
Toward Natural Emotional Text-To-Speech System with Fine-Grained Non-Verbal Expression Control
Source: arXiv:2605.25504 · Published 2026-05-25 · By Wangzixi Zhou, Bagus Tris Atmaja, Sakriani Sakti
TL;DR
This paper addresses a key limitation in emotional text-to-speech (TTS) systems: the insufficient modeling and control of non-verbal vocalizations (NVs) such as laughter, crying, and yelling, which play a critical role in authentic emotional expression. Existing NV datasets are limited by coarse, simplistic annotations that do not allow fine-grained control of the type, frequency, or duration of non-verbal sounds, thus restricting the naturalness and expressiveness of generated emotional speech. To overcome this, the authors curated a fine-grained NV dataset from the female speaker portion of the EARS corpus, introducing a novel annotation scheme that encodes NV style, frequency, and duration with detailed tags.
They then built an emotional TTS system based on Grad-TTS augmented with an emotion encoder and an NV-aware text processing pipeline. Their system demonstrated substantial improvements in emotional expressiveness (eMOS 4.20) and emotion recognition accuracy (78.8%) compared to baselines using only verbal cues or coarse-grained NV annotations. Emotion-specific results confirmed that NVs especially boost recognition accuracy for high-arousal emotions like happy (82.5%) and fear (82.7%), while sadness was nearly perfectly conveyed (98.3%). A human preference study further validated the effectiveness of nuanced multi-part NV expressions. Overall, the paper provides a compelling demonstration that fine-grained modeling of non-verbal vocal expressions is a critical step toward natural, highly expressive emotional TTS.
Key findings
- Fine-grained NV emotional TTS achieves an expressiveness mean opinion score (eMOS) of 4.20, outperforming verbal-only and coarse-grained NV baselines.
- Emotion recognition accuracy improved by 13.3% over verbal-only baseline, reaching 78.8% with fine-grained NV control.
- Happy emotion recognition increased to 82.5% accuracy, fear to 82.7%, and sadness to 98.3% with fine-grained NV cues.
- Including NVs caused a minor trade-off in naturalness MOS (fine-grained NV nMOS 3.43 vs verbal-only 3.54).
- Coarse-grained NV annotations (from NVTTS corpus) had lower emotional recognition accuracy and sometimes confused happy cues as sadness.
- Non-verbal vocalizations were segmented from 60 female speakers of EARS corpus, yielding 739 utterances of 2–6 seconds each.
- Preference tests showed participants favored cheering sounds over laughter for 'happy' and complex crying expressions over simpler ones for 'sad' emotions.
- The specialized NV text processing pipeline parses style, discrete units, and duration from fine-grained annotation tags to produce structured NV tokens for Grad-TTS.
Threat model
n/a - This is a system-building paper focused on improving emotional expressiveness of TTS via non-verbal vocalizations rather than threat modeling or adversarial attacks.
Methodology — deep read
Threat Model & Assumptions: The paper assumes the adversary is not explicitly modeled; the focus is on improving emotional expression in synthesized speech rather than adversarial robustness. The system targets realistic emotional TTS with fine-grained NV control, assuming access to labeled NV data.
Data: The authors curated NV utterances from the female subset (60 speakers) of the EARS corpus, a high-quality speech dataset containing diverse speaking styles and emotional vocalizations. Audio was segmented into 739 clips (2–6s each) at 22.05 kHz sampling rate using silence detection (-40 dBFS threshold, min 200 ms silence). The fine-grained annotation scheme encodes NV type (laughter, crying, cheering, yelling, screaming), frequency (repetitions of discrete units), and duration (length of continuous vocalizations).
Architecture / Algorithm: The baseline TTS model is Grad-TTS, a diffusion probabilistic model for high-fidelity speech synthesis. An emotion encoder was added to ingest continuous arousal and valence labels based on Russell’s circumplex model. The text processing pipeline was extended with a Non-Verbal (NV) processor composed of three parsers: style parser (identifies NV category), discrete unit parser (counts repetitions in discrete vocalizations), and duration parser (measures length from continuous vocalizations). This allows explicit embedding of structured NV tokens alongside verbal text.
Training Regime: A 9-hour mixed English female emotional speech dataset was compiled from EXPRESSO, SEMAINE, and ESD corpora. Missing arousal and valence labels were inferred using a Speech Emotion Recognition model. The TTS was trained with mel-spectrogram inputs (80-dim) for 400,000 iterations on a single NVIDIA RTX A6000 GPU. Hifi-GAN vocoder was used to convert mel-spectrograms to audio waveforms.
Evaluation Protocol: Subjective listening tests with 15 human participants evaluated three conditions: verbal-only, verbal + coarse-grained NV (NVTTS corpus), and verbal + fine-grained NV. Twenty ambiguous sentences ensured prosody carried emotional info. Metrics collected included naturalness MOS (nMOS), expressiveness MOS (eMOS), and 4-class emotion recognition accuracy (happy, sad, fear, anger). A preference test separately evaluated variations of happy and sad NV expressions.
Reproducibility: The fine-grained NV dataset derived from EARS, and existing datasets EXPRESSO, SEMAINE, ESD were used, with some data inferred via pre-trained models. The source code or pretrained model weights are not explicitly mentioned as released, but speech samples are publicly available on the project demo page. The NV annotations and parsers are described in detail.
Example end-to-end: An input text with fine-grained NV annotations like "<(crying) wuuuuu whep> why you do this to me" is processed by the NV processor which identifies "crying" style, discrete vocalizations "whep" count, and continuous "wuuuuu" duration to create NV tokens. These tokens along with verbal text and emotion embeddings are fed into Grad-TTS to synthesize speech containing controlled crying vocalizations conveying sadness. Human listeners then rate naturalness, expressiveness, and perform emotion recognition tasks on this sample, enabling comprehensive assessment of the fine-grained NV approach.
Technical innovations
- A novel fine-grained annotation scheme for non-verbal vocalizations encoding style, frequency, and duration enabling precise NV control beyond coarse tags.
- Integration of an NV processor with style, discrete unit, and duration parsers into the text pipeline before synthesis for structured NV token representation.
- Augmentation of Grad-TTS with an emotion encoder using continuous arousal-valence embeddings to synthesize emotional speech with fine-grained NV expressions.
- Compilation of a curated female NV subset from EARS corpus producing 739 annotated NV utterances designed for fine-grained emotional TTS training.
Datasets
- EARS female NV subset — 739 utterances (2–6 seconds each) — curated and reprocessed from EARS corpus
- EXPRESSO — multi-hour emotional speech dataset — public
- SEMAINE — emotional character interaction recordings — public
- ESD — Emotional Speech Database — public
- NVTTS corpus — 17-hour dataset with coarse-grained NV annotations used for baseline comparisons
Baselines vs proposed
- Only Verbal: emotion recognition accuracy = 65.5% vs Fine-Grained NV: 78.8%
- Only Verbal: Expressiveness MOS (eMOS) = ~3.8 vs Fine-Grained NV: 4.20
- Only Verbal: Naturalness MOS (nMOS) = 3.54 vs Fine-Grained NV: 3.43
- Coarse-Grained NV (NVTTS corpus): recognition accuracy (happy) < Fine-Grained NV (82.5%)
- Coarse-Grained NV: eMOS < Fine-Grained NV (exact values not explicitly reported for coarse NV eMOS except it underperforms)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.25504.
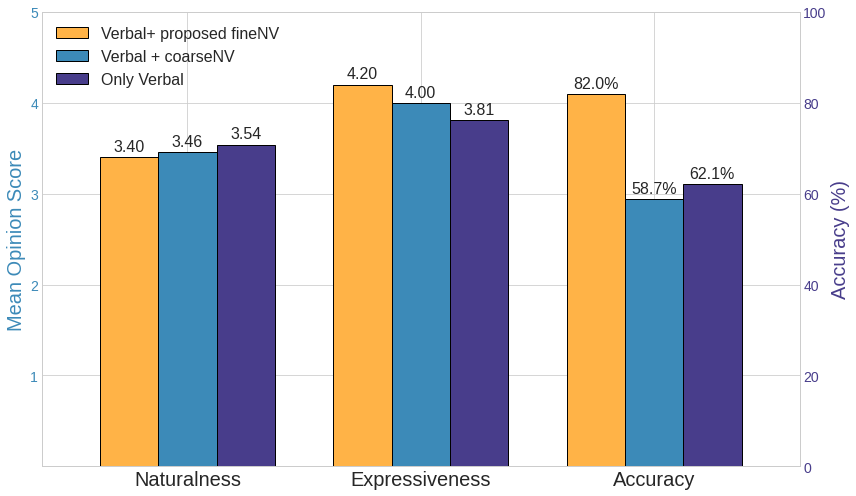
Fig 2: The figure provides performance results of three de-
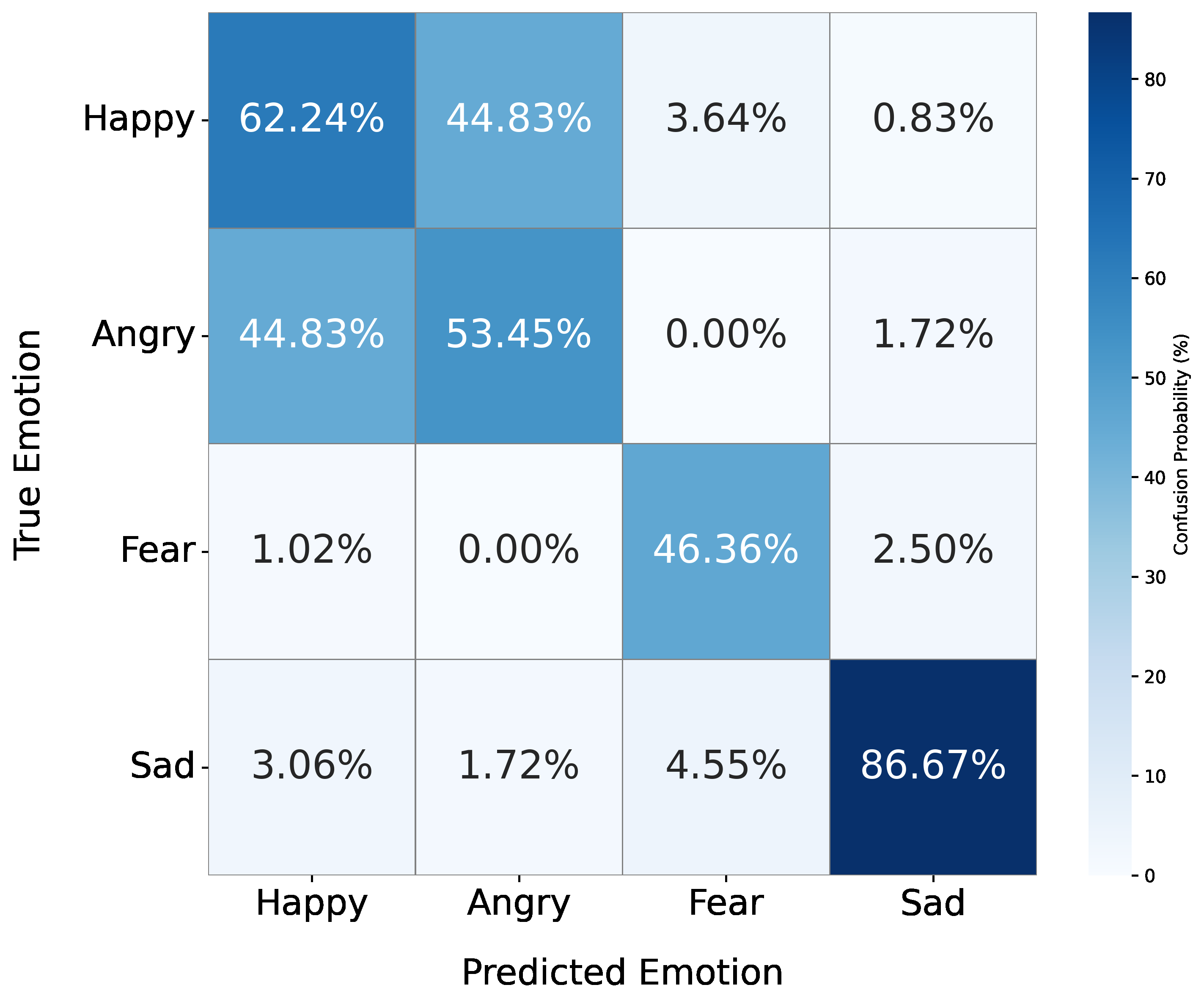
Fig 3: Emotion recognition confusion matrices for (a) Only verbal, (b) Verbal + coarse-grained non-verbal, and (c) Verbal +
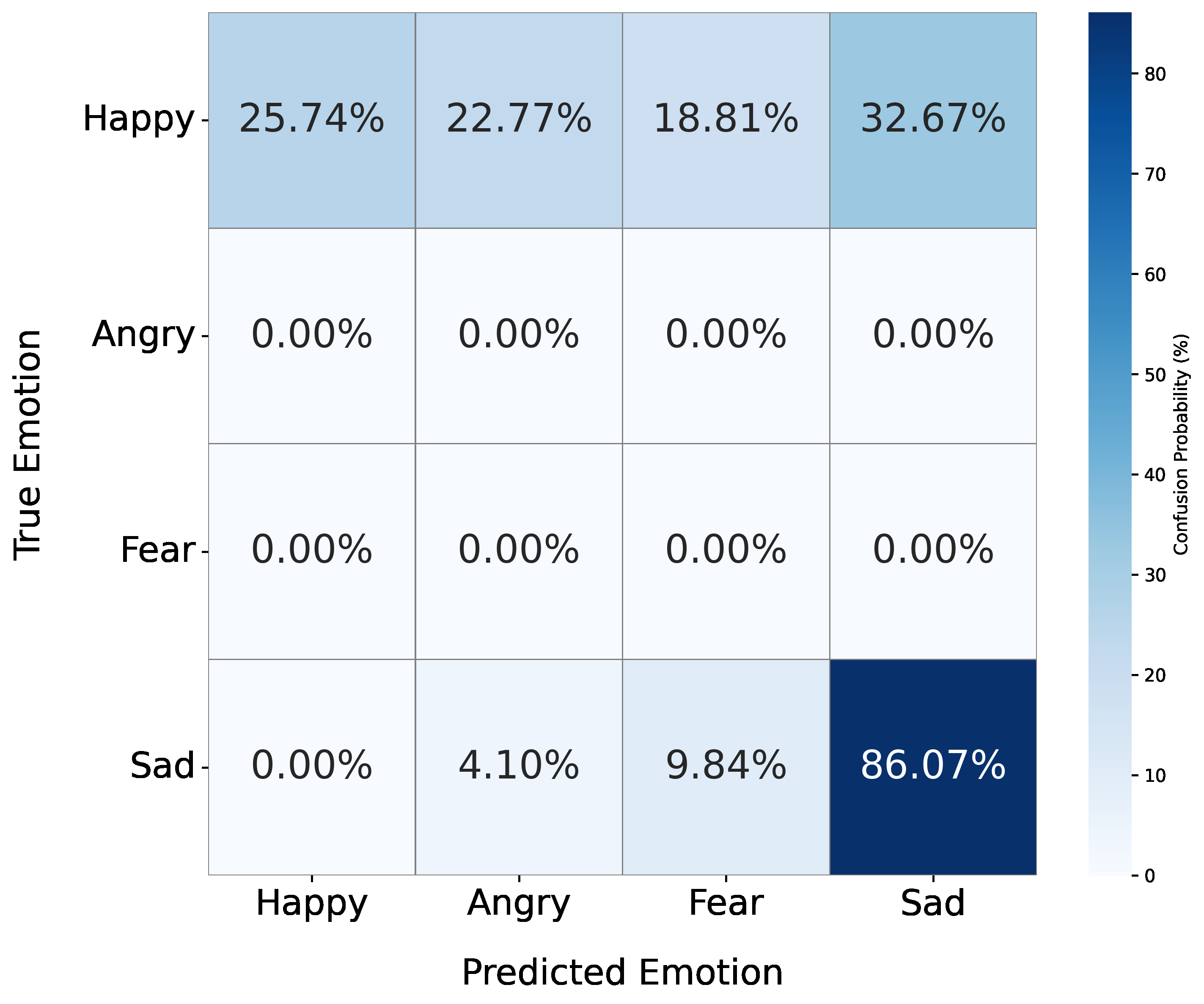
Fig 4: Preference evaluation results for different non-verbal
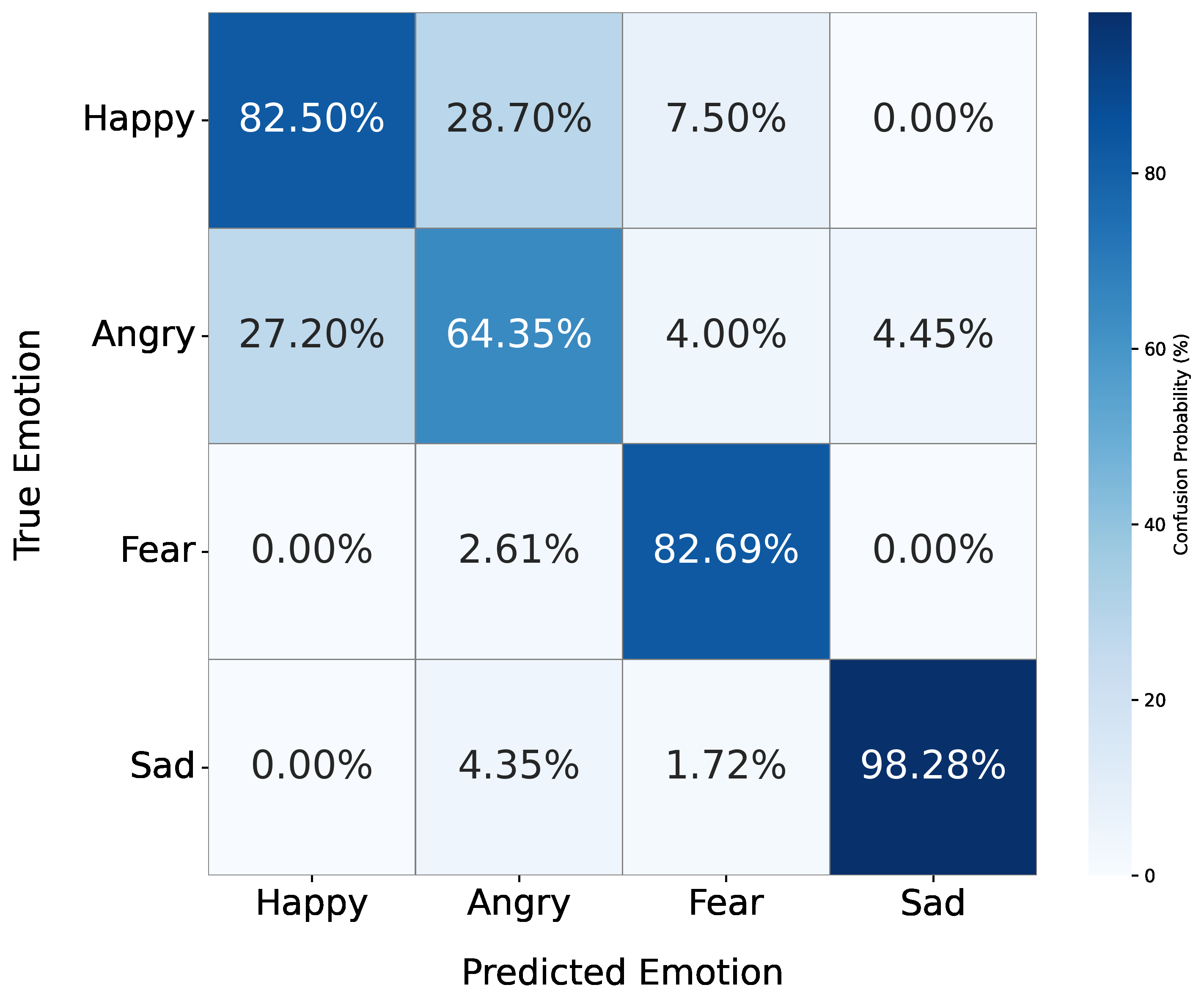
Fig 4 (page 5).
Limitations
- Minor decrease in perceived naturalness when adding fine-grained NVs (nMOS drops from 3.54 to 3.43).
- Small subjective evaluation sample size (15 participants), limiting generalizability of listening test results.
- Emotion categories limited to happy, sad, fear, and anger, with limited non-verbal cues for anger reducing improvements.
- Dataset focused exclusively on female speakers from EARS limiting gender diversity and broader generalization.
- No adversarial robustness or real-world noisy environment evaluation reported.
- The coarse-grained NV baseline uses a limited dataset lacking fear/anger NVs, making direct comparisons uneven.
Open questions / follow-ons
- How would the fine-grained NV approach perform on male or mixed-gender datasets and diverse languages or cultures?
- Can the framework generalize to real-time streaming TTS applications with dynamic NV control?
- What are the effects of adding other non-verbal cues such as breathing, sighs, or subtle voice tremors beyond the six NV categories?
- How robust is the model under noisy or conversational real-world conditions, and can adversarial NV attacks cause misclassification or degradation?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights the importance of capturing subtle non-verbal vocal cues to improve the realism and human-likeness of synthesized speech in dialog systems. Fine-grained NV control could help in detecting synthesized speech or differentiating human users from bots by analyzing nuanced emotional vocal patterns that are hard for bots to mimic naturally. Conversely, attackers may aim to replicate these fine-grained NV cues to bypass voice biometrics or emotion-based security measures, so understanding such advanced TTS capabilities helps inform more robust bot detection criteria. Careful annotation and modeling of NVs also suggest potential signals that could be leveraged to strengthen liveness detection or behavioral biometrics in voice-based CAPTCHAs.
Cite
@article{arxiv2605_25504,
title={ Toward Natural Emotional Text-To-Speech System with Fine-Grained Non-Verbal Expression Control },
author={ Wangzixi Zhou and Bagus Tris Atmaja and Sakriani Sakti },
journal={arXiv preprint arXiv:2605.25504},
year={ 2026 },
url={https://arxiv.org/abs/2605.25504}
}