
StreamProfileBench: A Benchmark for Fine-Grained User Profile Inference in Real-World Streaming Scenarios
Source: arXiv:2605.25758 · Published 2026-05-25 · By Sizhe Wang, Feiyu Duan, Juelin Wang, Liwen Zhang, Zhongyu Wei
TL;DR
This paper addresses a key gap in user profiling research where prior work largely evaluates models on static snapshots of user-generated content (UGC), ignoring the dynamic and streaming nature of real-world personalized systems. The authors formalize streaming user profiling as a continuous state maintenance problem, where models incrementally update user profiles over time as new posts arrive. To rigorously benchmark this, they curate StreamProfileBench — a large-scale dataset of over 120,000 real posts from 7,000+ users across five major Chinese social media platforms. The benchmark also introduces a novel, annotation-free evaluation framework leveraging temporal correlations between past user profiles and future interest signals extracted from UGC streams. Their comprehensive experiments across 14 popular large language models (LLMs) reveal that continuous profile updating remains a challenging open problem. Models exhibit systemic conservative bias, favoring retention of past interests while poorly recognizing emerging or decaying interests. Ablation studies confirm the importance of the streaming paradigm over static or one-shot long-context methods. Overall, the paper establishes a foundational testbed and empirical insights for advancing fine-grained streaming user profiling.
Key findings
- StreamProfileBench dataset contains over 120,000 UGC posts from 7,000+ real users across five major platforms (Weibo, Xiaohongshu, Toutiao, Zhihu, Douban).
- The streaming profiling task is formalized as a state maintenance problem with a read-update-write loop: Pn = fθ(Bn, Pn−1), where Bn is new UGC batch and Pn−1 is prior profile.
- Evaluation uses future interest anchors as self-verifying ground truth, combining positive and distractor candidate tags with a fixed output budget, enabling annotation-free recall and error measures.
- 14 LLMs evaluated showed average recall ( ¯R) ranged from 25.18% (Llama-3.1-8B) to 52.26% (Gemini-3-Flash), with Gemini-3-Flash also best balancing novelty and stability (FNS1 = 54.97%).
- Models exhibited a strong stability-novelty recall trade-off: RecallStability was broadly > 60% while RecallNovelty was often below 30%, indicating models conservatively overweight old interests and under-recognize new ones.
- Decay error from outdated interests dominated distractor errors, averaging 48-72% error rates for decayed interest labels across models, while other distractors (peers, viral trends, random) were below 10%.
- Ablation studies showed incremental profile updating with persona passing outperformed no-passing or long context baselines, confirming the advantage of streaming over one-shot processing.
- Model performance scaled with size but plateaued beyond 14B parameters (e.g., Qwen3-14B similar to Qwen3-32B), indicating raw scale alone does not solve streaming profile challenges.
Threat model
n/a — This work is focused on benchmarking and modeling the challenge of streaming user profile maintenance in naturalistic settings rather than defending against a malicious adversary. The adversary capabilities and attack scenarios are not considered.
Methodology — deep read
Threat model & assumptions: The paper assumes an adversary-agnostic setting focused on evaluating model ability to maintain fine-grained, continuously evolving user profiles from publicly posted UGC streams. There is no adversarial attack scenario; instead, the challenge is coping with unbounded, temporally non-stationary user content, where user interests evolve rapidly. Models receive per-user batches of new UGC and prior profile state, then update the profile representation incrementally.
Data: The dataset consists of over 120,000 posts from 7,000+ real users collected over a 30-day window from five major Chinese social platforms (Weibo, Xiaohongshu, Toutiao, Zhihu, Douban). The raw data comprised ~137 million posts from 17.4 million users daily, filtered through a multi-stage pipeline selecting sustained, authentic user activity with topical diversity. Batches for streaming were emitted via per-user chronological buffering ensuring uniform information load per step. Personal information was protected via anonymization (salted hashes and LLM-based span detection).
Architecture / Algorithm: The streaming user profiling task is formalized as a continuous state maintenance problem with a read-update-write loop. At time n, the model receives new batch Bn and prior profile Pn−1, and produces updated profile Pn = fθ(Bn, Pn−1). Profiles Pn are free-form natural language descriptions encoding relevant information without structural constraints. Evaluation leverages a self-verifying framework using future UGC-derived interest anchors Tn as ground-truth signals, embedded in candidate pools mixing true positives and distractors (decayed interests, semantic peers, viral tags, random noise). Metrics focus on recall of true anchors and error rates on distractors.
Training regime: Details on training (e.g., fine-tuning, epochs) are not explicitly provided, implying models were evaluated as-found using their standard inference. Evaluation uses prompting strategies to conduct persona passing (incrementally passing prior profile as context) or no-passing baselines.
Evaluation protocol: 14 models, including closed-source (GPT-4o-mini, GPT-5 variants, Gemini-3-Flash) and open-source (MiniMax-M2.5, GLM-4.7, DeepSeek-v3.2, Llama-3.1 variants, Qwen3 series, GPT-oss models) were tested. Metrics include macro-averaged overall recall ¯R, a harmonic mean FNS1 balancing novelty (new interest recall) and stability (retained interest recall), and distractor error rates. Ablations investigated persona passing vs no passing, streaming with varied batch granularity vs long context input. Per-platform and cross-model analyses dissected recall trade-offs and error sources.
Reproducibility: Dataset and code are publicly released under a restricted research-only license with anonymization. Full details of protocols, data curation, and evaluation are provided as appendices. Exact inference prompts and batch configurations are documented. However, detailed training setups or fine-tuning recipes are not emphasized, since the benchmark evaluates existing LLMs mostly in a zero/few-shot setting.
End-to-end example: At step n, the model receives a batch of new user posts Bn along with previous profile Pn−1. It uses these inputs, via prompting, to generate an updated free-text user profile Pn describing current interests. Separately, the benchmark creates a candidate pool Cn containing positive future interest anchors (tags extracted from future posts) and distractors. The model selects a subset ˆTn from Cn to predict currently relevant interests. These predictions are scored by recall against the true anchors in Tn, providing an incremental metric of the model’s ability to track evolving user interest dynamics over time. This process repeats iteratively for all batches in the stream, accumulating results.
Technical innovations
- Formalizing streaming user profiling as a continuous state maintenance problem with a read-update-write profile evolution loop, enabling incremental updates rather than static snapshot inference.
- Curating StreamProfileBench, the first large-scale, real-world dataset for streaming user profiling spanning 120K posts from 7K+ real users across five social media platforms with temporally balanced batching.
- Introducing an annotation-free self-verifying evaluation framework leveraging future user-generated interest anchors extracted from post metadata to serve as ground truth for temporal interest drift tracking.
- Developing a novel metric suite decomposing recall into stability (retention of past interests) and novelty (recognition of emerging interests), and analyzing error types via distractor tag categories (decayed, peer, viral, random).
- Demonstrating through ablations the practical necessity of iterative persona passing in streaming scenarios over no-passing or one-shot long-context approaches.
Datasets
- StreamProfileBench — 120,000+ posts from 7,000+ real users — curated from 5 major Chinese social media platforms (Weibo, Xiaohongshu, Toutiao, Zhihu, Douban) over 30 days
Baselines vs proposed
- GPT-4o-mini: Avg Recall = 33.32% vs proposed best Gemini-3-Flash: 52.26%
- GPT-5.1: Avg Recall = 38.87% vs Gemini-3-Flash: 52.26%
- GLM-4.7: Avg Recall = 41.69% vs Gemini-3-Flash: 52.26%
- DeepSeek-v3.2: Avg Recall = 43.05% vs Gemini-3-Flash: 52.26%
- Llama-3.1-8B: Avg Recall = 25.18% vs Gemini-3-Flash: 52.26%
- Qwen3-14B: Avg Recall = 39.44% vs Gemini-3-Flash: 52.26%
- Long-context baseline recall (e.g., 39.1% for DeepSeek-V3) is consistently outperformed by streaming incremental methods with persona passing (up to 50.0%), validating streaming advantage.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.25758.

Fig 1: Illustration of differences between Static Profiling and Streaming Profiling. The streaming paradigm
Fig 2: Overview of StreamProfileBench. Top: The data-curation pipeline of StreamProfileBench. Bottom:
Fig 6: shows the batch count distribution for

Fig 4 (page 4).
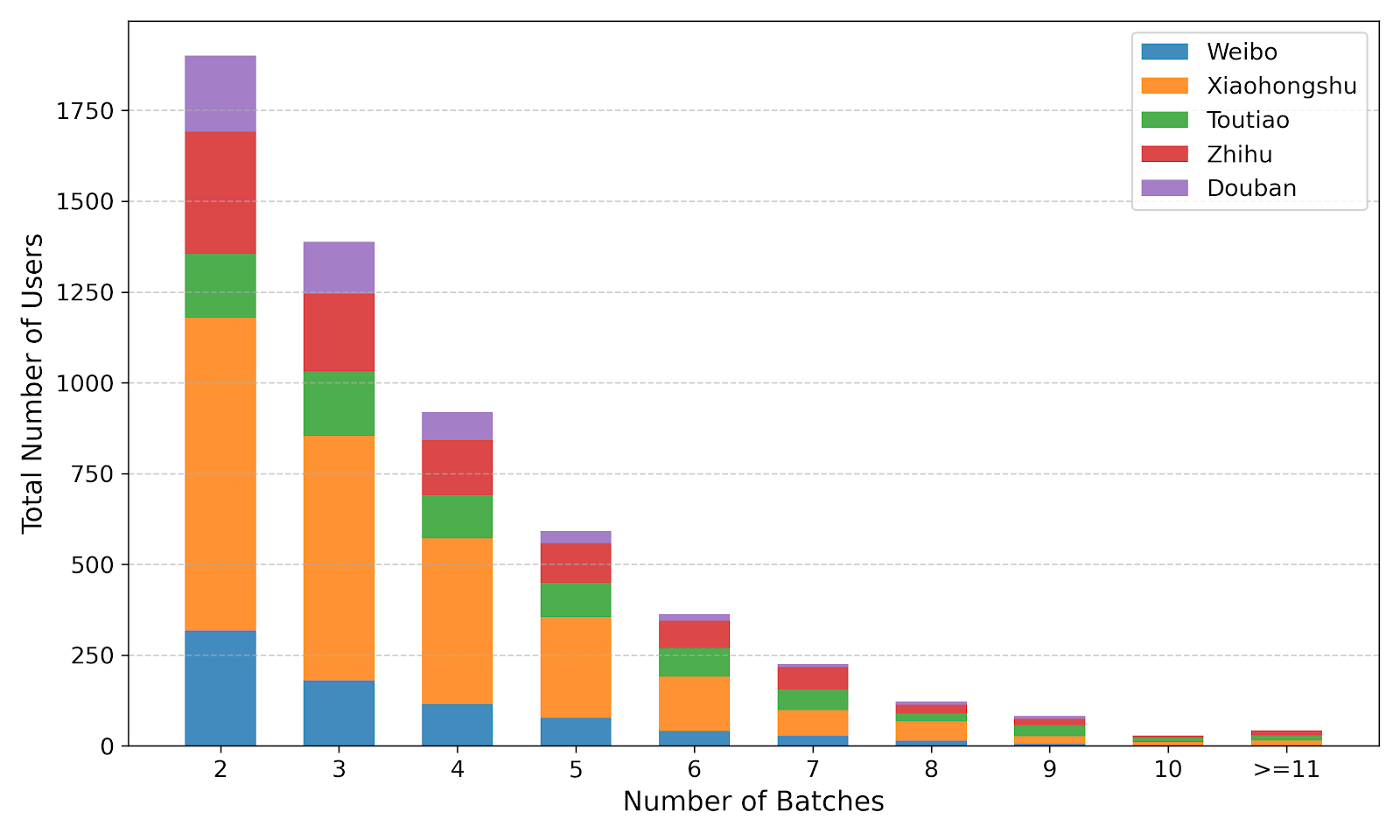
Fig 5: highlights DeepSeek-
Limitations
- Dataset relies primarily on explicit user-generated content (posts), lacking implicit or interactive signals such as clicks or dwell time that could enrich user profiles.
- Observation window spans 30 days, limiting analysis of long-term lifecycle patterns or macroscopic user interest evolution over years.
- Evaluation focuses on interest anchors extracted via heuristic rules, which may miss other nuanced profile facets such as attitudes or intentions.
- Models tested are mostly zero/few-shot evaluated without fine-tuning specific to streaming, possibly underestimating potential performance achievable with adaptation.
- Benchmark currently covers only Chinese social media data, potentially limiting generalization to other languages or user demographics.
- The conservative bias of models is observed but underlying causes (e.g., architecture, training objectives) remain unexplored in depth.
Open questions / follow-ons
- How can LLM architectures or training objectives be adapted to better recognize and respond to emerging interests while preventing stale profile retention?
- What role can implicit behavioral signals (clicks, browsing, interactions) play in complementing explicit UGC for more holistic streaming user profiling?
- Can specialized lightweight streaming user profiling models distilled from large LLMs achieve near-parity with better efficiency and maintained temporal sensitivity?
- How well do streaming profiling approaches generalize across other languages, cultures, or longer time horizons spanning months or years?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work highlights the complexity and necessity of modeling users not just from static snapshots but from continuously streaming data that reflect fast-evolving user interests. Bot behaviors can mimic real users over time only if profiling systems dynamically capture such fine-grained temporal changes. The benchmark and evaluation methodologies provide practical tools to assess whether user profiling models correctly attribute recent versus stale user interests, a crucial factor in distinguishing real or compromised accounts from bots that replay old or synthetic behaviors. Furthermore, the clear identification of failure modes, e.g., conservative bias and poor interest decay recognition, offers target areas for enhancement to reduce false positives/negatives in authentication systems. Lastly, the streaming formalism informs how profiling pipelines could be architected to maintain evolving, up-to-date user profiles for more robust behavioral authentication in continuous interaction scenarios.
Cite
@article{arxiv2605_25758,
title={ StreamProfileBench: A Benchmark for Fine-Grained User Profile Inference in Real-World Streaming Scenarios },
author={ Sizhe Wang and Feiyu Duan and Juelin Wang and Liwen Zhang and Zhongyu Wei },
journal={arXiv preprint arXiv:2605.25758},
year={ 2026 },
url={https://arxiv.org/abs/2605.25758}
}