
RePlan-Bot: Multi-Level Replanning for Embodied Instruction Following
Source: arXiv:2605.25851 · Published 2026-05-25 · By Xicheng Gong, Guozheng Sun, Peiran Xu, Yadong Mu
TL;DR
RePlan-Bot addresses key challenges in embodied instruction following (EIF) within interactive 3D environments, such as long-horizon planning, handling irreversible state changes, and recovering from execution errors. Unlike previous modular and end-to-end approaches with static or brittle planning, RePlan-Bot implements a novel multi-level continuous replanning framework through high-level LLM-based auditing for dynamic sub-goal adjustment, a commonsense-guided mid-level search leveraging a multi-layered instance map for precise object localization, and a ViT-based vision-driven low-level action corrector that anticipates and fixes risky primitive actions during execution. This layered architecture combines symbolic reasoning, spatial semantic mapping, and visual action validation to boost robustness and flexibility.
Evaluated on the ALFRED benchmark for household tasks with partial observability, RePlan-Bot achieves state-of-the-art success rates and goal completion metrics across both seen and unseen test environments, outperforming strong baselines such as CAPEAM, FILM, and Prompter. Ablation studies confirm that each of the three components—high-level LLM auditor, mid-level commonsense search, and low-level ViT corrector—significantly contributes to improved performance, with notable gains in generalization to novel and cluttered scenes. Qualitative analyses demonstrate RePlan-Bot’s ability to dynamically revise flawed plans, efficiently search occluded objects, and visually adapt actions to prevent failures, highlighting its effectiveness for long-horizon, vision-based task execution.
Key findings
- On the ALFRED Test Unseen split with task description only, RePlan-Bot achieves 44.79% Success Rate vs CAPEAM’s 40.42%, and 57.02% Goal-Condition Success vs CAPEAM’s 54.17%.
- With both task description and step-by-step instructions, RePlan-Bot further improves to 47.61% Success Rate and 60.29% Goal-Condition Success on Test Unseen, compared to CAPEAM's 43.17% SR and 56.52% GC.
- Ablation removing the high-level LLM auditor decreases SR by up to 3.19% (Test Seen) and 2.87% (Test Unseen), and GC by up to 2.40% and 2.42% respectively.
- Removing the mid-level commonsense-guided search reduces Test Unseen SR by 1.70% and GC by 0.31%, demonstrating importance for generalization.
- Eliminating the low-level ViT-based action corrector causes SR to drop by 2.41% and GC by 1.94% on Test Unseen, showing its role in mitigating execution failures.
- Figure 3 shows RePlan-Bot effectively searches multiple cabinet instances to find an occluded sponge, whereas CAPEAM fails after checking only one cabinet.
- Figure 7 illustrates ViT corrector replacing infeasible planned actions like PickUp when the agent is poorly positioned, enabling successful manipulation.
- Multi-layered instance maps enable spatially precise, instance-aware search, improving localization under occlusion or clutter compared to coarse heatmap baselines.
Threat model
The paper's threat model concerns challenges from partial observability, ambiguous or incomplete natural language instructions, and noisy or occluded visual input within embodied environments that impede correct task execution. The agent faces no explicit adversarial attacks but must handle complex, dynamic scenes and irreversible environment state changes to avoid failure. The adversary is essentially environmental uncertainty and task complexity causing planning and execution errors.
Methodology — deep read
Threat Model and Assumptions: RePlan-Bot assumes an environment with partial observability, clutter, and dynamic state changes. The agent’s adversary is the complexity and ambiguity of real-world 3D tasks, including incomplete or ambiguous natural language instructions and imperfect perception (occlusions, sensor noise). There is no explicit adversarial attacker; failures arise from environment uncertainty and imperfect controls. The key threat is task execution failure due to misaligned planning, localization errors, or infeasible low-level actions.
Data: RePlan-Bot is trained and evaluated on the ALFRED benchmark, which contains 25,743 pairs of natural language instructions and demonstration trajectories in AI2-THOR simulated 3D households. The dataset covers seven task types involving multi-step navigation and manipulation under partial observability. The official splits include training, validation, and test sets, with test further partitioned into seen and unseen environments. The ViT-based low-level corrector is trained on visual observations relabeled from execution trajectories derived from these demonstrations. Details of processing instance segmentation, depth mapping, and pre-processing for semantic maps are in the appendix.
Architecture / Algorithm: RePlan-Bot has three integrated components:
- High-Level: A modular planner that generates initial sub-goal sequences from instructions using a template-based planner. An LLM-based auditor (a large language model with a custom prompt) then refines sub-goals pre-execution and dynamically during execution by grounding plans in observed objects and environmental feedback to fix missing or incorrect steps.
- Mid-Level: A commonsense-guided search mechanism builds a multi-layered instance map by integrating semantic segmentation, instance masks (via Mask R-CNN), depth, and vertical spatial voxelization. This layered map models object instances spatially, enabling the agent to sequentially explore candidate host object instances predicted by the LLM for occluded targets, rather than relying on coarse heatmap likelihoods.
- Low-Level: A lightweight vision transformer (ViT) receives the current egocentric RGB image and the low-level controller’s planned primitive action and outputs either the original action or a corrected alternative that is more feasible considering the visual scene. Actions include discrete navigation and manipulation primitives. The ViT corrector is trained as an action classifier on relabeled execution samples to predict safer alternatives preventing failures such as grasp misses or collisions.
Training Regime: The ViT corrector is trained on the constructed dataset of annotated RGB images paired with action labels and corrected alternatives. Specific hyperparameters (epochs, batch size) are not detailed but the training follows supervised classification with softmax over actions. The LLM auditor uses a frozen pre-trained large language model (exact model unspecified) prompted with three information streams: system message, agent message (instructions), and environment feedback. The network runs inference during execution for replanning.
Evaluation Protocol: Metrics: ALFRED’s official metrics including Success Rate (SR), Goal-Condition Success (GC), and path-length weighted variants (PLWSR, PLWGC) are reported. Evaluations are done on seen and unseen test splits. Both sparse task descriptions and full step-by-step instructions are tested. Baselines: Compared against recent state-of-the-art EIF models FILM, CAPEAM, LGS-RPA, Prompter, and ABP, using reproduced CAPEAM results and reported literature values for others. Ablations: Each component is removed in isolation to measure its contribution in both seen and unseen environments. Qualitative analysis: Specific task examples illustrate replanning in complex occlusion or misalignment cases.
Reproducibility: Full code and model checkpoints are not explicitly reported as released in this version. Detailed prompt structures and dataset construction methods are described in appendices. The ALFRED benchmark is publicly available, so replication is feasible with caveats on LLM auditor configuration and ViT training data.
Concrete Example End-to-End: Given a task 'Put the sponge in the bowl,' the modular planner might generate sub-goals including picking up the sponge. The LLM auditor, observing from the instance map that the sponge is inside a closed cabinet, amends the plan to open the cabinet before pickup. The mid-level search then sequentially visits candidate cabinets as guided by the LLM’s predicted host (cabinet), consults the multi-layer instance map with instance IDs, and locates the sponge despite occlusion. During execution, the low-level ViT-based corrector monitors planned primitive actions such as PickUp and adjusts them when visual feedback indicates the agent is too far or obstructed, substituting safer navigation or rotation actions to successfully complete the pick operation. This example illustrates multi-level continuous replanning and visual feedback integration.
Technical innovations
- Integration of an LLM-auditor that dynamically revises high-level sub-goals using textual and environmental feedback for real-time adaptive planning.
- Development of a commonsense-guided mid-level search using a multi-layered instance map with vertical voxelization and instance-level differentiation enabling precise object localization in cluttered and occluded scenes.
- A lightweight ViT-based low-level corrector that assesses planned primitive actions via egocentric RGB input, proactively predicts failures, and outputs corrected actions to improve execution robustness.
- Continuous multi-level replanning mechanism combining symbolic reasoning, spatial mapping, and visual action correction throughout the task execution horizon.
Datasets
- ALFRED — 25,743 instruction-demonstration pairs — public benchmark in AI2-THOR simulated 3D household environments
Baselines vs proposed
- CAPEAM: Success Rate = 40.42% vs RePlan-Bot: 44.79% (Test Unseen, Task Description Only)
- CAPEAM: Goal-Condition Success = 54.17% vs RePlan-Bot: 57.02% (Test Unseen, Task Description Only)
- CAPEAM: Success Rate = 43.17% vs RePlan-Bot: 47.61% (Test Unseen, Task + Step-by-step Instructions)
- CAPEAM: Goal-Condition Success = 56.52% vs RePlan-Bot: 60.29% (Test Unseen, Task + Step-by-step Instructions)
- w/o High-Level Replanning: SR drops by up to 3.19%, GC by up to 2.40%
- w/o Mid-Level Searching: SR drops by up to 1.70%, GC by 0.31% (Test Unseen)
- w/o Low-Level Replanning: SR drops by 2.41%, GC drops by 1.94% (Test Unseen)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.25851.

Fig 1: Overview of the proposed RePlan-Bot. It consists of

Fig 2: The detailed pipeline of RePlan-Bot. At the high level, upon receiving natural-language commands, the Modular Planner
Fig 3 (page 1).

Fig 4 (page 1).

Fig 5 (page 1).

Fig 6 (page 1).
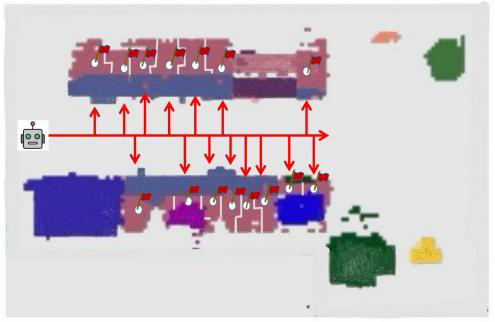
Fig 7 (page 1).

Fig 8 (page 1).
Limitations
- The evaluation is entirely in simulation (ALFRED/AI2-THOR) and does not test real-world robotic deployments, leaving the sim-to-real gap unaddressed.
- No adversarial attack or robustness testing against deliberate perturbations of perception or environment state is reported.
- The LLM auditor relies on prompt engineering and a particular language model whose choice and details are unspecified, potentially limiting reproducibility.
- Mid-level maps and search assume availability of accurate Mask R-CNN instance segmentation and depth data, which may degrade under real or noisy sensors.
- Low-level ViT corrector depends on curated training data with relabeled corrected actions; transferability to unseen visual domains needs further assessment.
- Computational overhead of continuous multi-level replanning with LLM calls and ViT inference may be significant, limiting real-time scalability.
Open questions / follow-ons
- How well does RePlan-Bot transfer from simulation to physical robotic platforms with real sensor noise and actuation uncertainty?
- Can the multi-level replanning framework adapt to adversarial or adversarially perturbed environmental conditions, e.g., occlusions or misleading visual cues?
- What are the efficiency trade-offs and latency impacts of integrating continuous LLM auditing and ViT-based correction on embedded or resource-limited systems?
- How does RePlan-Bot perform on other embodied AI benchmarks or tasks beyond ALFRED, including outdoor navigation or non-household manipulation?
Why it matters for bot defense
For bot-defense or CAPTCHA practitioners, RePlan-Bot’s approach illustrates the benefits of hierarchical, multi-level feedback and corrective mechanisms to improve agents’ robustness under complex and ambiguous instructions. The concept of integrating high-level language model auditing with mid-level spatial commonsense search and low-level perceptual action correction can inspire multi-component verification systems that detect and dynamically adjust for errors or adversarial conditions in real time. However, applying similar methods for bot-detection requires mapping these components to relevant modalities such as user interaction patterns, data provenance, or network observations.
The emphasis on continuous replanning and grounding symbolic plans with multi-layered spatial context has parallels in CAPTCHA design where challenge adaptivity and contextual awareness are critical. Also, the use of visual transformer modules to preemptively detect risky or impossible actions suggests opportunities to incorporate vision-based anomaly detection in automated challenge-response mechanisms. Overall, RePlan-Bot contributes valuable techniques for resilient reasoning and recovery in embodied agents that could analogously inform adaptive and layered defenses in interaction-based bot recognition systems.
Cite
@article{arxiv2605_25851,
title={ RePlan-Bot: Multi-Level Replanning for Embodied Instruction Following },
author={ Xicheng Gong and Guozheng Sun and Peiran Xu and Yadong Mu },
journal={arXiv preprint arXiv:2605.25851},
year={ 2026 },
url={https://arxiv.org/abs/2605.25851}
}