
MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
Source: arXiv:2605.26114 · Published 2026-05-25 · By Dingbang Wu, Rui Hao, Haiyang Wang, Shuzhe Wu, Han Xiao, Zhenghong Li et al.
TL;DR
MobileGym addresses a critical gap in mobile GUI agent research: the lack of a lightweight, scalable, and verifiable simulation environment for everyday mobile apps. Existing emulator-based or real-device setups either lack scalability, determinism in evaluation, or coverage of natural everyday apps due to backend dependencies and resource demands. MobileGym introduces a browser-hosted Android-like simulation environment with fully structured and manipulable JSON state that supports exact snapshotting, resetting, and deterministic task judging. This enables verifiable outcome signals and massively parallel online reinforcement learning (RL) rollouts on a single server, overcoming the limitations of heavyweight emulator or physical-device solutions.
The accompanying MobileGym-Bench contains 416 parameterized task templates across 28 simulated apps, supporting broad task diversity with clear orthogonal difficulty strata. The environment’s layered state model and declarative navigation specification simplify environment programming and scalable task definition. Empirical results show substantial headroom for both proprietary and open-source models on these everyday mobile tasks and demonstrate generalization benefits from MobileGym training to real-device execution with 95.1% retention of simulation PG improvements. The platform thus enables reproducible, scalable training and evaluation of mobile GUI agents without real-user or backend dependencies.
Overall, MobileGym innovates by uniquely combining interaction fidelity (not backend replication), fully programmable and verifiable environment state, and efficient browser-based parallelism. It provides a foundation for progress on mobile GUI agent development and sim-to-real transfer that was previously infeasible at scale.
Key findings
- MobileGym instances use ~400 MB RAM and cold-start in ~3 seconds, allowing hundreds of parallel rollouts on a single server, vastly more efficient than emulator-based environments requiring multiple GBs per instance.
- MobileGym-Bench contains 416 parameterized task templates (256 test + 160 train) over 28 everyday apps, with a difficulty stratification into L1–L4 levels, calibrated via reference-model success rates.
- Success rates (SR) on the 256-task test set vary widely, from 9.4% (Qwen3-VL-4B-Instruct) to 58.8% (Gemini 3.1 Pro), demonstrating a 6× performance spread and room for improvement.
- Unexpected Side Effects (USE), where agents cause unintended state mutations, vary from 4.7% to 14.5% across models, exposing off-target errors undetectable by screenshot-based judges.
- GRPO training on the 160-task train set lifts the 256-task test SR from 9.4% to 22.2% (+12.8 points) for Qwen3-VL-4B-Instruct, with largest gains at moderate difficulty levels (L2).
- Sim-to-real transfer evaluation on a 59-task signal subset shows real-device success rate improves from 32.2% to 72.9% (+40.7 points) after training, retaining 95.1% of the simulated gain.
- Sim and real-device successful trajectories have similar lengths (e.g., base model operate tasks: 5.00 sim vs 6.03 real steps), indicating behavioral consistency across sim-to-real boundary.
- Visual language model (VLM) judges show a 10.2% misjudgment rate on real-device trajectories, highlighting the advantage of MobileGym's state-based deterministic judging.
Threat model
MobileGym assumes a benign research-user adversary focused on reproducible evaluation and training of mobile GUI agents. It does not consider malicious attackers aiming to compromise the environment, escape sandboxing, or manipulate backend services. Agents observe only screenshots and produce discrete GUI actions. The environment prevents irreversible real-world consequences by sandboxing all state in browser-hosted, simulated JSON without access to live accounts or services.
Methodology — deep read
Threat Model & Assumptions: The environment assumes an adversary is a benign research user evaluating or training mobile GUI agents. It does not consider malicious adversaries attempting to exploit or subvert the simulation. Agents only observe screenshots and output discrete GUI actions (tap, swipe, type, etc.). The system prevents irreversible state changes affecting real accounts or devices by sandboxing all operations in browser-hosted simulated state.
Data: MobileGym simulates 28 apps commonly used in everyday mobile scenarios, covering messaging, ticketing, file management, gallery, settings, and more. The benchmark contains 416 parameterized task templates divided into 160 training and 256 testing templates. Tasks vary across four orthogonal axes (scope, objective, composition, difficulty), instantiated by randomized sampling of instructions, environment configurations, and parameter values leading to over 27,000 distinct instances. Evaluation uses pre-defined step budgets per task (15–60 steps) with extra steps for tasks requiring AnswerSheet form filling.
Architecture / Algorithm: MobileGym represents the app and OS runtime state fully as layered structured JSON—split into immutable world data (e.g., contacts, posts), a mutable per-environment runtime overlay capturing agent interactions, and core OS runtime state. GUI screens are rendered by compositing these layers with a browser-hosted Android-like UI and interaction stack (notification shade, keyboard, back gestures, task stack). App navigation is defined declaratively as finite state machines driving programmatic state transitions. A unified 17-action interface maps agent outputs to Playwright action executions. Critical components include deterministic, state-based judging over full environment diffs, snapshotting/reset/forking functionality enabling parallel rollouts and reproducibility, and the AnswerSheet structured answer protocol replacing free-text answer judging.
Training Regime: As a concrete example, Qwen3-VL-4B-Instruct was fine-tuned with GRPO on MobileGym-Bench's 160 training tasks for 10 steps using a single node with 3 RTX 6000 GPUs, 96 parallel environments, batch size 12, learning rate 1e-6, group size 8, KL constraint 0.01, and DAPO-style asymmetric clipping. Rewards combined progress-shaped dense signals with multiplicative penalties for AnswerSheet errors, side effects, false completions, and overdue execution.
Evaluation Protocol: Agents are evaluated on the 256 test tasks with metrics including Success Rate (SR), Progress Rate (PR), False Completes (FC), Unexpected Side Effects (USE), and Overdue Terminations (OT). Four difficulty strata (L1–L4) are defined post hoc via reference model pass rates to stratify results. Multiple trials per model re-sample parameters to compute means and stddevs. Sim-to-real transfer used a Redmi Note 12 Turbo device to run a 59-task subset stratified by simulation pass signals; trajectories were audited manually to assess judging errors.
Reproducibility: The paper references extensive appendices detailing implementation, benchmarks, and evaluation protocols. MobileGym is open source with benchmark tasks released, but real-device datasets remain partial due to live account constraints. Frozen weights for proprietary models are unavailable, but open-source agent runs are reproducible.
End-to-end example: A train-ticket booking task is instantiated by parameterizing origin/destination and passenger names; the JSON environment state is patched accordingly. The agent observes rendered screenshots and executes actions navigating through app UI modules, whose transitions update the structured state. The deterministic judge compares final environment state diffs to the expected changes, e.g., ticket status 'created', verifying no unintended side effects such as rogue messages. Parallel rollouts fork from identical snapshots, enabling scalable policy gradient RL training. The AnswerSheet form submission encodes query answers precisely, allowing robust evaluation without heuristics.
Technical innovations
- A layered state representation combining immutable world data with mutable runtime overlays enables exact snapshotting, reset, fork, and deterministic state-diff judging for mobile apps.
- A browser-hosted lightweight Android-like simulation environment using structured JSON states achieves ~10× lower memory usage than emulator-based solutions, supporting hundreds of parallel instances on a single server.
- The declarative finite-state machine specification of app navigation allows scalable, programmatic task definition and automated task-trajectory generation.
- The AnswerSheet protocol replaces brittle free-text answer matching by typed GUI form filling with type-specific matchers, eliminating false positives and negatives in query task evaluation.
Datasets
- MobileGym-Bench — 416 parameterized task templates over 28 simulated apps — publicly hosted via MobileGym
- Sim-to-Real signal subset — 59 tasks drawn from test set — private real-device execution data on Redmi Note 12 Turbo
Baselines vs proposed
- Gemini 3.1 Pro: Success Rate = 58.8% vs Qwen3-VL-4B-Instruct base: 9.4% on 256-task MobileGym-Bench test set
- Qwen3-VL-4B-Instruct base: Success Rate = 9.4% vs trained with GRPO: 22.2% (+12.8 pt gain) on 256-task test set
- Qwen3.6-Plus VLM judge error rate = 10.2% vs MobileGym programmatic judge error = 0%
- Simulated test set trained SR increase: +12.8 pt vs real-device 59-task subset SR increase: +40.7 pt with 95.1% gain retention
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.26114.
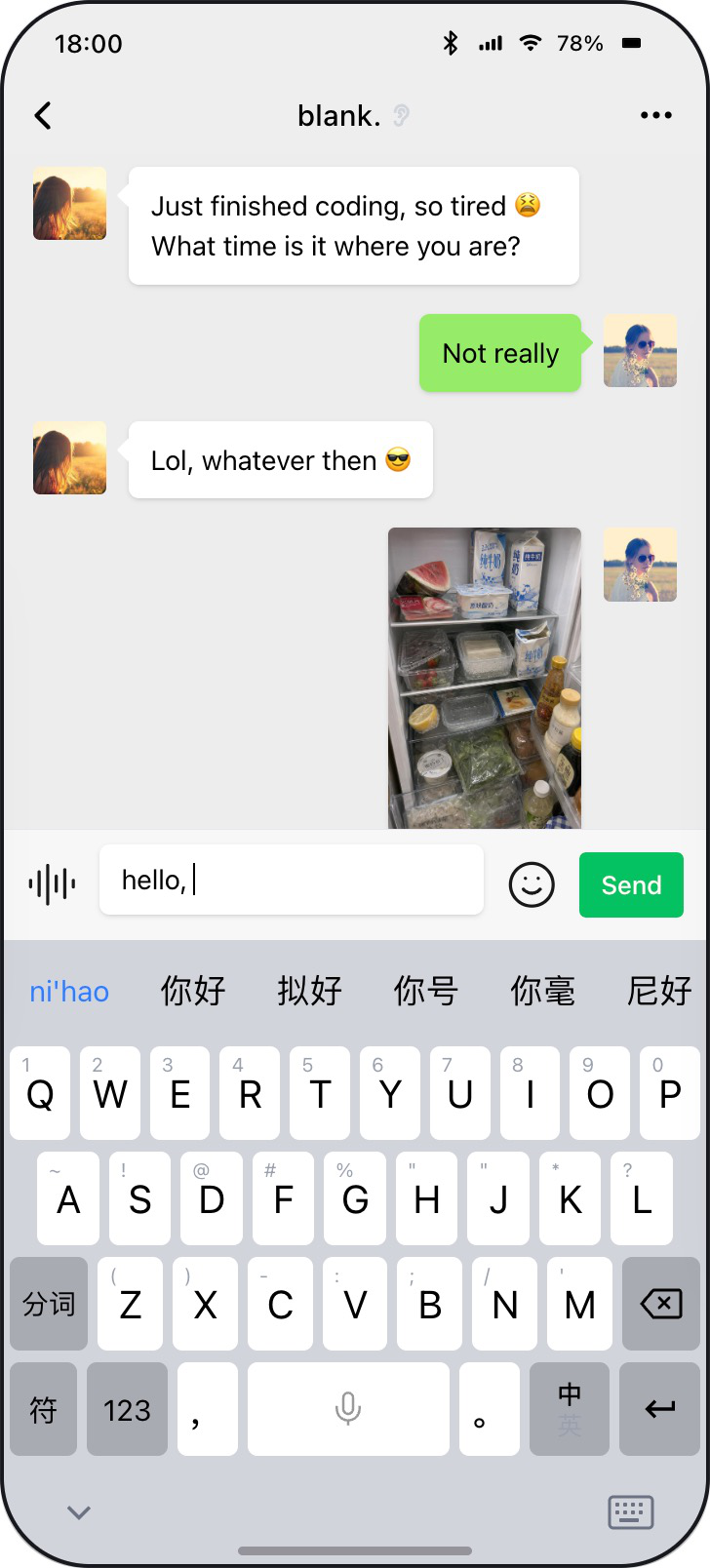
Fig 1: Example screens from MOBILEGYM. An-
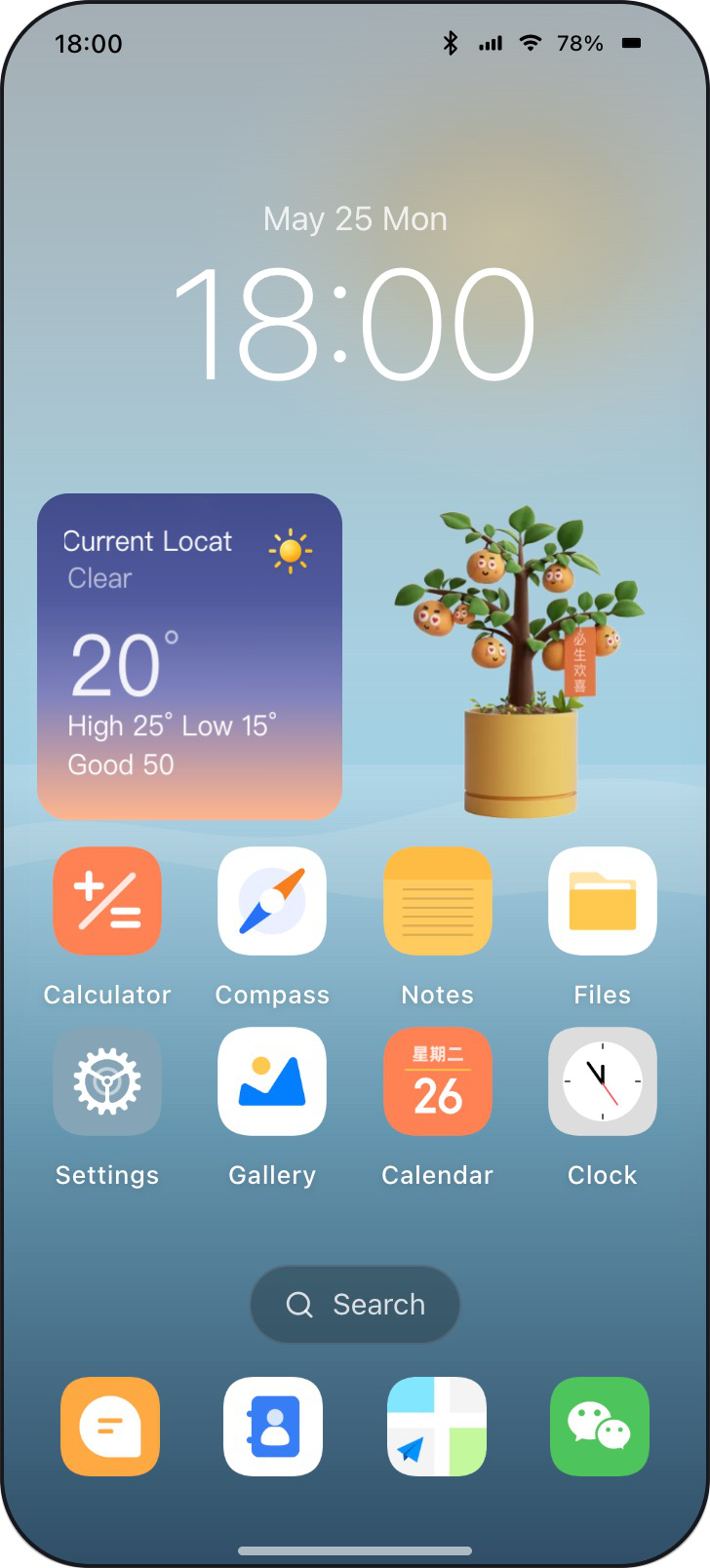
Fig 2: End-to-end workflow of MOBILEGYM. A structured state supports task instantiation, parallel rollout
Fig 3 (page 2).
Fig 4 (page 2).
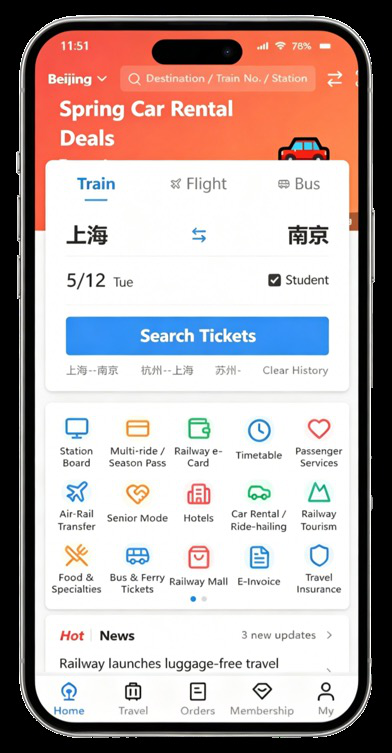
Fig 5 (page 2).
Fig 6 (page 2).
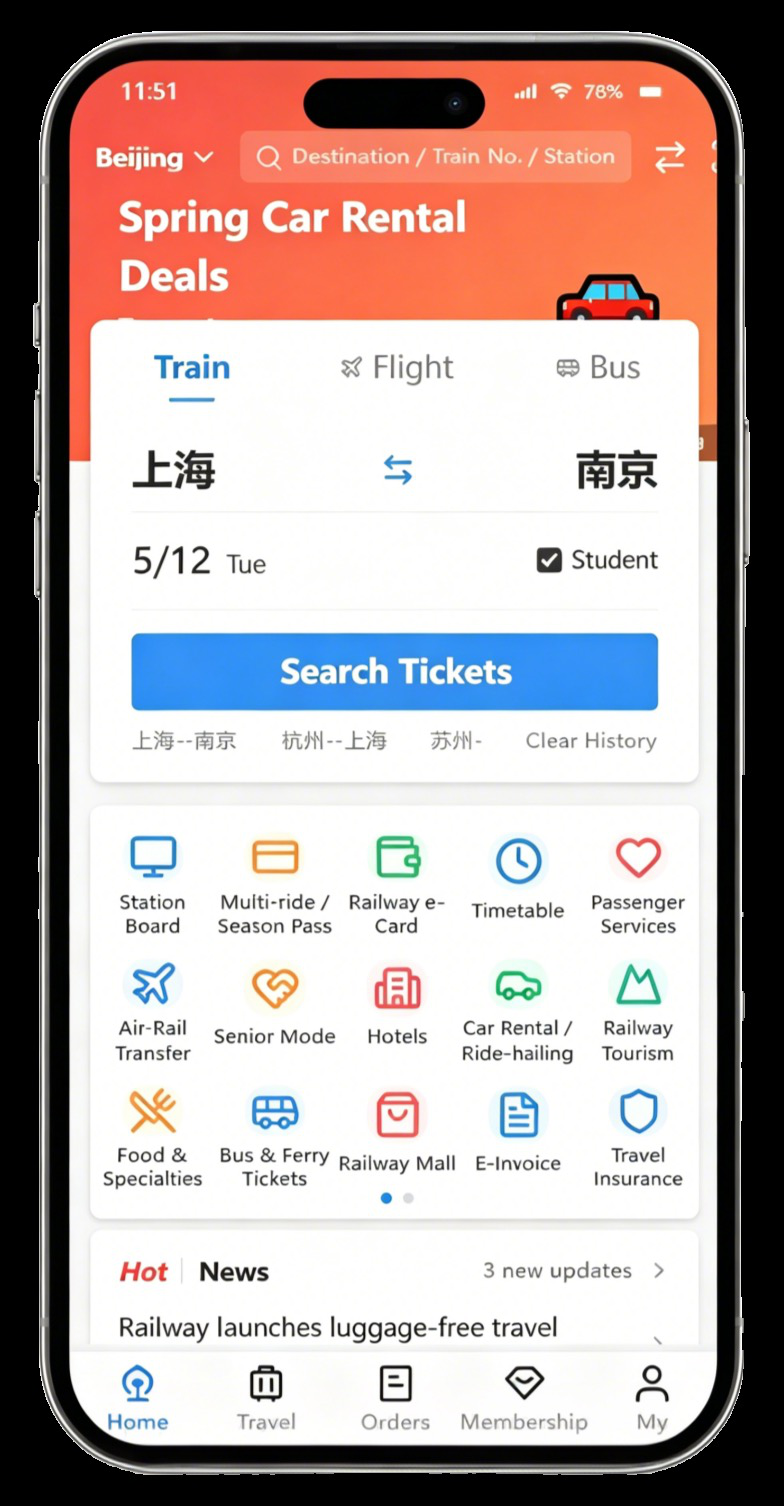
Fig 3: System capabilities and state model of MOBILEGYM. App views are produced by composing read-
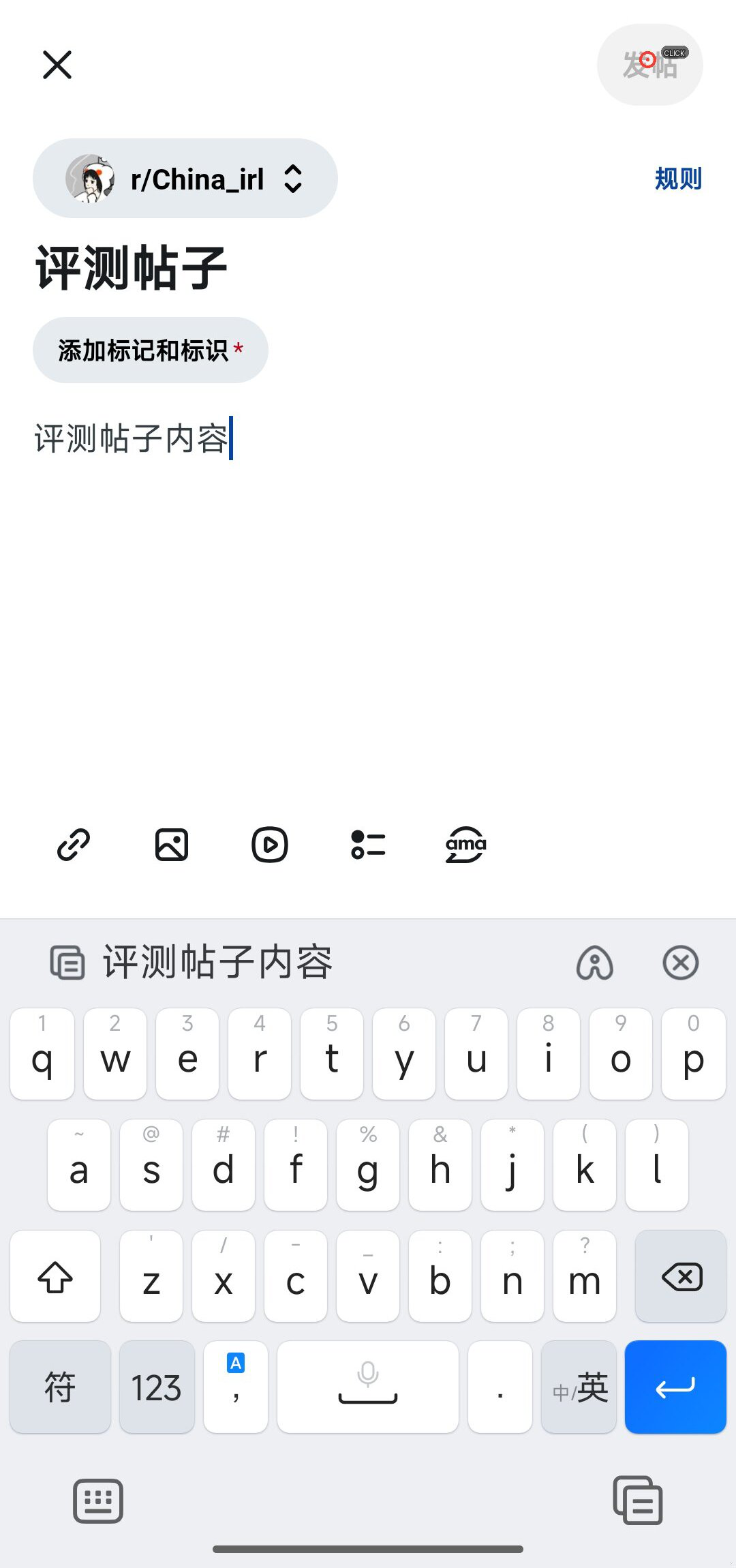
Fig 6: Sim-to-Real OOD generalization on Reddit_CreatePostToCommunity. The real-device r/China_irl
Limitations
- MobileGym simulates interaction surfaces but does not replicate pixel-perfect visual appearance or proprietary backend logic, affecting transfer on tasks reliant on precise iconography or dynamic content.
- Backend phenomena like live recommendation updates, fraud detection, latency spikes, or server-side policy changes are not modeled unless explicitly introduced as controllable state.
- Simulated apps implement main everyday-use scenarios but do not cover full feature sets, possibly missing edge cases or obscure workflows.
- Sim-to-real validation was performed on a limited real-device subset (59 tasks) and a single device model, limiting statistical generalization across app versions or hardware.
- VLM judge comparisons suggest current vision-language models are insufficiently reliable for evaluation in this domain, but MobileGym’s programmatic judging requires target task state formalization not always available.
- Online RL training was demonstrated on a moderate scale (10 steps of GRPO), leaving longer or more diverse training regimes unexplored.
Open questions / follow-ons
- How can MobileGym be extended to model backend-driven stochastic dynamics such as live recommendations or fraud detection to better simulate real-world variability?
- Can the simulated apps be expanded further to cover broader feature sets and corner cases, particularly in deeply nested or rare workflows?
- What are the limits of sim-to-real transferability across diverse mobile devices, OS versions, and app updates?
- How can safety-alignment and robustness testing frameworks be integrated with MobileGym's deterministic state-based judging?
Why it matters for bot defense
MobileGym provides a directly applicable platform for bot-defense and CAPTCHA researchers focused on mobile device agent interactions and automation detection. Its deterministic state modeling and verification mechanisms can help develop more reliable evaluation metrics beyond screenshot-based heuristics, which are prone to adversarial manipulation or error. The scalable parallel rollout capability facilitates large-scale RL training that could, for example, improve bot-behavior modeling or interactive CAPTCHA solving strategies.
Furthermore, the structured environment and AnswerSheet protocol demonstrate how replacing free-text or visual matching with typed, programmatic state checks can enhance robustness and reduce false positives/negatives in automated human verification tasks. Its sim-to-real validated environment means defenses or detection algorithms developed on MobileGym are more likely to generalize to real-device contexts. Overall, MobileGym represents an important methodological advance for mechanically verifying agent behaviors on mobile platforms under scalable, controlled conditions.
Cite
@article{arxiv2605_26114,
title={ MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research },
author={ Dingbang Wu and Rui Hao and Haiyang Wang and Shuzhe Wu and Han Xiao and Zhenghong Li and Bojiang Zhou and Zheng Ju and Zichen Liu and Lue Fan and Zhaoxiang Zhang },
journal={arXiv preprint arXiv:2605.26114},
year={ 2026 },
url={https://arxiv.org/abs/2605.26114}
}