
HTMLCure: Turning Browser Experience into State Guided Repair for Interactive HTML
Source: arXiv:2605.26807 · Published 2026-05-26 · By Jiajun Wu, Jian Yang, Tuney Zheng, Wei Zhang, Haowen Wang, Yihang Lou et al.
TL;DR
The paper addresses a key challenge in large language model (LLM) generated HTML: while many generated pages render visually at first glance, they fail under interactive use cases such as scrolling, clicking, hovering, resizing, or gameplay. Traditional screenshot-based or static evaluation misses these failures, leading to overly optimistic assessments and filtering out pages that could be repairable. HTMLCure proposes a browser experience-driven evaluation and repair framework that executes a page along multiple viewports and interaction states, capturing a detailed trace of visual and behavioral evidence. This multi-dimensional state is fed into a state-aware repair controller that selects targeted repair strategies (rewrite, local fix, or refinement) based on the page's current state rather than uniformly applying edits. The repaired pages are then re-executed and only quality verified candidates are exported for supervised fine tuning (SFT) data construction. On a large 97K prompt corpus, this pipeline expands a partially usable seed set into a refined 40K training set with superior quality. The refined 27B model fine tuned on this data achieves 50.6 total score and 45.2% deterministic test case pass on the HTMLBENCH-400 benchmark, matching or exceeding strong baselines such as Kimi-K2.6 and GPT-5.4, and reaching 81.2 average on the MiniAppBench validation split, improving over raw SFT by 15.3 points. The key novelty is turning browser-experienced state into a control signal that routes repairs and validation to improve data quality robustly for interactive HTML generation.
Key findings
- Only about 15% of generated HTML pages in the 97K prompt corpus are directly usable by initial browser gating (Kimi-K2.5 baseline).
- HTMLCure expands the usable seed into a candidate pool of 63,703 quality cleared pages, yielding a final refined SFT training set of 40K pages after repair and re-validation.
- HTMLCure-27B-Refined achieves 50.6 score on HTMLBENCH-400 and 45.2% deterministic test case pass, placing it in the performance band of strong baselines like Kimi-K2.6 and GPT-5.4.
- On the released MiniAppBench validation split, HTMLCure-27B-Refined attains an 81.2 average score, 15.3 points higher than raw 27B SFT under the same recipe.
- State aware repair routing significantly reduces catastrophic regressions compared to naive rewrite: rewrite in Low state succeeds +14.2 lift with 0.6% catastrophe, while rewrite in High state causes -2.7 lift with 17% catastrophe.
- Repair rounds saturate after 3-5 iterations; exporting the best checkpoint rather than the last edit preserves verified gains (Figure 5).
- Task families differ in difficulty and repair gains but all benefit from state-aware repair routing, which outperforms fixed repair policies (Figure 4).
- Regression aware acceptance weighing functionality and interactivity dimensions achieves safer repair by penalizing regressions across multiple score axes.
Threat model
Non-adversarial setting focused on HTML generation correctness: the 'adversary' is the inherent brittleness of generated HTML under interactive use. The system assumes no malicious attacker, but acknowledges that interactive failures undermine trustworthiness for users and downstream applications.
Methodology — deep read
HTMLCure assumes an adversary-free setting focused on interactive HTML generation correctness rather than security threats. The adversary is the inherent complexity and brittleness of HTML/JS interactions that cause generated pages to break beyond initial rendering.
Data provenance involves a 97,484 prompt corpus of semantic frontend tasks across six categories, including apps, content, games, data viz, 3D, and animation. The pipeline first generates candidate HTML from LLMs, then filters and repairs with browser experiential evaluation. Labels come from deterministic test case pass/fail and multi-dimensional scores on rendering, visual design, functionality, interactivity, and code quality. Data splits include raw, filtered (high scoring), and refined (repaired) subsets, with 40K final refined pages used for supervised fine tuning.
The core architecture includes a multi-layer browser execution environment that probes each page along a designed sequence of states: initial render, various viewports, interactions (click, hover, keyboard, scrolling), and deeper gameplay where relevant. The output is a structured trace of visual evidence (rendered frames, viewport snapshots) and behavioral evidence (DOM state, console logs, test case outcomes), ordered temporally.
A vision-language model (VLM) scores curated keyframes from these traces for visual design, combined with rule-based deterministic test passes for other dimensions. These compose a multi-dimensional received page score vector s=(sd)d∈D and scalar total S. Three discrete page state bands define the repair route selection policy: Low (<40) pages get holistic rewrite, Mid (40–79) pages receive diagnosis guided local fixes, High (≥80) pages are preserved or receive constrained refinement edits.
The repair controller operates in closed loop rounds: at each round t, it evaluates current page state, selects admissible repair operators for the state, prompts the LLM to produce up to 2 candidate repairs, re-executes each candidate through the browser trace, scores candidates with regression-aware composite metric Scomp that penalizes dimension regressions weighted heavier for functionality and interactivity, and selects the best candidate or retains current page if no improvement. This loop iterates up to 8 rounds or until scores surpass 97 or gains plateau.
Evaluation uses the HTMLBENCH-400 benchmark and MiniAppBench validation split. HTMLBENCH has 400 tasks covering 6 families, with 6000 deterministic test cases covering rendering, functionality, interactivity, and code checks. The benchmark allows multi-dimensional scoring and exact reproducible browser test execution. Baselines compared include strong open source and closed source LLMs and SFT variants of the same backbone tuned on different data subsets.
Comprehensive ablation studies at 9B and 27B model scales fix dataset size and training recipe, isolating data quality due to repair versus raw filtering or no repair. Ablations confirm refined repaired data improves scores and test case passes over filtered or raw data at the same scale. Statistical details on pass rates, catastrophic failure rates, and task family gains are reported. Repair rounds and checkpoint exports are analyzed to understand iteration gains and saturation.
The code base including evaluation framework and benchmark is released for reproducibility but the final datasets come from internal crawling and filtering. Exact training recipes reuse LlamaFactory, with hyperparameters unspecified but consistent across runs. The controller is a fixed heuristic system, not learned, enabling interpretability of repair routing decisions.
Technical innovations
- Turning multi-layer browser experiential traces (visual + behavioral evidence) into a structured state signal to guide interactive HTML repair.
- State aware repair routing: selecting distinct operator families (holistic rewrite, local fix, refinement) conditioned on experienced page score bands instead of uniform editing.
- Closed loop repair with re-execution and regression-aware candidate acceptance to maintain multidimensional quality and avoid regressions across rendering, functionality, and interactivity.
- Using the best verified checkpoint export instead of last edit to construct a refined SFT dataset from repaired pages.
- Multi-dimensional scoring combining deterministic browser test case passes with VLM visual scoring over curated keyframes sampled from interaction trajectories.
Datasets
- HTMLBENCH-400 — 400 tasks, 6,000 deterministic test cases, released benchmark
- MiniAppBench validation split — released external validation set
- 97K prompt corpus — internal browser crawled, sources not publicly specified
Baselines vs proposed
- Kimi-K2.6: HTMLBENCH score = 49.8, TC pass = 43.7% vs HTMLCure-27B-Refined: score = 50.6, TC pass = 45.2%
- GPT-5.4: HTMLBENCH score = 49.2, TC pass = 42.7% vs HTMLCure-27B-Refined: score = 50.6, TC pass = 45.2%
- Qwen3.5-27B Raw SFT: MiniAppBench avg = 65.9 vs HTMLCure-27B-Refined: 81.2 (+15.3 points)
- HTMLCure-9B Raw: HTMLBENCH score = 43.0, TC pass = 41.4% vs Refined: 48.5 & 42.1%
- Ablation matched at equal data size with 12,392 samples (9B scale): Raw (score 41.9) < Filtered (45.1) < Refined (47.5) on HTMLBENCH
- Ablation matched at equal data size (27B scale): Raw (45.0) < Filtered (48.2) < Refined (49.9) on HTMLBENCH
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.26807.

Fig 1: Problem setting and full pipeline objective. HTMLCURE evaluates

Fig 2: HTMLCURE pipeline. The evaluator gathers browser evidence and curated keyframes, the
Fig 3 (page 1).

Fig 4 (page 1).
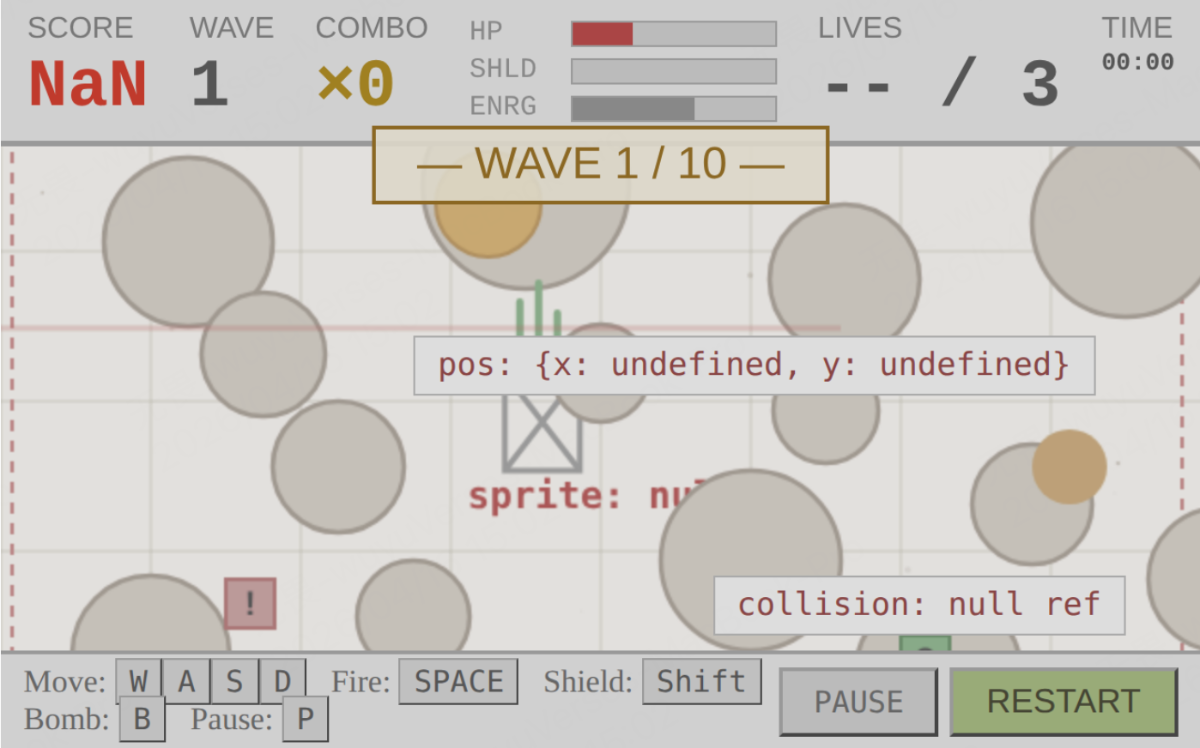
Fig 5 (page 1).
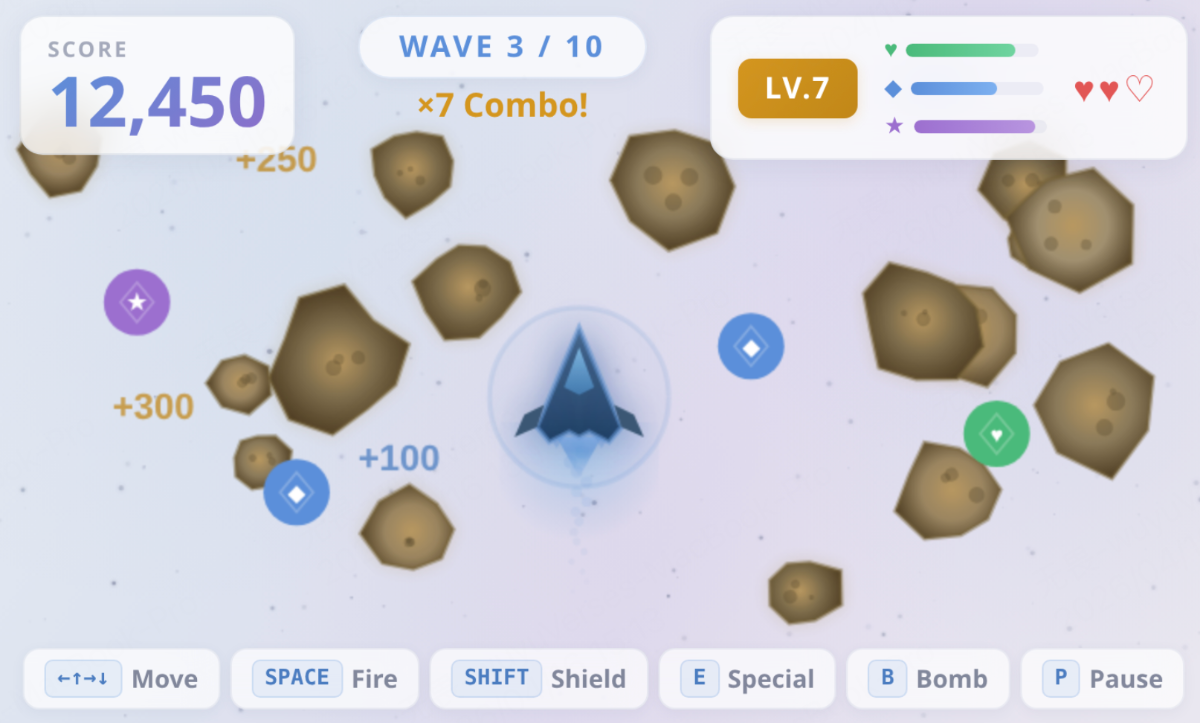
Fig 6 (page 1).

Fig 7 (page 1).

Fig 8 (page 1).
Limitations
- VLM scoring still bounded and limited to visual design aspects; may miss deeper interaction bugs.
- Browser probes are deterministic but cannot cover every possible user interaction or timing-sensitive states.
- The repair controller is a fixed heuristic not a learned policy, potentially limiting adaptability.
- Focuses on single file HTML; does not handle multi-file projects, external data, or complex stateful web apps.
- The datasets used for repair training are not fully public, which may limit external reproducibility.
- Complex gameplay and coupled timing/state failures remain challenging and partially unsolved.
Open questions / follow-ons
- Can repair routing and stopping be learned from data rather than fixed heuristics, enabling more adaptive repair policies?
- How to extend browser experience evaluation and repair from single file HTML to multi-file, multi-resource web apps with complex state and backend interactions?
- How to increase probe coverage and improve VLM judgment for subtler interactive failures, especially in timing-critical or stateful gameplay scenarios?
- How generalizable are the repair and scoring strategies to other frontend frameworks or programming environments?
Why it matters for bot defense
From a bot-defense and CAPTCHA perspective, HTMLCure’s approach highlights the importance of comprehensive interactive evaluation beyond superficial rendering checks. Many modern bot interactions mimic human actions including clicks, scrolls, and keypresses. Simple screenshot-based or static heuristics may overlook subtle failures or behavioral deviations in bots versus humans. HTMLCure’s multi-layer browser experience evaluation and state-aware repair logic can inspire more robust bot detection frameworks that incorporate stateful interaction traces and repair/validation loops.
Moreover, the concept of leveraging detailed interaction state and deterministic probing signals to direct targeted repair or reclassification could be adapted to CAPTCHA challenges that require dynamic user interface correctness or complexity over time. Rather than a single challenge-response frame, incorporating adaptive sequences and scoring over multi-step interactions is analogous to the layered evaluation strategy here. Practitioners building bot-defense mechanisms can seek to combine static verification with interactive experience monitoring and iterative feedback-driven refinement to reduce false positives/negatives and better distinguish scripted bot behavior from legitimate human browsing patterns.
Cite
@article{arxiv2605_26807,
title={ HTMLCure: Turning Browser Experience into State Guided Repair for Interactive HTML },
author={ Jiajun Wu and Jian Yang and Tuney Zheng and Wei Zhang and Haowen Wang and Yihang Lou and Xianglong Liu },
journal={arXiv preprint arXiv:2605.26807},
year={ 2026 },
url={https://arxiv.org/abs/2605.26807}
}