
CUA-Gym: Scaling Verifiable Training Environments and Tasks for Computer-Use Agents
Source: arXiv:2605.25624 · Published 2026-05-25 · By Bowen Wang, Dunjie Lu, Junli Wang, Tianyi Bai, Shixuan Liu, Zhipeng Zhang et al.
TL;DR
This paper addresses the critical bottleneck of scalable, verifiable training data for Reinforcement Learning with Verifiable Rewards (RLVR) applied to computer-use agents (CUAs). Unlike domains with straightforward problem/answer pairs, CUAs require consistent triplets of task instructions, executable environment states, and deterministic reward functions, which have been costly and slow to produce. The authors introduce CUA-GYM, an agentic pipeline that synergistically co-generates these triplets via adversarially coupled Generator and Discriminator agents orchestrated to iteratively refine task setups and reward functions. This approach ensures internal consistency and enables programmatic verification, mitigating reward hacking and ambiguity. Additionally, they synthesize CUA-GYM-HUB, a large suite of mock web applications reflecting real software usage, dramatically increasing environment diversity.
Using this pipeline, the authors construct CUA-GYM, a dataset of 32,112 verified RLVR tuples spanning 110 environments. Training RL policies with GSPO on this data yields significant improvements over strong open-source baselines, including +7.6 and +10.4 percentage points absolute gains on OSWorld-Verified for models with 35B and 397B parameters, respectively. Performance also transfers positively to held-out benchmarks like WebArena, demonstrating generalization beyond synthesized mocks. The work establishes environment diversity as an important new scaling axis complementary to data volume, and uncovers emergent multi-action tool calls compressing trajectories by up to 45%. The full pipeline, models, dataset, and environment suite are open-sourced to foster reproducible research.
Key findings
- CUA-GYM dataset contains 32,112 verified RLVR training tuples across 110 environments, including 94 mock web apps and 16 desktop apps.
- Training Qwen3.5-35B-A3B with GSPO on CUA-GYM improves OSWorld-Verified success rate from 54.5% to 62.1% (+7.6 pp).
- Training Qwen3.5-397B-A17B on CUA-GYM lifts OSWorld-Verified from 62.2% to 72.6% (+10.4 pp).
- CUA-GYM trained agents also improve on held-out WebArena benchmark by +3.7 pp for A3B and +2.0 pp for A17B.
- Increasing environment diversity (from 10 to 80 envs) at fixed trajectory count improves performance by around 3 percentage points on OSWorld-Verified.
- Doubling trajectory volume on the 80 environment pool yields a substantially larger improvement than environment diversity alone.
- RL training induces spontaneous multi-action tool calls per step, increasing from ~1.0 to stable 1.4–1.9 range, compressing trajectory lengths by 33–45% without performance loss.
- CUA-GYM combines programmatic reward verification with broad environment coverage uniquely among open RLVR datasets.
Threat model
The threat model assumes a reward hacker adversary who could manipulate the reward function if it had access to environment setup details. To counter this, the pipeline enforces strict information barriers between the Generator agent (which creates environment states) and the Discriminator agent (which writes the reward function), so the reward function must base verification solely on the task and resulting environment states. This prevents reward hacking that relies on re-checking the construction procedure rather than genuine task completion.
Methodology — deep read
Threat Model & Assumptions: The adversary is a potential reward hacker who might exploit reward function designs if the reward construction is not isolated from environment setup. The pipeline enforces strict information isolation between the Generator (environment setup) and Discriminator (reward function) agents to prevent reward cheating. It assumes access to stable simulated environments that can be reset programmatically, which the synthesized web mocks provide.
Data Provenance & Preprocessing: CUA-GYM data consists of tuples (t, s, r) where t is a natural-language instruction with grounded context, s is an initial reproducible environment state, and r is a programmatic reward function yielding scores in [0,1]. Task contexts come from a combination of web research, software documentation, and prepared assets to ensure realism and coverage. 32,112 verified tuples span 110 environments, including 94 synthesized mock web applications (CUA-GYM-HUB) and 16 desktop applications.
Architecture / Algorithm: The data synthesis pipeline deploys three specialized agents coordinated by an Orchestrator: the Generator creates initial_setup.py and golden_patch.py scripts that produce initial and golden environment states; the Discriminator, isolated from Generator's workspace, composes reward.py from the task description and resulting environments. They iteratively exchange feedback and improve scripts until the reward function cleanly distinguishes initial vs golden states under execution checks and satisfies agreement criteria.
A final filter applies LLM majority voting on tuple quality metrics (consistency, clarity, hack-risk) and teacher-model rollout verification ensuring tasks are solvable and rewards trace task success.
For environment scaling, a multi-agent pipeline synthesizes CUA-GYM-HUB's mock single-page web applications from occupational taxonomies and software usage distributions. A Plan Agent drafts specs; a Dev Agent codes; a Web Agent exercise tests via Playwright, looping till verification convergence. The mock apps expose unified HTTP APIs enabling task-specific state injection, session isolation, and programmatic reset to create diverse, reusable, fully controllable training environments.
Training Regime: Models are fine-tuned from SFT-initialized Qwen3.5-35B-A3B and Qwen3.5-397B-A17B base backbones using Group Sequence Policy Optimization (GSPO), a stable RL algorithm designed for mixture-of-experts setups. Trajectories include multimodal inputs (screenshots + actions). Long-horizon interactions use a trajectory slicing scaffold that keeps recent observations full-resolution and older states as compact placeholders, preserving late-step supervision and enabling efficient training.
Evaluation Protocol: Performance is evaluated on OSWorld-Verified, a benchmark dataset with 369 and 360 tasks for A3B and A17B models respectively, measuring task success rate. Per-domain success breakdowns are reported (e.g., multi-app workflows +21.5 pp lift, libreoffice_calc +14.9 pp). Held-out generalization is measured on the WebArena browser benchmark with site clones disjoint from training mocks. Ablations on environment diversity vs trajectory volume use teacher-model distillation fine-tuning for efficiency.
Reproducibility: The paper commits to open-sourcing all artifacts including the synthesis pipeline, dataset, CUA-GYM-HUB environments, and trained models. Codes and datasets are publicly available through Github and Huggingface. Experimental setups and hyperparameters are detailed in the appendix.
Concrete Example: Given a task 'Send emails to clients listed on Notion page using template via Gmail with attached spreadsheet data', the Generator writes environment setup scripts molding initial and golden states reflecting email content and recipients. Discriminator drafts a reward function decomposing criteria like presence of sent emails, content match, and recipient correctness, isolated from Generator's scripts. Orchestrator runs iterative rounds until the reward function cleanly separates golden from initial states. The tuple passes through majority vote and teacher rollout filters before inclusion in CUA-GYM.
Technical innovations
- Adversarially coupled Generator and Discriminator agents with strict information isolation co-generate environment setups and reward functions, mitigating reward hacking in RLVR data for CUAs.
- Multi-agent pipeline for synthesizing diverse, high-fidelity mock web applications (CUA-GYM-HUB) grounded in occupational taxonomies and real-world software usage, enabling large-scale environment diversity for RL.
- Use of an orchestrator and an iterative loop that runs Generator and Discriminator agents producing scripts and rewards until agreement conditions are met, ensuring internal tuple consistency.
- A final data filter combining LLM majority voting on tuple quality with teacher-model rollout verification that ensures task solvability and reward validity beyond loop-level checks.
- Long-horizon trajectory slicing scaffold preserving late-horizon supervision and enabling efficient RL training on multimodal GUI interaction data with overlapping context prefixes.
Datasets
- CUA-GYM — 32,112 verified tuples — public via Huggingface
- CUA-GYM-HUB — 94 mock web applications — public via Github
- OSWorld-Verified — ~360 tasks — evaluation benchmark (not fully public)
- WebArena — held-out browser benchmark — public
Baselines vs proposed
- Qwen3.5-35B-A3B base: OSWorld-Verified = 54.5% vs CUA-GYM-A3B: 62.1% (+7.6 pp)
- Qwen3.5-397B-A17B base: OSWorld-Verified = 62.2% vs CUA-GYM-A17B: 72.6% (+10.4 pp)
- Qwen3.5-35B-A3B base: WebArena = 40.8% vs CUA-GYM-A3B: 44.5% (+3.7 pp)
- Qwen3.5-397B-A17B base: WebArena = 54.0% vs CUA-GYM-A17B: 56.0% (+2.0 pp)
- Environment scaling: at fixed 3K trajectories, increasing envs from 10 to 80 improves OSWorld-Verified from ~53% to ~56%
- Trajectory scaling: doubling trajectories on 80 envs improves OSWorld-Verified by about 5 percentage points
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.25624.

Fig 1: Overview of the CUA-GYM data synthesis pipeline. From a task instruction and its grounded

Fig 2 (page 1).

Fig 2: Multi-agent pipeline for mock environment synthesis. From a target application seed, the

Fig 3: State-injected environments in CUA-GYM-HUB. The same mail mock can be instantiated with
Fig 4: Training scaffold for long-horizon CUA trajectories. Instead of training on a single sliding
Fig 6 (page 3).
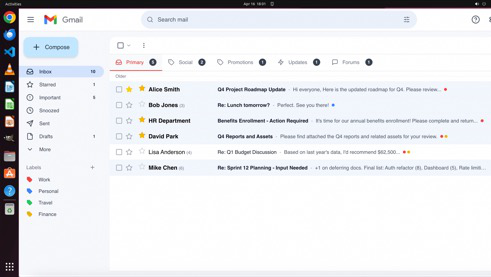
Fig 7 (page 3).
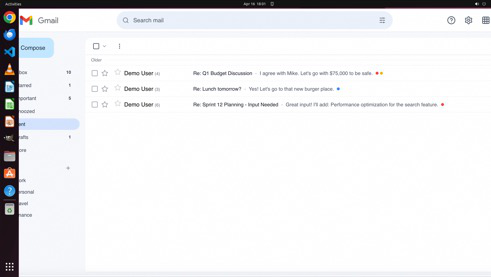
Fig 8 (page 3).
Limitations
- RL experiments focus on Qwen3.5 backbones; other architectures not evaluated so generalizability is untested.
- Environment scaling ablation uses teacher distillation rather than expensive RL retraining; may not capture all RL dynamics.
- Real-world complexity and robustness outside synthesized mock environments remain to be validated.
- Some tasks exhibit zero or negative gains (e.g., Thunderbird saw -13.3 pp for A17B), indicating uneven domain transfer.
- Reward functions validated via agent rollouts and LLM filtering, but no adversarial or human-in-the-loop attack testing reported.
- Synthesized mocks abstract real applications and may miss subtle UI or data interaction nuances affecting realism.
Open questions / follow-ons
- How well do CUA-GYM models generalize to fully realistic, uncontrolled environments beyond mocks and benchmarks?
- Can adversarial testing uncover reward-hacking vulnerabilities that bypass the Generator-Discriminator pipeline?
- How do alternative reward co-generation strategies compare in robustness and scalability?
- What is the impact of finer granularity in task difficulty or longer-horizon workflows on RLVR training with this pipeline?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, CUA-GYM demonstrates a scalable method to generate complex, verifiable task-reward training data for agents interacting with realistic computer-use environments. Its adversarial co-generation and strict information barriers offer a compelling approach to robust reward design that could inform constructing and verifying CAPTCHA-solving benchmarks or defenses. The environment scaling via mock web apps aligns well with simulating adversarial interactions over diverse, programmatic interfaces, enabling richer evaluation and training setups beyond static CAPTCHA challenges. The emergent multi-action batching behavior shows RL agents optimizing interaction efficiency, highlighting the importance of modeling multi-step exploits in bot-defense training.
Overall, the paper provides a reproducible framework that could be adapted or extended to build verified datasets for training and testing CAPTCHA and bot-defense systems against sophisticated agents. Its joint focus on task, environment, and reward fidelity addresses core challenges in scalable bot-defense evaluation. However, real-world robustness and adversarial resistance remain open, underlining the need for ongoing integration of security analyses with such training pipelines.
Cite
@article{arxiv2605_25624,
title={ CUA-Gym: Scaling Verifiable Training Environments and Tasks for Computer-Use Agents },
author={ Bowen Wang and Dunjie Lu and Junli Wang and Tianyi Bai and Shixuan Liu and Zhipeng Zhang and Haiquan Wang and Hao Hu and Tianbao Xie and Shuai Bai and Dayiheng Liu and Que Shen and Junyang Lin and Tao Yu },
journal={arXiv preprint arXiv:2605.25624},
year={ 2026 },
url={https://arxiv.org/abs/2605.25624}
}