
Learning to Orchestrate Agents under Uncertainty
Source: arXiv:2605.27073 · Published 2026-05-26 · By Mary Chriselda Antony Oliver, Lan Jiang, Aaron Bundi Anampiu, Elaf Almahmoud, Francesco Quinzan, Umang Bhatt
TL;DR
This paper tackles the problem of sequentially orchestrating a set of heterogeneous agents under uncertainty, where agents differ in reliability, cost, and output behavior, and these characteristics evolve over time. Prior agent orchestration approaches typically focus on optimizing performance or cost without explicitly modeling uncertainty about agent reliability or output distributional mismatch. The authors propose BOT-Orch, a novel framework that formulates orchestration as a multi-armed bandit problem regularized by Optimal Transport (OT) distances measuring the discrepancy between agent output distributions and task-specific reference distributions. By integrating OT-based alignment costs with bandit learning, BOT-Orch adaptively balances exploitation of high-reward agents with exploration and alignment-awareness, accounting explicitly for uncertainty in agent outputs.
Theoretically, they prove that BOT-Orch enjoys sublinear O(√T) regret, establishes preference ordering in agents with identical mean rewards but different distributional match, and is robust to noisy alignment measurements. Empirically, they evaluate BOT-Orch on multiple synthetic and semi-synthetic benchmarks—including stationary and non-stationary task distributions, adversarial reward shifts, and a human–AI triage clinical task under deployment shift. BOT-Orch consistently outperforms classic bandit baselines (UCB1), random assignment, and ablations without OT regularization by large margins in cumulative net utility and oracle regret. The results demonstrate the importance of explicitly incorporating output distribution alignment and uncertainty into agent orchestration to improve robustness and adaptivity in heterogeneous, evolving environments.
Key findings
- BOT-Orch achieves sublinear cumulative OT-regularized regret O(√T) under standard assumptions (Theorem 4.1).
- For agents with identical expected rewards but differing OT alignment costs, BOT-Orch prefers agents with lower Wasserstein distance, proving structural optimality (Thm 4.1).
- Under Gaussian noise in alignment measurements, BOT-Orch has margin robustness ensuring correct agent preference if alignment cost differences exceed σ√2 log 2 (Thm 4.1).
- Empirically, BOT-Orch consistently attains higher cumulative net utility and lower oracle regret across five synthetic environments including i.i.d. and non-i.i.d. task distributions (Tables 1 and 2).
- In synthetic IID-G environment, BOT-Orch’s cumulative net utility -467.53 ± 17.6 vs No-OT ablation at -588.34; similarly reduced regret (122.65 vs 243.47).
- In non-stationary NonIID-PS setting, BOT-Orch achieves net utility -498.28 ± 22.49 vs No-OT -642.77 and regret 126.77 vs 271.26, showcasing robustness to distributional shifts.
- In a semi-synthetic human–AI triage task under deployment shift, BOT-Orch increases team accuracy to 0.993 ± 0.007 vs No-OT 0.905 and reduces alignment cost by an order of magnitude (Table 3).
- Ablation shows OT regularization parameter λ strongly influences performance, with gains peaking around λ ≈ 3.0.
Threat model
The adversary can induce non-stationary, possibly adversarial shifts in task distributions and agent output characteristics but cannot manipulate the orchestration algorithm or access internal reward and alignment costs beyond standard bandit feedback. Agents are assumed heterogeneous but non-strategic and non-malicious with bounded reward distributions and Lipschitz continuous OT cost functions. The orchestrator does not have access to full information about reward or alignment distributions and must learn under partial, stochastic feedback.
Methodology — deep read
The authors formalize the problem as sequential delegation of tasks drawn from a stochastic, possibly non-stationary process to M heterogeneous agents, where each agent’s reward and output distribution vary over time. The orchestration policy selects agents probabilistically each round, seeking to maximize net expected reward penalized by a Wasserstein distance-based alignment cost measuring distributional mismatch between agent outputs and task-specific reference distributions.
Threat model & assumptions: They consider an adversary that induces non-i.i.d. task contexts and noisy agent outputs but assume bounded rewards and Lipschitz continuous OT cost functions. Adversaries cannot alter the OT metric or the learning update mechanism. The approach accounts for latent frailty variables modeling unobserved task difficulty and allows non-stationarity, but does not cover fully adversarial or strategic agents explicitly.
Data & setting: Tasks arrive either i.i.d. or following non-stationary regimes (piecewise variance shifts, sinusoidal drift, Brownian-bridge latent mean changes) in synthetic settings. Rewards are drawn from distributions with matched means but different higher-order moments and covariances. Semi-synthetic data uses Breast Cancer Wisconsin dataset split with simulated deployment shift via feature perturbations.
Algorithm: BOT-Orch implements an exponential weights (softmax) bandit policy updated at each round based on realized survival-adjusted rewards minus λ times OT alignment costs (Wasserstein distances). OT costs compare the selected agent’s output distribution µ_i and a task reference ν_t, estimated by Wasserstein barycenters or time-adaptive barycenters for drift. Survival-based rewards model time-to-success and censoring via frailty-adjusted survival functions. A history correction term in non-i.i.d. algorithm variant enables adaptivity to temporal correlations.
Training regime: The policy update step size η_t decays at O(t^{-1/2}), ensuring convergence. The policy weight vector ϕ_t is updated via stochastic approximation under noisy reward-cost signals. Experiments run on standard CPU with multiple random seeds ensuring statistical robustness.
Evaluation: Metrics include cumulative net utility (reward - λ alignment cost), cumulative alignment cost, oracle regret (performance gap vs oracle with full knowledge), team accuracy, and escalation rate in triage setting. Baselines include a No-OT ablation (λ=0), uniform random agent selection, and classical UCB1 bandit without alignment costs. Statistical significance of performance gaps is reported with 95% confidence intervals over multiple seeds.
Reproducibility: Algorithms and synthetic environments are described in detail with pseudocode. Semi-synthetic experiments use a public benchmark (Breast Cancer Wisconsin), though code release is not explicitly mentioned in the provided text. Theoretical guarantees are proven in appendices.
Concrete example: In the NonIID-PS setting, tasks’ reward variances abruptly shift at unknown changepoints. BOT-Orch uses the non-i.i.d. algorithm variant with history-aware correction to update agent policies. At each round t, after observing task x_t, it computes the Wasserstein distance between agent output distributions and a sliding-window barycenter reference ν_t, then updates agent weights ϕ_t via softmax of survival-based reward minus λ times OT cost. Over 200 rounds, BOT-Orch adapts agent selection to favor those maintaining good output alignment despite variance shifts, achieving significantly lower oracle regret and higher net utility than baselines that do not use OT alignment or history correction.
Technical innovations
- Formulating agent orchestration as a multi-armed bandit regularized by Optimal Transport distances between agent output distributions and task-specific reference distributions.
- Introducing survival-based frailty modeling into bandit rewards, capturing latent task difficulty and censoring within multi-agent orchestration.
- Theoretically proving sublinear O(√T) regret, structural agent preference based on distributional alignment, and robustness to noisy OT alignment costs.
- Designing a scalable non-i.i.d. extension via history-corrected policy updates accommodating temporal correlations and non-stationary task distributions.
Datasets
- Synthetic IID-G, IID-M, NonIID-PS, NonIID-SD, NonIID-BB — varying sizes (T=200 rounds) — synthetic task and reward generation models
- Breast Cancer Wisconsin (Diagnostic) dataset — 569 samples — public UCI dataset; split into train, calibration, Test-ID, Test-Shift subsets for semi-synthetic human–AI triage experiments
Baselines vs proposed
- IID-G: No-OT cumulative net utility = -588.34 ± 23.19 vs BOT-Orch = -467.53 ± 17.60; Oracle regret 243.47 vs 122.65
- IID-M: No-OT net utility -478.54 ± 20.49 vs BOT-Orch -386.10 ± 10.04; Oracle regret 166.25 vs 74.70
- NonIID-PS: No-OT net utility -642.77 ± 25.89 vs BOT-Orch -498.28 ± 22.49; Oracle regret 271.26 vs 126.77
- NonIID-SD: No-OT net utility -644.68 ± 21.62 vs BOT-Orch -492.92 ± 18.74; Oracle regret 280.53 vs 128.77
- Human–AI triage Non-IID: No-OT team accuracy 0.905 ± 0.016 vs BOT-Orch 0.993 ± 0.007; cumulative alignment cost 10.84 vs 0.85
- UCB1 baseline consistently underperforms BOT-Orch by 20-30% in oracle regret across conditions
- Random baseline lowest performance, confirming learning benefit of BOT-Orch
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.27073.
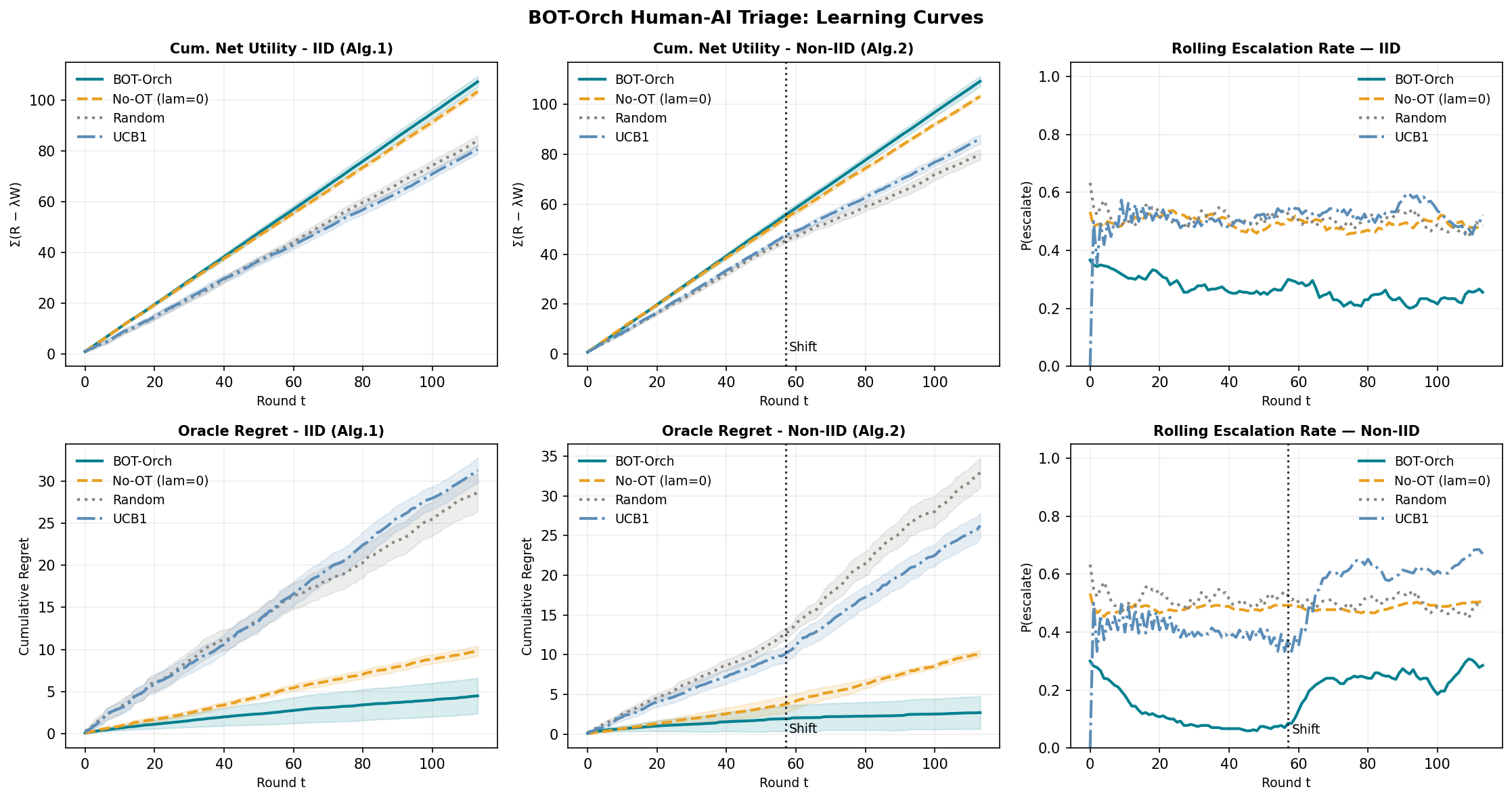
Fig 1: Cumulative learning curves. Top row: cumulative net utility. Bottom row:
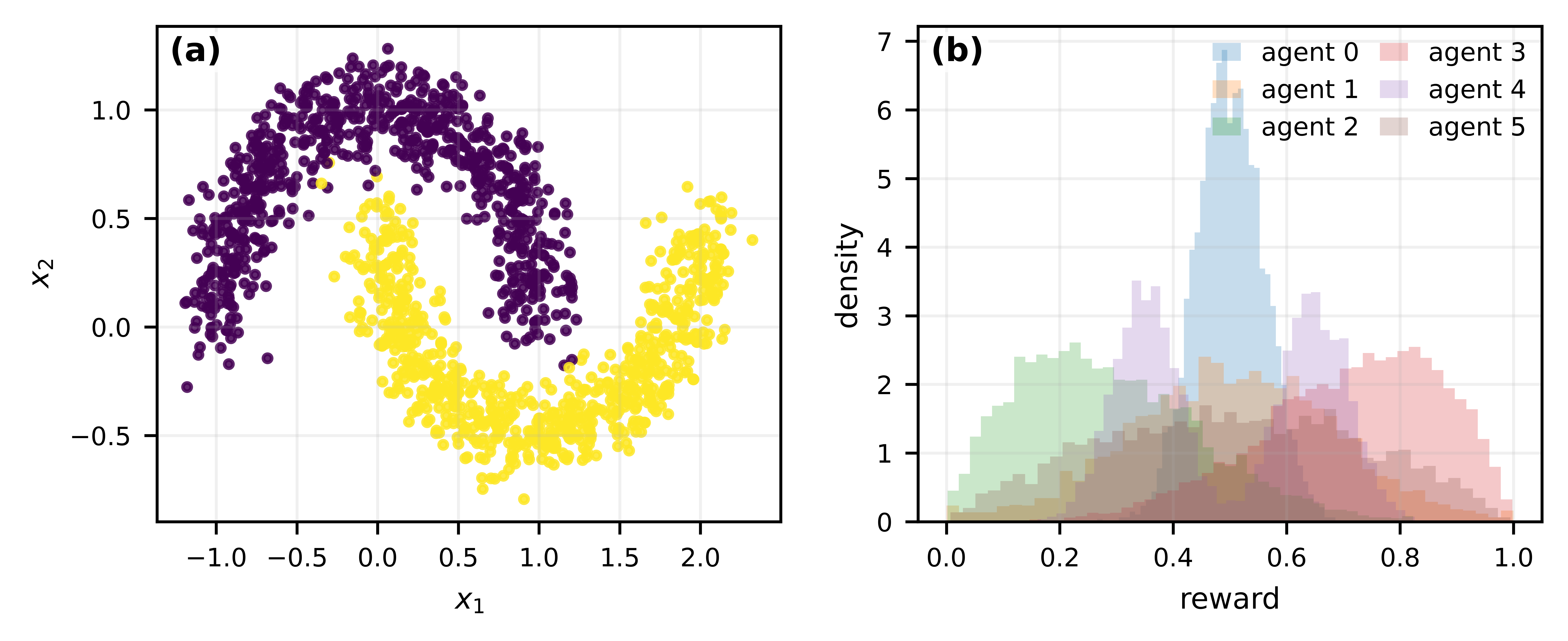
Fig 2: IID data generation (a) IID task contexts sampled from a half-moons distribution,
Fig 3: Non-IID data generation (a) Piecewise-stationary rewards where the variance
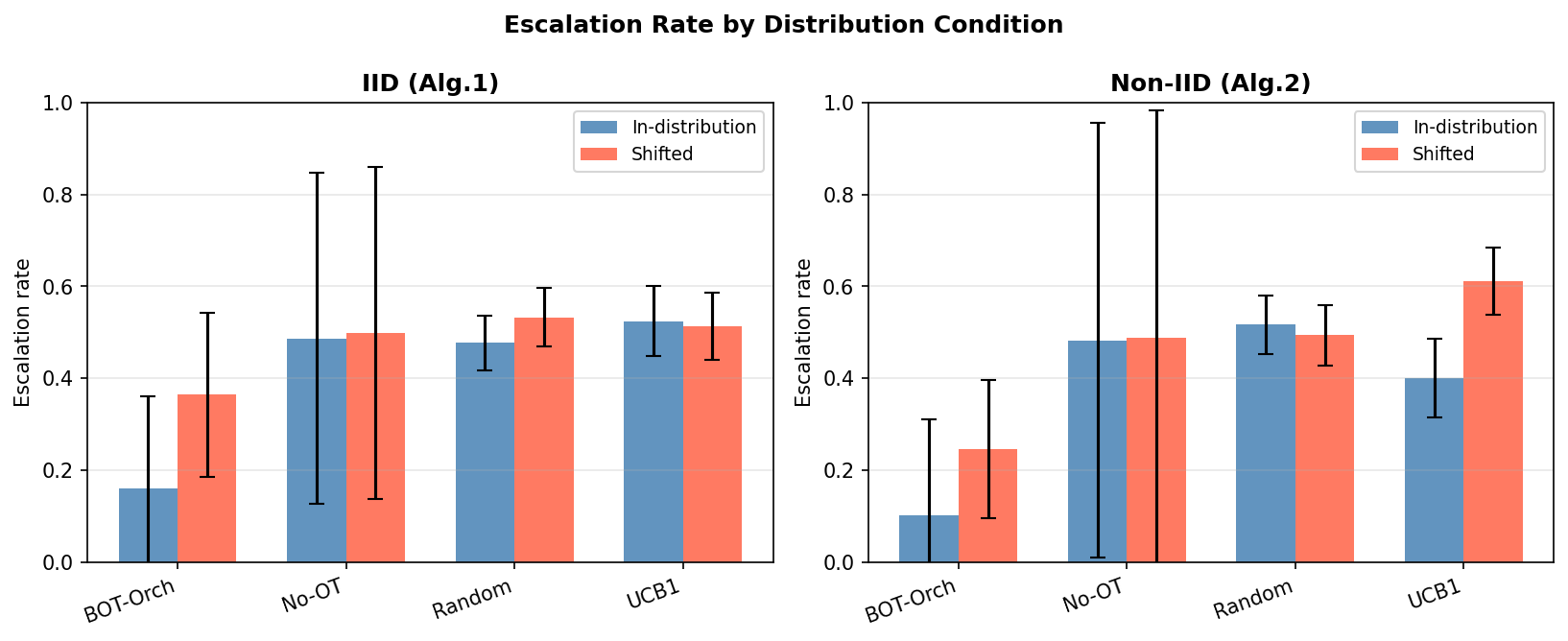
Fig 4: and 5 provide diagnostic analyses.
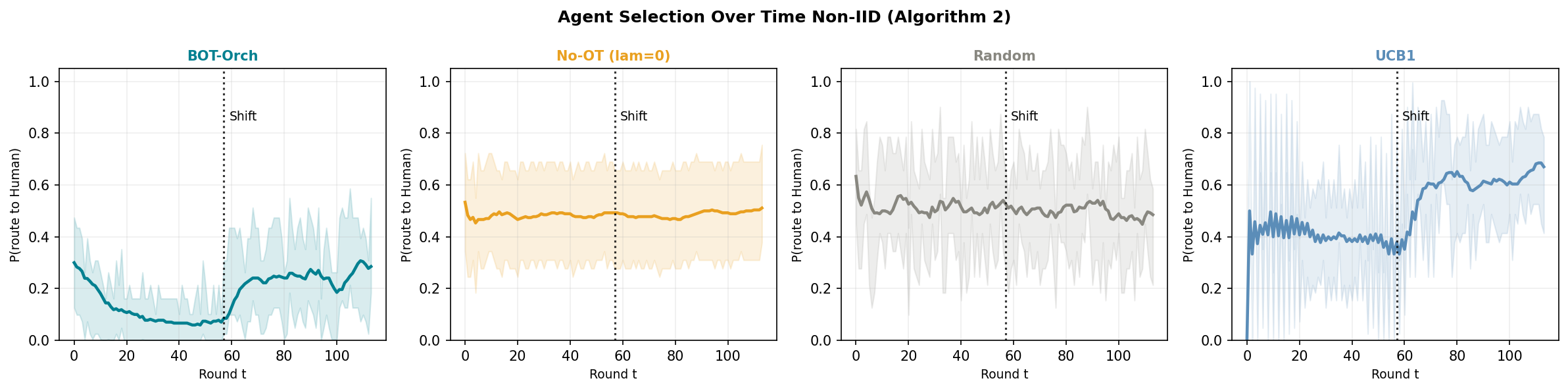
Fig 5: Agent selection trajectories, Non-IID condition (Algorithm 2). Rolling
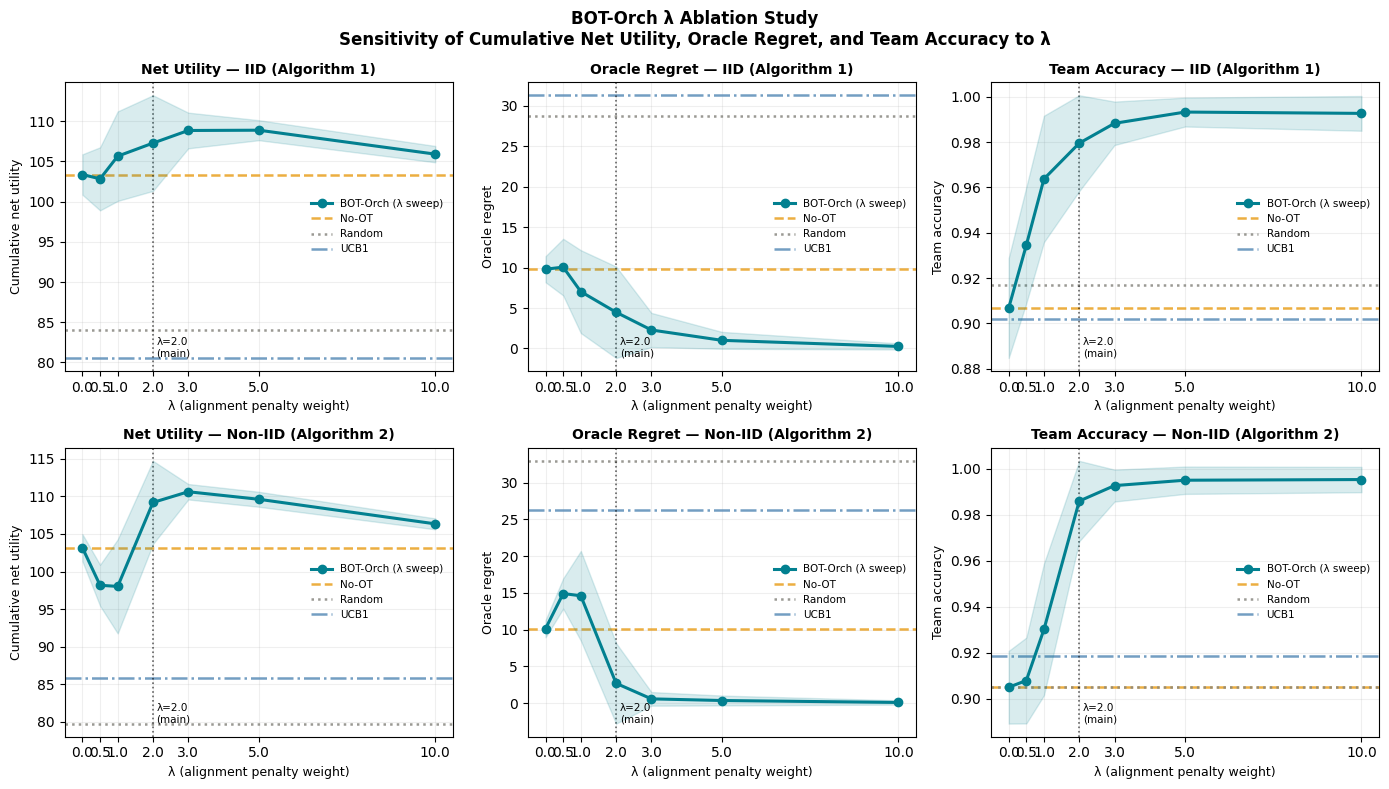
Fig 6: λ sensitivity curves. Cumulative net utility (left), oracle regret (centre), and team
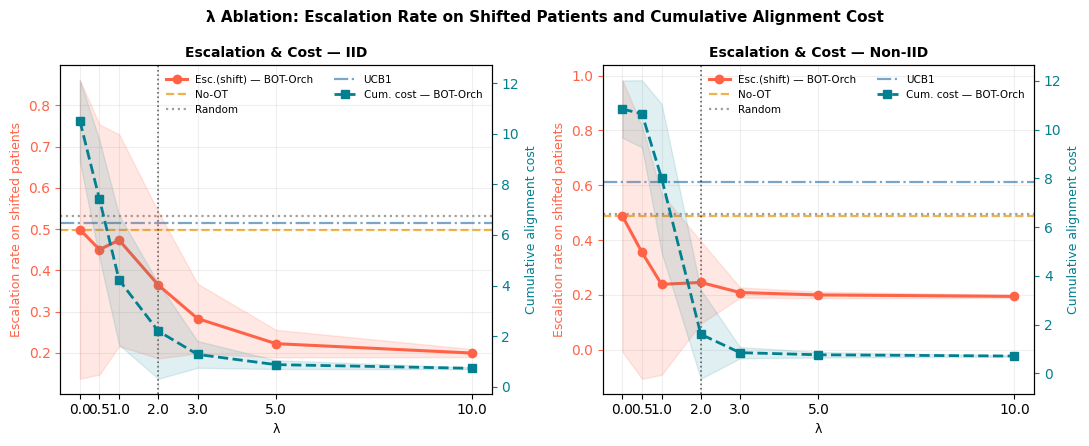
Fig 7: Escalation rate on shifted patients (left axis, red) and cumulative alignment
Limitations
- Computing Wasserstein distances can be computationally expensive in high-dimensional settings, limiting real-time scalability.
- The alignment trade-off parameter λ requires careful calibration; over- or under-weighting OT costs can degrade performance.
- The approach assumes access to suitable task-specific reference distributions; estimating these reliably in open-world or rapidly evolving environments may be challenging.
- The framework and experiments focus on single-agent delegation per task; coordination across multiple simultaneously delegated agents is not addressed.
- No adversarial or strategic agent behavior is explicitly modeled; resilience to malicious agents remains an open question.
- Reproducibility may be limited by absence of publicly released code and reliance on synthetic and semi-synthetic datasets.
Open questions / follow-ons
- How to scale OT-based alignment computations efficiently for very high-dimensional or large-scale agent output distributions?
- How to generalize the framework to multi-agent delegation per task or richer interaction structures beyond single-agent assignment?
- How to design adaptive or automated tuning schemes for the alignment regularization parameter λ in varying environments?
- How robust is BOT-Orch to strategic or adversarial agents aiming to manipulate rewards or alignment signals?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights the importance of explicitly modeling uncertainty and distributional output alignment when orchestrating multiple specialized agents or classifiers under evolving and uncertain environment conditions. BOT-Orch’s incorporation of Optimal Transport distances provides a principled way to quantify disagreement or mismatch between agent outputs and expected task distributions, beyond mean performance metrics. This can help in dynamically selecting or deferring to more reliable detection or verification modules as adversarial or shifting bot behaviors evolve over time.
The framework’s ability to handle non-stationary settings through history-aware policy updates and robust regret guarantees suggests practical applicability in adaptive multi-model CAPTCHA systems or layered defense architectures where agent reliability varies and cannot be assumed stationary. However, careful calibration of alignment parameters would be needed to balance false positives and detection costs. Overall, BOT-Orch offers an elegant method to integrate uncertainty-aware, distributional alignment into agent orchestration, a useful direction for enhancing robustness and adaptivity in CAPTCHA and bot-defense pipelines involving multiple detection heuristics or models.
Cite
@article{arxiv2605_27073,
title={ Learning to Orchestrate Agents under Uncertainty },
author={ Mary Chriselda Antony Oliver and Lan Jiang and Aaron Bundi Anampiu and Elaf Almahmoud and Francesco Quinzan and Umang Bhatt },
journal={arXiv preprint arXiv:2605.27073},
year={ 2026 },
url={https://arxiv.org/abs/2605.27073}
}