
PANDO: Efficient Multimodal AI Agents via Online Skill Distillation
Source: arXiv:2605.24785 · Published 2026-05-24 · By Yubo Li, Yidi Miao, Haotian Shen, Yuxin Liu
TL;DR
This paper addresses the efficiency challenges faced by multimodal AI agents operating in web task environments, focusing on reducing the growing inference-time costs as agents accumulate experience. The authors analyze failures in VisualWebArena (VWA) trajectories and identify three main inefficiencies: repeated action loops, hidden discovery costs, and poor prompt cache reuse. To tackle these, they propose PANDO, an online skill-distillation framework that builds and maintains a structured Skill Library during evaluation. PANDO integrates components like progress reflection, confidence-based skill demotion, hierarchical routing, visual compression, and cache-aware prompting to improve both success rate and efficiency.
Empirically, PANDO achieves a 58.3% success rate on all 910 VWA tasks, surpassing prior state-of-the-art methods SGV (54.0%) and WALT reproduction (45.2%), while using 58% fewer tokens than SGV and 61% fewer than WALT. Ablations confirm that rules and reusable routines drive most performance gains, while routing and cache optimizations mainly reduce token cost. Novel efficiency metrics beyond terminal success—Action Repetition Rate, Step Overhead Ratio, and Prompt Cache Utilization—show PANDO improves trajectory-level efficiency, with fewer redundant steps and higher prompt reuse. Overall, PANDO demonstrates that agents can become cheaper, not more expensive, as they accumulate skills online without costly offline discovery or multiple rollouts.
Key findings
- PANDO achieves 58.3% success rate on the full 910-task VisualWebArena benchmark, outperforming SGV's 54.0% and WALT's 45.2%.
- PANDO reduces token consumption by 58% compared to SGV (115K vs 275K tokens per task) and 61% compared to WALT (115K vs 294K tokens).
- Action Repetition Rate (ARR) drops to 9.1% with PANDO versus 14.2% in SGV and 18.3% in WALT, indicating fewer repeated failure loops.
- Step Overhead Ratio (SOR) reduces to 1.8× in PANDO, lower than SGV (2.3×) and WALT (2.6×), reflecting faster fail-fast behavior.
- Prompt Cache Utilization reaches 72.4% in PANDO, markedly higher than SGV (45.1%) and WALT (38.6%), enabling better prompt token reuse.
- Online skill components lift success rate from 38.6% baseline to 57.3%, highlighting rules, routines, reflection, and skill demotion as main competence drivers.
- Routing, visual compression, and cache-aware prompting further reduce tokens from 147K to 117K and raise cache utilization from 69.3% to 72%.
- The skill library grows from 12 seed routines to 47 induced routines by task 910; demotion blacklists 15 brittle routines to avoid efficiency loss.
Threat model
The threat model is implicit and centers on realistic web automation tasks where the environment acts as a challenging multi-step adversary presenting complex GUI state changes and partial observability. The adversary is not assumed to be actively malicious or adversarial in ordering, but the agent must handle repeated failures, ambiguous or underspecified tasks, and avoid redundant action loops. The attacker cannot corrupt the agent's internal skill library but can lead it to discover brittle or ineffective skills if not properly demoted. No direct adversary manipulating the model weights or prompt inputs is considered.
Methodology — deep read
Threat Model and Assumptions: The adversary is implicitly the task environment presenting mixed web-based tasks requiring multimodal grounding from screenshots and DOM states. There is no assumption of adversarial task ordering but stability is verified under scrambled task order and parallel workers. The agent cannot cheat by caching ground-truth answers and faces realistic web interaction complexity (VisualWebArena).
Data: The method is evaluated on the VisualWebArena benchmark consisting of 910 web automation tasks from three domains: Classifieds, Shopping, and Reddit. Tasks are streamed in a fixed order (seed 42) for the main experiments; supplementary experiments scramble order and test multi-worker sharing. No additional labels are imposed beyond terminal success and trajectory state actions. Data collection integrates screenshot, DOM, and action sequences logged to analyze failure modes and token consumption.
Architecture / Algorithm: PANDO is structured around a skill library indexed by literal keywords, partitioned into pattern-triggered guardrail rules and parameterized subgoal routines. Its Agent has four loops: planning (task decomposition), skill selection (rule/routine retrieval), acting (primitive browser actions fallback), reflection (progress verification), and learning (online skill induction and demotion). The Learning Module maintains confidence statistics of skills, merges polarity pairs (e.g., ascending/descending variants), and blacklists brittle skills via failure history. Hierarchical routing dispatches subgoals to cheaper actors when possible. Visual compression reduces token cost for screenshots. Cache-aware prompt layout improves token reuse. The Planner and Reflector run on a strong LLM sparingly; the Actor is cheaper and handles fallback.
Training Regime: PANDO uses online lifelong learning at evaluation time; it induces new skills from successful sub-trajectories after each task evaluation with no offline pre-evaluation discovery budget. Confidence updates use Beta-style running averages. Polarity pair merging and demotion occur online. The unified evaluation uses a fixed LLM backbone (Opus 4.6 + GPT-5.2) with no explicit training epochs or offline fine-tuning described. Seeds and hyperparameters for skills and demotion thresholds are detailed in appendix but not fully disclosed in the truncated text.
Evaluation Protocol: Metrics include terminal Success Rate (SR), mean steps per task, tokens per task (prompt+completion+reasoning), latency, Action Repetition Rate (ARR), Step Overhead Ratio (SOR), and Prompt Cache Utilization (fraction of tokens served from KV cache). Baselines are reproduced with public code or replicated internally: SGV (Gemini Flash), WALT (Claude-4-Sonnet), and multiple SoM (State-of-Mind) variants. Ablations on a 300-task stratified subset analyze incremental contributions of rules, routines, reflection, skill induction, routing, compression, and cache prompting. Confidence intervals (paired bootstrap), scrambled order and parallel-worker experiments test robustness.
Reproducibility: The authors release benchmark code, metric trackers, prompt templates, and anonymized trajectories, excluding private credentials and site states. Exact model weights or training scripts are not mentioned. The policy implementations of baselines SGV and WALT are either publicly available or replicated. The full online skill induction pipeline is described at high level with appendix files referenced but not fully open in the text excerpt.
Example end-to-end: For one task, the Planner breaks the goal into subgoals, Skill Selector tries matching rules or routines via keyword triggers, falling back to primitive actions if needed. The Reflector checks post-action progress via DOM/screenshot changes, feeding success evidence back to Learning. If a subgoal sequence succeeds, a new routine is induced representing this reusable macroaction. Confidence statistics update, and any brittle skills failing repeatedly are demoted to blacklist. The skill library grows online, making future tasks cheaper via hierarchical routing and cached prompt prefixes reducing token cost. Over many tasks, success rate rises and tokens per task fall, demonstrating improved efficiency and competence simultaneously.
Technical innovations
- An online skill-distillation framework combining pattern-indexed rules and parameterized routines induced from on-task successes without offline discovery budgets.
- A literal keyword containment retrieval for the skill library enabling auditable, stable, and cache-friendly prompt layout, contrasting prior embedding-based retrievers.
- Introducing confidence-based skill demotion to blacklist brittle skills dynamically rather than accumulating stale routines monotonically.
- Integration of hierarchical routing, visual compression, and cache-aware prompting to convert a growing skill library into lower marginal token cost per task.
- New intrinsic efficiency metrics—Action Repetition Rate, Step Overhead Ratio, and Prompt Cache Utilization—that expose trajectory-level inference economy beyond terminal success.
Datasets
- VisualWebArena (VWA) — 910 tasks — public benchmark for multimodal web automation
Baselines vs proposed
- SGV (Gemini Flash): success rate = 54.0% vs PANDO: 58.3%
- SGV: tokens per task = 275K vs PANDO: 115K
- WALT (Claude-4-Sonnet): success rate = 45.2% vs PANDO: 58.3%
- WALT: tokens per task = 294K vs PANDO: 115K
- Baseline (SoM-Qwen (M)) multimodal grounding: success rate = 38.6% vs PANDO: 58.3%
- Baseline (SoM-Qwen (M)): tokens per task = 223K vs PANDO: 115K
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.24785.

Fig 1 (page 1).
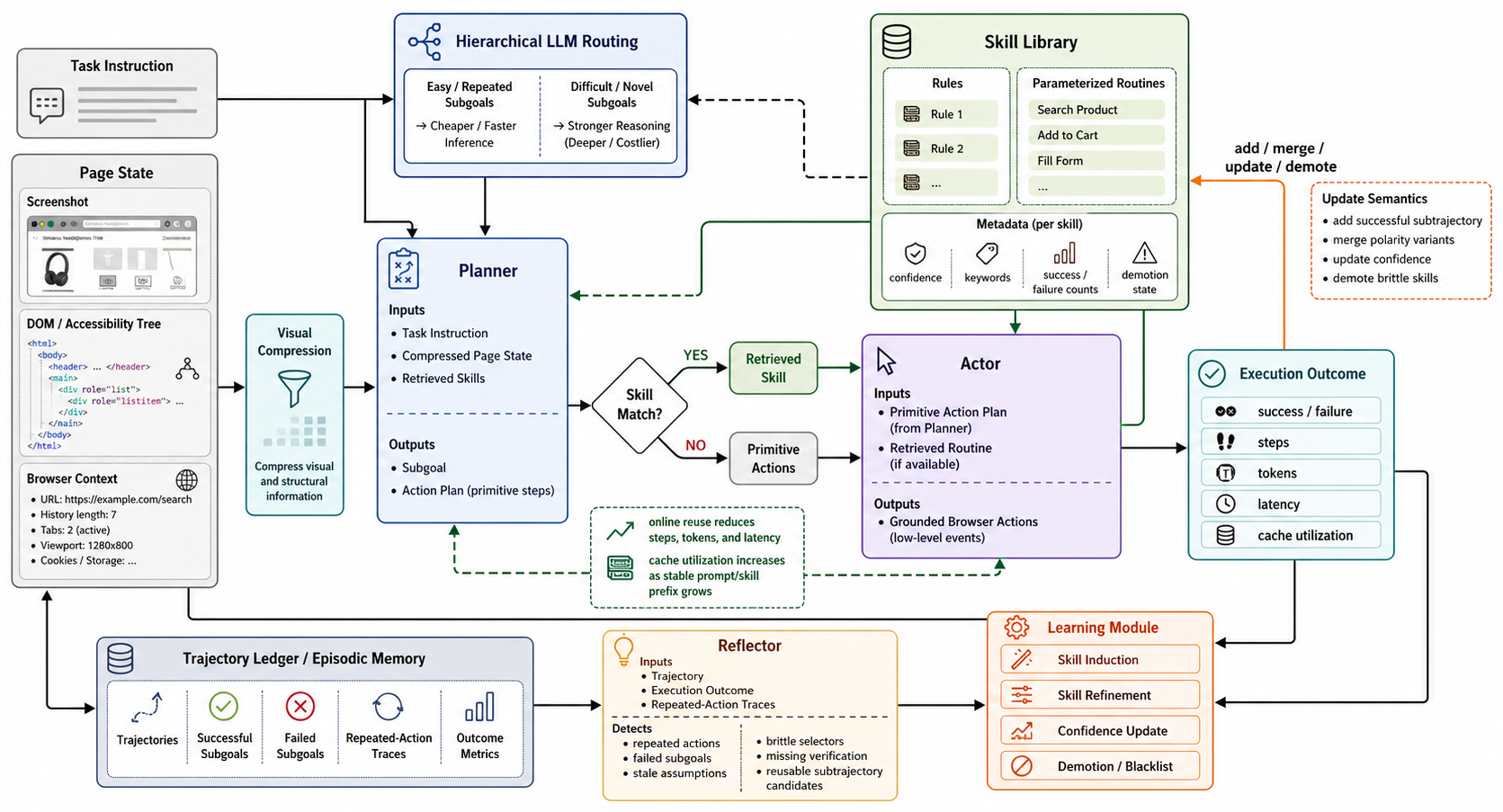
Fig 1: PANDO architecture. The Planner decomposes tasks into subgoals; the Skill Selector
Limitations
- All experiments are restricted to VisualWebArena; generalization to desktop OS automation (OSWorld) or other environments is untested and will require new domain-specific rules.
- Online learning assumes a trusted, non-adversarial task stream order; adversarial task ordering or malicious environments could degrade cold-start efficiency.
- Polarity-pair skill merging covers only simple syntactic opposites; broader program equivalence or semantic merging remains future work.
- Details on hyperparameters, seeds, and exact model configurations for reproducibility are limited in the provided text.
- No explicit adversarial evaluation or robustness tests against task distribution shifts beyond task reorderings are reported.
- The experiments exclude private site states and credentials, possibly limiting replicability for web environments requiring authentication.
Open questions / follow-ons
- How to extend online skill induction and demotion to more complex program-equivalence detection beyond polarity-pair merging?
- Can PANDO’s framework generalize effectively to desktop OS automation environments with different error modes and multi-application coordination?
- What are the impacts of adversarial or heavily non-stationary task streams on online skill learning stability and cold-start efficiency?
- How might integrating stronger multimodal grounding models reduce residual errors and skill-coverage gaps highlighted in failure analyses?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, PANDO presents a compelling methodology to build multimodal agents that improve efficiency over time by accumulating reusable skills online without incurring heavy upfront discovery or multiple rollout costs. Its token-economics framing and trajectory-level metrics provide a richer picture of agent efficiency than success rate alone, which is critical in evaluating real-world agent deployments under latency, compute, or cache constraints. The skill library design with explicit demotion and cache-aware prompting suggests ways to mitigate repeat failures common in automated web interactions relevant to CAPTCHA-solving or bot detection contexts.
Moreover, PANDO’s hierarchical routing and visual compression components align well with the operational need to minimize exposure to detection by reducing unnecessary or repetitive token-heavy queries. While the evaluation is on automation task benchmarks rather than direct adversarial bot/defender settings, the principles of online skill distillation and efficiency-oriented design contribute practical insights for building scalable, efficient multimodal AI-driven bots or defenses. Care should be taken regarding environment assumptions and adversarial robustness when adapting these methods for security-critical bot detection or CAPTCHA solving scenarios.
Cite
@article{arxiv2605_24785,
title={ PANDO: Efficient Multimodal AI Agents via Online Skill Distillation },
author={ Yubo Li and Yidi Miao and Haotian Shen and Yuxin Liu },
journal={arXiv preprint arXiv:2605.24785},
year={ 2026 },
url={https://arxiv.org/abs/2605.24785}
}