preventing formula-hunting behavior. The system assumes access to students' strategy essays and historical data relating essays to error types; the model cannot perfectly classify error types, but uses domain knowledge and few-shot learning to generate pedagogically sound feedback.
Data: The dataset consists primarily of 11,948 strategy essays from 1,418 students collected over multiple semesters (Fall 2024 to Spring 2026) of a large, calculus-based physics course with approximately 3,300 annual enrollments. Essays are written responses of at least 50 words without formulas or symbols, describing students’ reasoning approach to solve quiz problems. Essays are associated with corresponding multiple-choice quiz answers that map to specific error types (correct, direction error, position error, or combined position-direction error). A small expert-annotated subset (~50 examples) links essays to tailored feedback comments for few-shot learning.
Architecture / Algorithm: The core classification task maps natural language strategy essays to error types via prompt-engineered LLM classification with Chain-of-Thought (CoT) reasoning. Few-shot in-context examples from expert annotations guide the LLM to identify both primary and secondary error predictions. Error predictions then condition the generation of adaptive feedback messages that prompt conceptual reflection rather than direct solution disclosure. Feedback generation is grounded in domain knowledge distilled from educational experts. The framework also considers student-specific features like prior performance to adapt feedback.
Training Regime: No full model fine-tuning is performed on the LLM. For baselines, a BERT classifier is fine-tuned on the limited labeled quiz data. LLMs are prompted zero-shot and with few-shot examples (3 per error class). The final approach prompts the LLM to output both primary and secondary error classes to increase robustness. Hyperparameters and hardware setup for BERT training are briefly referenced but not detailed; prompting is conducted with GPT-5.1.
Evaluation Protocol: Error classification is evaluated by accuracy and macro F1 score on multi-class labels (correct vs three error types). Student quiz performance is compared across four equivalent semesters, measuring correct response rates on identical quiz questions with and without LLM JiT feedback. Student feedback helpfulness is self-reported via surveys, and qualitative analysis of open-ended responses is conducted with clustering. Analysis of iterative conversational turns tracks changes in essay error classification and correlation between revision activity (word count changes) and essay correctness. No adversarial robustness or out-of-distribution generalization tests are performed.
Reproducibility: The dataset is proprietary, collected from Purdue University physics course students, and likely not publicly available. Source code, prompting templates, and full LLM weights are not disclosed. Detailed prompt structures and experimental appendices are included in supplementary material. Overall, partial reproducibility through prompt descriptions but limited access to raw data and models.
Concrete Example End-to-End: Students write a strategy essay for a physics quiz item (e.g., force direction in block system). The essay text is fed to an LLM prompted with few-shot expert-annotated examples. The LLM outputs predicted primary and secondary error types using CoT reasoning. Based on predictions and domain-grounded feedback, adaptive text hints are generated to highlight concepts students missed (e.g., importance of force direction). Students read feedback, revise their essays, and may iterate multiple times, each time receiving refined feedback until essay classification is ‘correct’ or student solves the quiz question correctly. This cycle is captured and analyzed over 209 conversational instances.
Technical innovations
- Integration of human expert domain knowledge into LLM prompt-based feedback generation to ground adaptive feedback in precise pedagogical content.
- Use of few-shot LLM classification enhanced by Chain-of-Thought prompting and secondary label prediction to robustly identify student error types from natural language essays.
- Implementing Just-in-Time (JiT) feedback within authentic large-scale university STEM quizzes by analyzing student-written strategy essays rather than multiple-choice responses alone.
- Leveraging iterative student-LLM conversational interaction to support incremental refinement of reasoning and conceptual understanding, tracking learning trajectories.
Datasets
- Strategy Essays Dataset — 11,948 essays from 1,418 students — collected during 11 quizzes across four semesters (Fall 2024 to Spring 2026) in a large university calculus-based physics course, proprietary and not publicly available.
Baselines vs proposed
- Fine-tuned BERT classifier: accuracy = 50.00%, macro F1 = 28.39% vs few-shot LLM w/ secondary label: accuracy = 60.61%, macro F1 = 54.24% (Table 1).
- Student quiz performance without LLM JiT feedback: correct rate < 50% vs with JiT LLM feedback: correct rate > 90% (Fig 5).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.26405.
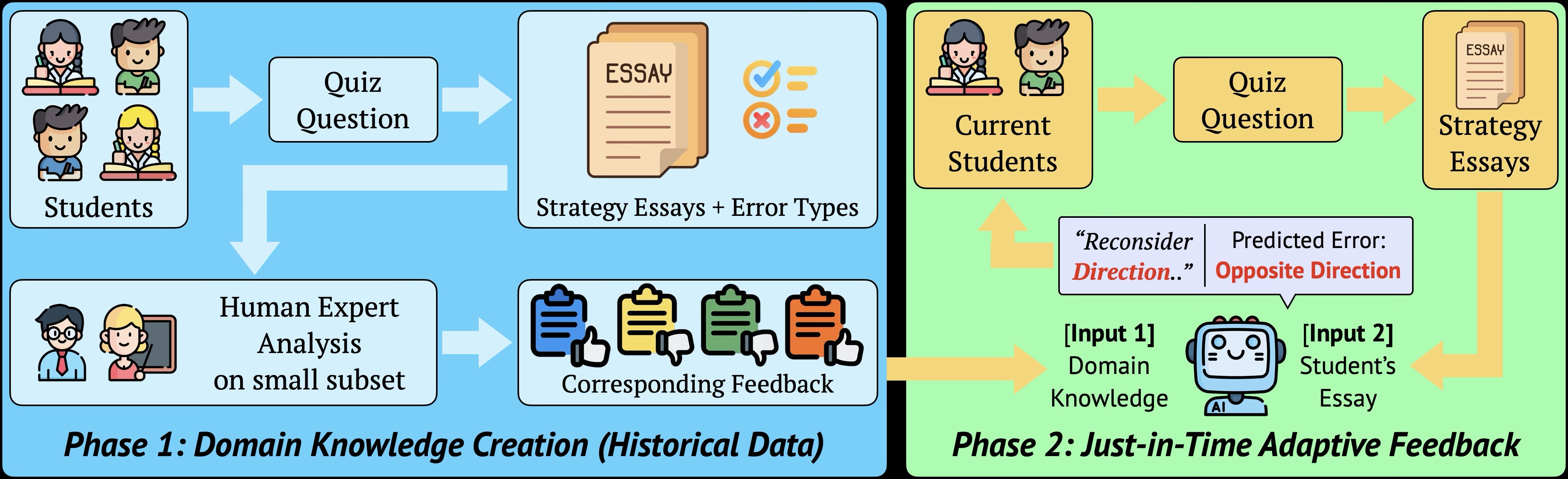
Fig 1: Overall framework of our Just-in-Time adaptive feedback LLM. In the first phase, we obtain domain
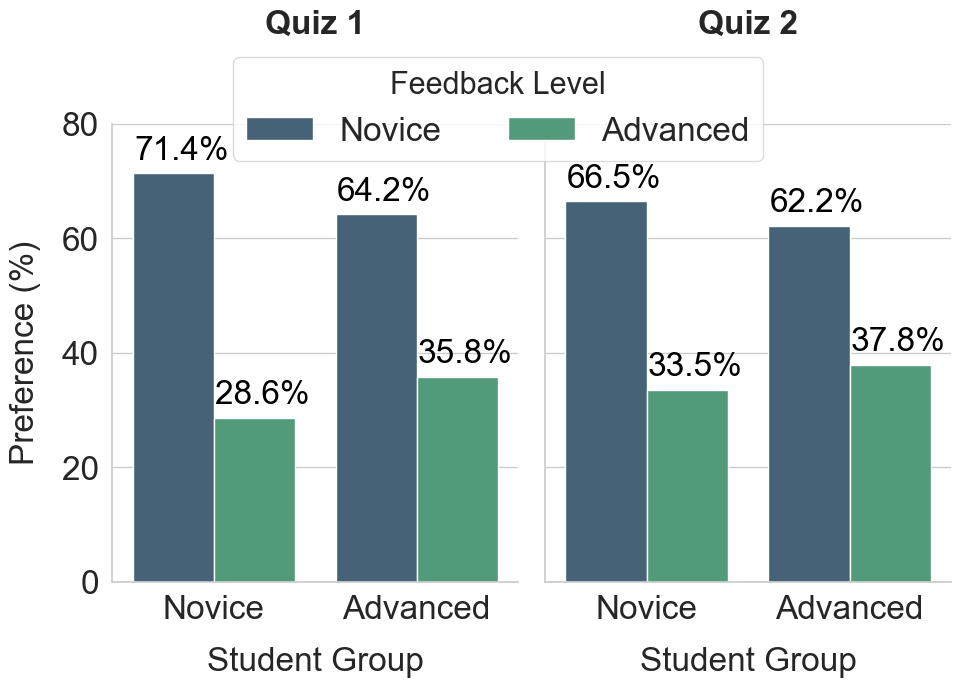
Fig 2: Survey results regarding preference be-
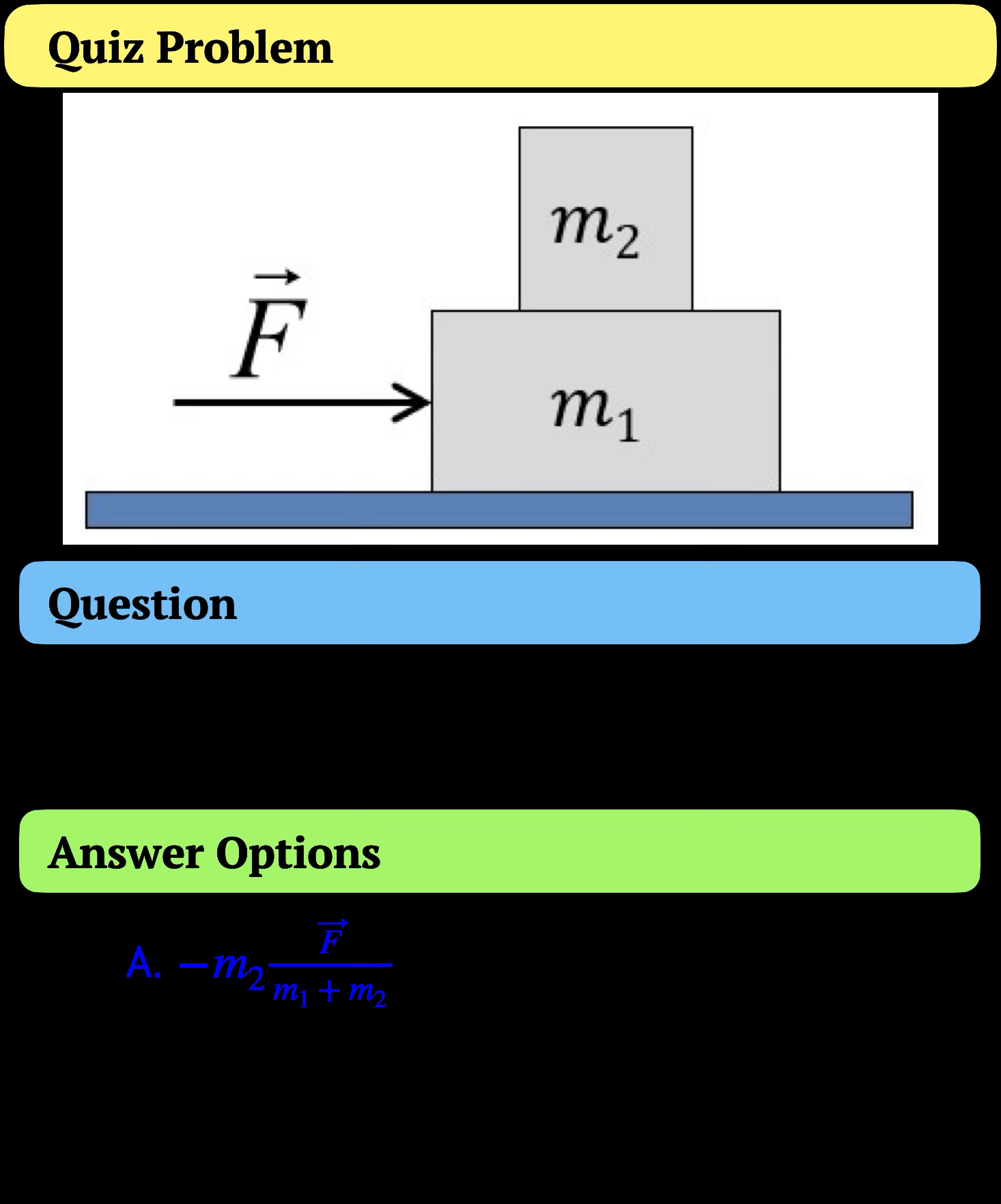
Fig 3: Example quiz problem. While A is correct,

Fig 4: Example of a strategy essay and annotated
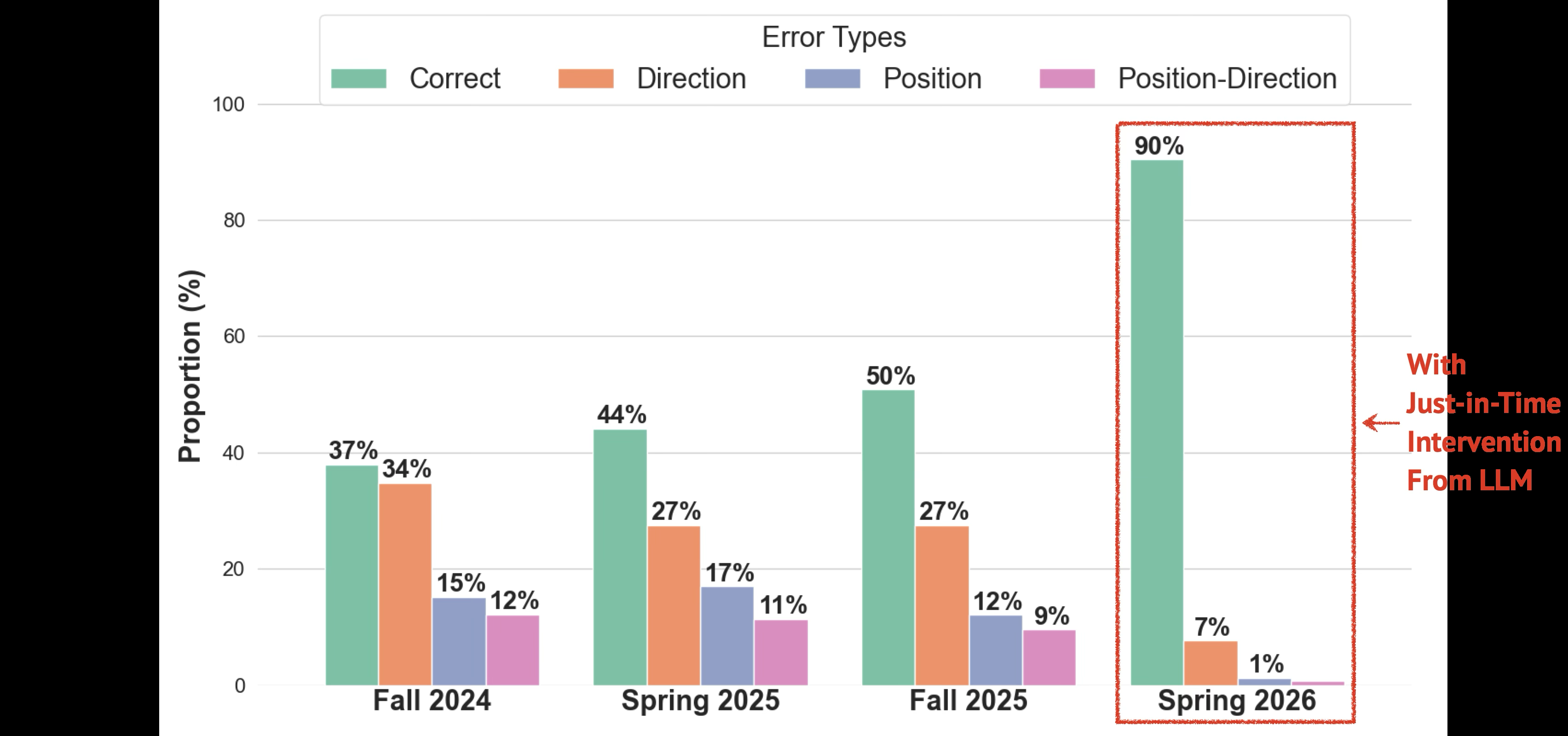
Fig 5: Student’s performance in the same quiz question over four semesters. When the students solved the
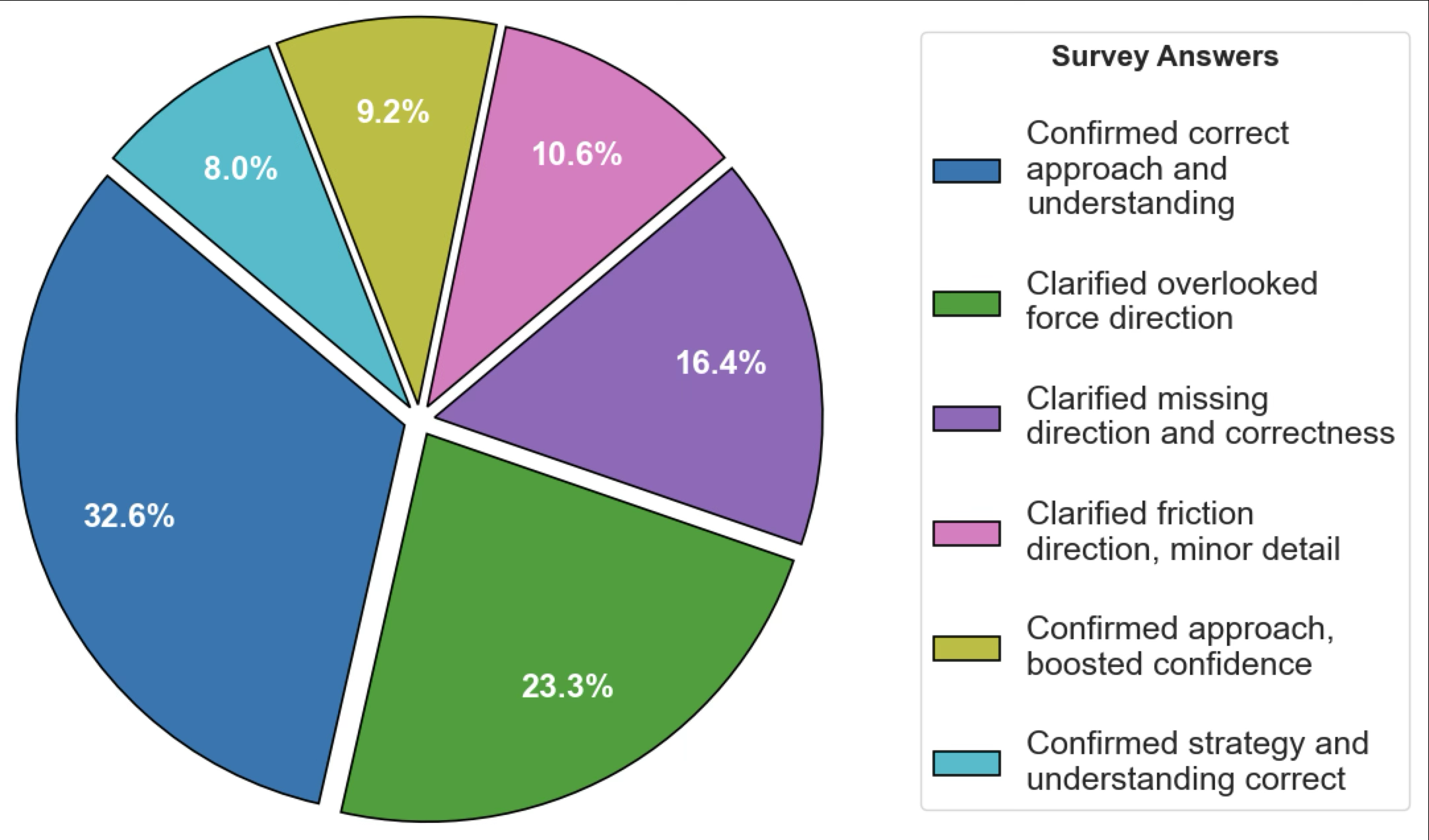
Fig 6: Survey results regarding why LLM’s feedback

Fig 7: shows an example of conversation be-
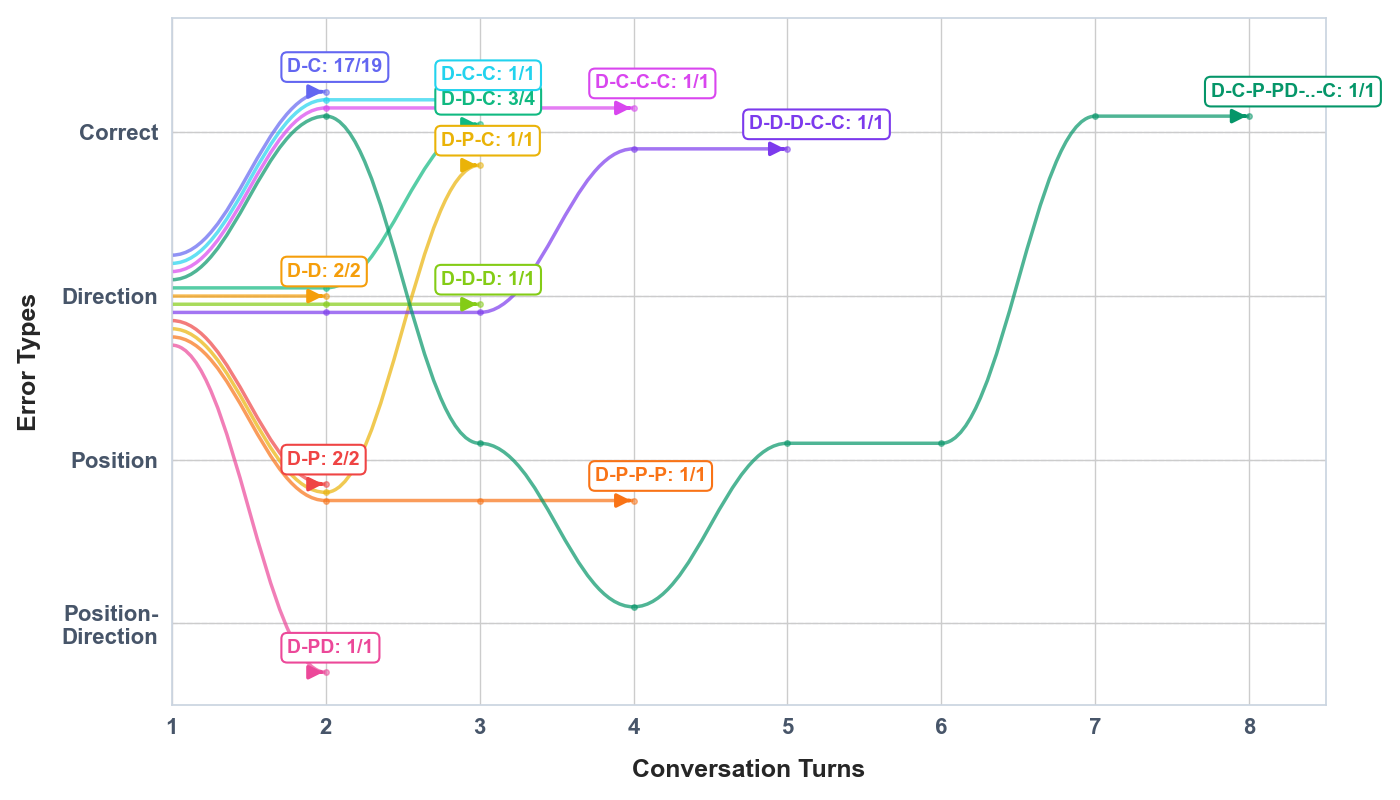
Fig 8: Learning Trajectories for students starting with Direction error. Each trace represents a sequence of
Limitations
- Suboptimal and imperfect accuracy in classifying error types from strategy essays (max ~60% accuracy), limiting reliability of feedback.
- Potential failure mode when LLM wrongly predicts essay as ‘correct’, resulting in no intervention for students needing help.
- JiT intervention was deployed and evaluated only on a single quiz question during one semester, limiting generalizability across topics and quiz types.
- LLM feedback generation mostly targets novice-level students; advanced students still preferred novice-level feedback indicating challenges in generating effective advanced feedback.
- System scalability is challenged by API rate limits and synchronous calls, causing failures for about 4% of students in large classes.
- Current LLM lacks memory to incorporate conversation history, processing each essay version standalone, which could hinder efficiency in iterative feedback.
Open questions / follow-ons
- How can the accuracy and robustness of error type classification be improved, possibly by integrating richer student metadata or structured essay formats?
- What is the effectiveness and scalability of this JiT feedback framework when deployed across multiple quizzes, subjects, and diverse STEM problem types?
- How can LLM feedback generation be improved for advanced learners who prefer more minimal and higher-level interventions?
- What technical designs enable LLMs with memory and student-specific context to reduce conversational turns required for conceptual mastery?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper's approach demonstrates how grounding large-scale language model outputs on domain-specific expert knowledge can improve the precision and adaptiveness of automatic textual feedback—paralleling how adaptive defenses require context-rich and expert-informed signals rather than generic patterns. The study shows that integrating multi-step reasoning and incremental feedback grounded in expert annotations enables better error detection and progressive correction, an idea that could inform design of layered verification challenges or interactive bot-detection workflows that adapt in real-time based on user input complexity. Furthermore, the work highlights the importance of robust classification under uncertainty using auxiliary predictions, a principle valuable for risk-mitigated challenge gating. Lastly, analyzing learning trajectories and conversational refinements might inspire dynamic CAPTCHA sequences that adjust difficulty just-in-time based on detected user behavior to resist automation more effectively.
Cite
@article{arxiv2605_26405,
title={ Towards Just-in-Time Adaptive Feedback: Enhancing Student Learning via Knowledge-Grounded LLM },
author={ Younghun Lee and Amir Bralin and Nobel Sanjay Rebello and Dan Goldwasser },
journal={arXiv preprint arXiv:2605.26405},
year={ 2026 },
url={https://arxiv.org/abs/2605.26405}
}