
AgentHijack: Benchmarking Computer Use Agent Robustness to Common Environment Corruptions
Source: arXiv:2605.25707 · Published 2026-05-25 · By Jingwei Sun, Jianing Zhu, Yuanyi Li, Tongliang Liu, Xia HU, Bo Han
TL;DR
This paper addresses the robustness challenge faced by autonomous computer-use agents powered by multimodal large language models (MLLMs) operating in real-world desktop environments. While such agents have demonstrated success in clean settings, real-world execution is frequently disrupted by common, non-adversarial corruptions such as pop-ups, resolution changes, overlapping apps, accidental clicks, or network errors. These disruptions degrade agent perception and control, causing failures or meaningless repeated attempts. To systematically study this, the authors introduce AgentHijack — a benchmark specifically designed to evaluate agent robustness against 9 configurable common environmental corruptions under realistic, dynamic conditions. They apply these corruptions to the OSWorld benchmark tasks, totaling 3,321 tasks, and evaluate multiple state-of-the-art MLLM-based agents. The results reveal severe performance degradation even with mild corruption, highlighting that current agents lack robustness to realistic disruptions.
Building on these insights, the paper proposes AgentHijack-Agent, a novel agent framework that combines an action generator with enhanced grounding, trained using Data-Augmented Group Relative Policy Optimization (DA-GRPO) across corrupted environments, and an onlooker module that continuously summarizes agent behavior and monitors environment state to detect initialization errors and unexpected environmental changes. This dual-component design enables the agent to maintain more stable grounding, better recover from errors, and avoid futile attempts in corrupted execution. Experiments demonstrate that AgentHijack-Agent consistently improves robustness over baselines across all 9 corruption types and varying intensities, representing a significant step toward deployable, corruption-resilient computer-use agents.
Key findings
- AgentHijack benchmark consists of 9 common corruptions including Pop Ups, Resolution Change, Marks, Subtitle, Multi Apps, Accidental Touch, App Minimization, Network Error, and Verification, applied to OSWorld tasks for a total of 3,321 evaluation tasks.
- State-of-the-art MLLM agents UI-TARS-7B-DPO and UI-TARS-1.5-7B suffer large relative performance declines under corruptions, from 3.72% to 57.54% degradation depending on corruption type (Fig 1).
- Corruption types like Verification and Pop Ups cause the most severe performance drops, exceeding 50% relative decline.
- Agents struggle with unstable grounding in presence of visual disruptors, tend to misattribute environmental changes caused by unexpected operations, and fail to detect environmental initialization errors, leading to persistent meaningless attempts (Fig 2).
- Proposed AgentHijack-Agent integrates an action generator with enhanced grounding trained by DA-GRPO on multiple corrupted environments and an onlooker agent that summarizes behavior and checks for environmental errors before and during execution.
- DA-GRPO optimizes policy by aggregating rollouts across corrupted environments and applying group-normalized advantage for stability and robustness.
- AgentHijack-Agent achieves universal robustness improvements, reducing meaningless attempts and improving task success across all tested corruption types and variants, with statistically significant gains over state-of-the-art baselines (Section 5).
- The benchmark supports configurable corruption content, size, and intensity parameters that allow flexible robustness evaluation under diverse realistic perturbations.
Threat model
The threat model assumes a non-malicious but dynamic and imperfect environment that introduces common corruptions disrupting agent perception and control. The adversary is environmental noise such as pop-ups, accidental touches, resolution changes, or network errors causing perturbations to observations, transitions, or environment states. However, the adversary neither actively targets the agent with hostile or deceptive attacks nor alters task goals. The agent must still complete its original task under these corrupted, uncertain conditions.
Methodology — deep read
The paper begins by framing computer-use agents as operating within a partially observable Markov decision process (POMDP), where state S, observations O (e.g., screenshots), action space A (click, type, hotkey), and transition dynamics T define the task execution environment. Agents aim to maximize a reward function that assigns a success score (0 or 1) after interacting for a maximum number of steps or reaching a termination flag.
Threat Model & Assumptions: The adversary is environmental corruption without direct adversarial intent. Corruptions represent common but unavoidable dynamic disruptions (pop-ups, accidental touches, network errors). There is no intentional, malicious attack or task manipulation. The agent observes corrupted states and must still complete the original task.
Data & Benchmark: AgentHijack corrupts the OSWorld benchmark task set (originally 369 tasks) by injecting 9 configurable corruption types. This expands evaluation to 3,321 corrupted tasks. Each corruption simulates realistic visual disruptors, unexpected operations, or environment errors and comes with configurable parameters (e.g., popup content/size, steps of accidental touches). This allows large-scale systematic evaluation.
Architecture / Algorithm: The proposed AgentHijack-Agent contains two components:
- Action Generator: A policy modeled on UI-TARS-1.5-7B with Qwen-2.5-VL architecture, enhanced with grounding capabilities for robust interactions.
- Onlooker: An auxiliary agent that continuously observes execution behavior and environmental state transitions. It summarizes dynamic changes into concise behavior summaries integrated into the action generator’s input context. It also runs an initial environment validation to detect initialization errors before execution.
Training Regime: The action generator is trained using Data-Augmented Group Relative Policy Optimization (DA-GRPO), an extension of Group Relative Policy Optimization (GRPO). DA-GRPO optimizes policies simultaneously over rollouts across multiple corrupted environments by normalizing advantages within each corruption group. This encourages consistent performance and robustness across corruptions. They use experience replay buffers to preserve and reuse rare successful trajectories amid sparse rewards. Hyperparameters, epochs and hardware details are provided in sections referenced in the appendix.
Evaluation Protocol: The benchmark evaluates task success rates under each corruption and intensity variant, comparing baseline MLLM agents and the proposed AgentHijack-Agent. They report relative decline rates versus clean environments, number of meaningless attempts, grounding accuracy metrics, and ablations for individual modules (onlooker, DA-GRPO). Statistical significance is analyzed where applicable. The evaluation spans 3,321 tasks enabling robust conclusions.
Reproducibility: The code, environment, baseline models, data, and corruption configurations are publicly available at https://AgentHijack.github.io. Exact seeds, splits, and YAML configurations for corruption generation are included, enhancing reproducibility.
Concrete example: For a task to create and save a new Python file in VSCode, the benchmark injects a popup dialog corruption during execution. The baseline agent mistakenly clicks on popup buttons, loses grounding on the target window, or attempts failures repeatedly. The onlooker notices the popup and summarizes environment changes, informing the action generator. DA-GRPO training enables the action generator to adapt behavior across corrupted rollouts, leading AgentHijack-Agent to correctly close popups and complete the file creation task with fewer errors and higher success rates.
Technical innovations
- AgentHijack benchmark introduces 9 realistic, configurable common environment corruptions applied to a comprehensive set of 3,321 OSWorld tasks for corruption robustness evaluation.
- Data-Augmented Group Relative Policy Optimization (DA-GRPO) extends GRPO by aggregating policy optimization across multiple corrupted environments with group-normalized advantages to enhance robustness.
- Introduction of an onlooker module that provides continuous behavioral summarization and environment error checking to support robust decision-making and avoid meaningless agent attempts in corrupted states.
- A unified agent framework (AgentHijack-Agent) that integrates enhanced grounding in the action generator with the onlooker’s auxiliary perspective for improved agent resilience against common but non-adversarial corruptions.
Datasets
- AgentHijack: 3,321 tasks derived from OSWorld with 9 configurable common environment corruptions applied; original OSWorld dataset has 369 tasks.
Baselines vs proposed
- UI-TARS-7B-DPO: Relative performance decline up to 57.54% vs AgentHijack-Agent: substantially reduced degradation across all 9 corruption types (Fig 1).
- UI-TARS-1.5-7B: Up to 56.71% relative decline in presence of common corruptions vs AgentHijack-Agent: consistent improvement with fewer meaningless attempts and better grounding recall.
- Baseline MLLM agents: exhibit frequent meaningless attempts and poor error detection vs AgentHijack-Agent: lowers meaningless attempts by a large margin and successfully detects environment initialization errors (Section 5).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.25707.
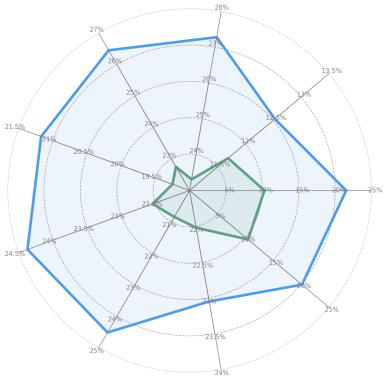
Fig 1: AgentHijack: benchmark robustness of computer use agents in corrupted scenarios. Agenthijack can generate configurable
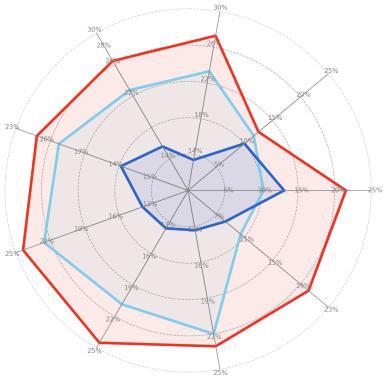
Fig 2: Case study of various corruptions in AgentHijack. UI-TARS-1.5-7B exhibits deviations in its grounding capability when

Fig 3 (page 3).

Fig 4 (page 3).

Fig 5 (page 3).

Fig 6 (page 3).
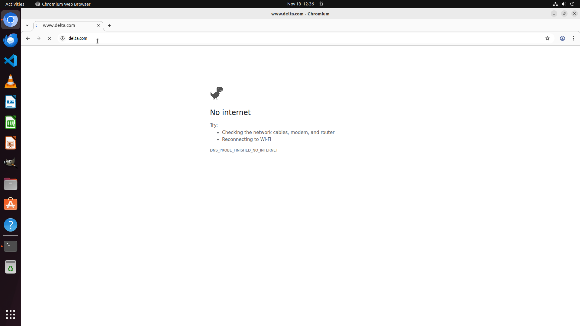
Fig 3: The pipeline of AgentHijack-Agent. The onlooker detects the presence of environmental errors prior to execution to ensure the
Fig 8 (page 4).
Limitations
- The benchmark focuses on common non-adversarial corruptions but does not evaluate resilience to fully adversarial attacks or intentional adversarial manipulations.
- Evaluation is conducted primarily on simulated virtual machines and OSWorld tasks; real-world physical device tests remain unexplored.
- The study primarily considers English-language GUI environments; applicability to other languages/localizations is not tested.
- While onlooker and DA-GRPO show improved robustness, the framework’s computational cost and runtime overhead are not fully characterized.
- Agent robustness to unexpected large distribution shifts beyond the defined corruption types has not been examined.
- The reliance on experience replay buffers to deal with sparse rewards may limit scaling in environments with rarer successful trajectories.
Open questions / follow-ons
- How can corruption robustness techniques generalize to fully adversarial manipulation or prompt injection attacks beyond common environmental corruptions?
- Can the onlooker design be extended to enable active intervention or environment repair rather than passive monitoring and summarization?
- What are the trade-offs in computational cost and latency introduced by the onlooker and DA-GRPO training in real-time, resource-constrained agent deployment?
- How well do corruption-robust agents trained on simulated benchmarks transfer to physical devices and real-world GUI systems with different layouts, languages, and noise characteristics?
Why it matters for bot defense
For bot-defense and CAPTCHA researchers, AgentHijack highlights critical vulnerabilities of multimodal LLM-powered agents to realistic non-adversarial environmental corruptions. While most bot defenses focus on outright adversarial manipulations, this work demonstrates that common dynamic disruptions—like pop-ups or accidental touches—can seriously degrade agent tasks such as automated GUI interaction or CAPTCHA solving workflows. Incorporating corruption robustness evaluation helps reveal fragility in agents that may otherwise succeed in clean, sanitized settings. Furthermore, the dual-module design with an onlooker for environment state detection and summarization can inspire architectural approaches for robust agent supervision and error detection in complex human-machine interaction pipelines. Practitioners should consider robustness beyond adversarial attacks and address realistic noisy conditions in agent design and evaluation frameworks.
Cite
@article{arxiv2605_25707,
title={ AgentHijack: Benchmarking Computer Use Agent Robustness to Common Environment Corruptions },
author={ Jingwei Sun and Jianing Zhu and Yuanyi Li and Tongliang Liu and Xia HU and Bo Han },
journal={arXiv preprint arXiv:2605.25707},
year={ 2026 },
url={https://arxiv.org/abs/2605.25707}
}